Migrasikan kluster Microsoft Azure HDInsight ke versi yang lebih baru
Untuk memanfaatkan fitur Microsoft Azure HDInsight terbaru, kami menyarankan agar kluster Microsoft Azure HDInsight secara teratur dimigrasikan ke versi terbaru. Microsoft Azure HDInsight tidak mendukung peningkatan di tempat di mana kluster yang ada ditingkatkan ke versi komponen yang lebih baru. Anda harus membuat kluster baru dengan komponen dan versi platform yang diinginkan dan kemudian memigrasikan aplikasi Anda untuk menggunakan kluster baru. Ikuti panduan di bawah ini untuk memigrasikan versi kluster Microsoft Azure HDInsight Anda.
Catatan
Jika Anda membuat kluster Apache Hive dengan kontainer penyimpanan utama, salin dari kluster HDInsight yang ada. Jangan salin konten lengkap. Salin hanya folder data yang dikonfigurasi.
Tugas migrasi
Alur kerja untuk memutakhirkan Kluster Microsoft Azure HDInsight adalah sebagai berikut.
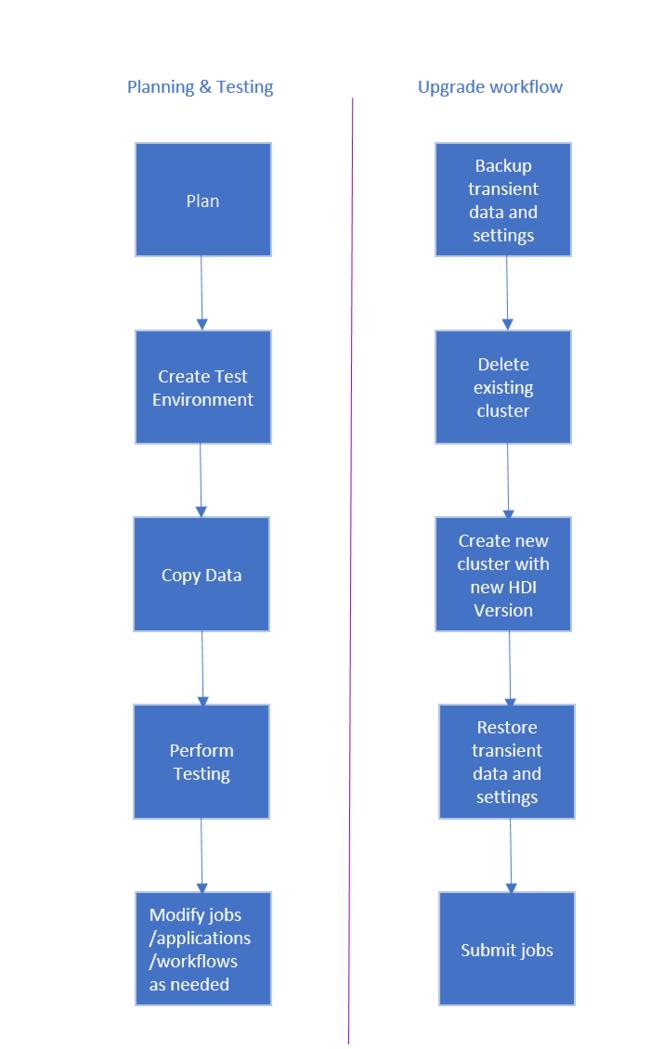
- Baca setiap bagian dari dokumen ini untuk memahami perubahan yang mungkin diperlukan saat memutakhirkan kluster Microsoft Azure HDInsight Anda.
- Buat kluster sebagai lingkungan uji/jaminan mutu. Untuk informasi selengkapnya tentang membuat kluster, lihat Mempelajari cara membuat kluster Microsoft Azure HDInsight berbasis Linux
- Salin pekerjaan, sumber data, dan wastafel yang ada ke lingkungan baru.
- Lakukan pengujian validasi untuk memastikan bahwa pekerjaan Anda berfungsi seperti yang diharapkan pada kluster baru.
Setelah Anda memverifikasi bahwa semuanya berfungsi seperti yang diharapkan, jadwalkan waktu henti untuk migrasi. Selama waktu henti ini, lakukan tindakan berikut:
- Cadangkan data sementara yang disimpan secara lokal pada node kluster. Misalnya, jika Anda memiliki data yang disimpan langsung pada node masuk.
