Contoh skenario ini menunjukkan bagaimana data dapat diserap ke lingkungan cloud dari gudang data lokal, lalu dilayani menggunakan model kecerdasan bisnis (BI). Pendekatan ini bisa menjadi tujuan akhir atau langkah pertama menuju modernisasi penuh dengan komponen berbasis cloud.
Langkah-langkah berikut dibangun pada skenario end-to-end Azure Synapse Analytics. Ini menggunakan Azure Pipelines untuk menyerap data dari database SQL ke kumpulan Azure Synapse SQL, lalu mengubah data untuk analisis.
Arsitektur

Unduh file Visio arsitektur ini.
Alur kerja
Sumber data
- Data sumber terletak di database SQL Server di Azure. Untuk mensimulasikan lingkungan lokal, skrip penyebaran untuk skenario ini menyediakan database Azure SQL. Database sampel AdventureWorks digunakan sebagai skema data sumber dan data sampel. Untuk informasi tentang cara menyalin data dari database lokal, lihat menyalin dan mengubah data ke dan dari SQL Server.
Penyerapan dan penyimpanan data
Azure Data Lake Gen2 digunakan sebagai area penahapan sementara selama penyerapan data. Anda kemudian dapat menggunakan PolyBase untuk menyalin data ke kumpulan SQL khusus Azure Synapse.
Azure Synapse Analytics adalah sistem terdistribusi yang dirancang untuk melakukan analitik pada data besar. Ini mendukung pemrosesan paralel besar-besaran (MPP), yang membuatnya cocok untuk menjalankan analitik berperforma tinggi. Kumpulan SQL khusus Azure Synapse adalah target untuk penyerapan yang sedang berlangsung dari lokal. Ini dapat digunakan untuk pemrosesan lebih lanjut, serta melayani data untuk Power BI melalui DirectQuery.
Azure Pipelines digunakan untuk mengatur penyerapan dan transformasi data dalam ruang kerja Azure Synapse Anda.
Analisis dan pelaporan
- Pendekatan pemodelan data dalam skenario ini disajikan dengan menggabungkan model perusahaan dan model BI Semantic. Model perusahaan disimpan dalam kumpulan SQL khusus Azure Synapse, dan model BI Semantic disimpan dalam kapasitas Power BI Premium. Power BI mengakses data melalui DirectQuery.
Komponen
Skenario ini menggunakan komponen berikut:
Arsitektur yang disederhanakan
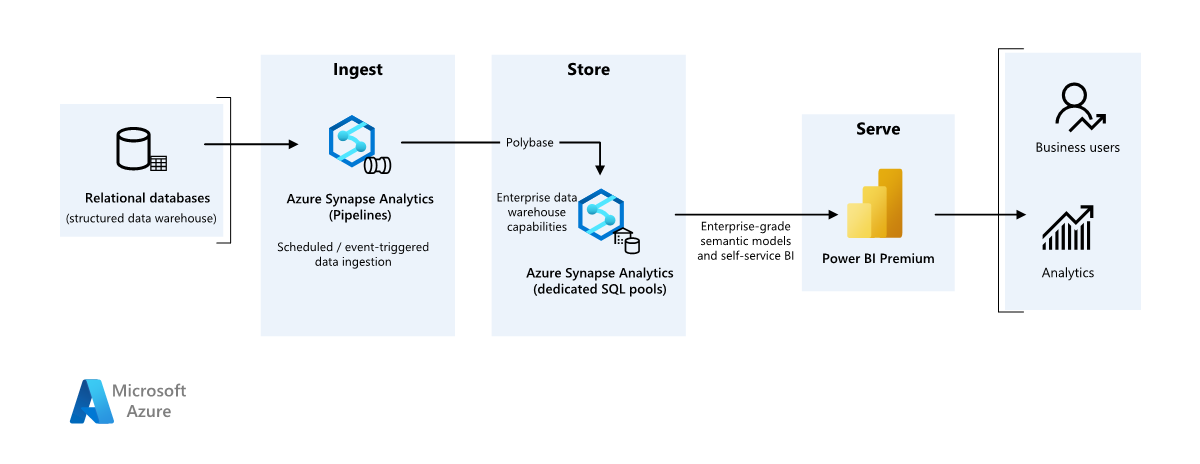
Detail skenario
Organisasi memiliki gudang data lokal besar yang disimpan dalam database SQL. Organisasi ingin menggunakan Azure Synapse untuk melakukan analisis, lalu melayani wawasan ini menggunakan Power BI.
