Bersosialisasi dengan Azure Cosmos DB
BERLAKU UNTUK: ![]() Nosql
Nosql ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Meja
Meja
Hidup dalam masyarakat yang saling terhubung secara besar-besaran berarti bahwa, pada titik tertentu, Anda menjadi bagian dari jejaring sosial. Anda menggunakan jejaring sosial untuk tetap berhubungan dengan teman, kolega, keluarga, atau kadang-kadang untuk berbagi hasrat Anda dengan orang-orang berminat sama.
Sebagai insinyur atau pengembang, Anda mungkin bertanya-tanya bagaimana jaringan ini menyimpan dan menghubungkan data Anda. Atau Anda bahkan mungkin telah ditugaskan untuk membuat atau merancang jejaring sosial baru untuk niche pasar tertentu. Saat itulah muncul pertanyaan penting: Bagaimana semua data ini disimpan?
Misalkan Anda membuat jejaring sosial baru tempat pengguna dapat mengirim artikel dengan media terkait, seperti gambar, video, atau bahkan musik. Pengguna dapat mengomentari kirima dan memberikan poin untuk peringkat. Akan ada umpan kiriman yang dilihat dan berinteraksi dengan pengguna di beranda. Metode ini tidak terdengar rumit pada awalnya, tetapi supaya sederhana, sampai situ saja. (Anda dapat mempelajari umpan pengguna kustom yang terpengaruh oleh hubungan, tetapi itu di luar tujuan artikel ini.)
Jadi, bagaimana cara menyimpan data ini dan di mana?
Anda mungkin memiliki pengalaman di database SQL atau mengerti pemodelan data relasional. Anda dapat mulai menggambar seperti ini:
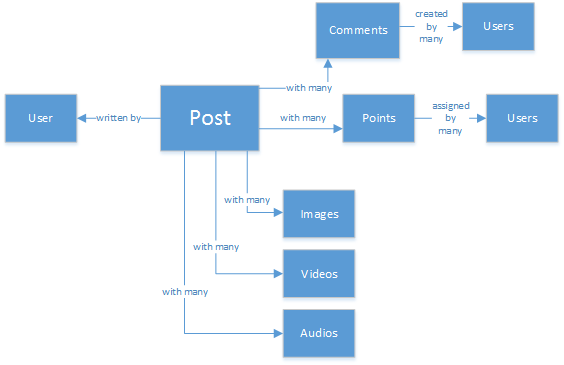
Struktur data yang normal dan cantik sempurna... tapi tidak dapat diskalakan.
Jangan salah paham, saya telah bekerja dengan database SQL seumur hidup. Mereka hebat, tetapi seperti setiap pola, latihan dan platform perangkat lunak, tidak akan cocok untuk setiap skenario.
Mengapa SQL bukan pilihan terbaik dalam skenario ini? Mari kita lihat struktur suatu kiriman. Jika saya ingin memperlihatkan kiriman di situs web atau aplikasi, saya harus melakukan kueri dengan... menggabungkan delapan tabel(!) hanya untuk menampilkan satu kiriman. Sekarang bayangkan aliran kiriman yang secara dinamis dimuat dan muncul di layar, dan Anda mungkin tahu tujuan saya.
Anda dapat menggunakan instans SQL sangat besar dengan daya yang cukup untuk menyelesaikan ribuan kueri dan banyak gabungan untuk melayani konten Anda. Tapi mengapa demikian, ketika ada solusi yang lebih sederhana?
