Csatlakozás az SAP HANA-adatforrásokhoz a DirectQuery használatával a Power BI-ban
Közvetlenül a DirectQuery használatával csatlakozhat SAP HANA-adatforrásokhoz. Az SAP HANA-hoz való csatlakozásnak két lehetősége van:
Kezelje az SAP HANA-t többdimenziós forrásként (alapértelmezett): Ebben az esetben a viselkedés hasonló ahhoz, mint amikor a Power BI más többdimenziós forrásokhoz, például az SAP Business Warehouse-hoz vagy az Analysis Serviceshez csatlakozik. Ha ezzel a beállítással csatlakozik az SAP HANA-hoz, egyetlen elemzési vagy számítási nézet lesz kiválasztva, és a nézet összes mértéke, hierarchiája és attribútuma elérhető a mezőlistában. A vizualizációk létrehozásakor a rendszer mindig lekéri az összesítő adatokat az SAP HANA-ból. Ez a módszer az ajánlott módszer, és az SAP HANA-n keresztüli új DirectQuery-jelentések alapértelmezett módszere.
Az SAP HANA relációs forrásként való kezelése: Ebben az esetben a Power BI az SAP HANA-t relációs forrásként kezeli. Ez a megközelítés nagyobb rugalmasságot biztosít. Ezzel a megközelítéssel ügyelni kell arra, hogy a mértékek a várt módon legyenek összesítve, és hogy elkerülhetők legyenek a teljesítményproblémák.
A kapcsolati megközelítést egy globális eszközbeállítás határozza meg, amely a Fájlbeállítások>és beállítások, majd a DirectQuery beállításai>, majd az SAP HANA relációs forrásként való kezelése lehetőség kiválasztásával van beállítva, ahogyan az az alábbi képen látható.
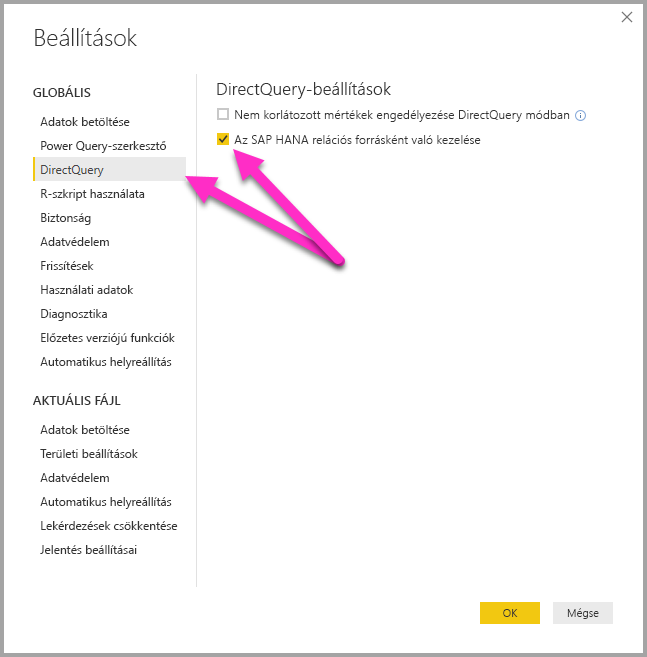
Az SAP HANA relációs forrásként való kezelésének lehetősége vezérli az sap HANA-n keresztüli DirectQueryt használó új jelentésekhez használt megközelítést. Nincs hatással az aktuális jelentésben meglévő SAP HANA-kapcsolatokra, sem a többi megnyitott jelentés kapcsolataira. Ha tehát a beállítás jelenleg nincs bejelölve, akkor amikor új kapcsolatot ad hozzá az SAP HANA-hoz az Adatok lekérése funkcióval, akkor a kapcsolat többdimenziós forrásként kezeli az SAP HANA-t. Ha azonban egy másik jelentés nyílik meg, amely szintén csatlakozik az SAP HANA-hoz, akkor a jelentés továbbra is a létrehozáskor beállított beállításnak megfelelően működik. Ez azt jelenti, hogy a 2018 februárja előtt létrehozott SAP HANA-hoz csatlakozó jelentések továbbra is relációs forrásként kezelik az SAP HANA-t.
A két megközelítés eltérő viselkedést jelent, és egy meglévő jelentés nem váltható át egyik megközelítésről a másikra.
