Panduan model komposit dalam Power BI Desktop
Artikel ini menargetkan pemodel data yang mengembangkan model komposit Power BI. Ini menjelaskan kasus penggunaan model komposit, dan memberi Anda panduan desain. Secara khusus, panduan ini dapat membantu Anda menentukan apakah model komposit sesuai untuk solusi Anda. Jika ya, maka artikel ini juga akan membantu Anda merancang model dan laporan komposit yang optimal.
Catatan
Pengantar model komposit tidak tercakup dalam artikel ini. Jika Anda tidak sepenuhnya terbiasa dengan model komposit, kami sarankan Anda terlebih dahulu membaca artikel Menggunakan model komposit di Power BI Desktop .
Karena model komposit terdiri dari setidaknya satu sumber DirectQuery, penting juga bahwa Anda memiliki pemahaman menyeluruh tentang hubungan model, model DirectQuery, dan panduan desain model DirectQuery.
Kasus penggunaan model komposit
Menurut definisi, model komposit menggabungkan beberapa grup sumber. Grup sumber dapat mewakili data yang diimpor atau koneksi ke sumber DirectQuery. Sumber DirectQuery dapat berupa database relasional atau model tabular lainnya, yang bisa menjadi model semantik Power BI (sebelumnya dikenal sebagai himpunan data) atau model tabular Analysis Services. Saat model tabular terhubung ke model tabular lain, model ini dikenal sebagai penautan. Untuk informasi selengkapnya, lihat Menggunakan DirectQuery untuk model semantik Power BI dan Analysis Services.
Catatan
Saat model tersambung ke model tabular tetapi tidak memperluasnya dengan data tambahan, model tersebut bukan model komposit. Dalam hal ini, ini adalah model DirectQuery yang terhubung ke model jarak jauh—sehingga hanya terdiri dari satu grup sumber. Anda dapat membuat jenis model ini untuk mengubah properti objek model sumber, seperti nama tabel, urutan pengurutan kolom, atau string format.
Koneksi ke model tabular sangat relevan saat memperluas model semantik perusahaan (saat model semantik Power BI atau model Analysis Services). Model semantik perusahaan sangat mendasar untuk pengembangan dan pengoperasian gudang data. Ini menyediakan lapisan abstraksi atas data di gudang data untuk menyajikan definisi dan terminologi bisnis. Ini umumnya digunakan sebagai tautan antara model data fisik dan alat pelaporan, seperti Power BI. Di sebagian besar organisasi, organisasi dikelola oleh tim pusat, dan itulah sebabnya digambarkan sebagai perusahaan. Untuk informasi selengkapnya, lihat skenario penggunaan BI perusahaan.
Anda dapat mempertimbangkan untuk mengembangkan model komposit dalam situasi berikut.
- Model Anda bisa menjadi model DirectQuery, dan Anda ingin meningkatkan performa. Dalam model komposit, Anda dapat meningkatkan performa dengan menyiapkan penyimpanan yang sesuai untuk setiap tabel. Anda juga dapat menambahkan agregasi yang ditentukan pengguna. Kedua pengoptimalan ini dijelaskan nanti dalam artikel ini.
- Anda ingin menggabungkan model DirectQuery dengan lebih banyak data, yang harus diimpor ke dalam model. Anda dapat memuat data yang diimpor dari sumber data yang berbeda, atau dari tabel terhitung.
- Anda ingin menggabungkan dua atau beberapa sumber data DirectQuery ke dalam satu model. Sumber-sumber ini bisa berupa database relasional atau model tabular lainnya.
Catatan
Model komposit tidak dapat menyertakan koneksi ke database analitik eksternal tertentu. Database ini termasuk SAP Business Warehouse, dan SAP Hana saat memperlakukan SAP Hana sebagai sumber multidmensional.
Mengevaluasi opsi desain model lainnya
Meskipun model komposit Power BI dapat menyelesaikan tantangan desain tertentu, model tersebut dapat berkontribusi pada performa yang lambat. Selain itu, dalam beberapa situasi, hasil perhitungan yang tidak terduga dapat terjadi (dijelaskan nanti dalam artikel ini). Untuk alasan ini, evaluasi opsi desain model lain ketika ada.
