Artikel ini memberikan jawaban ke beberapa pertanyaan yang sangat umum tentang cara menjalankan Microsoft Azure HDInsight.
Membuat atau menghapus kluster Microsoft Azure HDInsight
Bagaimana cara provisikan kluster Microsoft Azure HDInsight?
Untuk meninjau jenis kluster Microsoft Azure HDInsight, dan metode provisi, lihat Siapkan kluster di Microsoft Azure HDInsight dengan Apache Hadoop, Apache Spark, Apache Kafka, dan banyak lagi.
Bagaimana cara menghapus kluster Microsoft Azure HDInsight yang ada?
Untuk mempelajari selengkapnya tentang menghapus kluster saat tidak lagi digunakan, lihat Hapus kluster Microsoft Azure HDInsight.
Cobalah untuk meninggalkan setidaknya 30 hingga 60 menit antara operasi buat dan hapus. Jika tidak, operasi mungkin gagal dengan pesan kesalahan berikut:
Conflict (HTTP Status Code: 409) error when attempting to delete a cluster immediately after creation of a cluster. If you encounter this error, wait until the newly created cluster is in operational state before attempting to delete it.
Bagaimana cara memilih jumlah inti atau simpul yang benar untuk beban kerja saya?
Jumlah inti dan opsi konfigurasi lainnya yang sesuai tergantung pada berbagai faktor.
Untuk informasi selengkapnya, lihat Perencanaan kapasitas untuk kluster Microsoft Azure HDInsight.
Apa saja jenis simpul dalam kluster Microsoft Azure HDInsight?
Apa saja praktik terbaik untuk membuat kluster Microsoft Azure HDInsight besar?
- Sarankan untuk menyiapkan kluster Microsoft Azure HDInsight dengan DB Ambari Kustom untuk meningkatkan skalabilitas kluster.
- Gunakan Azure Data Lake Storage Gen2 untuk membuat kluster Microsoft Azure HDInsight untuk memanfaatkan bandwidth yang lebih tinggi dan karakteristik kinerja Azure Data Lake Storage Gen2 lainnya.
- Headnodes harus cukup besar untuk mengakomodasi beberapa layanan master yang berjalan pada simpul ini.
- Beberapa beban kerja tertentu seperti Interactive Query juga akan membutuhkan simpul Zookeeper yang lebih besar. Harap pertimbangkan minimal delapan VM inti.
- Dalam kasus Apache Hive dan Spark, gunakan metastore Apache Hive Eksternal.
Komponen Individu
Dapatkah saya memasang komponen tambahan pada kluster saya?
Ya. Untuk memasang komponen tambahan atau menyesuaikan konfigurasi kluster, gunakan:
Skrip selama atau setelah pembuatan. Skrip dipanggil melalui tindakan skrip. Tindakan skrip adalah opsi konfigurasi yang dapat Anda gunakan dari portal Microsoft Azure, cmdlet HDInsight Windows PowerShell, atau Microsoft Azure HDInsight .NET SDK. Opsi konfigurasi ini dapat digunakan dari portal Microsoft Azure, cmdlet Microsoft Azure HDInsight Windows PowerShell, atau Microsoft Azure HDInsight .NET SDK.
Platform Aplikasi Microsoft Azure HDInsight untuk memasang aplikasi.
Untuk daftar komponen yang didukung, lihat Apa saja komponen dan versi Apache Hadoop yang tersedia di Microsoft Azure HDInsight?
Dapatkah saya meningkatkan komponen individual yang telah dipasang sebelumnya pada kluster?
Jika Anda meningkatkan komponen atau aplikasi bawaan yang telah dipasang sebelumnya di kluster, konfigurasi yang dihasilkan tidak akan didukung oleh Microsoft. Konfigurasi sistem ini belum diuji oleh Microsoft. Cobalah untuk menggunakan versi berbeda dari kluster Microsoft Azure HDInsight yang mungkin sudah memiliki versi peningkatan dari komponen yang telah dipasang sebelumnya.
