Merekam sampel suara untuk suara saraf kustom
Artikel ini memberi Anda instruksi tentang menyiapkan sampel suara berkualitas tinggi untuk membuat model suara profesional menggunakan proyek pro suara neural kustom.
Menciptakan suara neural kustom produksi berkualitas tinggi dari awal bukanlah usaha biasa. Komponen sentral dari suara saraf kustom adalah banyak koleksi sampel audio ucapan manusia. Sangat penting bahwa rekaman audio ini berkualitas tinggi. Pilih bakat suara yang memiliki pengalaman membuat rekaman semacam ini, dan rekamlah oleh insinyur rekaman menggunakan peralatan profesional.
Namun, sebelum Anda dapat membuat rekaman ini, Anda memerlukan skrip: kata-kata diucapkan oleh bakat suara Anda untuk membuat sampel audio.
Banyak detail kecil tapi penting masuk ke dalam membuat rekaman suara profesional. Panduan ini adalah peta jalan untuk proses yang akan membantu Anda mendapatkan hasil yang baik dan konsisten.
Tips untuk menyiapkan data untuk suara berkualitas tinggi
Suara saraf kustom yang sangat alami tergantung pada beberapa faktor, seperti kualitas dan ukuran data pelatihan Anda.
Kualitas data pelatihan Anda adalah faktor utama. Misalnya, dalam set pelatihan yang sama, volume yang konsisten, tingkat berbicara, pitch berbicara, dan gaya berbicara sangat penting untuk membuat suara saraf kustom berkualitas tinggi. Anda juga harus menghindari kebisingan latar belakang dalam rekaman dan memastikan skrip dan rekaman cocok. Untuk memastikan kualitas data, Anda perlu mengikuti kriteria pemilihan skrip dan persyaratan perekaman.
Mengenai ukuran data pelatihan, dalam banyak kasus Anda dapat membangun suara neural kustom yang wajar dengan 500 ucapan. Menurut pengujian kami, menambahkan lebih banyak data pelatihan dalam sebagian besar bahasa tidak selalu meningkatkan keaslian suara itu sendiri (diuji menggunakan skor MOS), namun, dengan lebih banyak data pelatihan yang mencakup lebih banyak instans kata, Anda memiliki kemungkinan yang lebih tinggi untuk mengurangi rasio bagian ucapan yang tidak memuaskan untuk suara, seperti gangguan. Untuk mendengar bagian suara ucapan yang tidak memuaskan seperti apa, lihat contoh GitHub.
Dalam beberapa kasus, Anda mungkin menginginkan persona suara dengan karakteristik unik. Misalnya, persona kartun membutuhkan suara dengan gaya berbicara khusus, atau suara yang dinamis dalam intonasi. Untuk kasus seperti itu, kami sarankan Anda menyiapkan setidaknya 1000 ungkapan (sebaiknya 2000), dan merekamnya di studio rekaman profesional. Untuk mempelajari selengkapnya tentang cara meningkatkan kualitas model suara Anda, lihat karakteristik dan batasan untuk menggunakan suara neural kustom.
Peran perekaman suara
Ada empat peran dasar dalam proyek perekaman suara saraf kustom:
| Role | Tujuan |
|---|---|
| Bakat suara | Suara orang ini membentuk dasar suara saraf kustom. |
| Insinyur perekaman | Mengawasi aspek teknis perekaman dan mengoperasikan peralatan perekaman. |
| Direktur | Siapkan naskah dan melatih performa bakat suara. |
| Editor | Menyelesaikan file audio dan menyiapkannya untuk diunggah ke Speech Studio |
Individu dapat mengisi lebih dari satu peran. Panduan ini mengasumsikan bahwa Anda mengisi peran sutradara dan mempekerjakan bakat suara dan insinyur rekaman. Jika Anda ingin membuat rekaman sendiri, artikel ini menyertakan beberapa informasi tentang peran insinyur rekaman. Peran editor tidak diperlukan sampai setelah sesi perekaman. Sementara itu, sutradara atau teknisi rekaman dapat mengisi peran ini.
Pilih bakat suara Anda
Aktor dengan pengalaman dalam voiceover, pekerjaan karakter suara, mengumumkan atau membaca berita membuat bakat suara yang baik. Pilih bakat suara yang suara alaminya Anda sukai. Dimungkinkan untuk membuat suara "karakter" yang unik, tetapi lebih sulit bagi sebagian besar talenta untuk melakukannya secara konsisten, dan upaya tersebut dapat menyebabkan ketegangan suara. Satu-satunya faktor terpenting untuk memilih bakat suara adalah konsistensi. Rekaman Anda untuk gaya suara yang sama semua harus terdengar seperti dibuat pada hari yang sama di ruangan yang sama. Anda dapat mendekati cita-cita ini melalui praktik perekaman dan rekayasa yang baik.
