Az adatfolyamok prémium funkciói
Az adatfolyamok a Power BI Pro, a Felhasználónkénti Prémium (PPU) és a Power BI Premium-felhasználók számára támogatottak. Egyes funkciók csak Power BI Premium-előfizetéssel érhetők el (amely prémium szintű kapacitás vagy PPU-licenc). Ez a cikk ismerteti és részletezi a csak PPU- és prémium szintű funkciókat és azok használatát.
A következő funkciók csak a Power BI Premium (PPU vagy Prémium szintű kapacitás-előfizetés) esetén érhetők el:
- Továbbfejlesztett számítási motor
- DirectQuery
- Számított entitások
- Csatolt entitások
- Növekményes frissítés
A következő szakaszok részletesen ismertetik ezeket a funkciókat.
Fontos
Ez a cikk az adatfolyamok első generációjára (Gen1) vonatkozik, és nem vonatkozik a Microsoft Fabricben (előzetes verzió) elérhető adatfolyamok második generációjára (Gen2). További információ: Getting from dataflows Generation 1 to dataflows Generation 2.
A továbbfejlesztett számítási motor
A Power BI továbbfejlesztett számítási motorja lehetővé teszi a Power BI Premium előfizetői számára, hogy kapacitásukkal optimalizálják az adatfolyamok használatát. A továbbfejlesztett számítási motor használata a következő előnyöket biztosítja:
- Drasztikusan csökkenti a hosszú ideig futó ETL-lépésekhez (kinyerés, átalakítás, betöltés) szükséges frissítési időt a számított entitások esetében, például illesztések, különböző elemek, szűrők és csoportosítási műveletek végrehajtásához.
- DirectQuery-lekérdezéseket hajt végre entitásokon keresztül.
Feljegyzés
- Az ellenőrzési és frissítési folyamatok tájékoztatják a modellséma adatfolyamait. A táblák sémájának beállításához használja a Power Query-szerkesztő és állítsa be az adattípusokat.
- Ez a funkció a WABI-INDIA-CENTRAL-A-PRIMARY kivételével minden Power BI-fürtön elérhető
A továbbfejlesztett számítási motor engedélyezése
Fontos
A továbbfejlesztett számítási motor csak A3 vagy nagyobb Power BI-kapacitásokhoz működik.
A Power BI Premiumban a továbbfejlesztett számítási motor egyenként van beállítva az egyes adatfolyamokhoz. Három konfiguráció közül választhat:
Letiltva
Optimalizált (alapértelmezett) – A továbbfejlesztett számítási motor ki van kapcsolva. Automatikusan be van kapcsolva, ha az adatfolyam egyik táblájára egy másik tábla hivatkozik, vagy ha az adatfolyam egy másik adatfolyamhoz csatlakozik ugyanazon a munkaterületen.
Bekapcsolva
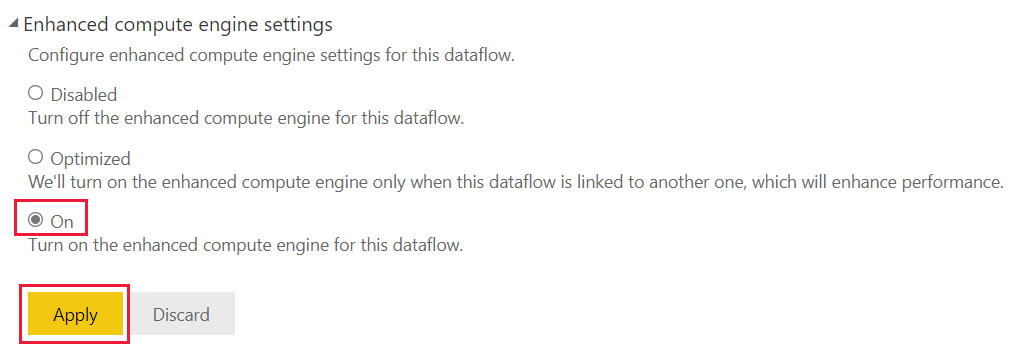
Az alapértelmezett beállítás módosításához és a továbbfejlesztett számítási motor engedélyezéséhez hajtsa végre az alábbi lépéseket:
A munkaterületen, azon adatfolyam mellett, amelyhez módosítani szeretné a beállításokat, válassza a További beállítások lehetőséget.
Az adatfolyam További beállítások menüjében válassza a Gépház lehetőséget.

Bontsa ki a bővített számítási motor beállításait.

A Bővített számítási motor beállításai között válassza a Be, majd az Alkalmaz lehetőséget.