Misalnya, meningkatkan Apache Hive sebagai komponen individual tidak didukung. Microsoft Azure HDInsight adalah layanan terkelola, dan banyak layanan terintegrasi dengan server Ambari dan diuji. Meningkatkan Apache Hive sendiri menyebabkan biner terindeks komponen lain berubah, dan akan menyebabkan masalah integrasi komponen pada kluster Anda.
Dapatkah Spark dan Kafka berjalan pada kluster Microsoft Azure HDInsight yang sama?
Tidak, Hal itu tidak mungkin untuk menjalankan Apache Kafka dan Apache Spark pada kluster Microsoft Azure HDInsight yang sama. Membuat kluster terpisah untuk Kafka dan Spark untuk menghindari masalah pertikaian sumber daya.
Bagaimana cara mengubah zona waktu di Ambari?
Buka Ambari Web UI di
https://CLUSTERNAME.azurehdinsight.net, di mana CLUSTERNAME adalah nama kluster Anda.Di sudut kanan atas, pilih admin I Pengaturan.
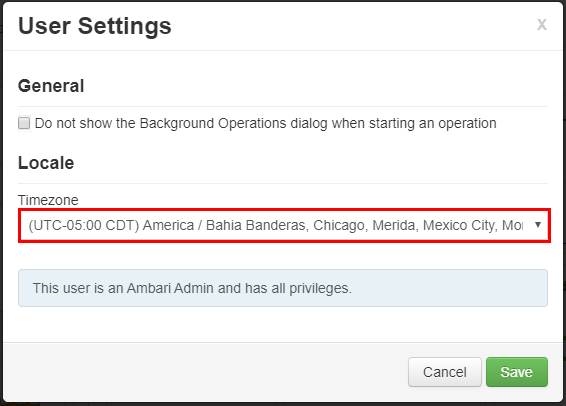
Di jendela Pengaturan Pengguna, pilih zona waktu baru dari turun bawah Zona Waktu, lalu klik Simpan.
Metastore
Bagaimana cara melakukan migrasi dari metastore yang sudah ada ke Azure SQL Database?
Untuk melakukan migrasi dari SQL Server ke Azure SQL Database, lihat Tutorial: Migrasikan SQL Server ke database tunggal atau database yang dikumpulan di Azure SQL Database offline menggunakan DMS.
Apakah metastore Apache Hive dihapus saat kluster dihapus?
Hal itu tergantung pada jenis metastore yang dikonfigurasi kluster Anda untuk digunakan.
Untuk metastore default: Metastore default adalah bagian dari siklus hidup kluster. Saat Anda menghapus kluster, metastore dan metadata yang sesuai juga akan dihapus.
Untuk metastore kustom: Siklus hidup metastore tidak terikat pada siklus hidup kluster. Jadi, Anda dapat membuat dan menghapus kluster tanpa kehilangan metadata. Metadata seperti skema Apache Hive Anda tetap ada bahkan setelah Anda menghapus dan membuat ulang kluster Microsoft Azure HDInsight.
Untuk mengetahui informasi selengkapnya, lihat Menggunakan penyimpanan metadata eksternal di Azure HDInsight.
Apakah migrasi metastore Apache Hive juga memigrasikan kebijakan default database Ranger?
Tidak, definisi kebijakan ada di database Ranger, jadi migrasi database Ranger akan memigrasikan kebijakannya.
Dapatkah Anda memigrasikan metastore Apache Hive dari klaster Paket Keamanan Perusahaan (ESP) ke kluster non-ESP, dan sebaliknya?
Ya, Anda dapat memigrasikan metastore Apache Hive dari ESP ke kluster non-ESP.
Bagaimana cara memperkirakan ukuran database metastore Apache Hive?
Metastore Apache Hive digunakan untuk menyimpan metadata untuk sumber data yang digunakan oleh server Apache Hive. Persyaratan ukuran sebagian tergantung pada jumlah dan kompleksitas sumber data Apache Hive Anda. Item ini tidak dapat diperkirakan di depan. Seperti yang diuraikan dalam pedoman metastore Apache Hive, Anda dapat memulai dengan tingkat S2. Tingkat ini menyediakan penyimpanan 50 DTU dan 250 GB, dan jika Anda melihat penyempitan, menskalakan database.