Jika memungkinkan, yang terbaik adalah mengembangkan model dalam mode impor. Mode ini memberikan fleksibilitas desain terbesar, dan performa terbaik.
Namun, tantangan yang terkait dengan volume data besar, atau pelaporan pada data mendekati real-time, tidak selalu dapat diselesaikan oleh model impor. Dalam salah satu kasus ini, Anda dapat mempertimbangkan model DirectQuery, menyediakan data Anda disimpan dalam satu sumber data yang didukung oleh mode DirectQuery. Untuk informasi selengkapnya, lihat Model DirectQuery di Power BI Desktop.
Tip
Jika tujuan Anda hanya untuk memperluas model tabular yang ada dengan lebih banyak data, jika memungkinkan, tambahkan data tersebut ke sumber data yang ada.
Mode penyimpanan tabel
Dalam model komposit, Anda dapat mengatur mode penyimpanan untuk setiap tabel (kecuali tabel terhitung).
- DirectQuery: Sebaiknya atur mode ini untuk tabel yang mewakili volume data besar, atau yang perlu memberikan hasil mendekati real-time. Data tidak akan pernah diimpor ke dalam tabel ini. Biasanya, tabel ini akan menjadi tabel jenis fakta, yang merupakan tabel yang dirangkum.
- Impor: Kami menyarankan agar Anda mengatur mode ini untuk tabel yang tidak digunakan untuk pemfilteran dan pengelompokan tabel fakta dalam mode DirectQuery atau Hybrid. Ini juga satu-satunya opsi untuk tabel berdasarkan sumber yang tidak didukung oleh mode DirectQuery. Tabel terhitung selalu mengimpor tabel.
- Ganda: Kami menyarankan agar Anda mengatur mode ini untuk tabel jenis dimensi, ketika ada kemungkinan mereka akan dikueri bersama dengan tabel jenis fakta DirectQuery dari sumber yang sama.
- Hibrid: Kami menyarankan agar Anda mengatur mode ini dengan menambahkan partisi impor, dan satu partisi DirectQuery ke tabel fakta saat Anda ingin menyertakan perubahan data terbaru secara real time, atau ketika Anda ingin memberikan akses cepat ke data yang paling sering digunakan melalui partisi impor sambil meninggalkan sebagian besar data yang jarang digunakan di gudang data.
Ada beberapa skenario yang mungkin saat Power BI meminta model komposit.
- Kueri hanya mengimpor atau tabel ganda): Power BI mengambil semua data dari cache model. Ini akan memberikan performa tercepat yang mungkin. Skenario ini umum untuk tabel jenis dimensi yang dikueri oleh filter atau visual pemotong.
- Kueri tabel ganda atau tabel DirectQuery dari sumber yang sama: Power BI mengambil semua data dengan mengirim satu atau beberapa kueri asli ke sumber DirectQuery. Ini akan memberikan performa yang baik, terutama ketika indeks yang sesuai ada pada tabel sumber. Skenario ini umum untuk kueri yang menghubungkan tabel tipe dimensi ganda dan tabel jenis fakta DirectQuery. Kueri ini adalah grup sumber intra, sehingga semua hubungan satu-ke-satu atau satu-ke-banyak dievaluasi sebagai hubungan reguler.
- Kueri tabel ganda atau tabel hibrid dari sumber yang sama: Skenario ini adalah kombinasi dari dua skenario sebelumnya. Power BI mengambil data dari cache model saat tersedia di partisi impor, jika tidak, Power BI mengirim satu atau beberapa kueri asli ke sumber DirectQuery. Ini akan memberikan performa tercepat yang mungkin karena hanya segudang data yang dikueri di gudang data, terutama ketika indeks yang sesuai ada pada tabel sumber. Adapun tabel jenis dimensi ganda dan tabel jenis fakta DirectQuery, kueri ini adalah grup sumber intra, sehingga semua hubungan satu-ke-satu atau satu-ke-banyak dievaluasi sebagai hubungan reguler.