Az SAP HANA kezelése többdimenziós forrásként (alapértelmezett)
Az SAP HANA minden új kapcsolata alapértelmezés szerint ezt a kapcsolati módszert használja, és az SAP HANA-t többdimenziós forrásként kezeli. Az SAP HANA-kapcsolat relációs forrásként való kezeléséhez ki kell választania a Fájlbeállítások>és beállítások>beállítások lehetőséget, majd jelölje be az SAP HANA relációs forrásként való kezelése a Direct Query Treat SAP HANA (Közvetlen lekérdezés>kezelése relációs forrásként) jelölőnégyzetet.
Ha többdimenziós forrásként csatlakozik az SAP HANA-hoz, az alábbi szempontokat kell figyelembe vennie:
A Get Data Navigator alkalmazásban egyetlen SAP HANA-nézet választható ki. Az egyes mértékek és attribútumok nem választhatók ki. A csatlakozáskor nincs definiálva lekérdezés, amely különbözik az adatok importálásától, vagy ha DirectQueryt használ az SAP HANA relációs forrásként való kezelése során. Ez a szempont azt is jelenti, hogy a kapcsolati módszer kiválasztásakor nem lehet közvetlenül SAP HANA SQL-lekérdezést használni.
A kijelölt nézet összes mértéke, hierarchiája és attribútuma megjelenik a mezőlistában.
Mivel egy vizualizációban mérték van használatban, az SAP HANA lekérdezi a mérték értékét a vizualizációhoz szükséges összesítés szintjén. A nem additív mértékek, például a számlálók és az arányok kezelésekor az összes összesítést az SAP HANA végzi, és a Power BI nem végez további összesítést.
Annak érdekében, hogy a megfelelő összesített értékek mindig az SAP HANA-tól származhassanak, bizonyos korlátozásokat kell bevezetni. Nem lehet például számított oszlopokat hozzáadni, vagy több SAP HANA-nézet adatait egyesíteni ugyanabban a jelentésben.
Az SAP HANA többdimenziós forrásként való kezelése nem biztosítja az alternatív relációs megközelítés által biztosított nagyobb rugalmasságot, de egyszerűbb. A megközelítés az összetettebb SAP HANA-mértékek kezelésekor is biztosítja a helyes összesített értékeket, és általában nagyobb teljesítményt eredményez.
A Mezőlista az SAP HANA nézet összes mértékét, attribútumát és hierarchiáit tartalmazza. Figyelje meg az alábbi viselkedéseket, amelyek a kapcsolati módszer használatakor érvényesek:
Alapértelmezés szerint minden olyan attribútum, amely legalább egy hierarchiában szerepel, alapértelmezés szerint rejtett. Ezek azonban szükség esetén a mezőlista helyi menüjében rejtett nézet kiválasztásával tekinthetők meg. Ugyanabból a helyi menüből szükség esetén láthatóvá tehetők.
Az SAP HANA-ban egy attribútum definiálható úgy, hogy egy másik attribútumot használjon címkeként. Például a Product( az értékekkel
123, és így tovább) a ProductName értéket, az értékeket, az értékeketBikeShirtGloves, és így tovább, címkéjeként használhatja. Ebben az esetben egyetlen mező terméke jelenik meg a mezőlistában, amelynek értékei a címkékBike,Shirt,Glovesstb.123Létrejön egy rejtett Product.Key oszlop is, amely szükség esetén hozzáférést biztosít a mögöttes kulcsértékekhez.
A mögöttes SAP HANA nézetben definiált változók a csatlakozáskor jelennek meg, és a szükséges értékek beírhatók. Ezek az értékek később módosíthatók a menüszalagOn az Adatok átalakítása, majd a Paraméterek szerkesztése lehetőség kiválasztásával a megjelenő legördülő menüből.
Az engedélyezett modellezési műveletek szigorúbbak, mint az általános esetben a DirectQuery használatakor, mivel biztosítani kell, hogy a megfelelő összesített adatok mindig elérhetők legyenek az SAP HANA-tól. Azonban továbbra is számos kiegészítést és módosítást végezhet, beleértve a mértékek definiálását, a mezők átnevezését és elrejtését, valamint a megjelenítési formátumok definiálását. Az összes ilyen módosítás megmarad a frissítéskor, és az SAP HANA nézet nem ütköző módosításait alkalmazza a rendszer.
További modellezési korlátozások
A DirectQuery használatával (többdimenziós forrásként kezelt) SAP HANA-hoz való csatlakozás egyéb elsődleges modellezési korlátozásai a következő korlátozások:
- A számított oszlopok nem támogatottak: A számított oszlopok létrehozásának lehetősége le van tiltva. Ez a tény azt is jelenti, hogy a számított oszlopokat létrehozó csoportosítás és fürtözés nem érhető el.