Autentikasi
Microsoft Entra mengautentikasi pengguna yang tersambung ke dasbor dan aplikasi Power BI. Akses menyeluruh digunakan untuk menyambungkan ke sumber data di kumpulan yang disediakan Azure Synapse. Otorisasi terjadi pada sumbernya.
Pemuatan secara bertahap
Saat Anda menjalankan proses extract-transform-load (ETL) otomatis atau extract-load-transform (ELT), paling efisien untuk memuat hanya data yang berubah sejak eksekusi sebelumnya. Ini disebut beban bertahap, dibandingkan dengan beban penuh yang memuat semua data. Untuk melakukan beban bertambah bertahap, Anda memerlukan cara untuk mengidentifikasi data mana yang telah berubah. Pendekatan yang paling umum adalah menggunakan nilai tanda air tinggi, yang melacak nilai terbaru beberapa kolom dalam tabel sumber, baik kolom tanggalwaktu atau kolom bilangan bulat unik.
Dimulai dengan SQL Server 2016, Anda dapat menggunakan tabel temporal, yang merupakan tabel versi sistem yang menyimpan riwayat penuh perubahan data. Mesin database secara otomatis merekam riwayat setiap perubahan dalam tabel riwayat terpisah. Anda bisa mengkueri data historis dengan menambahkan FOR SYSTEM_TIME klausa ke kueri. Secara internal, mesin database meminta tabel riwayat, tetapi transparan untuk aplikasi.
Catatan
Untuk versi SQL Server yang lebih lama, Anda dapat menggunakan change data capture (CDC). Pendekatan ini kurang nyaman dibandingkan tabel temporal, karena Anda harus membuat kueri tabel perubahan terpisah, dan perubahan dilacak dengan nomor urut log, bukan stempel waktu.
Tabel temporal berguna untuk data dimensi, yang dapat berubah seiring waktu. Tabel fakta biasanya mewakili transaksi yang tidak dapat diubah seperti penjualan, dalam hal ini menjaga riwayat versi sistem adalah hal yang tidak masuk akal. Sebaliknya, transaksi biasanya memiliki kolom yang mewakili tanggal transaksi, yang dapat digunakan sebagai nilai marka air. Misalnya, di Gudang Data AdventureWorks, SalesLT.* tabel memiliki LastModified bidang .
Berikut adalah alur umum untuk alur ELT:
Untuk setiap tabel di database sumber, lacak waktu cutoff saat pekerjaan ELT terakhir dijalankan. Simpan informasi ini di gudang data. Pada penyiapan awal, semua kali diatur ke
1-1-1900.Selama langkah ekspor data, waktu cutoff dilewatkan sebagai parameter ke set prosedur tersimpan di database sumber. Prosedur tersimpan ini mengkueri rekaman apa pun yang diubah atau dibuat setelah waktu cutoff. Untuk semua tabel dalam contoh, Anda bisa menggunakan
ModifiedDatekolom .Saat migrasi data selesai, perbarui tabel yang menyimpan waktu cutoff.
Pipa data
Skenario ini menggunakan database sampel AdventureWorks sebagai sumber data. Pola beban data bertambah bertahap diimplementasikan untuk memastikan kami hanya memuat data yang dimodifikasi atau ditambahkan setelah eksekusi alur terbaru.