Apakah Anda mendukung database lain selain Azure SQL Database sebagai metastore eksternal?
Tidak, Microsoft hanya mendukung Azure SQL Database sebagai metastore kustom eksternal.
Dapatkah saya berbagi metastore di beberapa kluster?
Ya, Anda dapat berbagi metastore khusus di beberapa kluster selama mereka menggunakan versi Microsoft Azure HDInsight yang sama.
Konektivitas dan Virtual Networks
Apa implikasi dari memblokir port 22 dan 23 di jaringan saya?
Jika Anda memblokir port 22 dan port 23, Anda tidak akan memiliki akses SSH ke kluster. Port ini tidak digunakan oleh layanan Microsoft Azure HDInsight.
Untuk informasi selengkapnya, lihat dokumen berikut:
Dapatkah saya menggunakan mesin virtual tambahan dalam subnet yang sama dengan kluster Microsoft Azure HDInsight?
Ya, Anda dapat menyebarkan mesin virtual tambahan dalam subnet yang sama dengan kluster Microsoft Azure HDInsight. Konfigurasi berikut dimungkinkan:
Simpul Azure Stack Edge: Anda dapat menambahkan simpul tepi lain ke kluster, seperti yang dijelaskan dalam Gunakan simpul tepi kosong pada kluster Apache Hadoop di Microsoft Azure HDInsight.
Node mandiri: Anda dapat menambahkan mesin virtual mandiri ke subnet yang sama dan mengakses kluster dari mesin virtual itu dengan menggunakan titik akhir pribadi
https://<CLUSTERNAME>-int.azurehdinsight.net. Untuk informasi selengkapnya, lihat Kontrol lalu lintas jaringan.
Haruskah saya menyimpan data pada disk lokal dari simpul tepi?
Tidak, menyimpan data pada disk lokal bukanlah ide yang baik. Jika simpul gagal, semua data yang disimpan secara lokal akan hilang. Sebaiknya menyimpan data di penyimpanan Azure Data Lake Storage Gen2 atau Azure Blob, atau dengan memasang berbagi Azure Files untuk menyimpan data.
Dapatkah saya menambahkan kluster Microsoft Azure HDInsight yang ada ke jaringan virtual lain?
Tidak, Anda tidak bisa. Jaringan virtual harus ditentukan pada saat provisi. Jika tidak ada jaringan virtual yang ditentukan selama provisi, penyebaran akan membuat jaringan internal yang tidak dapat diakses dari luar. Untuk informasi selengkapnya, lihat Tambahkan Microsoft Azure HDInsight ke bagian jaringan virtual yang ada.
Keamanan dan Sertifikat
Apa saja rekomendasi untuk perlindungan malware pada kluster Microsoft Azure HDInsight?
Untuk informasi tentang perlindungan malware, lihat Microsoft Antimalware untuk Azure Cloud Services dan Mesin Virtual.
Bagaimana cara membuat tab kunci untuk kluster Microsoft Azure HDInsight ESP?
Buat tab kunci Kerberos untuk nama pengguna domain Anda. Anda nantinya dapat menggunakan tab kunci ini untuk mengautentikasi ke kluster yang bergabung dengan domain jarak jauh tanpa memasukkan kata sandi. Nama domainnya adalah huruf besar:
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
Kapan salting diperlukan untuk enkripsi AES256 saat membuat keytab?
Jika TenantName & DomainName Anda berbeda (contoh TenantName – bob@CONTOSO.ONMICROSOFT.COM & DomainName – bob@CONTOSOMicrosoft.ONMICROSOFT.COM), Anda perlu menambahkan nilai SALT menggunakan opsi -s.
Bagaimana cara menentukan nilai SALT yang tepat?
- Gunakan login Kerberos interaktif untuk menentukan nilai garam yang tepat untuk keytab. Login Kerberos interaktif akan menggunakan enkripsi tertinggi secara default. Pelacakan harus diaktifkan untuk mengamati garam. Di bawah ini adalah contoh login Kerberos:
$ KRB5_TRAACE=/dev/stdout kinit <username> -V
- Lihat output untuk garam "......." Baris.