A továbbfejlesztett számítási motor használata
Miután a továbbfejlesztett számítási motor be van kapcsolva, térjen vissza az adatfolyamokhoz , és teljesítménybeli javulást kell látnia minden olyan számítási táblában, amely összetett műveleteket hajt végre, például illesztéseket vagy csoportosítási műveleteket az ugyanazon a kapacitáson lévő meglévő csatolt entitásokból létrehozott adatfolyamokhoz.
A számítási motor legjobb kihasználása érdekében ossza fel az ETL szakaszt két különálló adatfolyamra a következő módon:
- 1 . adatfolyam – ez az adatfolyam csak az összes szükséges adatot betölti egy adatforrásból.
- Adatfolyam 2 – az összes ETL-műveletet végrehajtja ebben a második adatfolyamban, de győződjön meg arról, hogy az 1. adatfolyamra hivatkozik, amelynek ugyanazon a kapacitáson kell lennie. Győződjön meg arról is, hogy olyan műveleteket hajt végre, amelyek először hajthatók végre: szűrés, csoportosítás, különbözőség, illesztés). Ezeket a műveleteket pedig bármely más művelet előtt hajthatja végre, hogy a számítási motort kihasználhassa.
Gyakori kérdések és válaszok
Kérdés: Engedélyeztem a továbbfejlesztett számítási motort, de a frissítéseim lassabbak. Miért?
Válasz: Ha engedélyezi a továbbfejlesztett számítási motort, két lehetséges magyarázat létezik, amelyek lassabb frissítési időt eredményezhetnek:
Ha a továbbfejlesztett számítási motor engedélyezve van, némi memóriára van szükség a megfelelő működéshez. Így a frissítés végrehajtásához rendelkezésre álló memória csökken, ezért növeli a frissítések várólistára helyezésének valószínűségét. Ez a növekedés ezután csökkenti az egyidejűleg frissíthető adatfolyamok számát. A probléma megoldásához a bővített számítás engedélyezésekor növelje az adatfolyamokhoz rendelt memóriát, hogy az egyidejű adatfolyam-frissítésekhez rendelkezésre álló memória változatlan maradjon.
Egy másik ok, amiért lassabb frissítéseket tapasztalhat, az az, hogy a számítási motor csak a meglévő entitásokon működik. Ha az adatfolyam olyan adatforrásra hivatkozik, amely nem adatfolyam, akkor nem fog javulást látni. Nem fog teljesítménynövekedést eredményezni, mivel egyes big data-forgatókönyvekben az adatforrások kezdeti olvasása lassabb lenne, mert az adatokat át kell adni a továbbfejlesztett számítási motornak.
Kérdés: Nem látom a továbbfejlesztett számítási motor kapcsolóját. Miért?
Válasz: A továbbfejlesztett számítási motort szakaszosan bocsátják ki a világ különböző régióiban, de még nem érhető el minden régióban.
Kérdés: Mik a számítási motor támogatott adattípusai?
Válasz: A továbbfejlesztett számítási motor és adatfolyamok jelenleg a következő adattípusokat támogatják. Ha az adatfolyam nem használja az alábbi adattípusok egyikét, a frissítés során hiba történik:
- Dátum/idő
- Decimális szám
- Szöveg
- Egész szám
- Dátum/idő/zóna
- True/false
- Dátum
- Idő
A DirectQuery használata adatfolyamokkal a Power BI-ban
A DirectQuery használatával közvetlenül csatlakozhat az adatfolyamokhoz, és így közvetlenül csatlakozhat az adatfolyamhoz anélkül, hogy importálnia kellene az adatokat.
A DirectQuery adatfolyamokkal való használata a következő fejlesztéseket teszi lehetővé a Power BI-ban és az adatfolyam-folyamatokban:
Kerülje a különálló frissítési ütemezéseket – A DirectQuery közvetlenül csatlakozik egy adatfolyamhoz, így nincs szükség importált szemantikai modell létrehozására. Ezért a DirectQuery és az adatfolyamok használata azt jelenti, hogy már nincs szükség külön frissítési ütemezésre az adatfolyamhoz és a szemantikai modellhez az adatok szinkronizálásának biztosításához.
Adatok szűrése – A DirectQuery hasznos az adatfolyamon belüli adatok szűrt nézetén való munkához. A DirectQuery és a számítási motor segítségével szűrheti az adatfolyam-adatokat, és használhatja a szükséges szűrt részhalmazt. Az adatok szűrésével az adatfolyamban lévő adatok kisebb és kezelhetőbb részhalmazával dolgozhat.
