Apa itu penyimpanan analitis Azure Cosmos DB?
BERLAKU UNTUK: ![]() Nosql
Nosql ![]() MongoDB
MongoDB ![]() Gremlin
Gremlin
Penyimpanan analitis Azure Cosmos DB adalah penyimpanan kolom yang sepenuhnya terisolasi untuk memungkinkan analitik skala besar terhadap data operasional di Azure Cosmos DB Anda, tanpa dampak apa pun terhadap beban kerja transaksional Anda.
Penyimpanan transaksional Azure Cosmos DB berskema-agnostik, dan memungkinkan iterasi pada aplikasi transaksional Anda tanpa harus berurusan dengan skema atau manajemen indeks. Sebaliknya, penyimpanan analitis Azure Cosmos DB memiliki skema yang dirancang untuk mengoptimalkan performa kueri analitis. Artikel ini menjelaskan secara detail tentang penyimpanan analitis.
Tantangan dengan analitik skala besar pada data operasional
Data operasional multimodel dalam kontainer Azure Cosmos DB disimpan secara internal di "penyimpanan transaksional" berbasis baris terindeks. Format penyimpanan baris dirancang untuk memungkinkan pembacaan dan penulisan transaksional cepat dengan waktu respons milidetik, dan kueri operasional. Jika himpunan data Anda tumbuh besar,kueri analitis yang kompleks bisa menjadi mahal di bagian throughput yang tersedia pada data yang disimpan dalam format ini. Konsumsi tinggi pada throughput yang tersedia dalam giliran berdampak pada performa beban kerja transaksional yang digunakan oleh aplikasi dan layanan real-time Anda.
Biasanya, untuk menganalisis sejumlah besar data, data operasional diekstrak dari penyimpanan transaksional Azure Cosmos DB dan disimpan dalam lapisan data terpisah. Misalnya, data disimpan di gudang data atau data lake dalam format yang sesuai. Data ini kemudian digunakan untuk analitik skala besar dan dianalisis menggunakan mesin komputasi seperti kluster Apache Spark. Pemisahan analitik dari data operasional mengakibatkan penundaan bagi analis yang ingin menggunakan data terbaru.
Alur ETL juga menjadi kompleks ketika menangani pembaruan data operasional dibandingkan ketika hanya menangani data operasional yang baru diproses.
Penyimpanan analitis berorientasi kolom
Penyimpanan analitis Azure Cosmos DB menjawab tantangan kompleksitas dan latensi yang hadir di alur ETL pada umumnya. Penyimpanan analitis Azure Cosmos DB dapat menyinkronkan data operasional Anda secara otomatis ke dalam penyimpanan kolom yang terpisah. Format penyimpanan kolom cocok untuk kueri analitis skala besar yang akan dilakukan secara optimal, sehingga meningkatkan latensi kueri tersebut.
Menggunakan Azure Synapse Link, Anda sekarang dapat membangun solusi HTAP tanpa ETL dengan langsung menautkan ke penyimpanan analitis Azure Cosmos DB dari Azure Synapse Analytics. Ini memungkinkan Anda untuk menjalankan analitik skala besar mendekati real-time pada data operasional Anda.
Fitur penyimpanan analitis
Ketika Anda mengaktifkan penyimpanan analitis pada kontainer Azure Cosmos DB, penyimpanan kolom baru dibuat secara internal berdasarkan data operasional dalam kontainer Anda. Penyimpanan kolom ini disimpan secara terpisah dari penyimpanan transaksional berorientasi baris untuk kontainer tersebut, di akun penyimpanan yang dikelola sepenuhnya oleh Azure Cosmos DB, dalam langganan internal. Pelanggan tidak perlu menghabiskan waktu dengan administrasi penyimpanan. Sisipan, pembaruan, dan penghapusan ke data operasional Anda secara otomatis disinkronkan ke penyimpanan analitis. Anda tidak memerlukan Umpan Perubahan atau ETL untuk menyinkronkan data.
Penyimpanan kolom untuk beban kerja analitis pada data operasional
Beban kerja analitis biasanya melibatkan agregasi dan pemindaian berurutan dari bidang yang dipilih. Dengan menyimpan data dalam urutan utama kolom, penyimpanan analitis memungkinkan satu grup nilai bagi setiap bidang diserialisasikan bersama-sama. Format ini mengurangi IOPS yang diperlukan untuk memindai atau menghitung statistik pada bidang tertentu. Ini secara dramatis meningkatkan waktu respons kueri untuk pemindaian pada himpunan data besar.
Misalnya, jika tabel operasional Anda berada dalam format berikut:
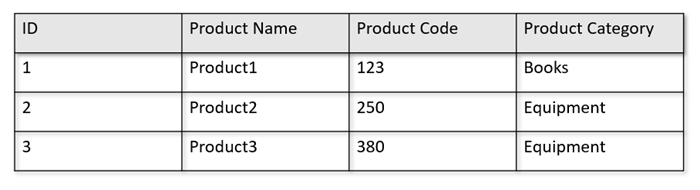
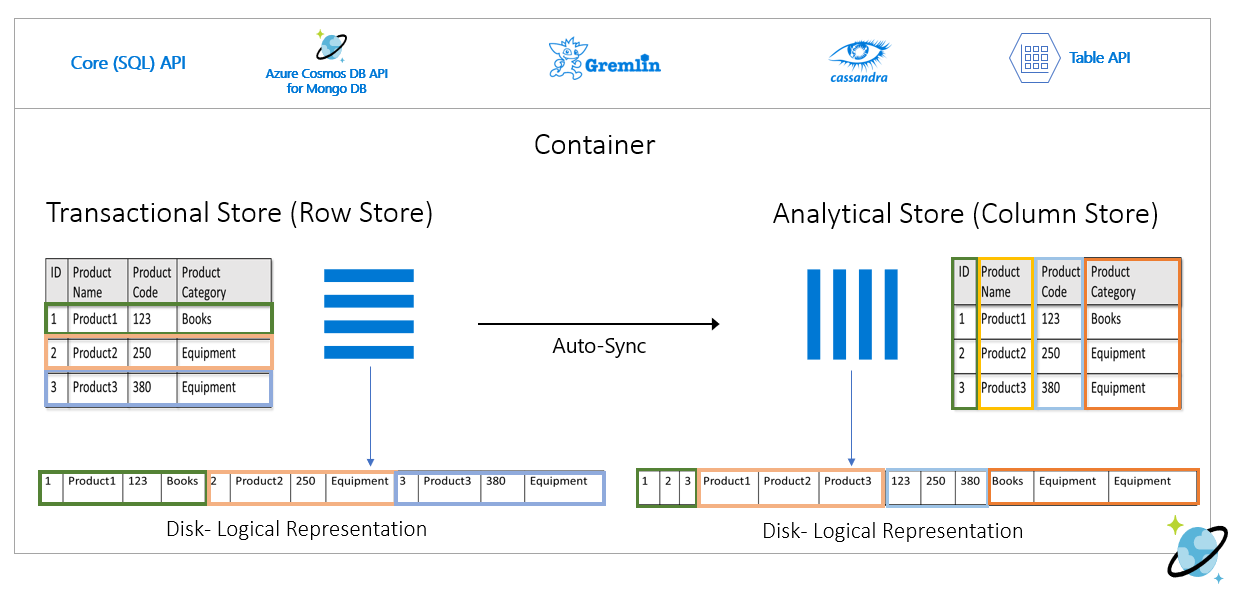
Penyimpanan baris mempertahankan data di atas dalam format serial, per baris, dalam disk. Format ini memungkinkan pembacaan transaksional, penulisan, dan kueri operasional yang lebih cepat, seperti, "Informasi pengembalian tentang Product1". Namun, seiring bertambahnya himpunan data dan bila Anda ingin menjalankan kueri analitis yang kompleks pada data tersebut, ini bisa menjadi mahal. Misalnya, jika Anda ingin mendapatkan "tren penjualan untuk produk di bawah kategori bernama 'Peralatan' di berbagai unit bisnis dan bulan", Anda perlu menjalankan kueri yang rumit. Pemindaian besar pada himpunan data ini bisa menjadi mahal di bagian throughput yang tersedia dan juga dapat berdampak pada performa beban kerja transaksional yang memberi daya aplikasi dan layanan real-time Anda.