Jalan NoSQL
Artikel ini memandu Anda untuk memodelkan data platform sosial dengan database NoSQL Azure Cosmos DB secara hemat. Ini juga memberi tahu Anda cara menggunakan fitur Azure Cosmos DB lainnya seperti API untuk Gremlin. Menggunakan pendekatan NoSQL, menyimpan data, dalam format JSON dan menerapkan denormalisasi, kiriman yang sebelumnya rumit dapat diubah menjadi satu Dokumen:
{
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["https://myfirstimage.png","https://mysecondimage.png"],
"videos":[
{"url":"https://myfirstvideo.mp4", "title":"The first video"},
{"url":"https://mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"https://myfirstaudio.mp3", "title":"The first audio"},
{"url":"https://mysecondaudio.mp3", "title":"The second audio"}
]
}
Dan itu bisa diperoleh dengan satu kueri, dan tanpa gabungan. Kueri ini jauh sederhana dan mudah, dan, secara anggaran, membutuhkan lebih sedikit sumber daya untuk mencapai hasil yang lebih baik.
Azure Cosmos DB memastikan bahwa semua properti diindeks dengan pengindeksan otomatisnya. Pengindeksan otomatis bahkan dapat disesuaikan. Pendekatan bebas skema memungkinkan kita menyimpan dokumen dengan struktur yang berbeda dan dinamis. Mungkin besok Anda ingin kirimannya memiliki daftar kategori atau tagar yang terkait? Azure Cosmos DB akan menangani Dokumen baru dengan atribut tambahan tanpa pekerjaan tambahan yang diperlukan oleh kami.
Komentar di kiriman dapat diperlakukan sebagai kiriman lain dengan properti induk. (Praktik ini menyederhanakan pemetaan objek Anda.)
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":User2,
"parent":"ew12-res2-234e-544f"
}
{
"id":"asd2-fee4-23gc-jh67",
"title":"Ditto!",
"date":"2016-01-03",
"createdBy":User3,
"parent":"ew12-res2-234e-544f"
}
Dan semua interaksi sosial dapat disimpan pada objek terpisah sebagai penghitung:
{
"id":"dfe3-thf5-232s-dse4",
"post":"ew12-res2-234e-544f",
"comments":2,
"likes":10,
"points":200
}
Membuat umpan hanyalah masalah membuat dokumen yang bisa menyimpan daftar ID kiriman dengan urutan relevansi tertentu:
[
{"relevance":9, "post":"ew12-res2-234e-544f"},
{"relevance":8, "post":"fer7-mnb6-fgh9-2344"},
{"relevance":7, "post":"w34r-qeg6-ref6-8565"}
]
Anda bisa memiliki aliran "terbaru" dengan kiriman yang diurut berdasarkan tanggal pembuatan. Atau Anda bisa memiliki aliran "terpanas" berisi kiriman dengan paling banyak suka dalam 24 jam terakhir. Anda bahkan dapat menerapkan aliran khusus untuk setiap pengguna berdasarkan logika seperti pengikut dan minat. Ini masih akan berupa daftar kiriman. Ini semua tentang cara membangun daftar, tetapi performa membaca tetap tanpa hambatan. Setelah Anda memperoleh salah satu daftar ini, Anda mengeluarkan satu kueri ke Azure Cosmos DB menggunakan kata kunci IN untuk mendapatkan halaman postingan sekaligus.
Aliran umpan dapat dibangun menggunakan proses latar belakang Azure App Services: Webjobs. Setelah kiriman dibuat, pemrosesan latar belakang dapat dipicu dengan menggunakan Azure StorageQueues dan Webjobs yang dipicu menggunakan Azure Webjobs SDK, menerapkan propagasi kiriman di dalam stream berdasarkan logika kustom Anda sendiri.
Poin dan suka suatu kiriman dapat diproses dengan cara yang dirujuk menggunakan teknik yang sama ini untuk menciptakan lingkungan yang akhirnya konsisten.
Pengikutnya lebih rumit. Azure Cosmos DB memiliki batas ukuran dokumen, dan membaca/menulis dokumen besar dapat memengaruhi skalabilitas aplikasi Anda. Jadi Anda mungkin berpikir untuk menyimpan pengikut sebagai dokumen dengan struktur ini:
{
"id":"234d-sd23-rrf2-552d",
"followersOf": "dse4-qwe2-ert4-aad2",
"followers":[
"ewr5-232d-tyrg-iuo2",
"qejh-2345-sdf1-ytg5",
//...