Pengisi suara Anda harus dapat berbicara dengan tingkat yang konsisten, tingkat volume, pitch, dan nada dengan dikte yang jelas. Mereka juga harus dapat mengontrol variasi nada mereka, efek emosional, dan perilaku ucapan. Merekam sampel suara bisa lebih melelahkan daripada jenis pekerjaan suara lainnya, sehingga sebagian besar talenta suara hanya dapat merekam selama dua atau tiga jam sehari. Batasi sesi hingga tiga atau empat hari seminggu, dengan hari libur di antaranya jika memungkinkan.
Bekerja sama dengan pengisi suara Anda untuk mengembangkan persona yang mendefinisikan suara keseluruhan dan nada emosional dari suara neural kustom, memastikan untuk menentukan suara "netral" apa yang terdengar serupa untuk persona itu. Anda menentukan gaya berbicara persona Anda dan meminta bakat suara Anda untuk membaca naskah dengan cara yang sesuai dengan gaya yang Anda inginkan.
Misalnya, persona dengan kepribadian optimis yang alami akan membawa aura optimis bahkan ketika mereka berbicara secara netral. Namun, sifat kepribadian seperti itu harus halus dan konsisten. Dengarkan bacaan dengan suara yang ada untuk mendapatkan gambaran tentang apa yang Anda tuju.
Tip
Biasanya, Anda ingin memiliki rekaman suara yang Anda buat. Bakat suara Anda harus dapat diberikan pada kontrak kerja-untuk-menyewa untuk proyek.
Membuat skrip
Titik awal dari setiap sesi perekaman suara saraf kustom adalah skrip, yang berisi ucapan yang akan diucapkan oleh bakat suara Anda. Istilah "ucapan" mencakup kalimat lengkap dan frasa yang lebih pendek. Membuat suara neural kustom memerlukan setidaknya 300 ucapan yang direkam sebagai data pelatihan.
Ungkapan dalam naskah Anda dapat datang dari mana saja: fiksi, non-fiksi, transkrip ucapan, laporan berita, dan apa pun yang tersedia dalam bentuk cetak. Untuk diskusi singkat tentang potensi masalah hukum, lihat bagian "Legalitas". Anda juga dapat menulis teks Anda sendiri.
Ucapan Anda tidak perlu berasal dari sumber yang sama, jenis sumber yang sama, atau ada hubungannya satu sama lain. Namun, jika Anda akan menggunakan frasa yang diatur (misalnya, "Anda telah berhasil masuk") di aplikasi ucapan Anda, pastikan untuk menyertakannya dalam skrip Anda. Ini memberi suara saraf kustom Anda kesempatan yang lebih baik untuk mengucapkan frasa tersebut dengan baik.
Kami merekomendasikan skrip rekaman menyertakan kalimat umum dan kalimat khusus domain Anda. Misalnya, jika Anda berencana untuk merekam 2.000 kalimat, 1.000 di antaranya bisa berupa kalimat umum, 1.000 lainnya bisa berupa kalimat dari domain target Anda atau kasus penggunaan aplikasi Anda.
Kami menyediakan contoh naskah di domain 'Umum', 'Obrolan', dan 'Layanan Pelanggan' untuk setiap bahasa untuk membantu Anda menyiapkan naskah rekaman Anda. Anda dapat menggunakan naskah bersama Microsoft ini untuk rekaman Anda secara langsung atau menggunakannya sebagai referensi untuk membuat naskah Anda sendiri.
Kriteria seleksi naskah
Berikut adalah beberapa panduan umum yang dapat Anda ikuti untuk membuat corpus yang baik (sampel audio rekaman) untuk pelatihan suara neural kustom.
Seimbangkan naskah Anda untuk mencakup berbagai jenis kalimat di domain Anda termasuk pernyataan, kalimat pertanyaan, kalimat perintah, kalimat panjang, dan kalimat pendek.
Setiap kalimat harus berisi empat kata hingga 30 kata, dan tidak ada kalimat duplikat yang harus disertakan dalam skrip Anda.
Untuk cara menyeimbangkan jenis kalimat yang berbeda, lihat tabel berikut:Tipe kalimat Cakupan Kalimat pernyataan Kalimat pernyataan harus 70-80% dari skrip. Kalimat pertanyaan Kalimat pertanyaan harus 10% -20% dari skrip domain Anda, termasuk 5%-10% nada naik dan 5%-10% nada turun. Kalimat perintah Kalimat seru harus sekitar 10%-20% dari skrip Anda. Kata pendek/frasa Skrip kata pendek/frasa juga harus sekitar 10% kasus dari total ucapan, dengan 5 hingga 7 kata per kasus. Catatan
Kata/frasa pendek harus dipisahkan dengan koma. Mereka membantu mengingatkan pengisi suara Anda untuk jeda singkat saat membacanya.
Praktik terbaiknya termasuk:
- Cakupan seimbang untuk Bagian Ucapan, seperti kata kerja, kata benda, kata sifat, dan sebagainya.
- Cakupan yang seimbang untuk pengucapan. Sertakan semua huruf dari A ke Z sehingga mesin Teks ke ucapan mempelajari cara mengucapkan setiap huruf dalam gaya Anda.