Alat penyalinan berbasis metadata
Alat salin berbasis metadata bawaan dalam Azure Pipelines secara bertahap memuat semua tabel yang terkandung dalam database relasional kami. Dengan menavigasi melalui pengalaman berbasis wizard, Anda dapat menyambungkan alat Salin Data ke database sumber, dan mengonfigurasi pemuatan bertahap atau penuh untuk setiap tabel. Alat Salin Data kemudian membuat alur dan skrip SQL untuk menghasilkan tabel kontrol yang diperlukan untuk menyimpan data untuk proses pemuatan bertahap—misalnya, nilai/kolom marka air tinggi untuk setiap tabel. Setelah skrip ini dijalankan, alur siap untuk memuat semua tabel di gudang data sumber ke dalam kumpulan khusus Synapse.
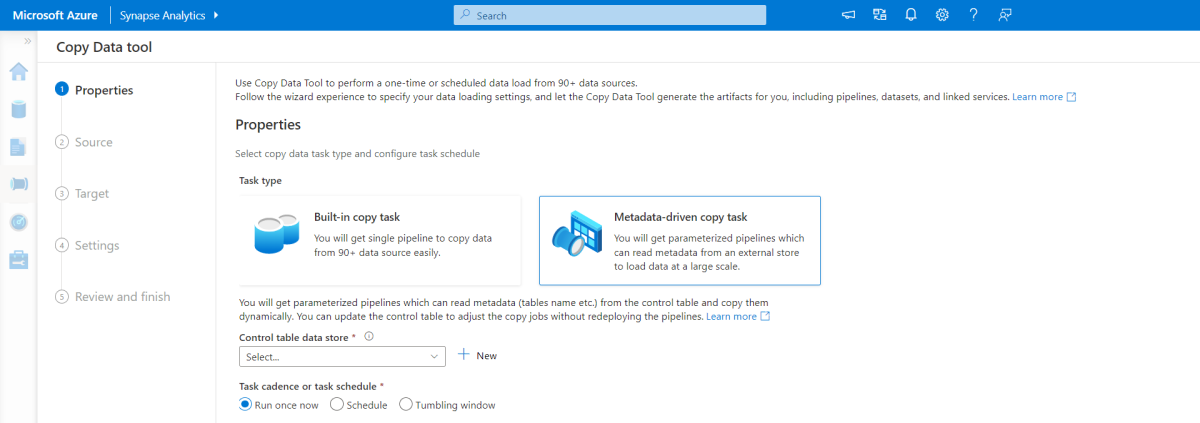
Alat ini membuat tiga alur untuk mengulangi semua tabel dalam database, sebelum memuat data.
Alur yang dihasilkan oleh alat ini:
- Hitung jumlah objek, seperti tabel, yang akan disalin dalam eksekusi alur.
- Ulangi setiap objek yang akan dimuat/disalin lalu:
- Periksa apakah beban delta diperlukan; jika tidak, selesaikan beban penuh normal.
- Ambil nilai marka air tinggi dari tabel kontrol.
- Salin data dari tabel sumber ke akun penahapan di ADLS Gen2.
- Muat data ke kumpulan SQL khusus melalui metode salin yang dipilih—misalnya, Polybase, perintah Salin.
- Perbarui nilai marka air tinggi dalam tabel kontrol.
Memuat data ke kumpulan Azure Synapse SQL
Aktivitas salin menyalin data dari database SQL ke kumpulan Azure Synapse SQL. Dalam contoh ini, karena database SQL kami berada di Azure, kami menggunakan runtime integrasi Azure untuk membaca data dari database SQL dan menulis data ke lingkungan penahapan yang ditentukan.
Pernyataan salin kemudian digunakan untuk memuat data dari lingkungan penahapan ke kumpulan khusus Synapse.