"uie0-4tyg-3456-rwjh"
]
}
Struktur ini mungkin berfungsi untuk pengguna dengan beberapa ribu pengikut. Namun, jika beberapa selebritas bergabung, pendekatan ini akan mengarah pada ukuran dokumen yang besar, dan akhirnya mungkin menabrak batas ukuran dokumen.
Untuk mengatasi masalah ini, Anda dapat menggunakan pendekatan campuran. Sebagai bagian dari dokumen Statistik Pengguna, Anda dapat menyimpan jumlah pengikut:
{
"id":"234d-sd23-rrf2-552d",
"user": "dse4-qwe2-ert4-aad2",
"followers":55230,
"totalPosts":452,
"totalPoints":11342
}
Anda dapat menyimpan grafik pengikut aktual menggunakan AZURE Cosmos DB API untuk Gremlin untuk membuat vertex untuk setiap pengguna dan tepi yang mempertahankan hubungan "A-follows-B". Dengan API untuk Gremlin, Anda bisa mendapatkan pengikut pengguna tertentu dan membuat kueri yang lebih kompleks untuk menyarankan orang-orang yang sama. Jika menambahkan Kategori Konten yang disukai atau dinikmati orang ke grafik, Anda dapat mulai menenun pengalaman yang menyertakan penemuan konten cerdas, menyarankan konten yang disukai orang-orang yang Anda ikuti, atau menemukan orang yang mungkin memiliki banyak kesamaan dengan Anda.
Dokumen Statistik Pengguna masih dapat digunakan untuk membuat kartu di UI atau pratinjau profil cepat.
Pola "Tangga" dan duplikasi data
Seperti yang mungkin telah Anda perhatikan dalam dokumen JSON yang merujuk kiriman, ada banyak kemunculan pengguna. Tebakan Anda benar, duplikat ini artinya informasi yang menggambarkan pengguna, dengan denormalisasi ini, mungkin ada di lebih dari satu tempat.
Untuk memungkinkan kueri yang lebih cepat, Anda dikenakan duplikasi data. Masalah dengan efek samping ini adalah jika data pengguna berubah karena beberapa tindakan, Anda perlu menemukan semua aktivitas yang pernah dilakukan pengguna dan memperbarui semuanya. Tidak terdengar praktis, kan?
Anda akan menyelesaikannya dengan mengenali atribut kunci pengguna yang ditampilkan di aplikasi untuk setiap aktivitas. Jika Anda secara visual menampilkan postingan di aplikasi dan hanya menampilkan nama dan gambar kreator, buat apa menyimpan semua data pengguna di atribut "createdBy"? Jika setiap komentar hanya menampilkan gambar pengguna, Anda tidak benar-benar memerlukan informasi pengguna lainnya. Di situlah "Pola tangga" berperan.
Mari kita ambil informasi pengguna sebagai contoh:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"address":"742 Evergreen Terrace",
"birthday":"1983-05-07",
"email":"john@doe.com",
"twitterHandle":"\@john",
"username":"johndoe",
"password":"some_encrypted_phrase",
"totalPoints":100,
"totalPosts":24
}
Dengan melihat informasi ini, Anda dapat dengan cepat mendeteksi mana yang merupakan informasi penting dan mana yang tidak, sehingga menciptakan "Tangga":

Langkah terkecil disebut UserChunk, bagian minimal informasi yang mengidentifikasi pengguna dan digunakan untuk duplikasi data. Dengan mengurangi ukuran data duplikat menjadi hanya informasi yang akan "ditampilkan", Anda mengurangi kemungkinan pembaruan besar-besaran.
Langkah tengah disebut pengguna. Ini adalah data lengkap yang akan digunakan pada sebagian besar kueri yang bergantung pada performa di Azure Cosmos DB, yang paling diakses dan penting. Ini termasuk informasi yang diwakili oleh UserChunk.
