Gambaran umum autoscaling kluster di Azure Kubernetes Service (AKS)
Untuk mengikuti permintaan aplikasi di Azure Kubernetes Service (AKS), Anda mungkin perlu menyesuaikan jumlah simpul yang menjalankan beban kerja Anda. Komponen autoscaler kluster mengawasi pod di kluster Anda yang tidak dapat dijadwalkan karena kendala sumber daya. Ketika autoscaler kluster mendeteksi masalah, penskala otomatis meningkatkan jumlah simpul di kumpulan simpul untuk memenuhi permintaan aplikasi. Ini juga secara teratur memeriksa node untuk kurangnya pod yang berjalan dan menurunkan skala jumlah simpul sesuai kebutuhan.
Artikel ini membantu Anda memahami cara kerja autoscaler kluster di AKS. Ini juga memberikan panduan, praktik terbaik, dan pertimbangan saat mengonfigurasi autoscaler kluster untuk beban kerja AKS Anda. Jika Anda ingin mengaktifkan, menonaktifkan, atau memperbarui autoscaler kluster untuk beban kerja AKS Anda, lihat Menggunakan autoscaler kluster di AKS.
Tentang autoscaler kluster
Kluster sering membutuhkan cara untuk menskalakan secara otomatis untuk menyesuaikan dengan mengubah tuntutan aplikasi, seperti antara hari kerja dan malam atau akhir pekan. Kluster AKS dapat menskalakan dengan cara berikut:
- Autoscaler kluster secara berkala memeriksa pod yang tidak dapat dijadwalkan pada simpul karena kendala sumber daya. Kemudian kluster meningkatkan jumlah node secara otomatis. Penskalaan manual dinonaktifkan saat Anda menggunakan autoscaler kluster. Untuk informasi selengkapnya, lihat Bagaimana cara kerja peningkatan skala?.
- Autoscaler Pod Horizontal menggunakan Server Metrik dalam kluster Kubernetes untuk memantau permintaan sumber daya pod. Jika sebuah aplikasi membutuhkan lebih banyak sumber daya, jumlah pod ditingkatkan secara otomatis untuk memenuhi permintaan.
- Autoscaler Pod Vertikal secara otomatis mengatur permintaan dan batasan sumber daya pada kontainer per beban kerja berdasarkan penggunaan sebelumnya untuk memastikan pod dijadwalkan ke simpul yang memiliki sumber daya CPU dan memori yang diperlukan.
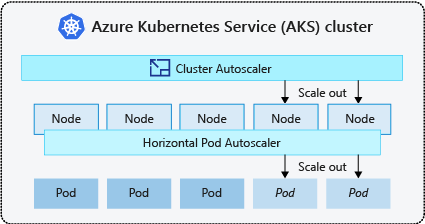
Ini adalah praktik umum untuk mengaktifkan autoscaler kluster untuk simpul dan Autoscaler Pod Vertikal atau Autoscaler Pod Horizontal untuk pod. Saat Anda mengaktifkan autoscaler kluster, itu menerapkan aturan penskalakan yang ditentukan ketika ukuran kumpulan simpul lebih rendah dari minimum atau lebih besar dari maksimum. Autoscaler kluster menunggu untuk berlaku sampai simpul baru diperlukan di kumpulan simpul atau sampai simpul mungkin dihapus dengan aman dari kumpulan simpul saat ini. Untuk informasi selengkapnya, lihat Bagaimana cara kerja penurunan skala?
Praktik serta pertimbangan terbaik
- Saat menerapkan zona ketersediaan dengan autoscaler kluster, sebaiknya gunakan satu kumpulan simpul untuk setiap zona. Anda dapat mengatur
--balance-similar-node-groupsparameter keTrueuntuk mempertahankan distribusi simpul yang seimbang di seluruh zona untuk beban kerja Anda selama operasi peningkatan skala. Ketika pendekatan ini tidak diterapkan, operasi penurunan skala dapat mengganggu keseimbangan simpul di seluruh zona. - Untuk kluster dengan lebih dari 400 simpul, sebaiknya gunakan Azure CNI atau Azure CNI Overlay.
- Untuk menjalankan beban kerja secara efektif secara bersamaan pada kumpulan simpul Spot dan Tetap, pertimbangkan untuk menggunakan perluas prioritas. Pendekatan ini memungkinkan Anda untuk menjadwalkan pod berdasarkan prioritas kumpulan simpul.
- Berhati-hatilah saat menetapkan permintaan CPU/Memori pada pod. Penskala otomatis kluster meningkatkan skala berdasarkan pod yang tertunda daripada tekanan CPU/Memori pada simpul.