- Semua kueri lainnya: Kueri ini melibatkan hubungan grup lintas sumber. Ini baik karena tabel impor berkaitan dengan tabel DirectQuery, atau tabel ganda berkaitan dengan tabel DirectQuery dari sumber yang berbeda—dalam hal ini berperilaku sebagai tabel impor. Semua hubungan dievaluasi sebagai hubungan terbatas. Ini juga berarti bahwa pengelompokan yang diterapkan ke tabel non-DirectQuery harus dikirim ke sumber DirectQuery sebagai subkueri materialisasi (tabel virtual). Dalam hal ini, kueri asli bisa tidak efisien, terutama untuk set pengelompokan besar.
Singkatnya, kami sarankan Anda:
- Pertimbangkan dengan cermat bahwa model komposit adalah solusi yang tepat—meskipun memungkinkan integrasi tingkat model dari sumber data yang berbeda, model ini juga memperkenalkan kompleksitas desain dengan kemungkinan konsekuensi (dijelaskan nanti dalam artikel ini).
- Atur mode penyimpanan ke DirectQuery saat tabel adalah tabel jenis fakta yang menyimpan volume data besar, atau saat perlu memberikan hasil mendekati real-time.
- Pertimbangkan untuk menggunakan mode hibrid dengan mendefinisikan kebijakan refresh inkremental dan data real time, atau dengan mempartisi tabel fakta dengan menggunakan TOM, TMSL, atau alat pihak ketiga. Untuk informasi selengkapnya, lihat Refresh bertahap dan data real time untuk model semantik dan skenario penggunaan manajemen model data tingkat lanjut.
- Atur mode penyimpanan ke Dual saat tabel adalah tabel jenis dimensi, dan akan dikueri bersama dengan tabel DirectQuery atau jenis fakta hibrid yang berada dalam grup sumber yang sama.
- Atur frekuensi refresh yang sesuai untuk menjaga cache model untuk tabel ganda dan hibrid (dan tabel terhitung dependen apa pun) sinkron dengan database sumber.
- Berusaha untuk memastikan integritas data di seluruh grup sumber (termasuk cache model) karena hubungan terbatas akan menghilangkan baris dalam hasil kueri saat nilai kolom terkait tidak cocok.
- Jika memungkinkan, optimalkan sumber data DirectQuery dengan indeks yang sesuai untuk gabungan, pemfilteran, dan pengelompokan yang efisien.
Agregasi yang ditentukan pengguna
Anda dapat menambahkan agregasi yang ditentukan pengguna ke tabel DirectQuery. Tujuan mereka adalah untuk meningkatkan performa untuk kueri biji-bijian yang lebih tinggi.
Ketika agregasi di-cache dalam model, agregasi bersifat sebagai tabel impor (meskipun tidak dapat digunakan seperti tabel model). Menambahkan agregasi impor ke model DirectQuery akan menghasilkan model komposit.
Catatan
Tabel hibrid tidak mendukung agregasi karena beberapa partisi beroperasi dalam mode impor. Tidak dimungkinkan untuk menambahkan agregasi pada tingkat partisi DirectQuery individu.
Sebaiknya agregasi mengikuti aturan dasar: Jumlah barisnya harus setidaknya faktor 10 lebih kecil dari tabel yang mendasarinya. Misalnya, jika tabel yang mendasar menyimpan 1 miliar baris, tabel agregasi tidak boleh melebihi 100 juta baris. Aturan ini memastikan bahwa ada perolehan performa yang memadai relatif terhadap biaya pembuatan dan pemeliharaan agregasi.
Hubungan grup sumber lintas
Saat hubungan model mencakup grup sumber, hubungan tersebut dikenal sebagai hubungan grup lintas sumber. Hubungan grup lintas sumber juga merupakan hubungan terbatas karena tidak ada jaminan sisi "satu". Untuk informasi selengkapnya, lihat Evaluasi hubungan.
Catatan
Dalam beberapa situasi, Anda dapat menghindari pembuatan hubungan grup lintas sumber. Lihat topik Gunakan pemotong Sinkronisasi nanti di artikel ini.
Saat menentukan hubungan grup lintas sumber, pertimbangkan rekomendasi berikut.
- Gunakan kolom hubungan kardinalitas rendah: Untuk performa terbaik, sebaiknya kolom hubungan menjadi kardinalitas rendah, yang berarti kolom tersebut harus menyimpan kurang dari 50.000 nilai unik. Rekomendasi ini terutama berlaku saat menggabungkan model tabular, dan untuk kolom non-teks.