- További korlátozások a mértékekre vonatkozóan: A DAX-kifejezésekre egyéb korlátozások vonatkoznak, amelyek az SAP HANA által nyújtott támogatás szintjét tükrözik.
- A kapcsolatok definiálása nem támogatott: Csak egyetlen nézet kérdezhető le egy jelentésben, így a kapcsolatok definiálása nem támogatott.
- Nincs adatnézet: Az Adatnézet általában a táblák részletességi adatait jeleníti meg. Az OLAP-források, például az SAP HANA jellegéből adódóan ez a nézet nem érhető el az SAP HANA-n keresztül.
- Az oszlop- és mértékadatok javítva vannak: A mezőlistában látható oszlopok és mértékek listáját az alapul szolgáló forrás rögzíti, és nem módosítható. Például nem lehet törölni egy oszlopot, és nem lehet módosítani az adattípusát. Azonban átnevezhető.
- További korlátozások a DAX-ban: A DAX-ra más korlátozások is vonatkoznak, amelyek a mértékdefiníciókban használhatók a forrás korlátainak tükrözésére. Például nem lehet összesített függvényt használni egy táblán.
További vizualizációs korlátozások
A vizualizációkban korlátozások vonatkoznak az SAP HANA-hoz DirectQuery használatával való csatlakozáskor (többdimenziós forrásként kezelendő):
- Nincs oszlopösszesítés: A vizualizációk oszlopainak összesítését nem lehet módosítani, és mindig nincs összegzés.
Az SAP HANA relációs forrásként való kezelése
Ha az SAP HANA-hoz való csatlakozást választja relációs forrásként, némi további rugalmasság válik elérhetővé. Létrehozhat például számított oszlopokat, több SAP HANA-nézet adatait is belefoglalhatja, és kapcsolatokat hozhat létre az eredményként kapott táblák között. Az SAP HANA többdimenziós forrásként való kezelésekor azonban eltérnek a viselkedéstől, különösen akkor, ha az SAP HANA-nézet nem additív mértékeket, például eltérő darabszámokat vagy átlagokat tartalmaz egyszerű összegek helyett, és az SAP HANA-n futtatott lekérdezések hatékonyságához kapcsolódik.
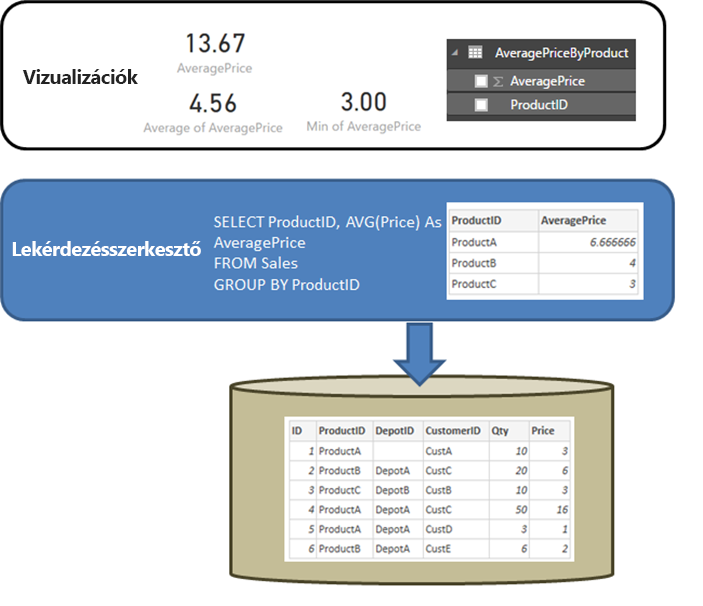
Először is érdemes tisztázni egy relációs forrás, például az SQL Server viselkedését, amikor az Adatok lekérése vagy Power Query-szerkesztő lekérdezés összesítést hajt végre. Az alábbi példában egy Power Query-szerkesztő definiált lekérdezés az átlagos árat adja eredményül ProductID alapján.
Ha az adatokat a Power BI-ba importálja a DirectQuery használata helyett, a következő helyzet következne be:
- Az adatok importálása a Power Query-szerkesztő létrehozott lekérdezés által meghatározott összesítés szintjén történik. Például az átlagos ár termék szerint. Ez a tény egy táblát eredményez, amely a vizualizációkban használható productID és AveragePrice oszlopot tartalmazza.