- Gunakan nilai garam ini saat membuat keytab.
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96 -s <SALTvalue>
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
Dapatkah saya menggunakan penyewa Microsoft Entra yang ada untuk membuat kluster HDInsight yang memiliki ESP?
Aktifkan Microsoft Entra Domain Services sebelum Anda dapat membuat kluster HDInsight dengan ESP. Hadoop sumber terbuka mengandalkan Kerberos untuk Autentikasi (dibandingkan dengan OAuth).
Untuk bergabung dengan VM ke domain, Anda harus memiliki pengontrol domain. Microsoft Entra Domain Services adalah pengontrol domain terkelola, dan dianggap sebagai ekstensi ID Microsoft Entra. Microsoft Entra Domain Services menyediakan semua persyaratan Kerberos untuk membangun kluster Hadoop yang aman dengan cara terkelola. HDInsight sebagai layanan terkelola terintegrasi dengan Microsoft Entra Domain Services untuk memberikan keamanan.
Dapatkah saya menggunakan sertifikat yang ditandatangani sendiri dalam penyiapan LDAP aman Microsoft Entra Domain Services dan menyediakan kluster ESP?
Direkomendasikan menggunakan sertifikat yang dikeluarkan oleh otoritas sertifikat. Tetapi menggunakan sertifikat yang ditandatangani sendiri juga didukung di ESP. Untuk informasi selengkapnya, lihat:
Dapatkah saya menginstal Data Analytics Studio (DAS) sebagai kluster ESP?
Tidak, DAS tidak didukung pada kluster ESP.
Bagaimana cara menarik aktivitas login yang ditampilkan di Ranger?
Untuk persyaratan audit, Microsoft merekomendasikan untuk mengaktifkan log Azure Monitor seperti yang dijelaskan dalam log Gunakan Azure Monitor untuk memantau kluster Microsoft Azure HDInsight.
Dapatkah saya menonaktifkan `Clamscan` pada kluster saya?
Clamscan adalah perangkat lunak antivirus yang berjalan pada kluster Microsoft Azure HDInsight dan digunakan oleh keamanan Azure (azsecd) untuk melindungi kluster Anda dari serangan virus. Microsoft sangat menyarankan agar pengguna menahan diri untuk tidak membuat perubahan apa pun pada konfigurasi Clamscan default.
Proses ini tidak mengganggu atau mengambil siklus apa pun dari proses lain. Ini akan selalu menghasilkan proses lain. Lonjakan CPU dari Clamscan harus dilihat hanya ketika sistem diam.
Dalam skenario di mana Anda harus mengontrol jadwal, Anda bisa menggunakan langkah-langkah berikut:
Nonaktifkan eksekusi otomatis menggunakan perintah berikut:
sudo
usr/local/bin/azsecd config -s clamav -d Disabledsudo layanan azsecd restartTambahkan pekerjaan Cron yang menjalankan perintah berikut sebagai root:
/usr/local/bin/azsecd manual -s clamav
Untuk informasi selengkapnya tentang cara mengatur dan menjalankan pekerjaan cron, lihat Bagaimana cara menyiapkan pekerjaan Cron?
Mengapa LLAP tersedia di kluster Spark ESP?
LLAP diaktifkan karena alasan keamanan (Apache Ranger), bukan performa. Gunakan simpul VM yang lebih besar untuk mengakomodasi penggunaan sumber daya LLAP (misalnya, minimum D13V2).
Bagaimana cara menambahkan grup Microsoft Entra tambahan setelah membuat kluster ESP?
Ada dua cara untuk mencapai tujuan ini: 1- Anda dapat membuat ulang kluster dan menambahkan grup tambahan pada saat pembuatan kluster. Jika Anda menggunakan sinkronisasi tercakup di Microsoft Entra Domain Services, pastikan grup B disertakan dalam sinkronisasi tercakup.
2- Tambahkan grup sebagai subkelompok bertumpuk dari grup sebelumnya yang digunakan untuk membuat kluster ESP. Misalnya, jika Anda telah membuat kluster ESP dengan grup A, Anda nantinya dapat menambahkan grup B sebagai subkelompok bertumpuk A dan setelah sekitar satu jam akan disinkronkan dan tersedia di kluster secara otomatis.