- Untuk kluster yang secara bersamaan menghosting beban kerja yang berjalan lama, seperti aplikasi web, dan beban kerja pekerjaan pendek/bursty, sebaiknya pisahkan menjadi kumpulan simpul yang berbeda dengan perluasan Aturan/Afinitas atau menggunakan PriorityClass untuk membantu mencegah pengurasan simpul yang tidak perlu atau menurunkan skala operasi.
- Dalam kumpulan simpul berkemampuan autoscaler, turunkan skala simpul dengan menghapus beban kerja, alih-alih mengurangi jumlah simpul secara manual. Ini bisa bermasalah jika kumpulan simpul sudah pada kapasitas maksimum atau jika ada beban kerja aktif yang berjalan pada simpul, berpotensi menyebabkan perilaku yang tidak terduga oleh autoscaler kluster
- Node tidak meningkatkan skala jika pod memiliki nilai PriorityClass di bawah -10. Prioritas -10 dicadangkan untuk provisi pod yang berlebihan. Untuk informasi selengkapnya, lihat Menggunakan autoscaler kluster dengan Prioritas Pod dan Preemption.
- Jangan gabungkan mekanisme autoscaling node lainnya, seperti autoscaler Virtual Machine Scale Set, dengan autoscaler kluster.
- Autoscaler kluster mungkin tidak dapat menurunkan skala jika pod tidak dapat bergerak, seperti dalam situasi berikut:
- Pod yang dibuat secara langsung tidak didukung oleh objek pengontrol, seperti Deployment atau ReplicaSet.
- Anggaran gangguan pod (PDB) yang terlalu ketat dan tidak memungkinkan jumlah pod berada di bawah ambang batas tertentu.
- Sebuah Pod menggunakan pemilih node atau anti-afinitas yang tidak dapat diterapkan jika dijadwalkan pada node yang berbeda. Untuk informasi selengkapnya, lihat Jenis pod apa yang dapat mencegah autoscaler kluster menghapus node?.
Penting
Jangan membuat perubahan pada simpul individual dalam kumpulan simpul yang diskalakan otomatis. Semua simpul dalam grup simpul yang sama harus memiliki kapasitas, label, taint, dan pod sistem yang seragam yang berjalan di atasnya.
Profil autoscaler kluster
Profil autoscaler kluster adalah sekumpulan parameter yang mengontrol perilaku autoscaler kluster. Anda dapat mengonfigurasi profil autoscaler kluster saat membuat kluster atau memperbarui kluster yang ada.
Mengoptimalkan profil autoscaler kluster
Anda harus menyempurnakan pengaturan profil autoscaler kluster sesuai dengan skenario beban kerja spesifik Anda sambil juga mempertimbangkan tradeoff antara performa dan biaya. Bagian ini menyediakan contoh yang menunjukkan tradeoff tersebut.
Penting untuk dicatat bahwa pengaturan profil autoscaler kluster di seluruh kluster dan diterapkan ke semua kumpulan simpul berkemampuan skala otomatis. Setiap tindakan penskalaan yang terjadi dalam satu kumpulan simpul dapat memengaruhi perilaku penskalaan otomatis kumpulan simpul lain, yang dapat menyebabkan hasil yang tidak terduga. Pastikan Anda menerapkan konfigurasi profil yang konsisten dan disinkronkan di semua kumpulan simpul yang relevan untuk memastikan Anda mendapatkan hasil yang Anda inginkan.
Contoh 1: Mengoptimalkan performa
Untuk kluster yang menangani beban kerja yang substansial dan bursty dengan fokus utama pada performa, sebaiknya tingkatkan scan-interval dan kurangi scale-down-utilization-threshold. Pengaturan ini membantu mengumpulkan beberapa operasi penskalaan ke dalam satu panggilan, mengoptimalkan waktu penskalaan dan pemanfaatan kuota baca/tulis komputasi. Ini juga membantu mengurangi risiko operasi penurunan skala cepat pada simpul yang kurang digunakan, meningkatkan efisiensi penjadwalan pod. Juga tingkatkan ok-total-unready-countdan max-total-unready-percentage.