Penyimpanan analitis, yang merupakan penyimpanan kolom, lebih cocok untuk kueri tersebut karena ia menserialisasikan bidang data yang serupa secara bersamaan dan mengurangi IOPS disk.
Gambar berikut menunjukkan penyimpanan baris transaksional vs. penyimpanan kolom analitis di Azure Cosmos DB:
Performa yang dipisahkan untuk beban kerja analitis
Tidak ada dampak pada performa beban kerja transaksional Anda karena kueri analitis, sebab penyimpanan analitis terpisah dari penyimpanan transaksional. Penyimpanan analitis tidak memerlukan unit permintaan (RUs) terpisah untuk dialokasikan.
Sinkronisasi Otomatis
Sinkronisasi Otomatis mengacu pada kemampuan Azure Cosmos DB yang dikelola penuh di mana sisipan, pembaruan, penghapusan ke data operasional secara otomatis disinkronkan dari penyimpanan transaksional ke penyimpanan analitis mendekati real time. Latensi sinkronisasi otomatis biasanya dalam 2 menit. Dalam kasus database throughput bersama dengan banyak kontainer, latensi sinkronisasi otomatis dari setiap kontainer bisa lebih tinggi dan memakan waktu hingga 5 menit.
Di akhir setiap eksekusi proses sinkronisasi otomatis, data transaksional Anda akan segera tersedia untuk runtime bahasa umum Azure Synapse Analytics:
Kumpulan Spark Azure Synapse Analytics dapat membaca semua data, termasuk data pembaruan terbaru, melalui tabel Spark, yang diperbarui secara otomatis, atau melalui perintah
spark.read, yang selalu membaca status terakhir data.Kumpulan Tanpa Server SQL Azure Synapse Analytics dapat membaca semua data, termasuk pembaruan terkini, melalui tampilan, yang diperbarui secara otomatis, atau melalui
SELECTbersama dengan perintahOPENROWSET, yang selalu membaca status terbaru data.
Catatan
Data transaksi Anda akan disinkronkan ke penyimpanan analitis meskipun waktu hidup transaksional (TTL) Anda lebih kecil dari 2 menit.
Catatan
Perlu diperhatikan bahwa jika Anda menghapus kontainer, penyimpanan analitis juga dihapus.
Skalabilitas & elastisitas
Dengan menggunakan pemartisian horizontal, penyimpanan transaksional Azure Cosmos DB dapat secara elastis menskalakan penyimpanan dan throughput tanpa waktu henti. Pemartisian horizontal di penyimpanan transaksional memberikan skalabilitas & elastisitas dalam sinkronisasi otomatis untuk memastikan data disinkronkan ke penyimpanan analitis dengan mendekati real time. Sinkronisasi data tetap terjadi terlepas dari throughput lalu lintas transaksional, baik itu 1000 operasi/detik atau 1 juta operasi/detik, dan itu tidak berdampak pada throughput yang tersedia di penyimpanan transaksional.
Menangani pembaruan skema secara otomatis
Penyimpanan transaksional Azure Cosmos DB berskema-agnostik, dan memungkinkan iterasi pada aplikasi transaksional Anda tanpa harus berurusan dengan skema atau manajemen indeks. Sebaliknya, penyimpanan analitis Azure Cosmos DB memiliki skema yang dirancang untuk mengoptimalkan performa kueri analitis. Dengan kemampuan sinkronisasi otomatis, Azure Cosmos DB mengelola inferensi skema pada pembaruan terbaru dari penyimpanan transaksional. Ia juga mengelola representasi skema di penyimpanan analitis di luar kotak yang juga menangani jenis data berlapis.
Seiring berkembangnya skema Anda, dan properti baru ditambahkan dari waktu ke waktu, penyimpanan analitis secara otomatis menghadirkan skema gabungan di seluruh skema historis dalam penyimpanan transaksional.
Catatan
Dalam konteks penyimpanan analitik, kami menganggap struktur berikut sebagai properti:
- JSON "elemen" atau "pasangan nilai string yang dipisahkan oleh
:". - Objek JSON, dibatasi oleh
{dan}. - Array JSON, dibatasi oleh
[dan].
Batasan skema
Batasan berikut ini berlaku pada data operasional dalam Azure Cosmos DB ketika Anda mengaktifkan penyimpanan analitis untuk menyimpulkan dan mewakili skema dengan benar:
Anda dapat memiliki maksimum 1000 properti di seluruh tingkat bertumpuk dalam skema dokumen dan kedalaman bertumpuk maksimum 127.
- Hanya 1000 properti pertama yang ditunjukkan di penyimpanan analitis.
- Hanya 127 tingkat lapisan pertama yang ditunjukkan di penyimpanan analitis.
- Tingkat pertama dokumen JSON adalah tingkat akar
/. - Properti di tingkat pertama dokumen akan ditunjukkan sebagai kolom.
Sampel skenario:
- Jika tingkat pertama dokumen Anda memiliki 2000 properti, proses sinkronisasi akan mewakili 1000 properti pertama.
- Jika dokumen Anda memiliki lima tingkat dengan 200 properti di masing-masing, proses sinkronisasi akan mewakili semua properti.
- Jika dokumen Anda memiliki 10 tingkat dengan 400 properti di masing-masing, proses sinkronisasi akan sepenuhnya mewakili dua tingkat pertama dan hanya setengah dari tingkat ketiga.
Dokumen hipotesis di bawah ini berisi empat properti dan tiga tingkat.
- Tingkatnya adalah
root,myArray, dan struktur bersarang di dalammyArray. - Propertinya adalah
id,myArray,myArray.nested1, danmyArray.nested2. - Representasi penyimpanan analitik akan memiliki dua kolom,
iddanmyArray. Anda dapat menggunakan fungsi Spark atau T-SQL untuk mengekspos struktur bersarang sebagai kolom.