- Skrip yang dapat dibaca, dimengerti, wajar agar mudah dibaca oleh penutur.
- Hindari terlalu banyak pola serupa untuk kata/frasa, seperti "mudah" dan "lebih mudah".
- Sertakan berbagai format angka: alamat, unit, telepon, jumlah, tanggal, dan sebagainya, di semua jenis kalimat.
- Sertakan kalimat ejaan jika itu adalah sesuatu yang akan dibaca suara neural kustom Anda. Misalnya, "Ejaan Apple adalah A P P L E".
Jangan memasukkan beberapa kalimat ke dalam satu baris/satu ucapan. Pisahkan setiap baris dengan ucapan.
Pastikan kalimatnya bersih. Umumnya, jangan sertakan terlalu banyak kata-kata yang tidak biasa seperti angka atau singkatan karena sulit dibaca. Beberapa aplikasi mungkin memerlukan pembacaan banyak angka atau akronim. Dalam hal ini, Anda dapat memasukkan kata-kata ini, tetapi menormalkannya dalam bentuk lisannya.
Berikut adalah beberapa praktik terbaik misalnya:
- Untuk baris dengan singkatan, Anda menyebutkan "by the way", bukan "BTW".
- Untuk baris berisi angka, Anda menyebutkan "nine one one", bukan "911".
- Untuk baris dengan akronim, Anda menyebutkan "A B C", bukan "ABC".
Dengan itu, pastikan pengisi suara Anda mengucapkan kata-kata ini dengan cara yang diharapkan. Jaga agar skrip dan rekaman Anda tetap cocok selama proses pelatihan.
Naskah Anda harus menyertakan banyak kata dan kalimat yang berbeda dengan panjang dan struktur kalimat, serta suasana hati yang bervariasi.
Periksa skrip dengan hati-hati untuk menemukan kesalahan. Jika memungkinkan, mintalah orang lain untuk memeriksanya juga. Ketika Anda menjalankan naskah dengan bakat suara Anda, Anda mungkin menangkap lebih banyak kesalahan.
Perbedaan antara skrip pengisi suara dan skrip pelatihan
Skrip pelatihan dapat berbeda dari skrip pengisi suara, terutama untuk skrip yang berisi digit, simbol, singkatan, tanggal, dan waktu. Skrip yang disiapkan untuk pengisi suara harus mengikuti konvensi pembacaan asli, seperti 50% dan $45. Skrip yang digunakan untuk pelatihan harus dinormalisasi agar sesuai dengan rekaman audio, seperti lima puluh persen dan empat puluh lima dolar.
Catatan
Kami menyediakan beberapa contoh skrip untuk pengisi suara di GitHub. Guna menggunakan contoh skrip untuk pelatihan, Anda harus menormalkannya sesuai dengan rekaman pengisi suara Anda sebelum mengunggah file.
Tabel berikut menunjukkan perbedaan antara skrip untuk pengisi suara dan skrip yang dinormalisasi untuk pelatihan.
| Category | Contoh skrip pengisi suara | Contoh skrip pelatihan (dinormalisasi) |
|---|---|---|
| Digit | 123 | seratus dua puluh tiga |
| Simbol | 50% | lima puluh persen |
| Singkatan | SEGERA | sesegera mungkin |
| Tanggal dan waktu | 3 Maret pukul 17.00 | Tiga Maret pukul lima sore |
Cacat khas dari naskah
Kualitas naskah yang buruk dapat memengaruhi hasil pelatihan. Untuk mencapai hasil pelatihan berkualitas tinggi, sangat penting untuk menghindari cacat.
Cacat skrip umumnya masuk ke dalam kategori berikut:
| Category | Contoh |
|---|---|
| Konten yang tidak berarti. | "Ide hijau tidak berwarna tidur dengan marah." |
| Kalimat yang tidak lengkap. | - "Ini adalah malam terakhir saya" (tidak ada subjek, tidak ada arti khusus) - "Mereka sudah lucu (tidak ada tanda kutip pada akhirnya, itu bukan kalimat lengkap) |
| Kesalahan penulisan pada kalimat. | - Mulai dengan huruf kecil - Tidak ada tanda baca akhir jika diperlukan - Salah eja - Kurangnya tanda baca: tidak ada tanda titik di akhir kalimat (kecuali judul berita) - Akhiri dengan simbol, kecuali koma, pertanyaan, tanda seru - Format yang salah, seperti: - 45$ (seharusnya $45) - Tanpa spasi atau spasi lebih antara kata/tanda baca |
| Duplikasi dalam format yang sama, satu per setiap pola sudah cukup. | - "Now is 1pm in New York" - "Now is 2pm in New York" - "Now is 3pm in New York" - "Now is 1pm in Seattle" - "Now is 1pm in Washington D.C." |
| Kata-kata asing yang tidak biasa: hanya kata asing yang umum digunakan yang dapat diterima dalam skrip kami. | Dalam bahasa Inggris, seseorang mungkin menggunakan kata Prancis "faux" dalam percakapan umum, tetapi ekspresi Prancis seperti "coincer la bulle" tidak bersifat umum. |
| Emoji atau simbol tidak umum lainnya |
Format skrip
Skrip ini untuk digunakan selama sesi rekaman, sehingga Anda dapat mengaturnya dengan cara apa pun yang menurut Anda mudah untuk dikerjakan. Buat file teks yang diperlukan oleh Speech Studio secara terpisah.
Format skrip dasar berisi tiga kolom:
- Jumlah ujaran, mulai dari 1. Penomoran memudahkan semua orang di studio untuk merujuk pada ucapan tertentu ("mari kita coba lagi nomor 356"). Anda bisa menggunakan fitur penomoran nama paragraf Microsoft Word untuk memberi nomor pada baris tabel secara otomatis.
- Kolom kosong tempat Anda menulis kode angka atau waktu ambil dari setiap ucapan untuk membantu Anda menemukannya di rekaman yang sudah selesai.
- Teks ujaran itu sendiri.
Catatan
Sebagian besar studio merekam dalam segmen pendek yang dikenal sebagai "takes". Setiap mengambil biasanya berisi 10 hingga 24 ungkapan. Hanya mencatat nomor take saja sudah cukup untuk menemukan ucapan nanti. Jika Anda merekam di studio yang lebih suka membuat rekaman yang lebih panjang, Anda sebaiknya mencatat kode waktu. Studio akan memiliki tampilan waktu yang menonjol.
Sisakan ruang yang setelah setiap baris untuk menulis catatan. Pastikan bahwa tidak ada ucapan yang terbelah di antara halaman. Beri nomor halaman, dan cetak skrip Anda di satu sisi kertas.
Cetak tiga salinan skrip: satu untuk pengisi suara, satu untuk teknisi, dan satu untuk sutradara (Anda). Gunakan klip kertas alih-alih staples: artis suara berpengalaman memisahkan halaman untuk menghindari kebisingan saat halaman dibalik.
Pernyataan pengisi suara
Untuk melatih suara neural, Anda harus membuat profil bakat suara dengan file audio yang direkam oleh talenta suara yang menyetujui penggunaan data ucapan mereka untuk melatih model suara kustom. Saat menyiapkan skrip rekaman, pastikan Anda menyertakan kalimat pernyataan di bawah ini.
Legalitas
Di bawah undang-undang hak cipta, pembacaan teks berhak cipta oleh aktor mungkin merupakan performa penulis karya yang harus diberi kompensasi. Performa ini tidak akan dikenali dalam produk akhir, suara neural kustom. Meski begitu, legalitas penggunaan karya berhak cipta untuk tujuan ini belum ditetapkan. Microsoft tidak dapat menyediakan nasihat hukum tentang masalah ini; konsultasikan dengan penasihat hukum Anda sendiri.
Untungnya, masalah ini dapat dihindari sepenuhnya. Ada banyak sumber teks yang bisa Anda gunakan tanpa izin atau lisensi.
| Sumber teks | Deskripsi |
|---|---|
| Korpus Arktik CMU | Sekitar 1100 kalimat yang dipilih dari karya di luar hak cipta khusus untuk digunakan dalam proyek sintesis ucapan. Titik awal yang sangat baik. |
| Tidak berfungsi lagi di bawah hak cipta |
Biasanya karya diterbitkan sebelum 1923. Untuk bahasa Inggris, Project Gutenberg menawarkan puluhan ribu karya semacam itu. Anda mungkin ingin fokus pada karya yang lebih baru, karena bahasanya lebih dekat ke bahasa Inggris modern. |
| Kebijakan pemerintah terkait penggunaan karya | Karya yang dibuat oleh pemerintah Amerika Serikat tidak dilindungi hak cipta dalam Amerika Serikat, meskipun pemerintah dapat mengklaim hak cipta di negara/wilayah lain. |
| Domain publik | Bekerja di mana hak cipta secara eksplisit ditolak atau didedikasikan untuk domain publik. Mungkin tidak mungkin untuk melepaskan hak cipta sepenuhnya di beberapa yurisdiksi. |
| Karya berlisensi permisif | Karya didistribusikan di bawah lisensi seperti Creative Commons atau GNU Free Documentation License (GFDL). Wikipedia menggunakan GFDL. Namun, beberapa lisensi dapat memberlakukan pembatasan pada performa konten berlisensi yang mungkin memengaruhi pembuatan model suara neural kustom, jadi baca lisensi dengan hati-hati. |
Merekam skrip Anda
Rekam skrip Anda di studio rekaman profesional yang berspesialisasi dalam pekerjaan suara. Mereka memiliki bilik rekaman, peralatan yang tepat, dan orang yang tepat untuk mengoperasikannya. Dianjurkan untuk tidak mengurangi rekaman.