Gunakan Azure Pipelines
Alur di Azure Synapse digunakan untuk menentukan serangkaian aktivitas yang diurutkan untuk menyelesaikan pola beban bertahap. Pemicu digunakan untuk memulai alur, yang dapat dipicu secara manual atau pada waktu yang ditentukan.
Mengubah data
Karena database sampel dalam arsitektur referensi kami tidak besar, kami membuat tabel yang direplikasi tanpa partisi. Untuk beban kerja produksi, menggunakan tabel terdistribusi kemungkinan akan meningkatkan performa kueri. Baca Panduan untuk mendesain tabel terdistribusi di Azure Synapse. Contoh skrip menjalankan kueri menggunakan kelas sumber daya statis.
Di lingkungan produksi, pertimbangkan untuk membuat tabel penahapan dengan distribusi round-robin. Kemudian ubah dan pindahkan data ke dalam tabel produksi dengan indeks penyimpan kolom berkluster, yang menawarkan performa kueri keseluruhan terbaik. Indeks penyimpan kolom dioptimalkan untuk kueri yang memindai banyak catatan. Indeks penyimpan kolom tidak berkinerja baik untuk pencarian singleton, yaitu mencari satu baris. Jika Anda perlu sering melakukan pencarian tunggal, Anda dapat menambahkan indeks yang tidak berkluster ke tabel. Pencarian singleton dapat berjalan jauh lebih cepat menggunakan indeks non-kluster. Namun, pencarian tunggal biasanya jarang dilakukan dalam skenario gudang data daripada beban kerja OLTP. Untuk informasi selengkapnya, baca Tabel pengindeksan di Azure Synapse.
Catatan
Tabel penyimpan kolom berkluster tidak mendukung varchar(max)jenis data , , nvarchar(max)atau varbinary(max) . Dalam hal ini, pertimbangkan indeks susunan atau berkluster. Anda sebaiknya menempatkan kolom-kolom tersebut ke dalam tabel yang terpisah.
Menggunakan Power BI Premium untuk mengakses, memodelkan, dan memvisualisasikan data
Power BI Premium mendukung beberapa opsi untuk menyambungkan ke sumber data di Azure, khususnya kumpulan yang disediakan Azure Synapse:
- Impor: Data diimpor ke dalam model Power BI.
- DirectQuery: Data ditarik langsung dari penyimpanan relasional.
- Model komposit: Gabungkan Impor untuk beberapa tabel dan DirectQuery untuk yang lain.
Skenario ini dikirimkan dengan dasbor DirectQuery karena jumlah data yang digunakan dan kompleksitas model tidak tinggi, sehingga kami dapat memberikan pengalaman pengguna yang baik. DirectQuery mendelegasikan kueri ke mesin komputasi yang kuat di bawahnya dan menggunakan kemampuan keamanan yang luas pada sumbernya. Selain itu, dengan menggunakan DirectQuery akan memastikan hasilnya selalu konsisten dengan sumber data terbaru.
Mode impor menyediakan waktu respons kueri tercepat, dan harus dipertimbangkan ketika model sepenuhnya sesuai dalam memori Power BI, latensi data antara refresh dapat ditoleransi, dan mungkin ada beberapa transformasi kompleks antara sistem sumber dan model akhir. Dalam hal ini, pengguna akhir menginginkan akses penuh ke data terbaru tanpa penundaan dalam refresh Power BI, dan semua data historis, yang lebih besar dari apa yang dapat ditangani himpunan data Power BI—antara 25-400 GB, tergantung pada ukuran kapasitas. Karena model data di kumpulan SQL khusus sudah berada dalam skema bintang dan tidak memerlukan transformasi, DirectQuery adalah pilihan yang tepat.
Power BI Premium Gen2 memberi Anda kemampuan untuk menangani model besar, laporan paginasi, alur penyebaran, dan titik akhir Analysis Services bawaan. Anda juga dapat memiliki kapasitas khusus dengan proposisi nilai unik.
Ketika model BI tumbuh atau kompleksitas dasbor meningkat, Anda dapat beralih ke model komposit dan mulai mengimpor bagian tabel pencarian, melalui tabel hibrid, dan beberapa data pra-agregat. Mengaktifkan penembolokan kueri dalam Power BI untuk himpunan data yang diimpor adalah opsi, serta menggunakan tabel ganda untuk properti mode penyimpanan.
Dalam model komposit, himpunan data bertindak sebagai lapisan pass-through virtual. Saat pengguna berinteraksi dengan visualisasi, Power BI menghasilkan kueri SQL ke penyimpanan ganda kumpulan Synapse SQL: dalam memori atau kueri langsung tergantung pada mana yang lebih efisien. Mesin memutuskan kapan harus beralih dari dalam memori ke kueri langsung dan mendorong logika ke kumpulan Synapse SQL. Bergantung pada konteks tabel kueri, tabel kueri dapat bertindak sebagai model komposit cache (diimpor) atau tidak di-cache. Pilih dan pilih tabel mana yang akan di-cache ke dalam memori, gabungkan data dari satu atau beberapa sumber DirectQuery, dan/atau gabungkan data dari campuran sumber DirectQuery dan data yang diimpor.
Rekomendasi: Saat menggunakan DirectQuery melalui kumpulan yang disediakan Azure Synapse Analytics:
- Gunakan penembolokan tataan hasil Azure Synapse untuk menyimpan hasil kueri dalam database pengguna untuk penggunaan berulang, meningkatkan performa kueri hingga milidetik, dan mengurangi penggunaan sumber daya komputasi. Kueri yang menggunakan kumpulan hasil yang di-cache tidak menggunakan slot konkurensi apa pun di Azure Synapse Analytics dan dengan demikian tidak dihitung terhadap batas konkurensi yang ada.
- Gunakan tampilan materialisasi Azure Synapse untuk melakukan pra-komputasi, menyimpan, dan memelihara data seperti tabel. Kueri yang menggunakan semua atau subset data dalam tampilan materialisasi bisa mendapatkan performa yang lebih cepat, dan tidak perlu membuat referensi langsung ke tampilan materialisasi yang ditentukan untuk menggunakannya.
Pertimbangan
Pertimbangan ini mengimplementasikan pilar Azure Well-Architected Framework, yang merupakan serangkaian tenet panduan yang dapat digunakan untuk meningkatkan kualitas beban kerja. Untuk informasi selengkapnya, lihat Microsoft Azure Well-Architected Framework.
Keamanan
Keamanan memberikan jaminan terhadap serangan yang disukai dan penyalahgunaan data dan sistem berharga Anda. Untuk informasi selengkapnya, lihat Gambaran Umum pilar keamanan.
Berita utama yang sering mengenai pelanggaran data, infeksi malware, dan injeksi kode berbahaya adalah di antara daftar ekstensif masalah keamanan bagi perusahaan yang ingin melakukan modernisasi cloud. Pelanggan perusahaan memerlukan penyedia cloud atau solusi layanan yang dapat mengatasi kekhawatiran mereka karena mereka tidak mampu melakukan kesalahan.
Skenario ini membahas masalah keamanan yang paling menuntut menggunakan kombinasi kontrol keamanan berlapis: jaringan, identitas, privasi, dan otorisasi. Sebagian besar data disimpan di kumpulan yang disediakan Azure Synapse, dengan Power BI menggunakan DirectQuery melalui akses menyeluruh. Anda dapat menggunakan ID Microsoft Entra untuk autentikasi. Ada juga kontrol keamanan yang luas untuk otorisasi data kumpulan yang disediakan.
Beberapa pertanyaan keamanan umum meliputi:
- Bagaimana cara saya mengontrol siapa yang dapat melihat data apa?
- Organisasi perlu melindungi datanya untuk mematuhi panduan federal, lokal, dan perusahaan guna mengurangi risiko pelanggaran data. Azure Synapse menawarkan beberapa kemampuan perlindungan data untuk mencapai kepatuhan.
- Apa saja opsi untuk memverifikasi identitas pengguna?
- Azure Synapse mendukung berbagai kemampuan untuk mengontrol siapa yang dapat mengakses data apa melalui kontrol akses dan autentikasi.
- Teknologi keamanan jaringan apa yang dapat saya gunakan untuk melindungi integritas, kerahasiaan, dan akses jaringan dan data saya?
- Untuk mengamankan Azure Synapse, ada berbagai opsi keamanan jaringan yang tersedia untuk dipertimbangkan.
- Alat apa yang mendeteksi dan memberi tahu saya tentang ancaman?
- Azure Synapse menyediakan banyak kemampuan deteksi ancaman seperti: Audit SQL, deteksi ancaman SQL, dan penilaian kerentanan untuk mengaudit, melindungi, dan memantau database.
- Apa yang dapat saya lakukan untuk melindungi data di akun penyimpanan saya?
- Akun Azure Storage sangat ideal untuk beban kerja yang memerlukan waktu respons yang cepat dan konsisten, atau yang memiliki jumlah operasi output input (IOP) per detik yang tinggi. Akun penyimpanan berisi semua objek data Azure Storage Anda, dan memiliki banyak opsi untuk keamanan akun penyimpanan.
Pengoptimalan biaya
Optimalisasi biaya adalah tentang mencari cara untuk mengurangi pengeluaran yang tidak perlu dan meningkatkan efisiensi operasional. Untuk informasi selengkapnya, lihat Gambaran umum pilar pengoptimalan biaya.
Bagian ini menyediakan informasi tentang harga untuk berbagai layanan yang terlibat dalam solusi ini, dan menyebutkan keputusan yang dibuat untuk skenario ini dengan himpunan data sampel.
Azure Synapse
Arsitektur tanpa server Azure Synapse Analytics memungkinkan Anda menskalakan tingkat komputasi dan penyimpanan secara independen. Sumber daya komputasi ditagih berdasarkan penggunaan, dan Anda dapat menskalakan atau menjeda sumber daya ini sesuai permintaan. Sumber daya penyimpanan ditagih per terabyte, sehingga biaya Anda akan meningkat saat Anda menyerap lebih banyak data.
Azure Pipelines
Detail harga untuk alur di Azure Synapse dapat ditemukan di bawah tab Integrasi Data di halaman harga Azure Synapse. Ada tiga komponen utama yang memengaruhi harga alur:
- Aktivitas alur data dan jam runtime integrasi
- Ukuran dan eksekusi kluster aliran data
- Biaya operasi
Harga bervariasi tergantung pada komponen atau aktivitas, frekuensi, dan jumlah unit runtime integrasi.
Untuk himpunan data sampel, runtime integrasi standar yang dihosting Azure, menyalin aktivitas data untuk inti alur, dipicu pada jadwal harian untuk semua entitas (tabel) dalam database sumber. Skenario tidak berisi aliran data. Tidak ada biaya operasional karena ada kurang dari 1 juta operasi dengan alur sebulan.
Kumpulan dan penyimpanan khusus Azure Synapse
Detail harga untuk kumpulan khusus Azure Synapse dapat ditemukan di bawah tab Pergudangan Data di halaman harga Azure Synapse. Di bawah model Konsumsi khusus, pelanggan ditagih per unit DWU yang disediakan, per jam waktu aktif. Faktor penyumbang lainnya adalah biaya penyimpanan data: ukuran data Anda saat tidak aktif + rekam jepret + geo-redundansi, jika ada.
Untuk himpunan data sampel, Anda dapat menyediakan 500DWU, yang menjamin pengalaman yang baik untuk beban analitis. Anda dapat menjaga komputasi tetap aktif dan berjalan selama jam kerja pelaporan. Jika diambil ke dalam produksi, kapasitas gudang data yang dipesan adalah opsi yang menarik untuk manajemen biaya. Teknik yang berbeda harus digunakan untuk memaksimalkan metrik biaya/performa, yang tercakup dalam bagian sebelumnya.
Penyimpanan Blob
Pertimbangkan untuk menggunakan fitur kapasitas cadangan Azure Storage untuk menurunkan biaya penyimpanan. Dengan model ini, Anda mendapatkan diskon jika Anda memesan kapasitas penyimpanan tetap selama satu atau tiga tahun. Untuk informasi selengkapnya, lihat Mengoptimalkan biaya untuk penyimpanan Blob dengan kapasitas terpesan.
Tidak ada penyimpanan persisten dalam skenario ini.
Power BI Premium
Detail harga Power BI Premium dapat ditemukan di halaman harga Power BI.
Skenario ini menggunakan ruang kerja Power BI Premium dengan berbagai peningkatan performa bawaan untuk mengakomodasi kebutuhan analitik yang menuntut.
Keunggulan operasional
Keunggulan operasional mencakup proses operasi yang menyebarkan aplikasi dan membuatnya tetap berjalan dalam produksi. Untuk informasi selengkapnya, lihat Gambaran umum pilar keunggulan operasional.
Rekomendasi DevOps
Buat grup sumber daya terpisah untuk lingkungan produksi, pengembangan, dan pengujian. Grup sumber daya yang terpisah akan mempermudah pengelolaan penyebaran, penghapusan penyebaran pengujian, dan penetapan hak akses.
Tempatkan setiap beban kerja dalam template penyebaran terpisah dan simpan sumber daya dalam sistem kontrol sumber. Anda dapat menyebarkan templat bersama-sama atau satu per satu sebagai bagian dari proses integrasi berkelanjutan (CI) dan pengiriman berkelanjutan (CD), membuat proses otomatisasi lebih mudah. Dalam arsitektur ini, ada empat beban kerja utama:
- Server gudang data, dan sumber daya terkait
- Alur Azure Synapse
- Aset Power BI: dasbor, aplikasi, himpunan data
- Skenario simulasi lokal ke cloud
Bertujuan untuk memiliki templat penyebaran terpisah untuk setiap beban kerja.
Pertimbangkan penahapan beban kerja Anda di mana praktis. Sebarkan ke berbagai tahap dan jalankan pemeriksaan validasi di setiap tahap sebelum melanjutkan ke tahap berikutnya. Dengan demikian, Anda dapat mendorong pembaruan ke lingkungan produksi Anda dengan cara yang terkontrol dan meminimalkan masalah penyebaran yang tidak tertandingi. Gunakan strategi penyebaran biru-hijau dan rilis kenari untuk memperbarui lingkungan produksi langsung.
Miliki strategi putar kembali yang baik untuk menangani penyebaran yang gagal. Misalnya, Anda dapat secara otomatis menerapkan ulang penyebaran sebelumnya yang berhasil dari riwayat penyebaran Anda.
--rollback-on-errorLihat bendera di Azure CLI.Azure Monitor adalah opsi yang disarankan untuk menganalisis performa gudang data Anda serta keseluruhan platform analitik Azure untuk pengalaman pemantauan yang terintegrasi. Azure Synapse Analytics memberikan pengalaman pemantauan dalam portal Azure untuk menampilkan wawasan tentang beban kerja gudang data Anda. Portal Microsoft Azure adalah alat yang direkomendasikan saat memantau gudang data Anda karena menyediakan periode retensi yang dapat dikonfigurasi, peringatan, rekomendasi, dan bagan serta dasbor yang dapat disesuaikan untuk metrik dan log.
Mulai Cepat
- Portal: Bukti konsep Azure Synapse
- Azure CLI: Membuat ruang kerja Azure Synapse dengan Azure CLI
- Terraform: Pergudangan data modern dengan Terraform dan Microsoft Azure
Efisiensi kinerja
Efisiensi performa adalah kemampuan beban kerja Anda untuk diskalakan agar memenuhi permintaan yang diberikan oleh pengguna dengan cara yang efisien. Untuk informasi selengkapnya, lihat Gambaran umum pilar efisiensi performa.
Bagian ini menyediakan detail tentang keputusan ukuran untuk mengakomodasi himpunan data ini.
Kumpulan yang disediakan Azure Synapse
Ada berbagai konfigurasi gudang data untuk dipilih.
| Unit gudang data | # dari node komputasi | # dari distribusi per node |
|---|---|---|
| DW100c | 1 | 60 |
-- TO -- |
||
| DW30000c | 60 | 1 |
Untuk melihat manfaat performa penskalaan, terutama untuk unit gudang data yang lebih besar, gunakan setidaknya himpunan data 1-TB. Untuk menemukan jumlah unit gudang data terbaik untuk kumpulan SQL khusus Anda, coba tingkatkan dan turunkan skala. Jalankan beberapa kueri dengan jumlah unit gudang data yang berbeda setelah Anda memuat data. Karena proses penskalaan berjalan cepat, Anda dapat mencoba berbagai tingkat performa dalam satu jam atau kurang.
Temukan jumlah unit gudang data terbaik
Untuk kumpulan SQL khusus dalam pengembangan, mulailah dengan memilih sejumlah kecil unit gudang data. Titik awal yang baik adalah DW400c atau DW200c. Pantau performa aplikasi Anda, perhatikan jumlah unit gudang data yang dipilih dibandingkan dengan performa yang Anda amati. Asumsikan skala linier, dan tentukan jumlah yang Anda perlukan untuk menambah atau mengurangi unit gudang data. Terus lakukan penyesuaian hingga Anda mencapai tingkat performa optimal untuk persyaratan bisnis Anda.
Menskalakan kumpulan Synapse SQL
- Menskalakan komputasi untuk kumpulan Synapse SQL dengan portal Azure
- Menskalakan komputasi untuk kumpulan SQL khusus dengan Azure PowerShell
- Menskalakan komputasi untuk kumpulan SQL khusus di Azure Synapse Analytics menggunakan T-SQL
- Menjeda, memantau, dan otomatisasi
Azure Pipelines
Untuk fitur skalabilitas dan pengoptimalan performa alur di Azure Synapse dan aktivitas salin yang digunakan, lihat panduan performa dan skalabilitas aktivitas Salin.
Power BI Premium
Artikel ini menggunakan Power BI Premium Gen 2 untuk menunjukkan kemampuan BI. SKU Kapasitas untuk Power BI Premium berkisar dari P1 (delapan v-core) hingga P5 (128 v-core) saat ini. Cara terbaik untuk memilih kapasitas yang diperlukan adalah dengan menjalani evaluasi pemuatan kapasitas, menginstal aplikasi metrik Gen 2 untuk pemantauan yang sedang berlangsung, dan pertimbangkan untuk menggunakan Autoscale dengan Power BI Premium.
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Galina Polyakova | Arsitek Solusi Cloud Senior
- Noah Costar | Arsitek Solusi Cloud
- George Stevens | Arsitek Solusi Cloud
Kontributor lain:
- Jim McLeod | Arsitek Solusi Cloud
- Miguel Myers | Manajer Program Senior
Untuk melihat profil LinkedIn non-publik, masuk ke LinkedIn.
Langkah berikutnya
- Apa itu Power BI Premium?
- Apa itu ID Microsoft Entra?
- Mengakses Azure Data Lake Storage Gen2 dan Blob Storage dengan Azure Databricks
- Apakah Azure Synapse Analytics itu?
- Alur dan aktivitas di Azure Data Factory dan Azure Synapse Analytics
- Apa itu Azure SQL?