- Tingkatnya adalah
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
Meskipun dokumen JSON (dan koleksi/kontainer Azure Cosmos DB) peka huruf besar/kecil dari perspektif keunikan, penyimpanan analitik tidak.
- Dalam dokumen yang sama: Nama properti dalam tingkat yang sama harus unik jika dibandingkan secara ketakpekaan huruf besar/kecil. Misalnya, dokumen JSON berikut memiliki "Nama" dan "nama" di tingkat yang sama. Meskipun ini adalah dokumen JSON yang valid, JSON tidak memenuhi batasan keunikan dan karena itu, tidak akan sepenuhnya ditampilkan di penyimpanan analitis. Dalam contoh ini, "Nama" dan "nama" itu sama jika dibandingkan secara ketakpekaan huruf besar/kecil. Hanya
"Name": "fred"yang akan ditunjukkan di penyimpanan analitis, karena ini adalah kemunculan yang pertama. Dan"name": "john"tidak akan ditunjukkan sama sekali.
{"id": 1, "Name": "fred", "name": "john"}- Dalam dokumen yang berbeda: Properti dalam tingkat yang sama dan dengan nama yang sama, tetapi dengan kapitalisasi huruf yang berbeda, akan ditunjukkan dalam kolom yang sama, menggunakan format nama kejadian pertama. Misalnya, dokumen JSON berikut memiliki
"Name"dan"name"dalam tingkat yang sama. Karena format dokumen pertama adalah"Name", inilah yang akan digunakan untuk mewakili nama properti di penyimpanan analitis. Dengan kata lain, nama kolom di penyimpanan analitis akan menjadi"Name". Baik"fred"dan"john"akan ditunjukkan dalam kolom"Name".
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}- Dalam dokumen yang sama: Nama properti dalam tingkat yang sama harus unik jika dibandingkan secara ketakpekaan huruf besar/kecil. Misalnya, dokumen JSON berikut memiliki "Nama" dan "nama" di tingkat yang sama. Meskipun ini adalah dokumen JSON yang valid, JSON tidak memenuhi batasan keunikan dan karena itu, tidak akan sepenuhnya ditampilkan di penyimpanan analitis. Dalam contoh ini, "Nama" dan "nama" itu sama jika dibandingkan secara ketakpekaan huruf besar/kecil. Hanya
Dokumen pertama dari koleksi menentukan skema awal penyimpanan analitis.
- Dokumen dengan lebih banyak properti daripada skema awal akan membuat kolom baru di penyimpanan analitis.
- Kolom tidak dapat dihapus.
- Penghapusan semua dokumen dalam koleksi tidak mengatur ulang skema penyimpanan analitik.
- Tidak ada pembuatan versi skema. Anda akan melihat versi terakhir yang disimpulkan dari penyimpanan transaksional dalam penyimpanan analitik.
Saat ini Azure Synapse Spark tidak dapat membaca properti yang berisi beberapa karakter khusus dalam nama Azure Synapse Spark yang tercantum di bawah ini. SQL tanpa server Azure Synapse tidak terpengaruh.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
Catatan
Spasi kosong juga tercantum dalam pesan kesalahan Spark yang ditampilkan saat Anda mencapai batasan ini. Tetapi, kami telah menambahkan perlakuan khusus untuk spasi kosong, periksa detail selengkapnya di item di bawah ini.
- Jika Anda memiliki nama properti menggunakan karakter yang tercantum di atas, alternatifnya adalah:
- Ubah model data Anda terlebih dahulu untuk menghindari karakter ini.
- Karena saat ini kami tidak mendukung pengaturan ulang skema, Anda dapat mengubah aplikasi Anda untuk menambahkan properti redundan dengan nama yang mirip, menghindari karakter ini.
- Gunakan Ubah Umpan untuk membuat tampilan yang terwujud dari kontainer Anda tanpa karakter ini dalam nama properti.
- Gunakan opsi Spark
dropColumnuntuk mengabaikan kolom yang terpengaruh dan memuat semua kolom lainnya ke dalam DataFrame. Sintaksnya adalah:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Azure Synapse Spark sekarang mendukung properti dengan spasi kosong di nama properti. Oleh karena itu, Anda perlu menggunakan opsi Spark
allowWhiteSpaceInFieldNamesuntuk memuat kolom yang terpengaruh ke dalam DataFrame, dengan mempertahankan nama asli. Sintaksnya adalah:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
Jenis data BSON berikut tidak didukung dan tidak akan diwakili di penyimpanan analitis:
- Decimal128
- Ekspresi Reguler
- Pointer DB
- JavaScript
- Simbol
- MinKey/MaxKey
Saat menggunakan string DateTime yang mengikuti standar ISO 8601 UTC, perilaku berikut yang diharapkan:
- Kumpulan Spark di Azure Synapse mewakili kolom ini sebagai
string. - Kumpulan tanpa server SQL di Azure Synapse mewakili kolom ini sebagai
varchar(8000).
- Kumpulan Spark di Azure Synapse mewakili kolom ini sebagai
Properti dengan jenis
UNIQUEIDENTIFIER (guid)direpresentasikan sebagaistringdi penyimpanan analitis dan harus dikonversi keVARCHARdi SQL atau kestringdi Spark untuk visualisasi yang tepat.SQL kumpulan tanpa server di kumpulan hasil dukung Azure Synapse dengan hingga 1000 kolom, dan mengekspos kolom berlapis juga dihitung terhadap batas tersebut. Ini adalah praktik yang baik untuk mempertimbangkan informasi ini dalam arsitektur dan pemodelan data transaksi anda.
Jika Anda mengganti nama properti, dalam satu atau banyak dokumen, hal ini akan dianggap sebagai kolom baru. Jika Anda menjalankan penggantian nama yang sama di semua dokumen dalam koleksi, semua data akan dimigrasikan ke kolom baru dan kolom lama akan diwakili dengan nilai
NULL.
Representasi skema
Ada dua metode representasi skema di penyimpanan analitik, berlaku untuk semua kontainer di akun database. Mereka memiliki tradeoff antara kesederhanaan pengalaman kueri versus kenyamanan representasi kolom yang lebih inklusif untuk skema polimorfik.
- Representasi skema yang ditentukan dengan baik, opsi default untuk API untuk akun NoSQL dan Gremlin.
- Representasi skema keakuratan penuh, opsi default untuk API untuk akun MongoDB.
Representasi skema yang terumuskan dengan baik
Representasi skema yang terumuskan dengan baik membuat representasi tabular sederhana dari data skema-agnostik di penyimpanan transaksional. Representasi skema yang terumuskan dengan baik memiliki pertimbangan berikut:
- Dokumen pertama menentukan skema dasar dan properti harus selalu memiliki jenis yang sama di semua dokumen. Satu-satunya pengecualian adalah:
- Dari
NULLjenis data ke jenis data lain. Kemunculan non-null pertama menentukan jenis data kolom. Dokumen apa pun yang tidak mengikuti datatype non-null pertama tidak akan terwakili di penyimpanan analitis. - Dari
floatsampaiinteger. Semua dokumen diwakili di penyimpanan analitis. - Dari
integersampaifloat. Semua dokumen diwakili di penyimpanan analitis. Namun, untuk membaca data ini dengan kumpulan tanpa server Azure Synapse SQL, Anda harus menggunakan klausa WITH untuk mengonversi kolom menjadivarchar. Dan setelah konversi awal ini, memungkinkan untuk mengubahnya lagi menjadi angka. Harap periksa contoh di bawah ini, di mana nilai awal num adalah bilangan bulat dan yang kedua adalah float.
- Dari
SELECT CAST (num as float) as num
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = '<your-connection',
OBJECT = 'IntToFloat',
SERVER_CREDENTIAL = 'your-credential'
)
WITH (num varchar(100)) AS [IntToFloat]
Properti yang tidak mengikuti jenis data skema dasar tidak akan diwakili di penyimpanan analitis. Sebagai contoh, perhatikan dokumen di bawah ini: yang pertama menentukan skema dasar penyimpanan analitis. Dokumen kedua, di mana
idadalah"2", tidak memiliki skema yang ditentukan dengan baik karena properti"code"adalah string dan dokumen pertama memiliki"code"sebagai angka. Dalam hal ini, penyimpanan analitik mendaftarkan jenis data"code"sebagaiintegeruntuk masa pakai penampung. Dokumen kedua akan tetap disertakan dalam penyimpanan analitis, tetapi properti"code"-nya tidak akan disertakan.{"id": "1", "code":123}{"id": "2", "code": "123"}
Catatan
Kondisi di atas tidak berlaku untuk properti NULL. Misalnya, {"a":123} and {"a":NULL} masih dirumuskan dengan baik.
Catatan
Kondisi di atas tidak berubah jika Anda memperbarui "code" dokumen "1" menjadi string di penyimpanan transaksional. Di penyimpanan analitis, "code" akan disimpan sebagai integer karena saat ini kami tidak mendukung pengaturan ulang skema.
- Jenis larik harus memuat satu jenis berulang. Misalnya,
{"a": ["str",12]}bukan skema yang terumuskan dengan baik karena lariknya memuat campuran jenis bilangan bulat dan untai (karakter).
Catatan
Jika penyimpanan analitis Azure Cosmos DB mengikuti representasi skema yang terumuskan dengan baik dan ketentuan di atas dilanggar oleh item-item tertentu, item-item tersebut tidak akan disertakan dalam penyimpanan analitis.
Antisipasi perilaku yang berbeda sehubungan dengan perbedaan jenis dalam skema yang terumuskan dengan baik:
- Kumpulan Spark di Azure Synapse mewakili nilai-nilai ini sebagai
undefined. - Kumpulan tanpa server SQL di Azure Synapse mewakili nilai-nilai ini sebagai
NULL.
- Kumpulan Spark di Azure Synapse mewakili nilai-nilai ini sebagai
Antisipasi perilaku yang berbeda sehubungan dengan nilai eksplisit
NULL:- Kumpulan Spark di Azure Synapse membaca nilai-nilai ini sebagai
0(nol), danundefinedsegera setelah kolom memiliki nilai non-null. - Kumpulan tanpa server SQL di Azure Synapse membaca nilai-nilai ini sebagai
NULL.
- Kumpulan Spark di Azure Synapse membaca nilai-nilai ini sebagai
Antisipasi perilaku yang berbeda sehubungan dengan kolom yang hilang:
- Kumpulan Spark di Azure Synapse mewakili kolom ini sebagai
undefined. - Kumpulan tanpa server SQL di Azure Synapse mewakili kolom ini sebagai
NULL.
- Kumpulan Spark di Azure Synapse mewakili kolom ini sebagai
Solusi tantangan representasi
Ada kemungkinan bahwa dokumen lama, dengan skema yang salah, digunakan untuk membuat skema dasar penyimpanan analitis kontainer Anda. Berdasarkan semua aturan yang disajikan di atas, Anda mungkin menerima NULL properti tertentu saat mengkueri penyimpanan analitik Anda menggunakan Azure Synapse Link. Untuk menghapus atau memperbarui dokumen yang bermasalah tidak akan membantu karena reset skema dasar saat ini tidak didukung. Solusi yang mungkin dilakukan:
- Untuk memigrasikan data ke kontainer baru, pastikan bahwa semua dokumen memiliki skema yang benar.
- Untuk meninggalkan properti dengan skema yang salah dan menambahkan yang baru dengan nama lain yang memiliki skema yang benar di semua dokumen. Contoh: Anda memiliki miliaran dokumen dalam kontainer Pesanan di mana properti status adalah string. Tetapi dokumen pertama dalam kontainer tersebut memiliki status yang ditentukan dengan bilangan bulat. Jadi, satu dokumen akan memiliki status yang diwakili dengan benar dan semua dokumen lainnya akan memiliki
NULL. Anda dapat menambahkan properti status2 ke semua dokumen dan mulai menggunakannya, bukan properti asli.
Representasi skema dengan keakuratan penuh
Representasi skema dengan keakuratan penuh dirancang untuk menangani luasnya skema polimorfik dalam data operasional skema-agnostik. Dalam representasi skema ini, tidak ada item yang dihilangkan dari penyimpanan analitis meskipun batasan skema yang terumuskan dengan baik (yakni tidak adanya bidang jenis data campuran atau larik jenis data campuran) dilanggar.
Ini dicapai dengan menerjemahkan properti daun data operasional ke penyimpanan analitik sebagai pasangan JSON key-value , di mana jenis data adalah key dan konten properti adalah value. Representasi objek JSON ini memungkinkan kueri tanpa ambiguitas, dan Anda dapat menganalisis setiap jenis data secara individual.
Dengan kata lain, dalam representasi skema keakuratan penuh, setiap jenis data dari setiap properti dari setiap dokumen akan menghasilkan key-valuepasangan dalam objek JSON untuk properti tersebut. Masing-masing dihitung sebagai salah satu dari batas properti maksimum 1000.
Sebagai contoh, mari kita ambil dokumen contoh berikut di penyimpanan transaksional:
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
Objek address berlapis adalah properti di tingkat akar dokumen dan akan diwakili sebagai kolom. Setiap properti daun dalam address objek akan diwakili sebagai objek JSON: {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}.
Tidak seperti representasi skema yang terdefinisi dengan baik, metode keakuratan penuh memungkinkan variasi dalam jenis data. Jika dokumen berikutnya dalam koleksi contoh di atas ini memiliki streetNo sebagai string, dokumen tersebut akan diwakili di penyimpanan analitis sebagai "streetNo":{"string":15850}. Dalam metode skema yang ditentukan dengan baik, itu tidak akan diwakili.
Peta jenis data untuk skema keakuratan penuh
Berikut adalah peta jenis data MongoDB dan representasinya di penyimpanan analitik dalam representasi skema keakuratan penuh. Peta di bawah ini tidak valid untuk akun NoSQL API.
| Jenis data asli | Akhiran | Contoh |
|---|---|---|
| Laju | ".float64" | 24.99 |
| Array | ".array" | ["a", "b"] |
| Biner | ".binary" | 0 |
| Boolean | ".bool" | Benar |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| NULL | ".NULL" | NULL |
| String | ".string" | "ABC" |
| Tanda Waktu | ".timestamp" | Tanda waktu(0,0) |
| ObjectId | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| Dokumen | ".object" | {"a": "a"} |
Antisipasi perilaku yang berbeda sehubungan dengan nilai eksplisit
NULL:- Kumpulan Spark di Azure Synapse akan menampilkan nilai-nilai berikut sebagai
0(nol). - Kumpulan SQL tanpa server di Azure Synapse akan menampilkan nilai-nilai berikut sebagai
NULL.
- Kumpulan Spark di Azure Synapse akan menampilkan nilai-nilai berikut sebagai
Antisipasi perilaku yang berbeda sehubungan dengan kolom yang hilang:
- Kumpulan Spark di Azure Synapse akan menampilkan kolom-kolom berikut sebagai
undefined. - Kumpulan SQL tanpa server di Azure Synapse akan menampilkan kolom-kolom berikut sebagai
NULL.
- Kumpulan Spark di Azure Synapse akan menampilkan kolom-kolom berikut sebagai
Harapkan perilaku yang berbeda sehubungan dengan
timestampnilai:- Kumpulan Spark di Azure Synapse akan membaca nilai-nilai ini sebagai
TimestampType, ,DateTypeatauFloat. Ini tergantung pada rentang dan bagaimana tanda waktu dihasilkan. - Kumpulan Tanpa Server SQL di Azure Synapse akan membaca nilai-nilai ini sebagai
DATETIME2, mulai dari0001-01-01melalui9999-12-31. Nilai di luar rentang ini tidak didukung dan akan menyebabkan kegagalan eksekusi untuk kueri Anda. Jika ini adalah kasus Anda, Anda dapat:- Hapus kolom dari kueri. Untuk mempertahankan representasi, Anda dapat membuat properti baru yang mencerminkan kolom tersebut tetapi dalam rentang yang didukung. Dan gunakan dalam kueri Anda.
- Gunakan Ubah Pengambilan Data dari penyimpanan analitik, tanpa biaya RU, untuk mengubah dan memuat data ke dalam format baru, dalam salah satu sink yang didukung.
- Kumpulan Spark di Azure Synapse akan membaca nilai-nilai ini sebagai
Menggunakan skema keakuratan penuh dengan Spark
Spark akan mengelola setiap jenis data sebagai kolom saat memuat ke dalam DataFrame. Mari kita asumsikan koleksi dengan dokumen di bawah ini.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
Sementara dokumen pertama memiliki rating sebagai angka dan timestamp dalam format utc, dokumen kedua memiliki rating dan timestamp sebagai string. Dengan asumsi bahwa koleksi ini dimuat tanpa DataFrame transformasi data apa pun, outputnya df.printSchema() adalah:
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
Dalam representasi skema yang ditentukan dengan baik, kedua rating dan timestamp dokumen kedua tidak akan diwakili. Dalam skema keakuratan penuh, Anda dapat menggunakan contoh berikut untuk mengakses setiap nilai setiap jenis data secara individual.
Dalam contoh di bawah ini, kita dapat menggunakan PySpark untuk menjalankan agregasi:
df.groupBy(df.item.string).sum().show()
Dalam contoh di bawah ini, kita dapat menggunakan PySQL untuk menjalankan agregasi lain:
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
Menggunakan skema keakuratan penuh dengan SQL
Mempertimbangkan dokumen yang sama dari contoh Spark di atas, pelanggan dapat menggunakan contoh sintaks berikut:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
Mulai dari kueri di atas, pelanggan dapat menerapkan transformasi menggunakan cast, convert atau fungsi T-SQL lainnya untuk memanipulasi data Anda. Pelanggan juga dapat menyembunyikan struktur jenis data yang kompleks dengan menggunakan tampilan.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<your-database-account-name';Database=<your-database-name>',
OBJECT = '<your-collection-name>',
SERVER_CREDENTIAL = '<your-synapse-sql-server-credential-name>')
WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
Bekerja dengan bidang _id MongoDB
bidang _id MongoDB adalah dasar dari setiap koleksi di MongoDB dan pada awalnya memiliki representasi heksadesimal. Seperti yang Anda lihat dalam tabel di atas, skema keakuratan penuh akan mempertahankan karakteristiknya, menciptakan tantangan untuk visualisasinya di Azure Synapse Analytics. Untuk visualisasi yang tepat, Anda harus mengonversi jenis data _id seperti di bawah ini:
Bekerja dengan bidang MongoDB _id di Spark
Contoh di bawah ini berfungsi pada versi Spark 2.x dan 3.x:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
Bekerja dengan bidang MongoDB _id di SQL
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET('CosmosDB',
'Your-account;Database=your-database;Key=your-key',
HTAP) WITH (_id VARCHAR(1000)) as HTAP
Skema keakuratan penuh untuk API untuk akun NoSQL atau Gremlin
Dimungkinkan untuk menggunakan Skema keakuratan penuh untuk API untuk akun NoSQL, alih-alih opsi default, dengan mengatur jenis skema saat mengaktifkan Synapse Link pada akun Azure Cosmos DB untuk pertama kalinya. Berikut adalah pertimbangan terkait mengubah tipe representasi skema default:
- Saat ini, jika Anda mengaktifkan Synapse Link di akun NOSQL API Anda menggunakan portal Azure, itu akan diaktifkan serta skema yang ditentukan dengan baik.
- Saat ini, jika Anda ingin menggunakan skema keakuratan penuh dengan akun NoSQL atau Gremlin API, Anda harus mengaturnya di tingkat akun dalam perintah CLI atau PowerShell yang sama yang akan mengaktifkan Synapse Link di tingkat akun.
- Saat ini Azure Cosmos DB for MongoDB tidak kompatibel dengan kemungkinan perubahan representasi skema ini. Semua akun MongoDB memiliki jenis representasi skema keakuratan penuh.
- Peta jenis data skema Keakuratan Penuh yang disebutkan di atas tidak valid untuk akun API NoSQL, yang menggunakan jenis data JSON. Sebagai contoh,
floatdanintegernilai direpresentasikan sebagainumdi penyimpanan analitis. - Tidak dimungkinkan untuk mengatur ulang jenis representasi skema, dari yang terdefinisi dengan baik hingga keakuratan penuh atau sebaliknya.
- Saat ini, skema kontainer di penyimpanan analitis ditentukan ketika kontainer dibuat, bahkan jika Synapse Link belum diaktifkan di akun database.
- Kontainer atau grafik yang dibuat sebelum Synapse Link diaktifkan dengan skema keakuratan penuh pada tingkat akun akan memiliki skema yang ditentukan dengan baik.
- Kontainer atau grafik yang dibuat setelah Synapse Link diaktifkan dengan skema keakuratan penuh pada tingkat akun akan memiliki skema keakuratan penuh.
Keputusan tipe representasi skema harus dibuat pada saat yang sama ketika Synapse Link diaktifkan pada akun, menggunakan Azure CLI atau PowerShell.
Dengan Azure CLI:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
Catatan
Pada perintah di atas, ganti create dengan update untuk akun yang ada.
Dengan PowerShell:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
Catatan
Pada perintah di atas, ganti New-AzCosmosDBAccount dengan Update-AzCosmosDBAccount untuk akun yang ada.
Waktu Hidup Analitis (TTL)
TTL Analitik (ATTL) menunjukkan cara data yang panjang seharusnya dipertahankan di penyimpanan analitis, untuk kontainer.
Penyimpanan analitis diaktifkan ketika ATTL diatur dengan nilai selain NULL dan 0. Jika penyimpanan analitis diaktifkan, sisipan, pembaruan, penghapusan ke data operasional secara otomatis disinkronkan dari penyimpanan transaksional ke penyimpanan analitis, terlepas dari konfigurasi TTL transaksional (TTTL). Retensi data transaksional di penyimpanan analitis ini dapat dikontrol pada tingkat wadah sesuai dengan properti AnalyticalStoreTimeToLiveInSeconds.
Konfigurasi ATTL yang memungkinkan adalah:
Jika nilai diatur ke
0atau diatur keNULL: penyimpanan analitis dinonaktifkan dan tidak ada data yang direplikasi dari penyimpanan transaksional ke penyimpanan analitisJika nilainya diatur ke
-1: penyimpanan analitis mempertahankan semua data riwayat, terlepas dari retensi data di penyimpanan transaksional. Pengaturan ini menunjukkan bahwa penyimpanan analitis memiliki retensi yang tak terbatas pada data operasional AndaJika nilainya diatur ke bilangan bulat positif
napa pun: item akan kedaluwarsa dari penyimpanan analitisndetik setelah waktu terakhir mereka diubah di penyimpanan transaksional. Pengaturan ini dapat dimanfaatkan jika Anda ingin mempertahankan data operasional Anda untuk jangka waktu terbatas di penyimpanan analitis, terlepas dari retensi data di penyimpanan transaksional
Poin yang perlu dipertimbangkan:
- Setelah penyimpanan analitis diaktifkan dengan nilai ATTL, maka akan dapat diperbarui ke nilai valid yang berbeda nanti.
- Meskipun TTTL dapat diatur di tingkat kontainer atau item, ATTL hanya dapat diatur pada tingkat kontainer saat ini.
- Anda bisa mendapatkan retensi yang lebih lama untuk data operasional Anda dalam penyimpanan analitis dengan mengatur ATTL >= TTTL di tingkat wadah.
- Penyimpanan analitis dapat dibuat untuk mencerminkan penyimpanan transaksional dengan mengatur ATTL = TTTL.
- Jika Anda memiliki ATTL lebih besar dari TTTL, pada suatu saat Anda akan memiliki data yang hanya ada di penyimpanan analitis. Data ini hanya dapat dibaca.
- Saat ini kami tidak menghapus data apa pun dari penyimpanan analitis. Jika Anda mengatur ATTL ke bilangan bulat positif apa pun, data tidak akan disertakan dalam kueri Anda dan Anda tidak akan ditagih untuk itu. Tetapi jika Anda mengubah ATTL kembali ke
-1, semua data akan muncul lagi, Anda akan mulai ditagih untuk semua volume data.
Cara mengaktifkan penyimpanan analitis pada kontainer:
Dari portal Azure, opsi ATTL, ketika diaktifkan, diatur ke nilai default -1. Anda dapat mengubah nilai ini menjadi 'n' detik, dengan menavigasi ke pengaturan kontainer di bagian Data Explorer.
Dari Azure Management SDK, Azure Cosmos DB SDKs, PowerShell, atau CLI, opsi ATTL dapat diaktifkan dengan mengaturnya ke -1 atau 'n' detik.
Untuk mempelajari lebih lanjut, lihat cara mengonfigurasi TTL analitis pada kontainer.
Analitik hemat biaya pada data historis
Penjenjangan data mengacu pada pemisahan data dari infrastruktur penyimpanan yang dioptimalkan untuk skenario yang berbeda. Sehingga meningkatkan performa keseluruhan dan efektivitas biaya tumpukan data end-to-end. Dengan penyimpanan analitis, Azure Cosmos DB sekarang mendukung penjenjangan data otomatis dari penyimpanan transaksional ke penyimpanan analitis dengan tata letak data yang berbeda. DIbandingkan dengan penyimpanan transaksional, penyimpanan analitis yang sudah dioptimalkan dalam hal biaya penyimpanan memungkinkan Anda untuk mempertahankan horizon data operasional yang lebih lama untuk analisis historis.
Setelah penyimpanan analitik diaktifkan, berdasarkan kebutuhan retensi data dari beban kerja transaksional, Anda dapat mengonfigurasi properti transactional TTL agar catatan dihapus secara otomatis dari penyimpanan transaksional setelah jangka waktu tertentu. Demikian pula, analytical TTL memungkinkan Anda untuk mengelola siklus hidup data yang disimpan di penyimpanan analitik, terlepas dari penyimpanan transaksional. Dengan mengaktifkan penyimpanan analitik dan mengonfigurasi properti TTL transaksional dan analitik, Anda dapat dengan mulus mengatur dan menentukan periode retensi data untuk kedua penyimpanan tersebut.
Catatan
Ketika analytical TTL lebih besar dari transactional TTL, kontainer Anda akan memiliki data yang hanya ada di penyimpanan analitik. Data ini hanya dibaca dan saat ini kami tidak mendukung TTL tingkat dokumen di penyimpanan analitik. Jika data kontainer Anda mungkin memerlukan pembaruan atau penghapusan pada beberapa titik waktu di masa mendatang, jangan gunakan analytical TTL yang lebih besar dari transactional TTL. Kemampuan ini direkomendasikan untuk data yang tidak memerlukan pembaruan atau penghapusan di masa mendatang.
Catatan
Jika skenario Anda tidak menuntut penghapusan fisik, Anda dapat mengadopsi pendekatan penghapusan/pembaruan logis. Sisipkan di penyimpanan transaksional versi lain dari dokumen yang sama yang hanya ada di penyimpanan analitik tetapi memerlukan penghapusan/pembaruan logis. Mungkin dengan bendera yang menunjukkan bahwa itu adalah penghapusan atau pembaruan dokumen yang kedaluwarsa. Kedua versi dokumen yang sama akan ada bersama di penyimpanan analitik, dan aplikasi Anda hanya boleh mempertimbangkan yang terakhir.
Ketahanan
Penyimpanan analitik bergantung pada Azure Storage dan menawarkan perlindungan berikut terhadap kegagalan fisik:
- Secara default, akun database Azure Cosmos DB mengalokasikan penyimpanan analitik di akun Locally Redundant Storage (LRS). LRS menyediakan setidaknya 99,999999999% (9 sebelas kali) durabilitas objek selama tahun tertentu.