Penyimpanan
Bisakah saya menambahkan Azure Data Lake Storage Gen2 ke kluster Microsoft Azure HDInsight yang ada sebagai akun penyimpanan tambahan?
Tidak, saat ini tidak dimungkinkan untuk menambahkan akun penyimpanan Azure Data Lake Storage Gen2 ke kluster yang memiliki penyimpanan blob sebagai penyimpanan utamanya. Untuk informasi selengkapnya, lihat Membandingkan opsi penyimpanan.
Bagaimana cara menemukan Perwakilan layanan yang saat ini ditautkan untuk akun penyimpanan Data Lake?
Anda dapat menemukan pengaturan Anda di akses Data Lake Storage Gen1 di bawah properti kluster Anda di portal Microsoft Azure. Untuk informasi selengkapnya, lihat Verifikasi pengaturan kluster.
Bagaimana cara menghitung penggunaan akun penyimpanan dan kontainer gumpalan untuk kluster Microsoft Azure HDInsight saya?
Lakukan salah satu tindakan berikut:
Temukan ukuran /user/hive/.Trash/ pada kluster Microsoft Azure HDInsight, menggunakan baris perintah berikut:
hdfs dfs -du -h /user/hive/.Trash/
Bagaimana cara menyiapkan audit untuk akun penyimpanan blob saya?
Untuk mengaudit akun penyimpanan blob, konfigurasikan pemantauan menggunakan prosedur di Monitor akun penyimpanan di portal Microsoft Azure. Log audit HDFS hanya menyediakan informasi audit untuk sistem berkas HDFS lokal saja (hdfs://mycluster). Ini tidak termasuk operasi yang dilakukan pada penyimpanan jarak jauh.
Bagaimana cara mentransfer file antara kontainer gumpalan dan simpul kepala Microsoft Azure HDInsight?
Jalankan skrip yang mirip dengan skrip shell berikut pada simpul kepala Anda:
for i in cat filenames.txt
do
hadoop fs -get $i <local destination>
done
Catatan
File filenames.txt akan memiliki jalur absolut file dalam kontainer blob.
Apakah ada plugin Ranger untuk penyimpanan?
Saat ini, tidak ada plugin Ranger untuk penyimpanan blob dan Azure Data Lake Storage Gen1 atau Gen2. Untuk kluster ESP, Anda harus menggunakan Azure Data Lake Storage. Anda setidaknya dapat mengatur izin halus secara manual di tingkat sistem file menggunakan alat HDFS. Selain itu, saat menggunakan Azure Data Lake Storage, kluster ESP akan melakukan beberapa kontrol akses sistem file menggunakan ID Microsoft Entra di tingkat kluster.
Anda dapat menetapkan kebijakan akses data ke grup keamanan pengguna dengan menggunakan Azure Storage Explorer. Untuk informasi selengkapnya, lihat:
Dapatkah saya meningkatkan penyimpanan HDFS pada kluster tanpa meningkatkan ukuran disk simpul pekerja?
Tidak. Anda tidak dapat meningkatkan ukuran disk simpul pekerja apa pun. Jadi satu-satunya cara untuk meningkatkan ukuran disk adalah dengan menjatuhkan kluster dan membuatnya kembali dengan VM pekerja yang lebih besar. Jangan gunakan HDFS untuk menyimpan data Microsoft Azure HDInsight Anda, karena data akan dihapus jika Anda menghapus kluster. Sebagai gantinya, simpan data Anda di Microsoft Azure. Tingkatkan kluster juga dapat menambahkan kapasitas tambahan ke kluster Microsoft Azure HDInsight Anda.
Simpul Azure Stack Edge
Dapatkah saya menambahkan simpul tepi setelah kluster dibuat?
Bagaimana cara menyambungkan ke simpul tepi?
Setelah membuat simpul tepi, Anda dapat terhubung dengan SSH pada port 22. Anda dapat menemukan nama simpul tepi dari portal kluster. Nama-nama biasanya berakhir dengan -ed.