- A vizualizációkban a rendszer minden további összesítést( például Sum, Average, Min és egyéb) az importált adatokon keresztül hajt végre. Egy vizualizáción például az AveragePrice értéke alapértelmezés szerint az Összeg aggregátumot használja, és az összeget az egyes ProductID-ekhez tartozó AveragePrice értéken adja vissza, ebben a példában 13,67. Ugyanez vonatkozik a vizualizációban használt bármely alternatív aggregátumfüggvényre, például a Min vagy az Átlag függvényre is. Az Átlagár átlaga például a 6,66, 4 és 3 átlagot adja vissza, ami 4,56-nak felel meg, és nem az alapul szolgáló tábla hat rekordján szereplő Ár átlaga, ami 5,17.
Ha az Importálás helyett ugyanazon a relációs forráson keresztül használja a DirectQueryt, ugyanazok a szemantikák érvényesek, és az eredmények pontosan megegyeznek:
Ugyanezzel a lekérdezéssel logikailag pontosan ugyanazok az adatok jelennek meg a jelentéskészítési rétegben , még akkor is, ha az adatok valójában nem importálva.
A vizualizációkban a rendszer ismét végrehajtja az összesítő összesítést, például az Összeg, az Átlag és a Min függvényt a lekérdezésből származó logikai táblán. A AveragePrice átlagát tartalmazó vizualizáció szintén ugyanazt a 4,56-ot adja vissza.
Vegye figyelembe az SAP HANA-t, ha a kapcsolat relációs forrásként van kezelve. A Power BI az SAP HANA elemzési nézeteivel és számítási nézeteivel is használható, amelyek mindegyike tartalmazhat mértékeket. Az SAP HANA megközelítése azonban ma is ugyanazokat az alapelveket követi, mint korábban ebben a szakaszban: az Adatok lekérése vagy Power Query-szerkesztő definiált lekérdezés határozza meg az elérhető adatokat, majd a vizualizációk későbbi összesítése ezen az adatokon halad át, és ugyanez vonatkozik az Importálás és a DirectQuery esetében is. Az SAP HANA jellegéből adódóan azonban a kezdeti Adatok lekérése párbeszédpanelen vagy Power Query-szerkesztő definiált lekérdezés mindig összesített lekérdezés, és általában olyan mértékeket is tartalmaz, amelyekben a tényleges összesítést az SAP HANA-nézet határozza meg.
Az előző SQL Server-példával egyenértékű, hogy létezik egy SAP HANA-nézet, amely azonosítót, ProductID-et, DepotID-ot és mértékeket tartalmaz, beleértve az AveragePrice-t is, amely az Ár átlaga nézetben van definiálva.
Ha az Adatok lekérése felületen a productID és az AveragePrice mértékre lettek kiválasztva, akkor ez egy lekérdezést határoz meg a nézetben, amely az összesítő adatokat kéri le. A korábbi példában az egyszerűség kedvéért pszeudo-SQL-t használunk, amely nem felel meg az SAP HANA SQL pontos szintaxisának. Ezután a vizualizációban definiált további összesítések tovább összesítják az ilyen lekérdezések eredményeit. Az SQL Server esetében korábban leírtaknak megfelelően ez az eredmény az Importálás és a DirectQuery esetre is érvényes. A DirectQuery esetében az Adatok lekérése vagy a Power Query-szerkesztő lekérdezése egy, az SAP HANA-nak küldött lekérdezés alválasztásában használatos, így valójában nem az a helyzet, hogy az összes adat beolvasva lenne a további összesítés előtt.
A DirectQuery SAP HANA-n keresztül történő használatakor a következő fontos szempontokat és viselkedéseket kell figyelembe venni:
Figyelmet kell fordítani a vizualizációkban végzett további összesítésekre, ha az SAP HANA-ban a mérték nem additív, például nem egyszerű Összeg, Min vagy Max.
Az Adatok lekérése vagy a Power Query-szerkesztő csak a szükséges oszlopoknak kell szerepelnie a szükséges adatok lekéréséhez, tükrözve azt a tényt, hogy az eredmény egy olyan lekérdezés, amelynek ésszerű lekérdezésnek kell lennie, amelyet el lehet küldeni az SAP HANA-nak. Ha például több tucat oszlopot választottak ki, és úgy gondolták, hogy szükség lehet rájuk a későbbi vizualizációkban, akkor még a DirectQuery esetében is egy egyszerű vizualizáció azt jelenti, hogy az alválasztásban használt összesítő lekérdezés több tucat oszlopot tartalmaz, amelyek általában rosszul teljesítenek.