- Jika ada wilayah geografis akun database yang dikonfigurasi untuk zona-redundansi, itu dialokasikan di akun Zone-redundant Storage (ZRS). Pelanggan perlu mengaktifkan Zona Ketersediaan di wilayah akun database Azure Cosmos DB mereka agar memiliki data analitik wilayah tersebut yang disimpan di Penyimpanan Zona-redundan. ZRS menawarkan daya tahan untuk sumber daya penyimpanan setidaknya 99,9999999999% (12 9) selama tahun tertentu.
Untuk informasi selengkapnya tentang durabilitas Azure Storage, klik di sini.
Cadangan
Meskipun penyimpanan analitik memiliki perlindungan bawaan terhadap kegagalan fisik, pencadangan dapat diperlukan untuk penghapusan atau pembaruan yang tidak disengaja di penyimpanan transaksional. Dalam kasus tersebut, Anda dapat memulihkan kontainer dan menggunakan kontainer yang dipulihkan untuk mengisi ulang data dalam kontainer asli, atau membangun kembali penyimpanan analitik sepenuhnya jika perlu.
Catatan
Saat ini penyimpanan analitik tidak dicadangkan, oleh karena itu tidak dapat dipulihkan. Kebijakan pencadangan Anda tidak dapat direncanakan dengan mengandalkan hal tersebut.
Synapse Link, dan penyimpanan analitis dengan konsekuensinya, memiliki tingkat kompatibilitas yang berbeda dengan mode pencadangan Azure Cosmos DB:
- Mode pencadangan berkala sepenuhnya kompatibel dengan Synapse Link dan 2 fitur ini dapat digunakan dalam akun database yang sama.
- Mode pencadangan berkelanjutan saat ini dan Synapse Link tidak didukung di akun database yang sama. Pelanggan harus memilih salah satu dari dua fitur ini dan keputusan ini tidak dapat diubah.
Kebijakan pencadangan
Ada dua kemungkinan kebijakan pencadangan dan untuk memahami cara menggunakannya, detail berikut tentang pencadangan Azure Cosmos DB sangat penting:
- Kontainer asli dipulihkan tanpa penyimpanan analitik di kedua mode pencadangan.
- Azure Cosmos DB tidak mendukung penimpaan kontainer dari pemulihan.
Sekarang mari kita lihat cara menggunakan pencadangan dan pemulihan dari perspektif penyimpanan analitis.
Memulihkan kontainer dengan TTTL >= ATTL
Ketika transactional TTL sama atau lebih besar dari analytical TTL, semua data di penyimpanan analitik masih ada di penyimpanan transaksional. Jika terjadi pemulihan, Anda memiliki dua kemungkinan situasi:
- Untuk menggunakan kontainer yang dipulihkan sebagai pengganti kontainer asli. Untuk membangun kembali penyimpanan analitik, cukup aktifkan Synapse Link di tingkat akun dan tingkat kontainer.
- Untuk menggunakan kontainer yang dipulihkan sebagai sumber data untuk mengisi ulang atau memperbarui data dalam kontainer asli. Dalam hal ini, penyimpanan analitik akan secara otomatis mencerminkan operasi data.
Memulihkan kontainer dengan TTTL < ATTL
Ketika transactional TTL lebih kecil dari analytical TTL, beberapa data hanya ada di penyimpanan analitis dan tidak akan berada dalam kontainer yang dipulihkan. Sekali lagi, Anda memiliki dua kemungkinan situasi:
- Untuk menggunakan kontainer yang dipulihkan sebagai pengganti kontainer asli. Dalam hal ini, ketika Anda mengaktifkan Synapse Link di tingkat kontainer, hanya data yang ada di penyimpanan transaksional yang akan disertakan dalam penyimpanan analitik baru. Tetapi harap dicatat bahwa penyimpanan analitik kontainer asli tetap tersedia untuk kueri selama kontainer asli ada. Anda mungkin ingin mengubah aplikasi Anda untuk mengkueri keduanya.
- Untuk menggunakan kontainer yang dipulihkan sebagai sumber data untuk mengisi ulang atau memperbarui data dalam kontainer asli:
- Penyimpanan analitik akan secara otomatis mencerminkan operasi data untuk data yang ada di penyimpanan transaksional.
- Jika Anda menyisipkan ulang data yang sebelumnya dihapus dari penyimpanan transaksional karena
transactional TTL, data ini akan diduplikasi di penyimpanan analitik.
Contoh:
- Kontainer
OnlineOrdersmemiliki TTTL yang diatur ke satu bulan dan ATTL yang diatur untuk satu tahun. - Saat Anda memulihkannya ke
OnlineOrdersNewdan mengaktifkan penyimpanan analitis untuk menyusunnya ulang, hanya akan ada satu bulan data di penyimpanan transaksional dan analitis. - Kontainer asli
OnlineOrderstidak dihapus dan penyimpanan analitisnya masih tersedia. - Data baru hanya disingkapkan ke dalam
OnlineOrdersNew. - Kueri analitis akan melakukan UNION ALL dari penyimpanan analitis sementara data asli masih relevan.
Jika Anda ingin menghapus kontainer asli namun tidak ingin kehilangan data penyimpanan analitisnya, Anda dapat tetap berada di penyimpanan analitis dari penyimpanan asli dalam layanan data Azure lain. Synapse Analytics memiliki kemampuan untuk melakukan hubungan antar data yang disimpan di lokasi yang berbeda. Contoh: Kueri Analitis Synapse menggabungkan data penyimpanan analitis dengan tabel eksternal yang terletak di Azure Blob Storage, Azure Data Lake Store, dll.
Penting untuk diperhatikan bahwa data di penyimpanan analitis memiliki skema yang berbeda dari yang ada di penyimpanan transaksional. Meskipun Anda dapat menghasilkan snapshot dari data penyimpanan analitis Anda, dan mengekspornya ke layanan Data Azure apa pun, tanpa biaya RU, kami tidak dapat menjamin penggunaan snapshot ini untuk umpan balik ke penyimpanan transaksional. Proses ini tidak didukung.
Distribusi global
Jika Anda memiliki akun Azure Cosmos DB yang terdistribusi secara global, setelah Anda mengaktifkan penyimpanan analitis untuk sebuah kontainer, ia akan tersedia di semua wilayah akun tersebut. Setiap perubahan pada data operasional direplikasi secara global di semua wilayah. Anda dapat menjalankan kueri analitis secara efektif terhadap salinan data wilayah terdekat di Azure Cosmos DB.
Partisi
Pemartisian penyimpanan analitik sepenuhnya bersifat independen dari pemartisian di penyimpanan transaksional. Secara default, data di penyimpanan analitis tidak dipartisi. Jika kueri analitik Anda sering menggunakan filter, Anda memiliki opsi untuk membuat partisi berdasarkan bidang ini untuk performa kueri yang lebih baik. Untuk mempelajari selengkapnya, lihat pengantar pemartisian kustom dan cara mengonfigurasi pemartisian kustom.
Keamanan
Autentikasi dengan penyimpanan analitik sama dengan penyimpanan transaksional untuk database tertentu. Anda dapat menggunakan kunci utama, sekunder, atau baca-saja untuk autentikasi. Anda dapat memanfaatkan layanan tertaut di Synapse Studio untuk mencegah penempelan kunci Azure Cosmos DB di buku catatan Spark. Untuk Azure Synapse SQL tanpa server, Anda dapat menggunakan informasi masuk SQL untuk juga mencegah menempelkan Kunci Azure Cosmos DB di SQL notebook. Akses ke Layanan Tertaut ini atau kredensial SQL ini tersedia bagi siapa saja yang memiliki akses ke ruang kerja. Harap dicatat bahwa kunci baca saja Azure Cosmos DB juga dapat digunakan.
Isolasi jaringan menggunakan titik akhir pribadi - Anda dapat mengontrol akses jaringan ke data di penyimpanan transaksional dan analitis secara independen. Isolasi jaringan dilakukan menggunakan titik akhir pribadi terkelola terpisah untuk setiap penyimpanan, dalam jaringan virtual terkelola di ruang kerja Azure Synapse. Untuk mempelajari selengkapnya, lihat cara Mengonfigurasi titik akhir pribadi untuk artikel penyimpanan analitis.
Enkripsi data tidak aktif - Enkripsi penyimpanan analitik Anda diaktifkan secara default.
Enkripsi data dengan kunci yang dikelola pelanggan - Anda dapat mengenkripsi data dengan lancar di seluruh penyimpanan transaksional dan analitis menggunakan kunci yang dikelola pelanggan yang sama secara otomatis dan transparan. Azure Synapse Link hanya mendukung konfigurasi kunci yang dikelola pelanggan menggunakan identitas terkelola akun Azure Cosmos DB Anda. Anda harus mengonfigurasi identitas terkelola akun Anda di kebijakan akses Azure Key Vault sebelum mengaktifkan Azure Synapse Link di akun Anda. Untuk mempelajari selengkapnya, lihat artikel cara Mengonfigurasi kunci yang dikelola pelanggan menggunakan identitas yang dikelola akun Azure Cosmos DB.
Catatan
Jika Anda mengubah akun database dari Pihak Pertama ke Sistem atau Identitas yang Ditetapkan Pengguna, dan mengaktifkan Azure Synapse Link di akun database, Anda tidak akan dapat kembali ke identitas Pihak Pertama karena Anda tidak dapat menonaktifkan Synapse Link dari akun database Anda.
Dukungan untuk sejumlah runtime bahasa umum Azure Synapse Analytics
Penyimpanan analitis Azure Cosmos DB telah dioptimalkan untuk memberikan skalabilitas, elastisitas, dan performa bagi beban kerja analitis tanpa dependensi apa pun pada run-time komputasi. Teknologi penyimpanan tersebut dikelola mandiri untuk mengoptimalkan beban kerja analitik Anda tanpa upaya manual.
Dengan memisahkan sistem penyimpanan analitis dari sistem komputasi analitis, data di penyimpanan analitis Azure Cosmos DB dapat dikueri secara bersamaan dari berbagai runtime bahasa umum analitik yang didukung oleh Azure Synapse Analytics. Mulai hari ini, Azure Synapse Analytics mendukung Apache Spark dan kumpulan SQL tanpa server dengan penyimpanan analitis Azure Cosmos DB.
Catatan
Anda hanya dapat membaca dari penyimpanan analitis menggunakan runtime bahasa umum Azure Synapse Analytics. Begitu pula sebaliknya, runtime bahasa umum Azure Synapse Analytics hanya dapat membaca dari penyimpanan analitis. Hanya proses sinkronisasi otomatis yang dapat mengubah data di penyimpanan analitis. Anda dapat menulis data kembali ke penyimpanan transaksional Azure Cosmos DB menggunakan kumpulan Azure Synapse Analytics Spark, menggunakan Azure Cosmos DB OLTP SDK bawaan.
Harga
Penyimpanan analitis mengikuti model harga berbasis konsumsi di mana Anda dikenakan biaya untuk:
Penyimpanan: volume data yang disimpan di penyimpanan analitis setiap bulan termasuk data historis sebagaimana didefinisikan oleh analytical TTL.
Operasi penulisan analitis: sinkronisasi terkelola lengkap untuk pembaruan data operasional ke penyimpanan analitis dari penyimpanan transaksional (sinkronisasi otomatis)
Operasi pembacaan analitis: operasi pembacaan yang dilakukan terhadap penyimpanan analitis dengan kumpulan Spark Azure Synapse Analytics dan durasi kumpulan SQL tanpa server.
Harga penyimpanan analitis berbeda dari model harga penyimpanan transaksi. Tidak ada konsep RU tersedia di penyimpanan analitis. Lihat halaman harga Azure Cosmos DB untuk detail lengkap tentang model harga untuk toko analitik.
Data di penyimpanan analitik hanya dapat diakses melalui Azure Synapse Link, yang dilakukan di runtime Azure Synapse Analytics: kumpulan Azure Synapse Apache Spark dan kumpulan SQL tanpa server Azure Synapse. Lihat halaman harga Azure Synapse Analytics untuk detail lengkap tentang model harga untuk mengakses data di penyimpanan analitik.
Untuk mendapatkan perkiraan biaya tingkat tinggi untuk mengaktifkan penyimpanan analitik pada kontainer Azure Cosmos DB, dari perspektif penyimpanan analitik, Anda dapat menggunakan Perencana Kapasitas Azure Cosmos DB dan mendapatkan perkiraan penyimpanan analitik dan menulis biaya operasi.
Perkiraan operasi baca penyimpanan analitik tidak disertakan dalam kalkulator biaya Azure Cosmos DB karena merupakan fungsi dari beban kerja analitik Anda. Tetapi sebagai perkiraan tingkat tinggi, pemindaian 1 TB data di penyimpanan analitis biasanya menghasilkan 130.000 operasi baca analitis, dan menghasilkan biaya $ 0,065. Sebagai contoh, jika Anda menggunakan kumpulan SQL tanpa server Azure Synapse untuk melakukan pemindaian 1 TB ini, biayanya akan sebesar $5,00 menurut halaman harga Azure Synapse Analytics. Total biaya akhir untuk pemindaian 1 TB ini adalah $5,065.
Meskipun perkiraan di atas adalah untuk memindai 1 TB data di penyimpanan analitik, menerapkan filter akan mengurangi volume data yang dipindai dan ini menentukan jumlah pasti operasi pembacaan analitik dengan model harga konsumsi. Bukti konsep sekeliling beban kerja analitik akan memberikan perkiraan operasi baca analitis yang lebih baik. Perkiraan ini tidak termasuk biaya Azure Synapse Analytics.
Langkah berikutnya
Untuk mempelajari lebih lanjut, lihat dokumen berikut ini:
Lihat modul pembelajaran terkait cara Merancang pemrosesan transaksional dan analitik hibrida dengan menggunakan Azure Synapse Analytics