- Hindari menggunakan kolom hubungan teks besar: Jika Anda harus menggunakan kolom teks dalam hubungan, hitung panjang teks yang diharapkan untuk filter dengan mengalikan kardinalitas dengan panjang rata-rata kolom teks. Panjang teks yang mungkin tidak boleh melebihi 1.000.000 karakter.
- Tingkatkan granularitas hubungan: Jika memungkinkan, buat hubungan pada tingkat granularitas yang lebih tinggi. Misalnya, alih-alih menghubungkan tabel tanggal pada kunci tanggalnya, gunakan kunci bulannya sebagai gantinya. Pendekatan desain ini mengharuskan tabel terkait menyertakan kolom kunci bulan, dan laporan tidak akan dapat menampilkan fakta harian.
- Berusaha untuk mencapai desain hubungan sederhana: Hanya buat hubungan grup lintas sumber saat diperlukan, dan coba batasi jumlah tabel di jalur hubungan. Pendekatan desain ini akan membantu meningkatkan performa dan menghindari jalur hubungan yang ambigu.
Peringatan
Karena Power BI Desktop tidak memvalidasi hubungan grup lintas sumber secara menyeluruh, dimungkinkan untuk membuat hubungan yang ambigu.
Skenario hubungan grup lintas sumber 1
Pertimbangkan skenario desain hubungan yang kompleks dan bagaimana hal itu dapat menghasilkan hasil yang berbeda—namun valid—.
Dalam skenario ini, tabel Wilayah di grup sumber A memiliki hubungan dengan tabel Tanggal dan tabel Penjualan di grup sumber B. Hubungan antara tabel Wilayah dan tabel Tanggal aktif, sementara hubungan antara tabel Wilayah dan tabel Penjualan tidak aktif. Selain itu, ada hubungan aktif antara tabel Wilayah dan tabel Penjualan , yang keduanya berada di grup sumber B. Tabel Penjualan menyertakan ukuran bernama TotalSales, dan tabel Wilayah menyertakan dua ukuran bernama RegionalSales dan RegionalSalesDirect.
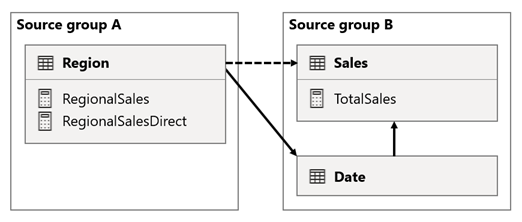
Berikut adalah definisi pengukuran.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Perhatikan bagaimana pengukuran RegionalSales mengacu pada ukuran TotalSales , sementara ukuran RegionalSalesDirect tidak. Sebagai gantinya , pengukuran RegionalSalesDirect menggunakan ekspresi SUM(Sales[Sales]), yang merupakan ekspresi pengukuran TotalSales .
Perbedaan dalam hasilnya halang. Saat Power BI mengevaluasi pengukuran RegionalSales , Power BI menerapkan filter dari tabel Wilayah ke tabel Penjualan dan tabel Tanggal . Oleh karena itu, filter juga menyebar dari tabel Tanggal ke tabel Penjualan . Sebaliknya, saat Power BI mengevaluasi pengukuran RegionalSalesDirect , power BI hanya menyebarluaskan filter dari tabel Wilayah ke tabel Penjualan . Hasil yang dikembalikan oleh pengukuran RegionalSales dan ukuran RegionalSalesDirect dapat berbeda, meskipun ekspresinya setara secara semantik.
Penting
Setiap kali Anda menggunakan CALCULATE fungsi dengan ekspresi yang merupakan ukuran dalam grup sumber jarak jauh, uji hasil perhitungan secara menyeluruh.
Skenario hubungan grup lintas sumber 2
Pertimbangkan skenario ketika hubungan grup lintas sumber memiliki kolom hubungan kardinalitas tinggi.
Dalam skenario ini, tabel Tanggal terkait dengan tabel Penjualan pada kolom DateKey . Jenis data kolom DateKey adalah bilangan bulat, menyimpan bilangan bulat yang menggunakan format yyyymmdd . Tabel milik grup sumber yang berbeda. Selanjutnya, ini adalah hubungan kardinalitas tinggi karena tanggal paling awal dalam tabel Tanggal adalah 1 Januari 1900 dan tanggal terbaru adalah 31 Desember 2100—jadi ada total 73.414 baris dalam tabel (satu baris untuk setiap tanggal dalam rentang waktu 1900-2100).