- Hapus kluster yang sudah ada.
- Membuat kluster di subnet VNET yang sama dengan versi IPM terbaru (atau didukung) menggunakan penyimpanan data default yang sama dengan kluster sebelumnya yang digunakan. Hal ini memungkinkan kluster baru untuk terus bekerja melawan data produksi Anda yang ada.
- Mengimpor data sementara yang Anda cadangkan.
- Mulai tugas/lanjutkan pemrosesan menggunakan kluster baru.
Panduan spesifik beban kerja
Dokumen berikut ini menyediakan panduan tentang cara melakukan migrasi beban kerja tertentu:
Mencadangkan dan memulihkan
Untuk informasi selengkapnya tentang pencadangan dan pemulihan database, lihat Memulihkan database di Azure SQL Database dengan menggunakan pencadangan database otomatis.
Meningkatkan skenario
Seperti yang disebutkan di atas, Microsoft menyarankan agar kluster HDInsight secara teratur dimigrasikan ke versi terbaru untuk memanfaatkan fitur dan perbaikan baru. Lihat daftar alasan kami meminta agar kluster dihapus dan disebarkan kembali:
- Versi kluster Dihentikan atau jika Anda mengalami masalah kluster yang akan diselesaikan dengan versi yang lebih baru.
- Akar penyebab masalah kluster ditentukan untuk menghubungkan mesin virtual yang berukuran kecil. Lihat konfigurasi node yang disarankan Microsoft.
- Pelanggan membuka kasus dukungan dan tim teknisi Microsoft menentukan masalah ini telah diperbaiki dalam versi kluster yang lebih baru.
- Database metastore default (Ambari, Apache Hive, Oozie, Ranger) telah mencapai batas penggunaannya. Microsoft meminta Anda untuk membuat ulang kluster menggunakan database metastore kustom.
- Akar penyebab masalah kluster adalah karena Operasi yang Tidak Didukung. Berikut adalah beberapa operasi umum yang tidak didukung:
- Memindahkan atau Menambahkan layanan di Ambari. Saat melihat informasi tentang layanan kluster di Ambari, salah satu tindakan yang tersedia dari menu Tindakan Layanan adalah Pindahkan [Nama Layanan]. Tindakan lainnya adalah Tambahkan [Nama Layanan]. Kedua opsi ini tidak didukung.
- Korupsi paket Python. Kluster HDInsight bergantung pada lingkungan Python bawaan, Python 2.7 dan Python 3.5. Langsung menginstal paket kustom di lingkungan bawaan default tersebut dapat menyebabkan perubahan versi pustaka yang tidak terduga dan merusak kluster. Pelajari cara menginstal paket Python eksternal kustom dengan aman untuk aplikasi Spark Anda.
- Perangkat lunak pihak ketiga. Pelanggan memiliki kemampuan untuk menginstal perangkat lunak pihak ketiga pada kluster Azure HDInsight mereka; namun, kami akan menyarankan untuk membuat ulang kluster jika merusak fungsi yang ada.
- Beberapa beban kerja pada kluster yang sama. Dalam HDInsight 4.0, Hive Warehouse Connector membutuhkan kluster terpisah untuk beban kerja Spark dan Interactive Query. Ikuti langkah-langkah ini untuk mengatur kedua kluster di Azure HDInsight. Demikian juga, mengintegrasikan Spark dengan HBASE membutuhkan 2 kluster yang berbeda.
- Kata sandi Ambari DB kustom berubah. Kata sandi Ambari DB diatur selama pembuatan kluster dan tidak ada mekanisme saat ini untuk memperbaruinya. Jika pelanggan menyebarkan kluster dengan Ambari DB kustom, mereka memiliki kemampuan untuk mengubah kata sandi DB pada SQL DB; namun, tidak ada cara untuk memperbarui kata sandi ini untuk kluster HDInsight yang sedang berjalan.
- Memodifikasi HdInsight Load Balancer. Load balancer HDInsight yang secara otomatis disebarkan untuk akses Ambari dan SSH tidak boleh dimodifikasi atau dihapus. Jika Anda memodifikasi load balancer HDInsight dan merusak fungsionalitas kluster, Anda akan disarankan untuk menyebarkan ulang kluster.