Diskusikan proyek Anda dengan teknisi rekaman studio dan dengarkan saran mereka. Rekaman harus memiliki sedikit atau tidak ada kompresi rentang dinamis (maksimum 4:1). Sangat penting agar audio memiliki volume yang konsisten dan rasio signal-to-noise yang tinggi, sekaligus bebas dari suara yang tidak diinginkan.
Persyaratan rekaman
Untuk mencapai hasil pelatihan berkualitas tinggi, ikuti persyaratan berikut selama rekaman atau persiapan data:
Jelas dan diucapkan dengan baik
Kecepatan alami: tidak terlalu lambat atau terlalu cepat antar file audio.
Volume, prosodi, dan jeda yang tepat: stabil dalam kalimat yang sama atau antar kalimat, jeda yang tepat untuk tanda baca.
Tidak ada kebisingan saat rekaman
Sesuai dengan desain personal Anda
Tidak ada aksen yang salah: sesuai dengan desain target
Tidak ada pengucapan yang salah
Anda dapat merujuk pada spesifikasi di bawah ini untuk mempersiapkan sampel audio sebagai praktik terbaik.
| Properti | Nilai |
|---|---|
| Format file | *.wav, Mono |
| Tingkat pengambilan sampel | 24 KHz |
| Format sampel | 16 bit, PCM |
| Tingkat volume puncak | -3 dB hingga -6 dB |
| SNR | > 35 dB |
| Hening | - Harus ada keheningan (yang direkomendasikan 100 ms) di awal dan akhir, tetapi tidak lebih dari 200 ms - Keheningan antar kata atau frasa < -30 dB - Keheningan dalam gelombang setelah kata terakhir diucapkan <-60 dB |
| Kebisingan lingkungan atau gema | - Tingkat kebisingan di awal gelombang sebelum berbicara < -70 dB |
Catatan
Anda dapat merekam pada tingkat pengambilan sampel yang lebih tinggi dan kedalaman bit, misalnya dalam format 48 KHz 24 bit PCM. Selama pelatihan suara neural kustom, kami akan menurunkan sampelnya menjadi 24 KHz 16 bit PCM secara otomatis.
Rasio sinyal-ke-kebisingan (SNR) yang lebih tinggi menunjukkan kebisingan yang lebih rendah dalam audio Anda. Anda biasanya dapat mencapai 35+ SNR dengan merekam di studio profesional. Audio dengan SNR di bawah 20 dapat menghasilkan kebisingan yang jelas dalam suara yang dihasilkan.
Pertimbangkan untuk merekam ulang ungkapan apa pun dengan skor pengucapan rendah atau rasio sinyal ke kebisingan yang buruk. Jika Anda tidak dapat merekam ulang, pertimbangkan untuk mengecualikan ucapan tersebut dari data Anda.
Kesalahan audio yang khas
Agar hasil pelatihan berkualitas tinggi, Anda sangat dianjurkan untuk menghindari kesalahan audio. Kesalahan audio biasanya dalam kategori berikut:
Nama file audio tidak cocok dengan ID skrip.
File WAR memiliki format yang tidak valid dan tidak dapat dibaca.
Laju pengambilan sampel audio lebih rendah dari 16 KHz. Disarankan agar tingkat pengambilan sampel file .wav sama atau lebih tinggi dari 24 KHz untuk suara neural berkualitas tinggi.
Puncak volume harus berada dalam kisaran -3 dB (70% dari volume maks) hingga -6 dB (50%).
Luapan bentuk gelombang: bentuk gelombang dipotong pada nilai puncaknya sehingga tidak selesai.
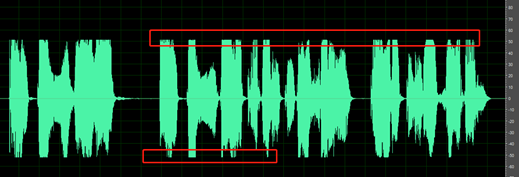
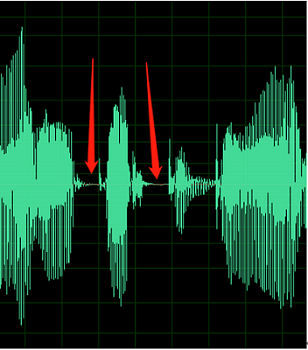
Bagian senyap dari rekaman tidak bersih; Anda dapat mendengar suara seperti kebisingan sekitar, kebisingan mulut, dan gema.
Misalnya, audio berikut berisi kebisingan lingkungan di antara ucapan.
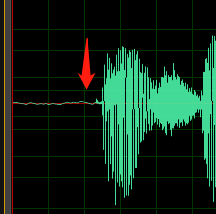
Sampel berikut berisi suara offset DC atau gema.
Volume keseluruhan terlalu rendah. Data Anda ditandai sebagai masalah jika volume lebih rendah dari -18 dB (10% dari volume maks). Pastikan semua file audio harus konsisten pada tingkat volume yang sama.
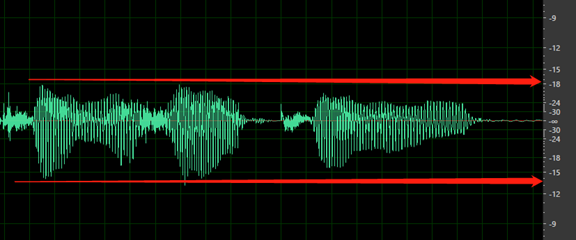
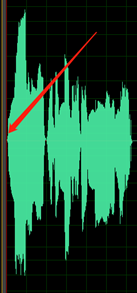
Tidak ada keheningan sebelum kata pertama atau setelah kata terakhir. Selain itu, keheningan awal atau akhir tidak boleh lebih lama dari 200 ms atau lebih singkat dari 100 ms.
Lakukan sendiri
Jika Anda ingin membuat rekaman sendiri, daripada pergi ke studio rekaman, inilah panduan singkatnya. Berkat maraknya rekaman rumah dan podcasting, sekarang lebih mudah untuk menemukan saran dan sumber rekaman yang bagus secara online.
"Ruang rekaman" Anda harus berupa ruangan kecil tanpa gema atau "nada ruangan" yang tampak, dan sebisa mungkin harus sunyi dan kedap suara. Tirai di dinding dapat digunakan untuk mengurangi gema dan menetralisir atau "mematikan" suara ruangan.
Gunakan mikrofon kondensor studio berkualitas tinggi (singkatnya"mikrofon") yang ditujukan untuk merekam suara. Sennheiser, AKG, dan bahkan mikrofon Zoom yang lebih baru dapat memberikan hasil yang baik. Anda dapat membeli mikrofon, atau menyewanya dari perusahaan penyewaan audio-visual lokal. Cari satu dengan antarmuka USB. Jenis mikrofon ini dengan mudah menggabungkan elemen mikrofon, preamp, dan konverter analog-ke-digital ke dalam satu paket, menyederhanakan sambungan.
Anda juga dapat menggunakan mikrofon analog. Banyak rumah sewaan menawarkan mikrofon "vintage" yang terkenal dengan karakter suaranya. Roda gigi analog profesional menggunakan konektor XLR seimbang, bukan colokan 1/4 inci yang digunakan dalam peralatan konsumen. Jika Anda menggunakan analog, Anda juga memerlukan preamp dan antarmuka audio komputer dengan konektor ini.
Pasang mikrofon pada dudukan atau boom, dan pasang filter pop di depan mikrofon untuk menghilangkan kebisingan dari konsonan "plosif" seperti "p" dan "b". Beberapa mikrofon dilengkapi dengan dudukan suspensi yang mengisolasi getaran di dudukan, yang sangat membantu.
Bakat suara harus tetap pada jarak yang konsisten dari mikrofon. Gunakan selotip di lantai untuk menandai tempat mereka harus berdiri. Jika bakat lebih suka duduk, berhati-hatilah untuk memantau jarak mikrofon dan menghindari kebisingan kursi.
Gunakan dudukan untuk memegang skrip. Hindari memiringkan dudukan agar dapat memantulkan suara ke arah mikrofon.
Orang yang mengoperasikan peralatan perekaman — teknisi — harus berada di ruangan terpisah dari talent, dengan beberapa cara untuk berbicara dengan talent di bilik rekaman (sirkuit talkback).
Rekaman harus mengandung kebisingan sesedikit mungkin, dengan tujuan -80 dB.
Dengarkan baik-baik rekaman keheningan di "stan" Anda, cari tahu dari mana suara itu berasal, dan hilangkan penyebabnya. Sumber kebisingan yang umum adalah ventilasi udara, pemberat lampu neon, lalu lintas di jalan terdekat, dan kipas peralatan (bahkan PC notebook mungkin memiliki kipas). Mikrofon dan kabel dapat menangkap gangguan listrik dari kabel AC terdekat, biasanya berupa dengungan atau dengungan. Buzz juga dapat disebabkan oleh perulangan tanah, yang disebabkan oleh peralatan yang dicolokkan ke lebih dari satu sirkuit listrik.
Tip
Dalam beberapa kasus, Anda mungkin dapat menggunakan equalizer atau plug-in perangkat lunak pengurang kebisingan untuk membantu menghilangkan kebisingan dari rekaman Anda, meskipun yang terbaik adalah menghentikannya di sumbernya.
Atur level sehingga sebagian besar rentang dinamis rekaman digital yang tersedia digunakan tanpa overdriving. Itu berarti mengatur audio keras, tetapi tidak begitu keras sehingga menjadi terdistorsi. Contoh bentuk gelombang rekaman yang baik diperlihatkan dalam gambar berikut:
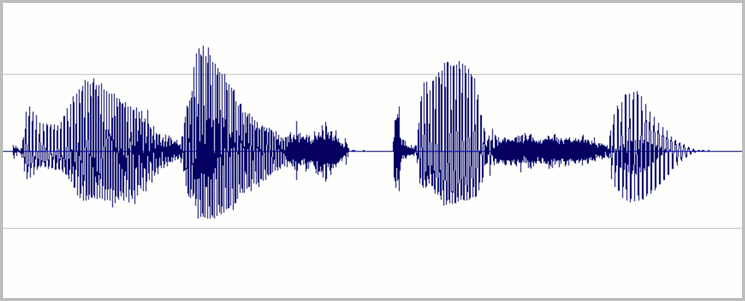
Di sini, sebagian besar jangkauan (tinggi) digunakan, tetapi puncak sinyal tertinggi tidak mencapai bagian atas atau bawah jendela. Anda juga dapat melihat bahwa keheningan dalam rekaman memperkirakan garis horizontal tipis, menunjukkan tingkat kebisingan rendah. Rekaman ini memiliki rentang dinamis dan rasio signal-to-noise yang dapat diterima.
Rekam langsung ke komputer melalui antarmuka audio berkualitas tinggi atau port USB, tergantung pada mikrofon yang Anda gunakan. Untuk analog, tetap sederhanakan rantai audio: mikrofon, preamp, antarmuka audio, komputer. Anda dapat melisensikan Avid Pro Tools danAdobe Audition setiap bulan dengan biaya yang wajar. Jika anggaran Anda sangat terbatas, cobalah Audacitygratis.
Rekam pada 44,1 kHz 16 bit monophonic (kualitas CD) atau lebih baik. Tahap perkembangan teknologi terbaru saat ini adalah 48 kHz 24 bit, jika peralatan Anda mendukungnya. Anda akan menurunkan sampel audio Anda menjadi 24 kHz 16-bit sebelum mengirimkannya ke Speech Studio. Namun, ada baiknya memiliki rekaman asli berkualitas tinggi jika pengeditan diperlukan.
Idealnya, mintalah orang yang berbeda untuk berperan sebagai sutradara, insinyur, dan bakat. Jangan mencoba melakukan semuanya sendiri. Dalam keadaan darurat, satu orang dapat menjadi direktur dan insinyur.
Sebelum sesi
Untuk menghindari membuang-buang waktu studio, jalankan melalui naskah dengan bakat suara Anda sebelum sesi rekaman. Sementara bakat suara menjadi akrab dengan teks, mereka dapat memperjelas pengucapan kata-kata asing.
Catatan
Sebagian besar studio rekaman menawarkan tampilan skrip elektronik di bilik rekaman. Dalam hal ini, ketikkan catatan run-through Anda langsung ke dalam dokumen skrip. Anda masih ingin salinan kertas untuk membuat catatan selama sesi. Sebagian besar insinyur juga menginginkan salinan cetak. Dan Anda masih menginginkan salinan cetak ketiga sebagai cadangan untuk bakat jika komputer mati.
Bakat suara Anda mungkin menanyakan kata mana yang ingin Anda tekankan dalam sebuah ucapan ("kata operatif"). Beri tahu mereka bahwa Anda menginginkan pembacaan yang alami tanpa penekanan khusus. Penekanan dapat ditambahkan ketika ucapan disintesis, dan tidak boleh menjadi bagian dari rekaman asli.
Arahkan bakat untuk mengucapkan kata-kata dengan jelas. Setiap kata dari naskah harus diucapkan seperti yang tertulis. Suara tidak boleh dihilangkan atau dibisikkan, sebagaimana dalam percakapan kasual, kecuali jika telah ditulis seperti itu dalam skrip.
| Teks tertulis | Pengucapan santai yang tidak diinginkan |
|---|---|
| tidak akan pernah menyerah | tidak akan pernah menyerah |
| ada empat lampu | ada empat lampu |
| bagaimana cuaca hari ini | bagaimana cuaca hari ini |
| menyapa teman kecilku | menyapa teman kecilku |
Bakat tidak boleh* menambahkan jeda yang berbeda di antara kata-kata. Kalimat itu harus tetap mengalir secara alami, bahkan saat terdengar sedikit formal. Perbedaan yang baik ini mungkin membutuhkan latihan untuk menjadi benar.
Sesi rekaman
Buat rekaman referensi, ataucocokkan file, dari ucapan khas di awal sesi. Mintalah bakat untuk mengulangi baris ini setiap halaman atau lebih. Setiap kali, bandingkan rekaman baru dengan referensi. Praktik ini membantu bakat tetap konsisten dalam volume, tempo, pitch, dan intonasi. Sementara itu, insinyur dapat menggunakan file pertandingan sebagai referensi untuk tingkat dan konsistensi suara secara keseluruhan.
File pertandingan sangat penting ketika Anda melanjutkan perekaman setelah istirahat atau di hari lain. Putar beberapa kali untuk talent dan minta mereka mengulanginya setiap kali hingga cocok.
Untuk merekam korpus dengan gaya tertentu, pilih skrip dengan hati-hati yang menampilkan gaya yang diinginkan. Selama perekaman, pastikan bakat suara tetap konsisten dalam volume, tempo, nada, dan nada untuk mencapai rekaman yang mewujudkan gaya yang dimaksudkan.
Latih bakat Anda untuk mengambil napas dalam-dalam dan berhenti sejenak sebelum setiap ucapan. Rekam beberapa detik keheningan antara ungkapan. Kata-kata harus diucapkan dengan cara yang sama setiap kali muncul, mempertimbangkan konteks. Misalnya, "rekam" sebagai kata kerja diucapkan berbeda dari "rekam" sebagai kata benda.
Rekam sekitar lima detik keheningan sebelum rekaman pertama untuk menangkap "nada ruangan". Praktik ini membantu Speech Studio mengimbangi kebisingan dalam rekaman.
Tip
Yang Anda butuhkan untuk menangkap adalah pengisi suara, sehingga Anda dapat membuat rekaman monofonik (saluran tunggal) hanya dari baris mereka. Namun, jika Anda merekam dalam stereo, Anda dapat menggunakan saluran kedua untuk merekam obrolan di ruang kontrol untuk menangkap diskusi tentang garis atau pengambilan tertentu. Hapus trek ini dari versi yang diunggah ke Speech Studio.
Dengarkan baik-baik, menggunakan headphone, untuk performa bakat suara. Anda mencari diksi yang baik tetapi alami, pengucapan yang benar, dan kurangnya suara yang tidak diinginkan. Jangan ragu untuk meminta bakat Anda merekam ulang ucapan yang tidak memenuhi standar ini.
Tip
Jika Anda menggunakan sejumlah besar ungkapan, satu ucapan mungkin tidak memiliki efek nyata pada suara saraf kustom yang dihasilkan. Mungkin lebih bijaksana untuk hanya mencatat setiap ucapan dengan masalah, mengecualikannya dari himpunan data Anda, dan melihat bagaimana suara saraf kustom Anda ternyata. Anda selalu dapat kembali ke studio dan merekam sampel yang terlewat nanti.
Catat nomor take atau kode waktu pada skrip Anda untuk setiap ucapan. Minta insinyur untuk menandai setiap ucapan dalam metadata rekaman atau lembar petunjuk juga.
Beristirahatlah secara teratur dan sediakan minuman untuk membantu bakat suara Anda menjaga suaranya tetap dalam kondisi yang baik.
Setelah sesi
Studio rekaman modern berjalan di komputer. Di akhir sesi, Anda menerima satu atau beberapa file audio, bukan kaset. File-file ini mungkin format WAV atau AIFF dalam kualitas CD (44,1 KHz 16-bit) atau lebih baik. 24 kHz 16-bit yang umum digunakan dan diinginkan. Tingkat pengambilan sampel default untuk suara neural kustom adalah 24 Hz. Anda dianjurkan agar wajib menggunakan laju sampel 24 Hz untuk data pelatihan Anda. Tingkat pengambilan sampel yang lebih tinggi, seperti 96 KHz, biasanya tidak diperlukan.
Speech Studio mengharuskan setiap ucapan yang diberikan berada dalam filenya sendiri. Setiap file audio yang dikirimkan oleh studio berisi beberapa ungkapan. Jadi tugas utama pascaproduksi adalah membagi rekaman dan mempersiapkannya untuk pengajuan. Insinyur rekaman mungkin telah menempatkan penanda dalam file (atau menyediakan lembar petunjuk terpisah) untuk menunjukkan tempat setiap ucapan dimulai.
Gunakan catatan Anda untuk menemukan pengambilan yang tepat yang Anda inginkan, lalu gunakan utilitas pengeditan suara, seperti Avid Pro Tools, Adobe Audition, atau Audacity gratis, untuk menyalin setiap ucapan ke dalam file baru.
Dengarkan setiap file dengan hati-hati. Pada tahap ini, Anda dapat mengedit suara kecil yang tidak diinginkan yang Anda lewatkan selama perekaman, seperti sedikit pukulan bibir sebelum baris,tetapi berhati-hatilah untuk tidak menghapus ucapan yang sebenarnya. Jika Anda tidak dapat memperbaiki file, hapus file dari himpunan data dan catat bahwa Anda telah melakukannya.
Konversikan setiap file menjadi 16 bit dan laju sampel 24 KHz sebelum disimpan dan jika Anda merekam obrolan studio, hapus saluran kedua. Simpan setiap file dalam format WAV, beri nama file dengan nomor ucapan dari skrip Anda.
Terakhir, buat transkrip yang mengaitkan setiap file WAV dengan versi teks dari ucapan yang sesuai. Melatih model suara mencakup detail format yang diperlukan. Anda dapat menyalin teks langsung dari skrip Anda. Kemudian buat file Zip dari file WAV dan transkrip teks.
Arsipkan rekaman asli di tempat yang aman jika Anda membutuhkannya nanti. Pertahankan skrip dan catatan Anda juga.
Langkah berikutnya
Anda siap mengunggah rekaman dan membuat suara saraf khusus.