DirectQuery használata adatfolyamokhoz
A DirectQuery adatfolyamokkal való használata a Power BI Desktopban érhető el.
A DirectQuery adatfolyamokkal való használatának előfeltételei:
- Az adatfolyamnak egy Power BI Premium-kompatibilis munkaterületen kell lennie.
- A számítási motort be kell kapcsolni.
Ha többet szeretne megtudni az adatfolyamokkal rendelkező DirectQueryről, olvassa el a DirectQuery használata adatfolyamokkal című témakört.
DirectQuery engedélyezése adatfolyamokhoz
Annak érdekében, hogy az adatfolyam elérhető legyen a DirectQuery-hozzáféréshez, a továbbfejlesztett számítási motornak optimalizált állapotban kell lennie. Ha engedélyezni szeretné a DirectQueryt adatfolyamokhoz, állítsa be az új továbbfejlesztett számítási motor beállításait.

A beállítás alkalmazása után frissítse az adatfolyamot az optimalizálás érvénybe lépéséhez.
A DirectQuery szempontjai és korlátozásai
A DirectQuery és az adatfolyamok néhány ismert korlátozást jelentenek:
Az importálási és DirectQuery-adatforrásokkal rendelkező összetett/vegyes modellek jelenleg nem támogatottak.
Előfordulhat, hogy a nagyméretű adatfolyamok időtúllépési problémákat tapasztalnak a vizualizációk megtekintésekor. Az időtúllépési problémákat okozó nagy adatfolyamoknak importálási módot kell használniuk.
Az adatforrás beállításai között az adatfolyam-összekötő érvénytelen hitelesítő adatokat jelenít meg, ha DirectQueryt használ. Ez a figyelmeztetés nem befolyásolja a viselkedést, és a szemantikai modell megfelelően fog működni.
Számított entitások
A Power BI Premium-előfizetéssel rendelkező adatfolyamok használatakor tárolási számításokat végezhet. Ez a funkció lehetővé teszi a számítások elvégzését a meglévő adatfolyamokon, és olyan eredményeket ad vissza, amelyek lehetővé teszik a jelentések létrehozására és elemzésére való összpontosítást.
A tároláson belüli számítások elvégzéséhez először létre kell hoznia az adatfolyamot, és adatokat kell bevinnie abba a Power BI-adatfolyam-tárolóba. Miután rendelkezik adatokat tartalmazó adatfolyamkal, létrehozhat számítási entitásokat, amelyek olyan entitások, amelyek tárolón belüli számításokat végeznek.
A számított entitások szempontjai és korlátozásai
- Amikor egy szervezet Azure Data Lake Storage Gen2-fiókjában létrehozott adatfolyamokkal dolgozik, a csatolt entitások és a számított entitások csak akkor működnek megfelelően, ha az entitások ugyanabban a tárfiókban találhatók.
Ajánlott eljárásként, amikor helyszíni és felhőbeli adatokhoz csatlakoztatott adatokon végez számításokat, hozzon létre egy új adatfolyamot minden forráshoz (egyet a helyszíni és egyet a felhőhöz), majd hozzon létre egy harmadik adatfolyamot a két adatforrás egyesítéséhez/kiszámításához.
Csatolt entitások
Meglévő adatfolyamokra hivatkozhat egy Power BI Premium-előfizetéssel rendelkező csatolt entitások használatával, amelyekkel számításokat végezhet ezeken az entitásokon számított entitások használatával, vagy létrehozhat egy "az igazság egyetlen forrása" táblát, amelyet több adatfolyamon belül újra felhasználhat.
Növekményes frissítés
Az adatfolyamok beállíthatók növekményes frissítésre, hogy ne kelljen minden frissítéshez lekérni az összes adatot. Ehhez válassza az adatfolyamot , majd a Növekményes frissítés ikont.

A növekményes frissítés beállítása paramétereket ad az adatfolyamhoz a dátumtartomány megadásához. A növekményes frissítés beállításával kapcsolatos részletes információkért lásd: Növekményes frissítés használata adatfolyamokkal.
A növekményes frissítés beállításának sikertelenségére vonatkozó szempontok
Ne állítson be adatfolyamot növekményes frissítésre a következő helyzetekben:
- A csatolt entitások nem használhatnak növekményes frissítést, ha adatfolyamra hivatkoznak.
Kapcsolódó tartalom
Az alábbi cikkek további információt nyújtanak az adatfolyamokról és a Power BI-ról:
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: