Tutorial: Mengekstrak, mengubah, dan memuat data menggunakan Azure Databricks
Dalam tutorial ini, Anda melakukan operasi ETL (ekstrak, transformasi, dan muat data) dengan menggunakan Azure Databricks. Anda mengekstrak data dari Azure Data Lake Storage Gen2 ke Azure Databricks, menjalankan transformasi pada data di Azure Databricks, dan memuat data yang diubah ke Azure Synapse Analytics.
Langkah-langkah dalam tutorial ini menggunakan konektor Azure Synapse untuk Azure Databricks untuk mentransfer data ke Azure Databricks. Konektor ini, pada gilirannya, menggunakan Azure Blob Storage sebagai penyimpanan sementara untuk data yang ditransfer antara kluster Azure Databricks dan Azure Synapse.
Ilustrasi berikut menunjukkan alur aplikasi:

Tutorial ini mencakup tugas-tugas berikut:
- Buat layanan Azure Databricks.
- Buat kluster Spark di Azure Databricks.
- Buat sistem file di akun Data Lake Storage Gen2.
- Unggah sampel data ke akun Azure Data Lake Storage Gen2.
- Membuat perwakilan layanan.
- Ekstrak data dari akun Azure Data Lake Storage Gen2.
- Transformasikan data di Azure Databricks.
- Muat data ke Azure Synapse
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
Catatan
Tutorial ini tidak dapat dilakukan menggunakan Langganan Coba Gratis Azure. Jika Anda memiliki akun gratis, buka profil Anda dan ubah langganan menjadi bayar sesuai pemakaian prabayar. Untuk informasi selengkapnya, lihat Akun gratis Azure. Kemudian, hapus batas pembelanjaan, dan minta peningkatan kuota untuk vCPU di wilayah Anda. Saat membuat ruang kerja Azure Databricks, Anda dapat memilih tingkat harga Uji Coba (Premium - DBU Gratis 14 Hari) untuk memberikan akses ruang kerja ke DBU Azure Databricks Premium gratis selama 14 hari.
Prasyarat
Selesaikan tugas berikut sebelum Anda memulai tutorial ini:
Buat Azure Synapse, buat aturan firewall tingkat server, dan sambungkan ke server sebagai admin server. Lihat Mulai Cepat: Membuat dan mengkueri kumpulan SQL Synapse menggunakan portal Azure.
Buat kunci master untuk Azure Synapse. Lihat Membuat kunci master database.
Buat akun penyimpanan Azure Blob, dan kontainer di dalamnya. Juga, ambil kunci akses untuk mengakses akun penyimpanan. Lihat Mulai Cepat: Mengunggah, mengunduh, dan mencantumkan blob dengan portal Azure.
Buat Akun penyimpanan Azure Data Lake Storage Gen2. Lihat Mulai Cepat: Membuat akun penyimpanan Azure Data Lake Storage Gen2.
Membuat perwakilan layanan. Lihat Cara: Menggunakan portal untuk membuat aplikasi microsoft Entra ID (sebelumnya Azure Active Directory) dan perwakilan layanan yang dapat mengakses sumber daya.
Ada beberapa hal spesifik yang harus Anda lakukan saat melakukan langkah-langkah dalam artikel itu.
Saat melakukan langkah tersebut di bagian artikel️Menetapkan aplikasi ke peran, pastikan untuk menetapkan peran Storage Blob Data Contributor ke prinsipal layanan di cakupan akun Data Lake Storage Gen2. Jika Anda menetapkan peran ke grup sumber daya induk atau langganan, Anda akan menerima kesalahan terkait izin sampai penetapan peran tersebut menyebar luas ke akun penyimpanan.
Jika Anda lebih suka menggunakan daftar kontrol akses (ACL) untuk mengaitkan prinsipal layanan dengan file atau direktori tertentu, referensi Kontrol akses di Azure Data Lake Storage Gen2.
Saat melakukan langkah tersebut di bagian artikel ️Dapatkan nilai untuk masuk, tempel ID penyewa, ID aplikasi, dan nilai rahasia ke dalam file teks.
Masuk ke portal Azure.
Mengumpulkan informasi yang Anda butuhkan
Pastikan Anda memenuhi prasyarat untuk tutorial ini.
Sebelum Anda mulai, Anda harus memiliki item informasi ini:
✔️ Nama database, nama server database, nama pengguna, dan kata sandi Azure Synapse Anda.
✔️ Kunci akses akun penyimpanan blob Anda.
✔️ Nama akun penyimpanan Data Lake Storage Gen2 Anda.
✔️ ID penyewa langganan Anda.
✔️ ID aplikasi aplikasi yang Anda daftarkan dengan MICROSOFT Entra ID (sebelumnya Azure Active Directory).
✔️ Kunci autentikasi untuk aplikasi yang Anda daftarkan dengan ID Microsoft Entra (sebelumnya Azure Active Directory).
Membuat layanan Azure Databricks
Di bagian ini, Anda membuat layanan Azure Databricks menggunakan portal Microsoft Azure.
Pada menu portal Microsoft Azure, pilih Buat sumber daya.
Kemudian, pilih Analytics>Azure Databricks.
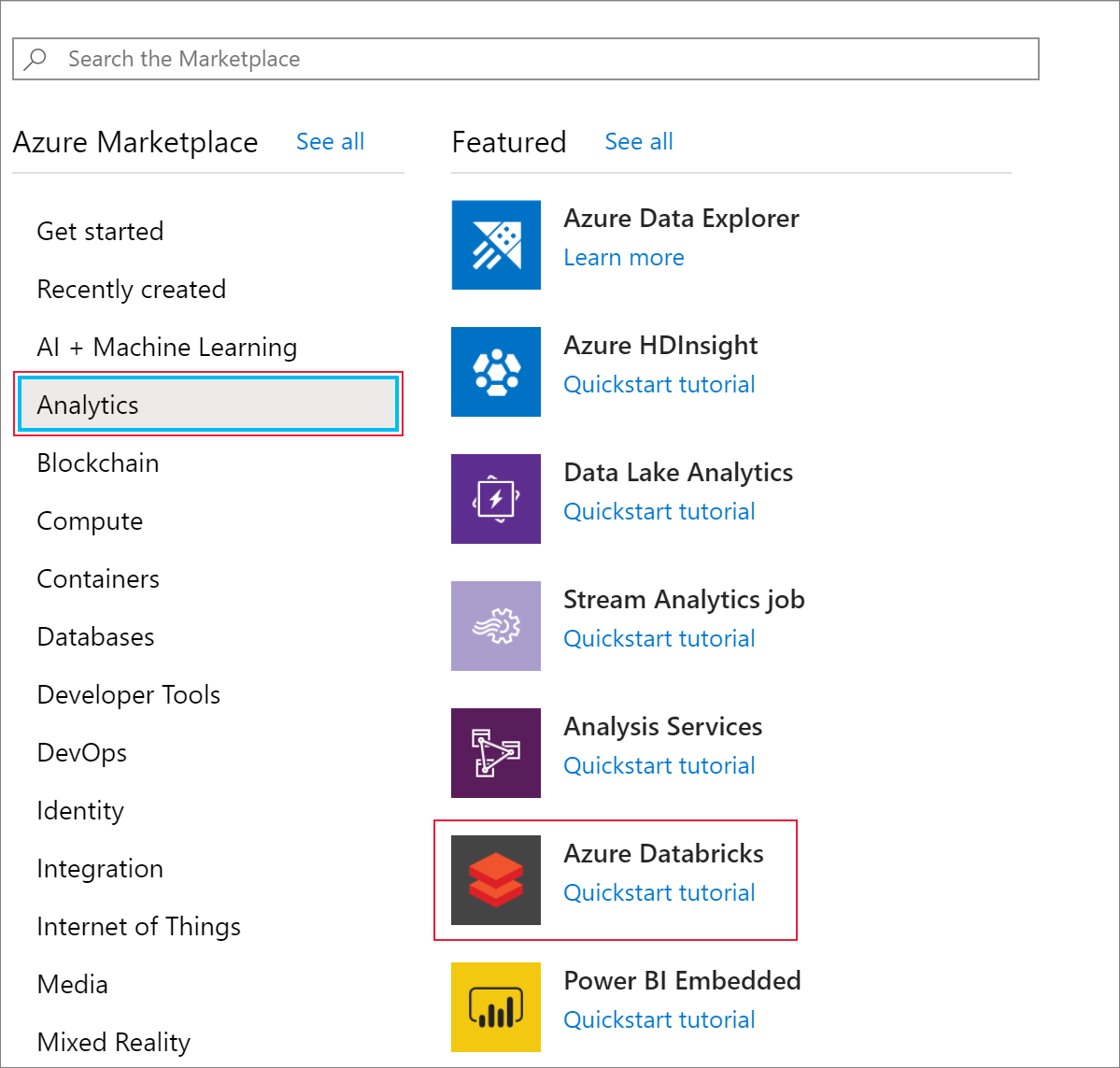
Di bawah Layanan Azure Databricks, berikan nilai berikut untuk membuat layanan Databricks:
Properti Deskripsi Nama ruang kerja Memberi nama untuk ruang kerja Databricks Anda. Langganan Dari menu dropdown, pilih langganan Azure Anda. Grup sumber daya Tentukan apakah Anda ingin membuat grup sumber daya baru atau menggunakan grup sumber daya yang sudah ada. Grup sumber daya adalah kontainer yang menampung sumber daya terkait untuk solusi Azure. Untuk informasi selengkapnya, lihat Ringkasan Azure Resource Group. Location