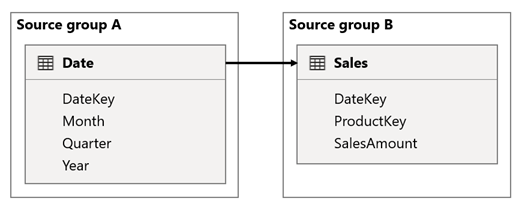
Ada dua kasus yang perlu dikhawatirkan.
Pertama, saat Anda menggunakan kolom tabel Tanggal sebagai filter, penyebaran filter akan memfilter kolom DateKey dari tabel Penjualan untuk mengevaluasi pengukuran. Saat memfilter menurut satu tahun, seperti 2022, kueri DAX akan menyertakan ekspresi filter seperti Sales[DateKey] IN { 20220101, 20220102, …20221231 }. Ukuran teks kueri bisa bertambah menjadi sangat besar ketika jumlah nilai dalam ekspresi filter besar, atau ketika nilai filter adalah string panjang. Sangat mahal bagi Power BI untuk menghasilkan kueri panjang dan agar sumber data dapat menjalankan kueri.
Kedua, saat Anda menggunakan kolom tabel Tanggal —seperti Tahun, Kuartal, atau Bulan—sebagai kolom pengelompokan, kolom tersebut menghasilkan filter yang menyertakan semua kombinasi unik tahun, kuartal, atau bulan, dannilai kolom DateKey . Ukuran string kueri, yang berisi filter pada kolom pengelompokan dan kolom hubungan, bisa menjadi sangat besar. Itu terutama berlaku ketika jumlah kolom pengelompokan dan/atau kardinalitas kolom gabungan ( kolom DateKey ) besar.
Untuk mengatasi masalah performa apa pun, Anda dapat:
- Tambahkan tabel Tanggal ke sumber data, menghasilkan model grup sumber tunggal (artinya, ini bukan lagi model komposit).
- Meningkatkan granularitas hubungan. Misalnya, Anda dapat menambahkan kolom MonthKey ke kedua tabel dan membuat hubungan pada kolom tersebut. Namun, dengan meningkatkan granularitas hubungan, Anda kehilangan kemampuan untuk melaporkan aktivitas penjualan harian (kecuali Anda menggunakan kolom DateKey dari tabel Penjualan ).
Skenario hubungan grup lintas sumber 3
Pertimbangkan skenario saat tidak ada nilai yang cocok antara tabel dalam hubungan grup lintas sumber.
Dalam skenario ini, tabel Tanggal di grup sumber B memiliki hubungan dengan tabel Penjualan di grup sumber tersebut, dan juga ke tabel Target di grup sumber A. Semua hubungan bersifat satu-ke-banyak dari tabel Tanggal yang berkaitan dengan kolom Tahun. Tabel Penjualan menyertakan kolom SalesAmount yang menyimpan jumlah penjualan, sementara tabel Target menyertakan kolom TargetAmount yang menyimpan jumlah target.
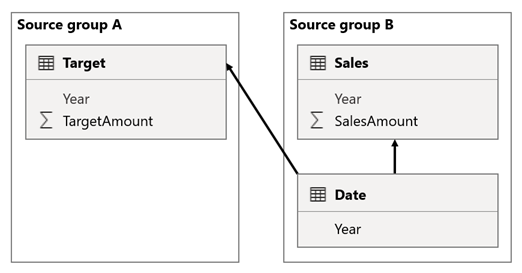
Tabel Tanggal menyimpan tahun 2021 dan 2022. Tabel Penjualan menyimpan jumlah penjualan untuk tahun 2021 (100) dan 2022 (200), sedangkan tabel Target menyimpan jumlah target untuk 2021 (100), 2022 (200), dan 2023 (300)—tahun mendatang.