Yang terbesar adalah Pengguna Diperluas. Ini termasuk informasi pengguna penting dan data lain yang tidak perlu dibaca dengan cepat atau memiliki penggunaan akhir, seperti proses masuk. Data ini dapat disimpan di luar Azure Cosmos DB, di Azure SQL Database atau Tabel Azure Storage.
Buat apa membagi pengguna dan bahkan menyimpan informasi ini di tempat yang berbeda? Karena dari sudut pandang performa, semakin besar dokumen, kuerinya lebih mahal. Jaga dokumen tetap ramping, dengan informasi yang tepat untuk melakukan semua kueri yang bergantung pada performa jejaring sosial Anda. Simpan informasi tambahan lainnya untuk pengeditan profil lengkap, login, dan penggalian data untuk analitik penggunaan dan inisiatif Big Data. Anda tidak perlu peduli jika penggalian datanya lebih lambat, karena itu berjalan di Azure SQL Database. Anda justru perlu agar pengguna Anda memiliki pengalaman yang cepat dan ramping. Pengguna yang disimpan di Azure Cosmos DB akan terlihat seperti kode ini:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"username":"johndoe"
"email":"john@doe.com",
"twitterHandle":"\@john"
}
Dan Kiriman akan terlihat seperti:
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":{
"id":"dse4-qwe2-ert4-aad2",
"username":"johndoe"
}
}
Saat pengeditan muncul untuk atribut gugus, Anda dapat dengan mudah menemukan dokumen yang terpengaruh. Cukup gunakan kueri yang menunjuk ke atribut terindeks, seperti SELECT * FROM posts p WHERE p.createdBy.id == "edited_user_id", lalu perbarui gugusnya.
Kotak pencarian
Untungnya, pengguna akan menghasilkan banyak konten. Dan Anda harus bisa memberikan kemampuan untuk mencari dan menemukan konten yang mungkin tidak berada di aliran konten mereka, mungkin karena tidak mengikuti pembuatnya, atau mungkin hanya mencoba menemukan kiriman enam bulan yang lalu.
Karena Anda menggunakan Azure Cosmos DB, Anda dapat dengan mudah mengimplementasikan mesin pencari menggunakan Azure AI Search dalam beberapa menit tanpa mengetik kode apa pun, selain proses pencarian dan UI.
Mengapa proses ini begitu mudah?
Azure AI Search mengimplementasikan apa yang mereka sebut Pengindeks, proses latar belakang yang terhubung di repositori data Anda dan secara otomatis menambahkan, memperbarui, atau menghapus objek Anda dalam indeks. Mereka mendukung pengindeks Azure SQL Database, pengindeks Azure Blobs dan untungnya, pengindeks Azure Cosmos DB. Transisi informasi dari Azure Cosmos DB ke Azure AI Search sangat mudah. Keduanya menyimpan informasi dalam format JSON, jadi Anda hanya perlu membuat Indeks dan memetakan atribut dari Dokumen yang ingin diindeks. Itu saja! Tergantung ukuran data, semua konten Anda akan tersedia untuk dicari dalam beberapa menit oleh solusi Search-as-a-Service terbaik dalam infrastruktur awan.
Untuk informasi selengkapnya tentang Azure AI Search, Anda dapat mengunjungi Panduan Hitchhiker untuk Pencarian.
Pengetahuan yang mendasarinya
Setelah menyimpan semua konten yang tumbuh setiap hari, Anda mungkin berpikir: Apa yang bisa saya lakukan dengan semua aliran informasi dari pengguna saya ini?
Jawabannya mudah: Pekerjakan dan pelajari.
Tapi apa yang bisa Anda pelajari? Beberapa contoh mudah termasuk analisis sentimen, rekomendasi konten berdasarkan minat pengguna, atau bahkan moderator konten otomatis yang memastikan konten jejaring sosial Anda aman untuk keluarga.
