Mendapatkan posisi wajah dengan viseme
Catatan
Untuk menjelajahi lokal yang didukung untuk ID viseme dan bentuk campuran, lihat daftar semua lokal yang didukung. Scalable Vector Graphics (SVG) hanya didukung untuk en-US lokal.
Viseme adalah deskripsi visual dari sebuah fonem dalam bahasa lisan. Ini menentukan posisi wajah dan mulut ketika seseorang berbicara. Setiap viseme menggambarkan pose kunci wajah untuk seperangkat fonem tertentu.
Anda dapat menggunakan viseme untuk mengontrol pergerakan model avatar 2D dan 3D, sehingga posisi wajah sesuai dengan ucapan sintetis. Misalnya, Anda dapat:
- Membuat asisten suara virtual animasi untuk kios cerdas, membangun layanan terintegrasi multi-mode untuk pelanggan Anda.
- Membangun siaran berita imersif dan menyempurnakan pengalaman audiens dengan gerakan wajah dan mulut yang alami.
- Menghasilkan lebih banyak avatar game interaktif dan karakter kartun yang dapat berbicara dengan konten dinamis.
- Buat video pengajaran bahasa yang lebih efektif yang membantu pelajar bahasa untuk memahami perilaku mulut dari setiap kata dan fonem.
- Orang dengan gangguan pendengaran juga dapat mendengar suara secara visual dan konten ucapan "membaca bibir" yang menunjukkan viseme pada wajah animasi.
Untuk informasi selengkapnya tentang viseme, lihat video pengantar ini.
Alur kerja keseluruhan memproduksi viseme dengan ucapan
Teks Neural ke ucapan (Neural TTS) mengubah teks input atau SSML (Speech Synthesis Markup Language) menjadi ucapan yang disintesis seperti hidup. Output audio ucapan dapat disertai dengan ID viseme, Scalable Vector Graphics (SVG), atau bentuk campuran. Menggunakan mesin rendering 2D atau 3D, Anda dapat menggunakan peristiwa viseme ini untuk menghidupkan avatar Anda.
Alur kerja keseluruhan viseme digambarkan dalam diagram alur berikut:
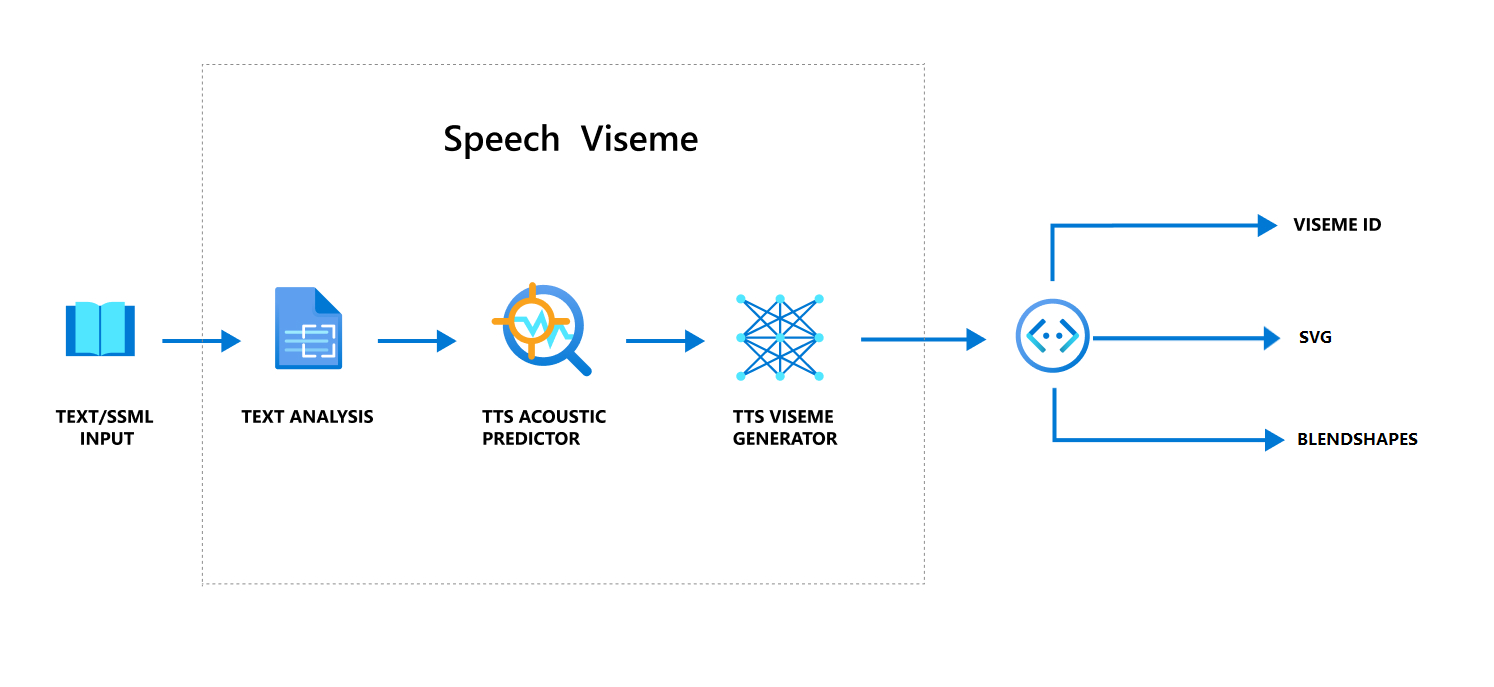
ID Visem
ID Viseme mengacu pada bilangan bulat yang menentukan viseme. Kami menawarkan 22 viseme yang berbeda, masing-masingnya menggambarkan posisi mulut untuk satu set fonem tertentu. Tidak ada korespondensi satu-ke-satu antara viseme dan fonem. Seringkali, beberapa fonem sesuai dengan satu viseme, karena terlihat sama pada wajah speaker ketika diproduksi, seperti s dan z. Untuk informasi lebih spesifik, lihat tabel untuk memetakan fonem untuk ID viseme.
Output audio ucapan dapat disertai dengan ID viseme dan Audio offset. Audio offset menunjukkan tanda waktu offset yang mewakili waktu mulai setiap viseme, dalam tanda waktu (100 nanodetik).
Petakan fonem ke visem
Viseme bervariasi menurut bahasa dan lokal. Setiap lokal memiliki serangkaian visem yang sesuai dengan fonem spesifiknya. Dokumentasi alfabet fonetik SSML memetakan ID viseme ke fonem Alfabet Fonetik Internasional (IPA) yang sesuai. Tabel di bagian ini menunjukkan hubungan pemetaan antara ID viseme dan posisi mulut, mencantumkan fonem IPA umum untuk setiap ID viseme.
| ID Visem | IPA | Posisi mulut |
|---|---|---|
| 0 | Hening |  |
| 1 | æ, , əʌ |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 4 | ɛ, ʊ |
 |
| 5 | ɝ |
 |
| 6 | j, , iɪ |
 |
| 7 | w, u |
 |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | s, z |
 |
| 16 | ʃ, , tʃdʒ,ʒ |
 |
| 17 | ð |
 |
| 18 | f, v |
 |
| 19 | d, , tn,θ |
 |
| 20 | k, , gŋ |
 |
| 21 | p, , bm |
 |
Animasi SVG 2D
Untuk karakter 2D, Anda dapat merancang karakter yang sesuai dengan skenario Anda dan menggunakan Scalable Vector Graphics (SVG) untuk setiap ID viseme untuk mendapatkan posisi wajah berbasis waktu.
Dengan tag temporal yang disediakan dalam acara viseme, SVG yang dirancang dengan baik ini diproses dengan modifikasi smoothing, dan memberikan animasi yang kuat kepada pengguna. Misalnya, ilustrasi berikut menunjukkan karakter berlip merah yang dirancang untuk pembelajaran bahasa.

Animasi bentuk campuran 3D
Anda dapat menggunakan bentuk campuran untuk mendorong gerakan wajah dari karakter 3D yang Anda rancang.
String JSON bentuk campuran direpresentasikan sebagai matriks 2 dimensi. Setiap baris merepresentasikan bingkai. Setiap bingkai (dalam 60 FPS) berisi array 55 posisi wajah.
Dapatkan peristiwa viseme dengan Speech SDK
Untuk mendapatkan viseme dengan ucapan yang disintesis, berlangganan ke peristiwa VisemeReceived di SDK Ucapan.
Catatan
Untuk meminta output SVG atau bentuk campuran, Anda harus menggunakan elemen mstts:viseme di SSML. Untuk detailnya, lihat cara menggunakan elemen viseme di SSML.
Cuplikan berikut menunjukkan cara berlangganan peristiwa viseme:
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
Berikut adalah contoh output viseme.
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
Setelah mendapatkan output viseme, Anda dapat menggunakan peristiwa ini untuk menggerakkan animasi karakter. Anda dapat membangun karakter Anda sendiri dan secara otomatis menganimasikannya.