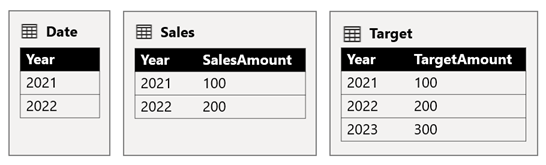
Saat visual tabel Power BI mengkueri model komposit dengan mengelompokkan pada kolom Tahun dari tabel Tanggal dan menjumlahkan kolom SalesAmount dan TargetAmount , itu tidak akan menampilkan jumlah target untuk 2023. Itu karena hubungan grup lintas sumber adalah hubungan terbatas, sehingga menggunakan INNER JOIN semantik, yang menghilangkan baris di mana tidak ada nilai yang cocok di kedua sisi. Namun, ini akan menghasilkan total jumlah target yang benar (600), karena filter tabel Tanggal tidak berlaku untuk evaluasinya.
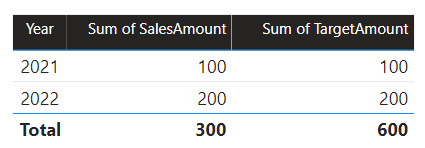
Jika hubungan antara tabel Tanggal dan tabel Target adalah hubungan grup sumber intra (dengan asumsi tabel Target milik grup sumber B), visual akan menyertakan tahun (Kosong) untuk memperlihatkan jumlah target 2023 (dan tahun tidak cocok lainnya).
Penting
Untuk menghindari kesalahanportasi, pastikan bahwa ada nilai yang cocok dalam kolom hubungan saat tabel dimensi dan fakta berada di grup sumber yang berbeda.
Untuk informasi selengkapnya tentang hubungan terbatas, lihat Evaluasi hubungan.
Penghitungan
Anda harus mempertimbangkan batasan tertentu saat menambahkan kolom terhitung dan grup perhitungan ke model komposit.
Kolom terhitung
Kolom terhitung yang ditambahkan ke tabel DirectQuery yang sumber datanya dari database relasional, seperti Microsoft SQL Server, terbatas pada ekspresi yang beroperasi pada satu baris pada satu waktu. Ekspresi ini tidak dapat menggunakan fungsi iterator DAX, seperti SUMX, atau memfilter fungsi modifikasi konteks, seperti CALCULATE.
Catatan
Tidak dimungkinkan untuk menambahkan kolom terhitung atau tabel terhitung yang bergantung pada model tabular berantai.
Ekspresi kolom terhitung pada tabel DirectQuery jarak jauh hanya terbatas pada evaluasi intra-baris. Namun, Anda dapat menulis ekspresi seperti itu, tetapi akan mengakibatkan kesalahan saat digunakan dalam visual. Misalnya, jika Anda menambahkan kolom terhitung ke tabel DirectQuery jarak jauh bernama DimProduct dengan menggunakan ekspresi [Product Sales] / SUM (DimProduct[ProductSales]), Anda akan berhasil menyimpan ekspresi dalam model. Namun, itu akan mengakibatkan kesalahan ketika digunakan dalam visual karena melanggar pembatasan evaluasi intra-baris.
Sebaliknya, kolom terhitung yang ditambahkan ke tabel DirectQuery jarak jauh yang merupakan model tabular, yang merupakan model semantik Power BI atau model Analysis Services, lebih fleksibel. Dalam hal ini, semua fungsi DAX diizinkan karena ekspresi akan dievaluasi dalam model tabular sumber.
Banyak ekspresi mengharuskan Power BI untuk mewujudkan kolom terhitung sebelum menggunakannya sebagai grup atau filter, atau menggabungkannya. Ketika kolom terhitung diwujudkan melalui tabel besar, kolom tersebut dapat mahal dalam hal CPU dan memori, tergantung pada kardinalitas kolom yang bergantung pada kolom terhitung. Dalam hal ini, kami sarankan Anda menambahkan kolom terhitung tersebut ke model sumber.
Catatan
Saat Anda menambahkan kolom terhitung ke model komposit, pastikan untuk menguji semua perhitungan model. Perhitungan upstram mungkin tidak berfungsi dengan benar karena tidak mempertimbangkan pengaruhnya pada konteks filter.
Grup perhitungan
Jika grup perhitungan ada dalam grup sumber yang tersambung ke model semantik Power BI atau model Analysis Services, Power BI dapat mengembalikan hasil yang tidak terduga. Untuk informasi selengkapnya, lihat Grup penghitungan, kueri, dan evaluasi pengukuran.