Pilih Barat US 2. Untuk wilayah lain yang tersedia, lihat Layanan Azure yang tersedia menurut wilayah. Tingkatan harga Pilih Standar. Pembuatan akun memakan waktu beberapa menit. Untuk memantau status operasi, lihat bilah kemajuan di bagian atas.
Pilih Sematkan ke Dasbor lalu pilih Buat.
Membuat kluster Spark di Azure Databricks
Di portal Microsoft Azure, buka layanan Databricks yang Anda buat, dan pilih Luncurkan Ruang Kerja.
Anda dialihkan ke portal Azure Databricks. Dari portal, pilih Kluster.

Di halaman Kluster baru, berikan nilai untuk membuat kluster.

Isi nilai untuk bidang berikut ini, dan terima nilai default untuk bidang lainnya:
Masukkan nama untuk kluster.
Pastikan Anda memilih kotak centang Hentikan setelah __ menit tidak aktif. Jika kluster tidak digunakan, berikan durasi (dalam hitungan menit) untuk mengakhiri kluster.
Pilih Buat kluster. Setelah kluster berjalan, Anda dapat melampirkan buku catatan ke kluster dan menjalankan pekerjaan Spark.
Membuat sistem file di akun Azure Data Lake Storage Gen2
Di bagian ini, Anda membuat buku catatan di ruang kerja Azure Databricks dan kemudian menjalankan cuplikan kode untuk mengonfigurasi akun penyimpanan
Di portal Microsoft Azure, masuk ke layanan Azure Databricks yang Anda buat, dan pilih Luncurkan Ruang Kerja.
Di sebelah kiri, pilih Ruang Kerja. Dari pilihan menurun Ruang Kerja, pilih Buat Buku>Catatan.

Dalam kotak dialog Buat Buku Catatan, masukkan nama untuk buku catatan tersebut. Pilih Scala sebagai bahasa, lalu pilih kluster Spark yang Anda buat sebelumnya.

Pilih Buat.
Blok kode berikut menetapkan info masuk perwakilan layanan default untuk akun ADLS Gen 2 apa pun yang diakses di sesi Spark. Blok kode kedua menambahkan nama akun ke pengaturan guna menentukan info masuk untuk akun ADLS Gen 2 tertentu. Salin dan tempel blok kode ke sel pertama buku catatan Azure Databricks Anda.
Konfigurasi sesi
val appID = "<appID>" val secret = "<secret>" val tenantID = "<tenant-id>" spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appID>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<secret>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant-id>/oauth2/token") spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "true")Konfigurasi akun
val storageAccountName = "<storage-account-name>" val appID = "<app-id>" val secret = "<secret>" val fileSystemName = "<file-system-name>" val tenantID = "<tenant-id>" spark.conf.set("fs.azure.account.auth.type." + storageAccountName + ".dfs.core.windows.net", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type." + storageAccountName + ".dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id." + storageAccountName + ".dfs.core.windows.net", "" + appID + "") spark.conf.set("fs.azure.account.oauth2.client.secret." + storageAccountName + ".dfs.core.windows.net", "" + secret + "") spark.conf.set("fs.azure.account.oauth2.client.endpoint." + storageAccountName + ".dfs.core.windows.net", "https://login.microsoftonline.com/" + tenantID + "/oauth2/token") spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "true") dbutils.fs.ls("abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/") spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "false")Dalam blok kode ini, ganti nilai placeholder
<app-id>,<secret>,<tenant-id>, dan<storage-account-name>dalam blok kode ini dengan nilai yang Anda kumpulkan saat menyelesaikan prasyarat tutorial ini. Ganti nilai placeholder<file-system-name>dengan nama apa pun yang ingin Anda berikan pada sistem file.<app-id>dan<secret>berasal dari aplikasi yang Anda daftarkan dengan direktori aktif sebagai bagian dari pembuatan perwakilan layanan.<tenant-id>ini dari langganan Anda.<storage-account-name>ini adalah nama akun penyimpanan Azure Data Lake Storage Gen2 Anda.
Tekan kunci SHIFT + ENTER untuk menjalankan kode di blok ini.
Menyerap sampel data ke akun Azure Data Lake Storage Gen2
Sebelum memulai sesi ini, Anda harus menyelesaikan prasyarat berikut:
Masukkan kode berikut ke dalam sel buku catatan:
%sh wget -P /tmp https://raw.githubusercontent.com/Azure/usql/master/Examples/Samples/Data/json/radiowebsite/small_radio_json.json
Pada sel, tekan SHIFT + ENTER untuk menjalankan kode.
Sekarang di sel baru di bawah ini, masukkan kode berikut, dan ganti nilai yang muncul dalam tanda kurung dengan nilai yang sama dengan yang Anda gunakan sebelumnya:
dbutils.fs.cp("file:///tmp/small_radio_json.json", "abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/")
Pada sel, tekan SHIFT + ENTER untuk menjalankan kode.
Mengekstrak data dari akun Azure Data Lake Storage Gen2
Anda sekarang dapat memuat file json sampel sebagai bingkai data di Azure Databricks. Tempel kode berikut di sel baru. Ganti placeholder yang ditampilkan dalam tanda kurung dengan nilai Anda.
val df = spark.read.json("abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/small_radio_json.json")Tekan kunci SHIFT + ENTER untuk menjalankan kode di blok ini.
Jalankan kode berikut untuk melihat isi bingkai data:
df.show()Anda akan melihat output yang mirip dengan gambar berikut:
+---------------------+---------+---------+------+-------------+----------+---------+-------+--------------------+------+--------+-------------+---------+--------------------+------+-------------+------+ | artist| auth|firstName|gender|itemInSession| lastName| length| level| location|method| page| registration|sessionId| song|status| ts|userId| +---------------------+---------+---------+------+-------------+----------+---------+-------+--------------------+------+--------+-------------+---------+--------------------+------+-------------+------+ | El Arrebato |Logged In| Annalyse| F| 2|Montgomery|234.57914| free | Killeen-Temple, TX| PUT|NextSong|1384448062332| 1879|Quiero Quererte Q...| 200|1409318650332| 309| | Creedence Clearwa...|Logged In| Dylann| M| 9| Thomas|340.87138| paid | Anchorage, AK| PUT|NextSong|1400723739332| 10| Born To Move| 200|1409318653332| 11| | Gorillaz |Logged In| Liam| M| 11| Watts|246.17751| paid |New York-Newark-J...| PUT|NextSong|1406279422332| 2047| DARE| 200|1409318685332| 201| ... ...Anda sekarang telah mengekstrak data dari Azure Data Lake Storage Gen2 ke Azure Databricks.
Transform data di Azure Databricks
File small_radio_json.json data sampel mentah mengambil penonton untuk stasiun radio dan memiliki berbagai kolom. Di bagian ini, Anda mengubah data menjadi hanya mengambil kolom tertentu dari himpunan data.
Pertama, ambil hanya kolom firstName, lastName, jenis kelamin, lokasi, dan tingkat dari dataframe yang Anda buat.
val specificColumnsDf = df.select("firstname", "lastname", "gender", "location", "level") specificColumnsDf.show()Anda menerima output seperti yang ditunjukkan dalam cuplikan berikut:
+---------+----------+------+--------------------+-----+ |firstname| lastname|gender| location|level| +---------+----------+------+--------------------+-----+ | Annalyse|Montgomery| F| Killeen-Temple, TX| free| | Dylann| Thomas| M| Anchorage, AK| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Tess| Townsend| F|Nashville-Davidso...| free| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| |Gabriella| Shelton| F|San Jose-Sunnyval...| free| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Tess| Townsend| F|Nashville-Davidso...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Alan| Morse| M|Chicago-Napervill...| paid| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| +---------+----------+------+--------------------+-----+Anda dapat mengubah data ini lebih lanjut untuk mengganti nama tingkat kolom menjadi subscription_type.
val renamedColumnsDF = specificColumnsDf.withColumnRenamed("level", "subscription_type") renamedColumnsDF.show()Anda menerima output seperti yang ditunjukkan pada cuplikan berikut.
+---------+----------+------+--------------------+-----------------+ |firstname| lastname|gender| location|subscription_type| +---------+----------+------+--------------------+-----------------+ | Annalyse|Montgomery| F| Killeen-Temple, TX| free| | Dylann| Thomas| M| Anchorage, AK| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Tess| Townsend| F|Nashville-Davidso...| free| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| |Gabriella| Shelton| F|San Jose-Sunnyval...| free| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Tess| Townsend| F|Nashville-Davidso...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Liam| Watts| M|New York-Newark-J...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Alan| Morse| M|Chicago-Napervill...| paid| | Elijah| Williams| M|Detroit-Warren-De...| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| | Alan| Morse| M|Chicago-Napervill...| paid| | Dylann| Thomas| M| Anchorage, AK| paid| | Margaux| Smith| F|Atlanta-Sandy Spr...| free| +---------+----------+------+--------------------+-----------------+
Memuat data ke Azure Synapse
Di bagian ini, Anda mengunggah data yang diubah ke Azure Synapse. Anda menggunakan konektor Azure Synapse untuk Azure Databricks untuk langsung mengunggah bingkai data sebagai tabel di kumpulan Synapse Spark.
Seperti disebutkan sebelumnya, konektor Azure Synapse menggunakan penyimpanan Azure Blob sebagai penyimpanan sementara untuk mengunggah data antara Azure Databricks dan Azure Synapse. Jadi, Anda mulai dengan menyediakan konfigurasi untuk terhubung ke akun penyimpanan. Anda pasti sudah membuat akun sebagai bagian dari prasyarat untuk artikel ini.
Menyediakan konfigurasi untuk mengakses akun Azure Storage dari Azure Databricks.
val blobStorage = "<blob-storage-account-name>.blob.core.windows.net" val blobContainer = "<blob-container-name>" val blobAccessKey = "<access-key>"Tentukan folder sementara yang akan digunakan saat memindahkan data antara Azure Databricks dan Azure Synapse.
val tempDir = "wasbs://" + blobContainer + "@" + blobStorage +"/tempDirs"Jalankan cuplikan berikut untuk menyimpan kunci akses penyimpanan Azure Blob dalam konfigurasi. Tindakan ini memastikan bahwa Anda tidak perlu menyimpan kunci akses di buku catatan dalam teks biasa.
val acntInfo = "fs.azure.account.key."+ blobStorage sc.hadoopConfiguration.set(acntInfo, blobAccessKey)Berikan nilai untuk terhubung ke instans Azure Synapse. Anda harus sudah membuat layanan Azure Synapse Analytics sebagai prasyarat. Gunakan nama server yang sepenuhnya memenuhi syarat untuk dwServer. Contohnya,
<servername>.database.windows.net.//Azure Synapse related settings val dwDatabase = "<database-name>" val dwServer = "<database-server-name>" val dwUser = "<user-name>" val dwPass = "<password>" val dwJdbcPort = "1433" val dwJdbcExtraOptions = "encrypt=true;trustServerCertificate=true;hostNameInCertificate=*.database.windows.net;loginTimeout=30;" val sqlDwUrl = "jdbc:sqlserver://" + dwServer + ":" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPass + ";$dwJdbcExtraOptions" val sqlDwUrlSmall = "jdbc:sqlserver://" + dwServer + ":" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPassJalankan cuplikan berikut untuk memuat dataframe yang diubah, renamedColumnsDF, sebagai tabel di Azure Synapse. Cuplikan ini membuat tabel yang disebut SampleTable di database SQL.
spark.conf.set( "spark.sql.parquet.writeLegacyFormat", "true") renamedColumnsDF.write.format("com.databricks.spark.sqldw").option("url", sqlDwUrlSmall).option("dbtable", "SampleTable") .option( "forward_spark_azure_storage_credentials","True").option("tempdir", tempDir).mode("overwrite").save()Catatan
Sampel ini menggunakan bendera
forward_spark_azure_storage_credentials, yang menyebabkan Azure Synapse mengakses data dari penyimpanan blob menggunakan Kunci Akses. Ini adalah satu-satunya metode autentikasi yang didukung.Jika Azure Blob Storage Anda dibatasi untuk memilih jaringan virtual, Azure Synapse memerlukan Identitas Layanan Terkelola, bukan Kunci Akses. Ini akan menyebabkan kesalahan "Permintaan ini tidak diizinkan untuk melakukan operasi ini".
Sambungkan ke database SQL dan verifikasi bahwa Anda melihat database bernama SampleTable.

Jalankan kueri pilih untuk memverifikasi konten tabel. Tabel harus memiliki data yang sama dengan dataframe renamedColumnsDF.

Membersihkan sumber daya
Setelah menyelesaikan tutorial, Anda dapat mengakhiri kluster. Dari ruang kerja Azure Databricks, pilih Kluster di sebelah kiri. Agar kluster dihentikan, pada Tindakan, arahkan ke elipsis (...) dan pilih ikon Hentikan.

Jika Anda tidak menghentikan kluster secara manual, kluster tersebut akan berhenti secara otomatis, asalkan Anda memilih kotak centang Hentikan setelah __ menit tidak aktif saat Anda membuat kluster. Dalam kasus seperti itu, kluster secara otomatis berhenti jika tidak aktif untuk waktu yang ditentukan.
Langkah berikutnya
Dalam tutorial ini, Anda mempelajari cara:
- Membuat layanan Azure Databricks
- Membuat kluster Spark di Azure Databricks
- Membuat buku catatan di Azure Databricks
- Mengekstrak data dari akun Data Lake Storage Gen2
- Transform data di Azure Databricks
- Memuat data ke Azure Synapse