Mengapa skrip bertahan tidak berjalan secara otomatis pada simpul tepi yang baru dibuat?
Anda menggunakan skrip bertahan untuk menyesuaikan simpul pekerja baru yang ditambahkan ke klaster melalui operasi penskalaan. Skrip bertahan tidak berlaku untuk simpul tepi.
REST API
Apa saja panggilan REST API untuk menarik tampilan kueri Tez dari kluster?
Anda dapat menggunakan titik akhir REST berikut untuk menarik informasi yang diperlukan dalam format JavaScript Object Notation. Gunakan header autentikasi dasar untuk membuat permintaan.
Tez Query View: https://<cluster name>.azurehdinsight.net/ws/v1/timeline/HIVE_QUERY_ID/Tez Dag View: https://<cluster name>.azurehdinsight.net/ws/v1/timeline/TEZ_DAG_ID/
Bagaimana cara mengambil detail konfigurasi dari kluster HDI dengan menggunakan pengguna Microsoft Entra?
Untuk menegosiasikan token autentikasi yang tepat dengan pengguna Microsoft Entra Anda, buka gateway dengan menggunakan format berikut:
- https://
<cluster dnsname>.azurehdinsight.net/api/v1/clusters/testclusterdem/stack_versions/1/repository_versions/1
Bagaimana cara menggunakan RESTful Ambari untuk memantau performa YARN?
Jika Anda memanggil perintah Curl di jaringan virtual yang sama atau jaringan virtual yang disaingi, perintahnya adalah:
curl -u <cluster login username> -sS -G
http://<headnodehost>:8080/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
Jika Anda memanggil perintah dari luar jaringan virtual atau dari jaringan virtual yang tidak di-peering, format perintahnya adalah:
Untuk kluster non-ESP:
curl -u <cluster login username> -sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpuUntuk kluster ESP:
curl -u <cluster login username>-sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
Catatan
Curl meminta kata sandi kepada Anda. Anda harus memasukkan kata sandi yang valid untuk nama pengguna log masuk kluster.
Billing
Berapa biaya untuk menyebarkan kluster Microsoft Azure HDInsight?
Untuk informasi selengkapnya tentang harga dan FAQ yang terkait dengan tagihan, lihat halaman Harga Azure Microsoft Azure HDInsight.
Kapan penagihan Microsoft Azure HDInsight mulai & berhenti?
Tagihan klaster HDInsight mulai dihitung setelah klaster dibuat dan akan berhenti saat klaster dihapus. Penagihan dipro rata per menit.
Bagaimana cara membatalkan langganan saya?
Untuk informasi tentang cara membatalkan langganan Anda, lihat Batalkan langganan Azure Anda.
Untuk langganan berbayar sesuai biaya, apa yang terjadi setelah saya membatalkan langganan saya?
Untuk informasi tentang langganan Anda setelah dibatalkan, lihat Apa yang terjadi setelah saya membatalkan langganan saya?
Hive
Mengapa versi Apache Hive muncul sebagai 1.2.1000 alih-alih 2.1 di UI Ambari meskipun saya menjalankan kluster Microsoft Azure HDInsight 3.6?
Meskipun hanya 1,2 yang muncul di UI Ambari, Microsoft Azure HDInsight 3.6 mengandung Apache Hive 1.2 dan Hive 2.1.
FAQ Lainnya
Apa yang ditawarkan Microsoft Azure HDInsight untuk kemampuan pemrosesan streaming real-time?
Untuk informasi tentang kemampuan integrasi pemrosesan streaming, lihat Memilih teknologi pemrosesan streaming di Azure.
Apakah ada cara untuk secara dinamis membunuh simpul kepala kluster ketika kluster diam untuk periode tertentu?
Anda tidak dapat melakukan tindakan ini dengan kluster Microsoft Azure HDInsight. Anda dapat menggunakan Azure Data Factory untuk skenario ini.
Penawaran kepatuhan apa yang ditawarkan Microsoft Azure HDInsight?
Untuk informasi kepatuhan, lihat Pusat Kepercayaan Microsoft.