Desain model
Anda harus selalu mengoptimalkan model Power BI dengan mengadopsi desain skema bintang.
Tip
Untuk informasi selengkapnya, lihat Memahami skema bintang dan pentingnya Power BI.
Pastikan untuk membuat tabel dimensi yang terpisah dari tabel fakta sehingga Power BI dapat menginterpretasikan gabungan dengan benar dan menghasilkan rencana kueri yang efisien. Meskipun panduan ini berlaku untuk model Power BI apa pun, terutama berlaku untuk model yang Anda kenali akan menjadi grup sumber model komposit. Ini akan memungkinkan integrasi tabel lain yang lebih sederhana dan lebih efisien dalam model hilir.
Jika memungkinkan, hindari memiliki tabel dimensi dalam satu grup sumber yang terkait dengan tabel fakta dalam grup sumber yang berbeda. Itu karena lebih baik memiliki hubungan grup sumber intra daripada hubungan grup lintas sumber, terutama untuk kolom hubungan kardinalitas tinggi. Seperti yang dijelaskan sebelumnya, hubungan grup lintas sumber mengandalkan memiliki nilai yang cocok di kolom hubungan, jika tidak, hasil yang tidak terduga dapat ditampilkan dalam visual laporan.
Keamanan tingkat baris
Jika model Anda menyertakan agregasi yang ditentukan pengguna, kolom terhitung pada tabel impor, atau tabel terhitung, pastikan bahwa keamanan tingkat baris (RLS) disiapkan dengan benar dan diuji.
Jika model komposit tersambung ke model tabular lainnya, aturan RLS hanya diterapkan pada grup sumber (model lokal) tempat model tersebut ditentukan. Mereka tidak akan diterapkan ke grup sumber lain (model jarak jauh). Selain itu, Anda tidak dapat menentukan aturan RLS pada tabel dari grup sumber lain juga tidak dapat menentukan aturan RLS pada tabel lokal yang memiliki hubungan dengan grup sumber lain.
Desain laporan
Dalam beberapa situasi, Anda dapat meningkatkan performa model komposit dengan merancang tata letak laporan yang dioptimalkan.
Visual grup sumber tunggal
Jika memungkinkan, buat visual yang menggunakan bidang dari satu grup sumber. Itu karena kueri yang dihasilkan oleh visual akan berkinerja lebih baik ketika hasilnya diambil dari satu grup sumber. Pertimbangkan untuk membuat dua visual yang diposisikan berdampingan yang mengambil data dari dua grup sumber yang berbeda.
Menggunakan pemotong sinkronisasi
Dalam beberapa situasi, Anda dapat menyiapkan pemotong sinkronisasi untuk menghindari pembuatan hubungan grup lintas sumber dalam model Anda. Ini dapat memungkinkan Anda untuk menggabungkan grup sumber secara visual yang dapat berkinerja lebih baik.
Pertimbangkan skenario saat model Anda memiliki dua grup sumber. Setiap grup sumber memiliki tabel dimensi produk yang digunakan untuk memfilter penjual dan penjualan internet.
Dalam skenario ini, grup sumber A berisi tabel Produk yang terkait dengan tabel ResellerSales . Grup sumber B berisi tabel Product2 yang terkait dengan tabel InternetSales . Tidak ada hubungan grup lintas sumber.
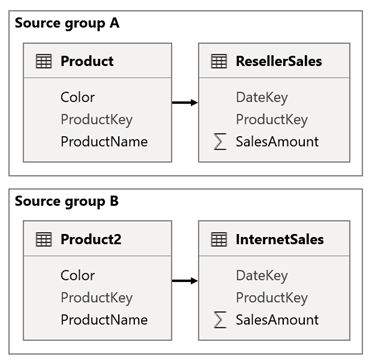
Dalam laporan, Anda menambahkan pemotong yang memfilter halaman dengan menggunakan kolom Warna tabel Produk. Secara default, pemotong memfilter tabel ResellerSales , tetapi bukan tabel InternetSales . Anda kemudian menambahkan pemotong tersembunyi dengan menggunakan kolom Warna tabel Product2 . Dengan mengatur nama grup yang identik (ditemukan di pemotong sinkronisasi Opsi tingkat lanjut), filter yang diterapkan ke pemotong yang terlihat secara otomatis disebarkan ke pemotong tersembunyi.