Az alábbi példában öt oszlop (CalendarQuarter, Color, LastName, ProductLine, SalesOrderNumber) kiválasztása az Adatok lekérése párbeszédpanelen az OrderQuantity mértékkel együtt azt jelenti, hogy később a Min OrderQuantity értéket tartalmazó egyszerű vizualizáció létrehozása a következő SQL-lekérdezést eredményezi az SAP HANA-nak. A színárnyalatos az alválasztás, amely az Adatok lekérése/Power Query-szerkesztő lekérdezését tartalmazza. Ha ez az alválasztás magas számosságú eredményt ad, akkor az sap HANA-teljesítmény valószínűleg gyenge lesz.

Emiatt a viselkedés miatt azt javasoljuk, hogy az Adatok lekérése vagy Power Query-szerkesztő kijelölt elemek csak a szükséges elemekre legyenek korlátozva, ugyanakkor ésszerű lekérdezést eredményeznek az SAP HANA-hoz.
Ajánlott eljárások
Az SAP HANA-hoz való csatlakozás mindkét megközelítése esetében a DirectQuery használatára vonatkozó javaslatok az SAP HANA-ra is vonatkoznak, különösen a jó teljesítmény biztosításával kapcsolatos javaslatokra. További információ: A DirectQuery használata a Power BI-ban.
Szempontok és korlátozások
Az alábbi lista az összes olyan SAP HANA-funkciót ismerteti, amely nem teljes mértékben támogatott, vagy a Power BI használatakor eltérően viselkedő funkciókat.
- Szülő gyermekhierarchiák: A szülő gyermekhierarchiák nem láthatók a Power BI-ban. Ennek az az oka, hogy a Power BI az SQL-felületen fér hozzá az SAP HANA-hez, és a szülő gyermekhierarchiák nem érhetők el teljes mértékben az SQL használatával.
- Egyéb hierarchia-metaadatok: A hierarchiák alapvető struktúrája megjelenik a Power BI-ban, de egyes hierarchia-metaadatoknak, például a ragged hierarchiák viselkedésének szabályozása, nincs hatása. Ez a tény az SQL-felület által előírt korlátozásoknak is köszönhető.
- Csatlakozás ssl használatával: Az Importálás és a többdimenziós kapcsolattal is csatlakozhat a TLS-sel, de nem tud csatlakozni a TLS relációs összekötőhöz való használatára konfigurált SAP HANA-példányokhoz.
- Attribútumnézetek támogatása: A Power BI képes kapcsolódni az elemzési és számítási nézetekhez, de nem tud közvetlenül attribútumnézetekhez csatlakozni.
- Katalógusobjektumok támogatása: A Power BI nem tud katalógusobjektumokhoz csatlakozni.
- Váltás változókra a közzététel után: A jelentés közzététele után nem módosíthatja az SAP HANA-változók értékeit közvetlenül a Power BI szolgáltatás.
Ismert problémák
Az alábbi lista az SAP HANA-hoz (DirectQuery) a Power BI-hoz való csatlakozáskor felmerülő összes ismert problémát ismerteti.
SAP HANA-probléma a számlálók lekérdezésekor és más mértékek esetén: Az SAP HANA helytelen adatokat ad vissza, ha elemzési nézethez csatlakozik, és a számláló mértéke és más aránymérések is szerepelnek ugyanabban a vizualizációban. Ezt a problémát az SAP Note 2128928 (Számított oszlop és számláló lekérdezésekor nem várt eredmények) ismerteti. Ebben az esetben az aránymérés helytelen.
Több Power BI-oszlop egyetlen SAP HANA-oszlopból: Egyes számítási nézetekben, ahol egy SAP HANA-oszlopot több hierarchiában használnak, az SAP HANA két különálló attribútumként teszi elérhetővé az oszlopot. Ez a megközelítés két oszlop létrehozását eredményezi a Power BI-ban. Ezek az oszlopok alapértelmezés szerint rejtve vannak, és a hierarchiákat vagy közvetlenül az oszlopokat tartalmazó összes lekérdezés megfelelően működik.
Kapcsolódó tartalom
A DirectQuery szolgáltatással kapcsolatos további információkért tekintse meg a következő erőforrásokat: