Konfigurasikan perulangan pembelajaran Personalizer
Penting
Mulai tanggal 20 September 2023 Anda tidak akan dapat membuat sumber daya Personalizer baru. Layanan Personalizer dihentikan pada tanggal 1 Oktober 2026.
Konfigurasi layanan mencakup bagaimana layanan memperlakukan hadiah, seberapa sering layanan mengeksplorasi, seberapa sering model dilatih kembali, dan berapa banyak data yang disimpan.
Konfigurasikan perulangan pembelajaran di halaman Konfigurasi, di portal Microsoft Azure untuk sumber daya Personalizer tersebut.
Merencanakan perubahan konfigurasi
Karena beberapa perubahan konfigurasi menyetel ulang model Anda, Anda harus merencanakan perubahan konfigurasi Anda.
Jika Anda berencana untuk menggunakanmode Apprentice, pastikan untuk meninjau konfigurasi Personalizer Anda sebelum beralih ke mode Apprentice.
Pengaturan yang menyertakan pengaturan ulang model
Tindakan berikut memicu pelatihan ulang model menggunakan data yang tersedia hingga 2 hari terakhir.
- Hadiah
- Penjelajahan
Untuk menghapus semua data Anda, gunakan halaman Pengaturan model dan pembelajaran.
Mengonfigurasi hadiah untuk perulangan umpan balik
Konfigurasikan layanan untuk penggunaan hadiah perulangan pembelajaran Anda. Perubahan pada nilai berikut akan menyetel ulang model Personalizer saat ini dan melatihnya kembali dengan data 2 hari terakhir.
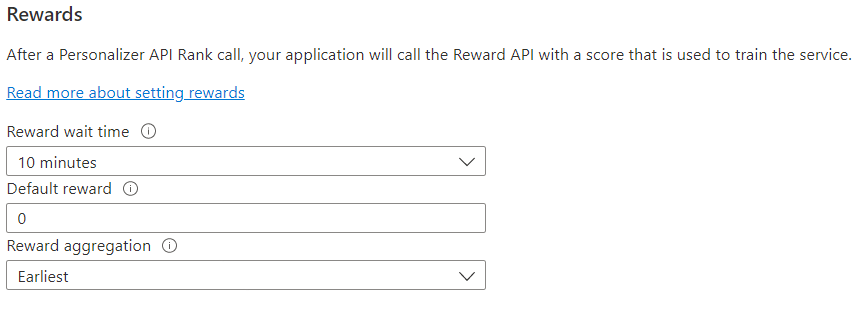
| Nilai | Kegunaan |
|---|---|
| Waktu tunggu hadiah | Mengatur durasi waktu yang nilai hadiah untuk panggilan Peringkat akan dikumpulkan Personalizer, mulai dari saat panggilan Peringkat dilakukan. Nilai ini diatur dengan menanyakan: "Berapa lama Personalizer harus menunggu panggilan hadiah?" Hadiah apa pun yang diterima setelah jendela ini akan dicatat tetapi tidak digunakan untuk pembelajaran. |
| Hadiah default | Jika tidak ada panggilan hadiah yang diterima oleh Personalizer selama jendela Waktu Tunggu Hadiah yang terkait dengan panggilan Peringkat, Personalizer akan menetapkan Hadiah Default. Secara default, dan dalam sebagian besar skenario, Hadiah Default adalah nol (0). |
| Agregasi hadiah | Jika beberapa hadiah diterima untuk panggilan API Rank yang sama, metode agregasi ini digunakan: sum atau earliest. Earliest memilih skor paling awal yang diterima dan membuang sisanya. Ini berguna jika Anda menginginkan hadiah unik di antara kemungkinan panggilan duplikat. |
Setelah mengubah nilai ini, pastikan untuk memilih Simpan.
Konfigurasikan eksplorasi untuk memungkinkan perulangan pembelajaran beradaptasi
Personalisasi mampu menemukan pola baru dan beradaptasi dengan perubahan perilaku pengguna dari waktu ke waktu dengan mengeksplorasi alternatif alih-alih menggunakan prediksi model terlatih. Nilai Eksplorasi menentukan persentase panggilan Peringkat apa yang dijawab dengan eksplorasi.
Perubahan pada nilai ini akan menyetel ulang model Personalizer saat ini dan melatihnya kembali dengan data 2 hari terakhir.
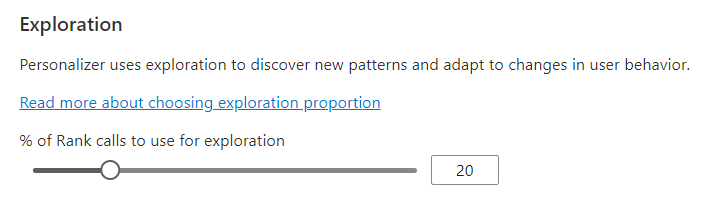
Setelah mengubah nilai ini, pastikan untuk memilih Simpan.
Konfigurasikan frekuensi pembaruan model untuk pelatihan model
Frekuensi pembaruan model mengatur seberapa sering model dilatih.
| Pengaturan frekuensi | Kegunaan |
|---|---|
| 1 menit | Frekuensi pembaruan satu menit berguna saat penelusuran kesalahan kode aplikasi menggunakan Personalizer, melakukan demo, atau menguji aspek pembelajaran mesin secara interaktif. |
| 15 menit | Frekuensi pembaruan model tinggi berguna untuk situasi ketika Anda ingin dengan cermat melacak perubahan perilaku pengguna. Contohnya termasuk situs yang berjalan di berita langsung, konten viral, atau penawaran produk langsung. Anda bisa menggunakan frekuensi 15 menit dalam skenario ini. |
| 1 jam | Untuk sebagian besar kasus penggunaan, frekuensi pembaruan yang lebih rendah efektif. |
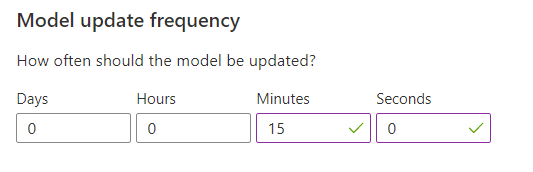
Setelah mengubah nilai ini, pastikan untuk memilih Simpan.
Retensi data
Periode retensi data menetapkan berapa hari Personalizer menyimpan log data. Log data sebelumnya diperlukan untuk melakukan evaluasi offline, yang digunakan untuk mengukur efektivitas Personalizer dan mengoptimalkan Kebijakan Pembelajaran.
Setelah mengubah nilai ini, pastikan untuk memilih Simpan.