Setelah tertarik, Anda mungkin berpikir perlu punya PhD ilmu matematika untuk mengekstrak pola dan informasi ini dari database dan file sederhana, tetapi itu salah.
Azure Pembelajaran Mesin, adalah layanan cloud terkelola penuh yang memungkinkan Anda membuat alur kerja menggunakan algoritma dalam antarmuka seret dan letakkan sederhana, mengodekan algoritma Anda sendiri di R, atau menggunakan beberapa API yang sudah dibuat dan siap digunakan seperti: Text Analytics, Content Moderator, atau Rekomendasi.
Untuk mencapai salah satu skenario Machine Learning ini, Anda dapat menggunakan Azure Data Lake untuk menelan informasi dari berbagai sumber. Anda juga dapat menggunakan U-SQL untuk memproses informasi dan menghasilkan output yang dapat diproses oleh Azure Machine Learning.
Opsi lain yang tersedia adalah menggunakan layanan Azure AI untuk menganalisis konten pengguna Anda; Anda tidak hanya dapat memahaminya dengan lebih baik (melalui menganalisis apa yang mereka tulis dengan Text Analytics API), tetapi Anda juga dapat mendeteksi konten yang tidak diinginkan atau matang dan bertindak sesuai dengan COMPUTER Vision API. Layanan Azure AI mencakup banyak solusi siap pakai yang tidak memerlukan pengetahuan Pembelajaran Mesin apa pun untuk digunakan.
Pengalaman sosial berskala planet
Ada artikel terakhir yang tidak kalah penting yang harus saya bahas: skalabilitas. Ketika Anda merancang arsitektur, setiap komponen harus berskala sendiri. Anda pada akhirnya perlu memproses lebih banyak data, atau perlu memiliki cakupan geografis yang lebih besar. Untungnya, mencapai kedua tugas adalah pengalaman turnkey dengan Azure Cosmos DB.
Azure Cosmos DB mendukung partisi dinamis secara langsung. Ini secara otomatis membuat partisi berdasarkan kunci partisi tertentu, yang didefinisikan sebagai atribut dalam dokumen Anda. Mendefinisikan kunci partisi yang benar harus dilakukan pada waktu desain. Untuk informasi selengkapnya, lihat artikel Pemartisian di Azure Cosmos DB.
Untuk pengalaman sosial, Anda harus menyelaraskan strategi partisi dengan cara kueri dan menulis. (Misalnya, bacaan dalam partisi yang sama diinginkan, dan hindari "hot spot" dengan menyebarkan tulisan di beberapa partisi.) Beberapa opsinya adalah: partisi berdasarkan kunci temporal (hari/bulan/minggu), berdasarkan kategori konten, berdasarkan wilayah geografis, atau oleh pengguna. Itu semua benar-benar tergantung pada bagaimana cara kueri data Anda dan memperlihatkan data dalam pengalaman sosial Anda.
Azure Cosmos DB akan menjalankan kueri Anda (termasuk agregat) di semua partisi Anda secara transparan, sehingga Anda tidak perlu menambahkan logika apa pun saat data Anda tumbuh.
Seiring waktu, lalu lintas Anda pada akhirnya akan tumbuh dan konsumsi sumber daya (diukur dalam RUs, atau Unit Permintaan) akan meningkat. Anda akan membaca dan menulis lebih sering saat basis pengguna Anda tumbuh. Basis pengguna akan mulai membuat dan membaca lebih banyak konten. Jadi kemampuan menskalakan throughput Anda sangatlah penting. Meningkatkan RUs itu mudah. Anda dapat melakukannya dengan beberapa klik pada portal Microsoft Azure atau dengan mengeluarkan perintah melalui API.
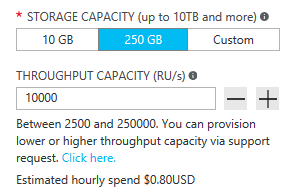
Apa yang terjadi jika keadaan terus membaik? Misalkan pengguna dari negara/wilayah atau benua lain memperhatikan platform Anda dan mulai menggunakannya. Sungguh kejutan besar!
Tapi tunggu! Anda segera menyadari pengalaman mereka di platform Anda tidak optimal. Mereka begitu jauh dari wilayah operasional Anda sehingga latensinya mengerikan. Anda jelas tidak ingin mereka berhenti. Apakah ada cara mudah untuk memperluas jangkauan global? Tentu ada!
Azure Cosmos DB memungkinkan Anda mereplikasi data Anda secara global dan transparan dengan beberapa klik dan secara otomatis memilih di antara wilayah yang tersedia dari kode klien Anda. Proses ini juga berarti bahwa Anda dapat memiliki beberapa wilayah failover.
Ketika mereplikasi data secara global, Anda perlu memastikan bahwa klien Anda dapat memanfaatkannya. Jika menggunakan frontend web atau mengakses API dari klien seluler, Anda dapat menerapkan Azure Traffic Manager dan mengkloning Azure App Service di semua wilayah yang diinginkan, menggunakan konfigurasi performa untuk mendukung perluasan cakupan global. Saat klien Anda mengakses frontend atau API Anda, mereka akan dirutekan ke App Service terdekat, yang pada gilirannya, akan terhubung ke replika Azure Cosmos DB lokal.
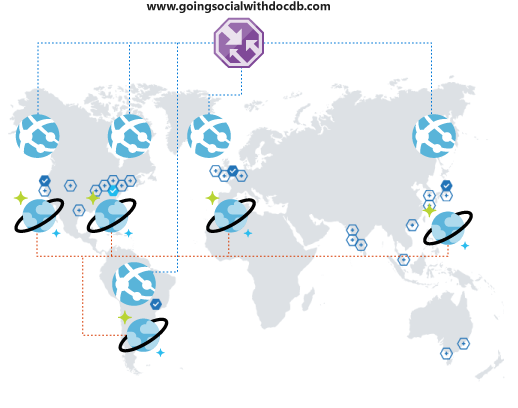
Kesimpulan
Artikel ini menjelaskan beberapa hal tentang alternatif pembuatan jejaring sosial sepenuhnya di Azure dengan layanan berbiaya rendah. ini memberikan hasil dengan mendorong penggunaan solusi penyimpanan berlapis dan distribusi data yang disebut "Tangga".
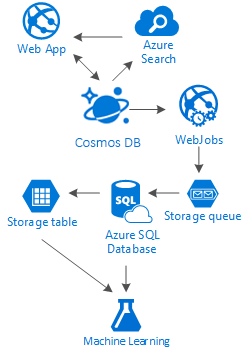
Sebenarnya tidak ada jurus pamungkas untuk skenario semacam ini. Ini adalah sinergi yang dibuat oleh kombinasi layanan hebat yang memungkinkan kami membangun pengalaman hebat: kecepatan dan kebebasan Azure Cosmos DB untuk menyediakan aplikasi sosial yang hebat, kecerdasan di balik solusi pencarian kelas satu seperti Azure AI Search, fleksibilitas Azure App Services untuk menghosting bahkan aplikasi agnostik bahasa tetapi proses latar belakang yang kuat dan Azure Storage dan Azure SQL Database yang dapat diperluas untuk menyimpan data dalam jumlah besar dan kekuatan analitik Azure Pembelajaran Mesin untuk membuat pengetahuan dan kecerdasan yang dapat memberikan umpan balik ke proses Anda dan membantu kami mengirimkan konten yang tepat kepada pengguna yang tepat.
Langkah berikutnya
Untuk mempelajari selengkapnya tentang kasus penggunaan untuk Azure Cosmos DB, lihat Kasus penggunaan Umum Azure Cosmos DB.