Untuk kluster dengan pod daemonset, sebaiknya atur ignore-daemonset-utilization ke true, yang secara efektif mengabaikan pemanfaatan node oleh pod daemonset dan meminimalkan operasi penurunan skala yang tidak perlu. Lihat profil untuk beban kerja bursty
Contoh 2: Mengoptimalkan biaya
Jika Anda menginginkan profil yang dioptimalkan biaya, sebaiknya atur konfigurasi parameter berikut:
- Kurangi
scale-down-unneeded-time, yang merupakan jumlah waktu simpul harus tidak diperlukan sebelum memenuhi syarat untuk menurunkan skala. - Kurangi
scale-down-delay-after-add, yang merupakan jumlah waktu untuk menunggu setelah node ditambahkan sebelum mempertimbangkannya untuk menurunkan skala. - Tingkatkan
scale-down-utilization-threshold, yang merupakan ambang pemanfaatan untuk menghapus simpul. - Tingkatkan
max-empty-bulk-delete, yang merupakan jumlah maksimum simpul yang dapat dihapus dalam satu panggilan. - Atur
skip-nodes-with-local-storageke false. - Tingkatkan
ok-total-unready-countdanmax-total-unready-percentage
Masalah umum dan rekomendasi mitigasi
Lihat kegagalan penskalan dan peningkatan skala tidak memicu peristiwa melalui CLI atau Portal.
Tidak memicu operasi peningkatan skala
| Penyebab umum | Rekomendasi mitigasi |
|---|---|
| Konflik afinitas simpul PersistentVolume, yang dapat muncul saat menggunakan autoscaler kluster dengan beberapa zona ketersediaan atau ketika zona volume pod atau persisten berbeda dari zona simpul. | Gunakan satu kumpulan simpul per zona ketersediaan dan aktifkan --balance-similar-node-groups. Anda juga dapat mengatur volumeBindingMode bidang ke WaitForFirstConsumer dalam spesifikasi pod untuk mencegah volume terikat ke node hingga pod yang menggunakan volume dibuat. |
| Konflik taint dan Toleransi/Afinitas node | Nilai taint yang ditetapkan ke simpul Anda dan tinjau toleransi yang ditentukan dalam pod Anda. Jika perlu, buat penyesuaian pada taint dan toleransi untuk memastikan bahwa pod Anda dapat dijadwalkan secara efisien pada simpul Anda. |
Meningkatkan kegagalan operasi
| Penyebab umum | Rekomendasi mitigasi |
|---|---|
| Kelelahan alamat IP di subnet | Tambahkan subnet lain di jaringan virtual yang sama dan tambahkan kumpulan simpul lain ke subnet baru. |
| Kelelahan kuota inti | Kuota inti yang disetujui telah habis. Minta penambahan kuota. Autoscaler kluster memasuki status backoff eksponensial dalam grup simpul tertentu ketika mengalami beberapa upaya peningkatan skala yang gagal. |
| Ukuran maksimum kumpulan simpul | Tingkatkan simpul maks pada kumpulan simpul atau buat kumpulan simpul baru. |
| Permintaan/Panggilan melebihi batas tarif | Lihat Kesalahan 429 Terlalu Banyak Permintaan. |
Kegagalan operasi penurunan skala
| Penyebab umum | Rekomendasi mitigasi |
|---|---|
| Pod mencegah pengurasan node/Tidak dapat mengeluarkan pod | • Lihat jenis pod apa yang dapat mencegah penurunan skala. • Untuk pod yang menggunakan penyimpanan lokal, seperti hostPath dan emptyDir, atur bendera skip-nodes-with-local-storage profil autoscaler kluster ke false. • Dalam spesifikasi pod, atur cluster-autoscaler.kubernetes.io/safe-to-evict anotasi ke true. • Periksa PDB Anda, karena mungkin ketat. |
| Ukuran minimum kumpulan simpul | Kurangi ukuran minimum kumpulan simpul. |
| Permintaan/Panggilan melebihi batas tarif | Lihat Kesalahan 429 Terlalu Banyak Permintaan. |
| Operasi tulis terkunci | Jangan membuat perubahan apa pun pada grup sumber daya AKS yang dikelola sepenuhnya (lihat kebijakan dukungan AKS). Hapus atau reset kunci sumber daya apa pun yang sebelumnya Anda terapkan ke grup sumber daya. |
Masalah Lain
| Penyebab umum | Rekomendasi mitigasi |
|---|---|
| PriorityConfigMapNotMatchedGroup | Pastikan Anda menambahkan semua grup simpul yang memerlukan penskalaan otomatis ke file konfigurasi expander. |
Kumpulan simpul di backoff
Kumpulan simpul di backoff diperkenalkan dalam versi 0.6.2 dan menyebabkan autoscaler kluster mundur dari penskalakan kumpulan simpul setelah kegagalan.
Bergantung pada berapa lama operasi penskalakan mengalami kegagalan, mungkin perlu waktu hingga 30 menit sebelum melakukan upaya lain. Anda dapat mengatur ulang status backoff kumpulan simpul dengan menonaktifkan lalu mengaktifkan kembali penskalaan otomatis.