Catatan
Saat menggunakan pemotong sinkronisasi dapat menghindari kebutuhan untuk membuat hubungan grup lintas sumber, itu meningkatkan kompleksitas desain model. Pastikan untuk mendidik pengguna lain tentang alasan Anda merancang model dengan tabel dimensi duplikat. Hindari kebingungan dengan menyembunyikan tabel dimensi yang tidak Anda inginkan untuk digunakan pengguna lain. Anda juga dapat menambahkan teks deskripsi ke tabel tersembunyi untuk mendokumen tujuannya.
Untuk informasi selengkapnya, lihat Menyinkronkan pemotong terpisah.
Panduan lainnya
Berikut adalah beberapa panduan lain untuk membantu Anda merancang dan memelihara model komposit.
- Performa dan skala: Jika laporan Anda sebelumnya tersambung langsung ke model semantik Power BI atau model Analysis Services, layanan Power BI dapat menggunakan kembali cache visual di seluruh laporan. Setelah Anda mengonversi koneksi langsung untuk membuat model DirectQuery lokal, laporan tidak akan lagi mendapat manfaat dari cache tersebut. Akibatnya, Anda mungkin mengalami performa yang lebih lambat atau bahkan kegagalan refresh. Selain itu, beban kerja untuk layanan Power BI akan meningkat, yang mungkin mengharuskan Anda meningkatkan kapasitas atau mendistribusikan beban kerja di seluruh kapasitas lain. Untuk informasi selengkapnya tentang refresh dan penembolokan data, lihat Refresh data di Power BI.
- Mengganti nama: Kami tidak menyarankan Agar Anda mengganti nama model semantik yang digunakan oleh model komposit, atau mengganti nama ruang kerjanya. Itu karena model komposit tersambung ke model semantik Power BI dengan menggunakan nama ruang kerja dan model semantik (dan bukan pengidentifikasi unik internalnya). Mengganti nama model semantik atau ruang kerja dapat memutus koneksi yang digunakan oleh model komposit Anda.
- Tata kelola: Kami tidak menyarankan agar versi tunggal model kebenaran Anda adalah model komposit. Itu karena akan bergantung pada sumber data atau model lain, yang jika diperbarui, dapat mengakibatkan pemecahan model komposit. Sebagai gantinya, kami sarankan Anda menerbitkan model semantik perusahaan sebagai versi tunggal kebenaran. Pertimbangkan model ini untuk menjadi fondasi yang dapat diandalkan. Pemodel data lain kemudian dapat membuat model komposit yang memperluas model fondasi untuk membuat model khusus.
- Silsilah data: Gunakan silsilah data dan fitur analisis dampak model semantik sebelum menerbitkan perubahan model komposit. Fitur-fitur ini tersedia di layanan Power BI, dan dapat membantu Anda memahami bagaimana model semantik terkait dan digunakan. Penting untuk dipahami bahwa Anda tidak dapat melakukan analisis dampak pada model semantik eksternal yang ditampilkan dalam tampilan silsilah tetapi sebenarnya terletak di ruang kerja lain. Untuk melakukan analisis dampak pada model semantik eksternal, Anda perlu menavigasi ke ruang kerja sumber.
- Pembaruan skema: Anda harus me-refresh model komposit Anda di Power BI Desktop saat perubahan skema dilakukan pada sumber data upstram. Anda kemudian perlu menerbitkan ulang model ke layanan Power BI. Pastikan untuk menguji perhitungan dan laporan dependen secara menyeluruh.
Konten terkait
Untuk informasi selengkapnya terkait artikel ini, lihat sumber daya berikut ini.
- Menggunakan model komposit dalam Power BI Desktop
- Hubungan model di Power BI Desktop
- Model DirectQuery di Power BI Desktop
- Menggunakan DirectQuery di Power BI Desktop
- Menggunakan DirectQuery untuk model semantik Power BI dan Analysis Services
- Mode Penyimpanan di Power BI Desktop
- Agregasi yang ditentukan pengguna
- Pertanyaan? Coba tanyakan kepada Komunitas Power BI
- Ada saran? Sumbang ide untuk meningkatkan Power BI
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk