Memecahkan masalah performa aktivitas penyalinan
BERLAKU UNTUK: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Artikel ini menguraikan cara memecahkan masalah performa aktivitas penyalinan di Azure Data Factory.
Setelah menjalankan aktivitas penyalinan, Anda dapat mengumpulkan hasil eksekusi dan statistik performa di tampilan pemantauan aktivitas penyalinan. Berikut adalah contohnya.
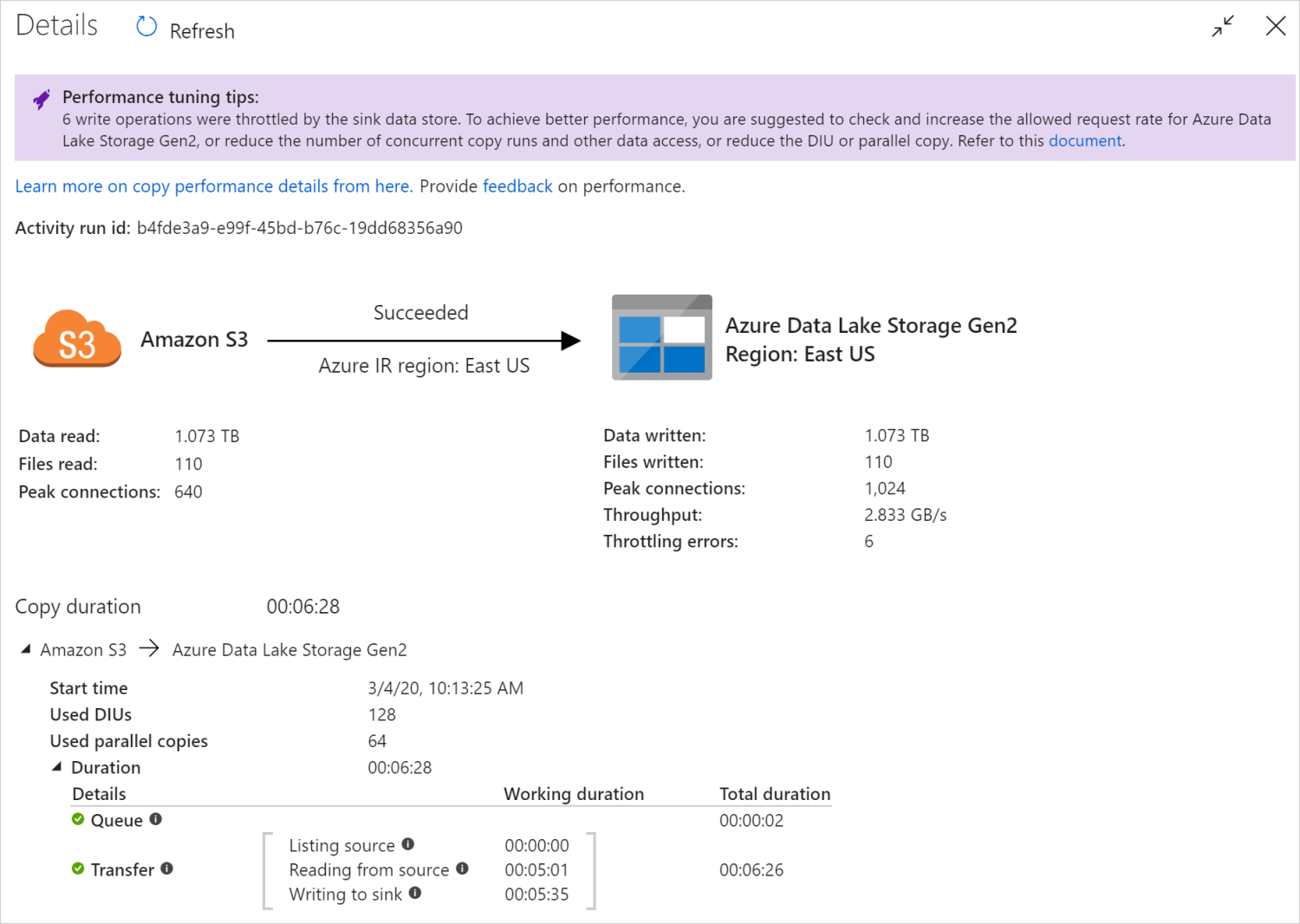
Tips penyetelan performa
Dalam beberapa skenario, saat Anda menjalankan aktivitas penyalinan, Anda akan melihat "Tips penyetelan performa" di bagian atas seperti yang ditunjukkan dalam contoh. Tips ini akan memberi tahu tentang penyempitan yang diidentifikasi oleh layanan untuk eksekusi penyalinan khusus ini, berikut saran tentang hal yang harus diubah untuk meningkatkan throughput penyalinan. Coba lakukan perubahan yang telah direkomendasikan, lalu jalankan penyalinannya lagi.
Sebagai referensi, saat ini tips penyetelan kinerja memberikan saran untuk kasus-kasus berikut:
| Golongan | Tips penyetelan performa |
|---|---|
| Penyimpanan data spesifik | Memuat data ke Azure Synapse Analytics: sarankan menggunakan pernyataan PolyBase atau COPY jika tidak digunakan. |
| Menyalin data dari/ke Azure SQL Database: ketika DTU berada di bawah pemanfaatan tinggi, sarankan pemutakhiran ke tingkat yang lebih tinggi. | |
| Menyalin data dari/ke Azure Cosmos DB: ketika RU berada di bawah pemanfaatan tinggi, sarankan peningkatan ke RU yang lebih besar. | |
| Menyalin data dari Tabel SAP: ketika menyalin data dalam jumlah besar, sarankan pemanfaatan opsi partisi konektor SAP untuk mengaktifkan beban paralel dan menambah jumlah partisi maks. | |
| Menyerap data dari Amazon Redshift: sarankan penggunaan UNLOAD jika tidak digunakan. | |
| Pembatasan penyimpanan data | Jika sejumlah operasi baca/tulis dibatasi oleh penyimpanan data selama penyalinan, sarankan untuk memeriksa dan meningkatkan tingkat permintaan yang diizinkan untuk penyimpanan data, atau mengurangi beban kerja bersamaan. |
| Runtime integrasi | Jika Anda menggunakan Runtime Integrasi (IR) yang Dihosting Sendiri dan aktivitas penyalinan menunggu lama dalam antrean hingga IR memiliki sumber daya yang tersedia untuk dieksekusi, sarankan penskalaan/peningkatan IR Anda. |
| Jika Anda menggunakan Azure Integration Runtime yang berada di wilayah yang tidak optimal sehingga baca/tulis lambat, sarankan konfigurasi untuk menggunakan IR di wilayah lain. | |
| Toleransi kegagalan | Jika Anda mengonfigurasi toleransi kesalahan dan dengan melompati baris yang tidak kompatibel menghasilkan kinerja yang lambat, sarankan untuk memastikan data sumber dan sink kompatibel. |
| Salinan yang dipentaskan | Jika penyalinan bertahap dikonfigurasi tetapi tidak berguna untuk pasangan sink sumber Anda, sarankan untuk menghapusnya. |
| Lanjutkan | Ketika aktivitas penyalinan dilanjutkan dari titik kegagalan terakhir tetapi Anda kebetulan mengubah pengaturan DIU setelah eksekusi asal, perhatikan bahwa pengaturan DIU baru tidak berlaku. |
Memahami detail eksekusi aktivitas penyalinan
Detail dan durasi eksekusi di bagian bawah tampilan pemantauan aktivitas penyalinan menjelaskan tahapan kunci yang dilalui aktivitas penyalinan Anda (lihat contoh di awal artikel ini), yang sangat berguna untuk memecahkan masalah kinerja penyalinan. Penyempitan dari eksekusi penyalinan adalah yang memiliki durasi terpanjang. Lihat tabel berikut pada definisi setiap tahap, dan pelajari cara Memecahkan masalah aktivitas penyalinan di Azure IR dan Memecahkan masalah aktivitas penyalinan di IR yang dihost sendiri dengan info tersebut.
| Tahap | Deskripsi |
|---|---|
| Antrean | Waktu yang berlalu sampai aktivitas penyalinan benar-benar dimulai pada runtime integrasi. |
| Skrip prapenyalinan | Waktu yang berlalu antara aktivitas penyalinanan dimulai pada IR dan aktivitas penyalinan selesai mengeksekusi skrip prapenyalinanan di penyimpanan data sink. Terapkan saat Anda mengonfigurasi skrip prapenyalinan untuk database sink, misalnya saat menulis data ke Azure SQL Database lakukan pembersihan sebelum menyalin data baru. |
| Transfer | Waktu yang berlalu antara akhir langkah sebelumnya dan IR mentransfer semua data dari sumber ke sink. Perhatikan sublangkah di bawah transfer yang berjalan secara paralel, dan beberapa operasi tidak ditampilkan sekarang misalnya parsing/menghasilkan format file. - Waktu untuk byte pertama: Waktu yang berlalu antara akhir langkah sebelumnya dan waktu ketika IR menerima byte pertama dari penyimpanan data sumber. Berlaku untuk sumber berbasis non-file. - Sumber daftar: Jumlah waktu yang dihabiskan untuk enumerasi file sumber atau partisi data. Yang terakhir berlaku saat mengonfigurasi opsi partisi untuk sumber database, misalnya ketika menyalin data dari database seperti Oracle/SAP Hana/Teradata/Netezza/dll. -Membaca dari sumber: Jumlah waktu yang dihabiskan untuk mengambil data dari penyimpanan data sumber. - Menulis dari sink: Jumlah waktu yang dihabiskan untuk menulis data untuk penyimpanan data sink. Perhatikan bahwa beberapa konektor tidak memiliki metrik ini saat ini, termasuk Azure AI Search, Azure Data Explorer, penyimpanan Azure Table, Oracle, SQL Server, Common Data Service, Dynamics 365, Dynamics CRM, Salesforce/Salesforce Service Cloud. |
Memecahkan masalah aktivitas penyalinan di Azure IR
Ikuti langkah penyetelan performa untuk merencanakan dan melakukan uji performa untuk skenario Anda.
Saat kinerja aktivitas penyalinan tidak memenuhi harapan, untuk memecahkan masalah aktivitas penyalinan tunggal yang berjalan di Azure Integration Runtime, jika Anda melihat tips penyetelan kinerja yang muncul dalam tampilan pemantauan penyalinan, terapkan saran tersebut, lalu coba lagi. Jika tidak, pahami detail eksekusi aktivitas penyalinan, periksa tahap mana yang memiliki durasi terpanjang, dan terapkan panduan di bawah ini untuk meningkatkan kinerja penyalinan:
"Skrip prapenyalinan" mengalami durasi panjang: itu berarti skrip prapenyalinan yang berjalan pada database sink membutuhkan waktu lama untuk diselesaikan. Menyetel logika skrip prapenyalinan yang ditentukan untuk meningkatkan kinerja. Jika memerlukan bantuan lebih lanjut dalam meningkatkan skrip, hubungi tim database.
"Transfer - Waktu ke byte pertama" mengalami durasi kerja yang panjang: itu berarti kueri sumber membutuhkan waktu lama untuk mengembalikan data apa pun. Periksa dan optimalkan kueri atau server. Jika memerlukan bantuan lebih lanjut, hubungi tim penyimpanan data.
"Transfer - Sumber daftar" mengalami durasi kerja yang lama: itu berarti enumerasi file sumber atau partisi data database sumber lambat.
Saat menyalin data dari sumber berbasis file, jika Anda menggunakan filter wildcard pada jalur folder atau nama file (
wildcardFolderPathatauwildcardFileName), atau menggunakan filter waktu yang terakhir dimodifikasi file (modifiedDatetimeStartataumodifiedDatetimeEnd), perhatikan bahwa filter tersebut akan mengakibatkan aktivitas penyalinan yang mencantumkan semua file di bawah folder yang ditentukan ke sisi klien lalu menerapkan filter. Enumerasi file semacam itu bisa menjadi penyempitan terutama ketika hanya sekumpulan kecil file yang memenuhi aturan filter.Periksa apakah Anda dapat menyalin file berdasarkan jalur atau nama file yang dipartisi datetime. Cara seperti itu tidak membebani sumber daftar.
Periksa apakah Anda dapat menggunakan filter asli penyimpanan data sebagai gantinya, khususnya "prefiks" untuk Amazon S3/Penyimpanan Azure Blob/Azure Files dan "listAfter/listBefore" untuk ADLS Gen1. Filter tersebut adalah filter sisi server penyimpanan data dan akan memiliki kinerja yang jauh lebih baik.
Pertimbangkan untuk membagi satu kumpulan data besar menjadi beberapa kumpulan data yang lebih kecil, dan biarkan pekerjaan salinan tersebut berjalan bersama setiap bagian dari data. Anda dapat melakukan ini dengan Lookup/GetMetadata + ForEach + Copy. Lihat Menyalin file dari beberapa kontainer atau Memigrasikan data dari Amazon S3 ke templat solusi ADLS Gen2 sebagai contoh umum.
Periksa apakah layanan melaporkan kesalahan pembatasan pada sumber atau jika penyimpanan data Anda berada di bawah status pemanfaatan tinggi. Jika demikian, kurangi beban kerja Anda di penyimpanan data, atau coba hubungi administrator penyimpanan data untuk meningkatkan batas pembatasan atau sumber daya yang tersedia.
Gunakan Azure IR di wilayah penyimpanan data sumber yang sama atau dekat.
"Transfer - membaca dari sumber" mengalami durasi kerja yang panjang:
Adopsi praktik terbaik pemuatan data khusus konektor jika berlaku. Misalnya, saat menyalin data dari Amazon Redshift, konfigurasikan untuk menggunakan Redshift UNLOAD.
Periksa apakah layanan melaporkan kesalahan pembatasan pada sumber atau jika penyimpanan data berada di bawah status pemanfaatan tinggi. Jika demikian, kurangi beban kerja Anda di penyimpanan data, atau coba hubungi administrator penyimpanan data untuk meningkatkan batas pembatasan atau sumber daya yang tersedia.
Periksa sumber salinan dan pola sink Anda:
Jika pola penyalinan Anda mendukung lebih dari 4 Unit Integrasi Data (DIU) - lihat bagian ini secara detail, umumnya Anda dapat mencoba meningkatkan DIU untuk mendapatkan kinerja yang lebih baik.
Jika tidak, pertimbangkan untuk membagi satu kumpulan data besar menjadi beberapa kumpulan data yang lebih kecil, dan biarkan pekerjaan salinan tersebut berjalan bersama setiap bagian dari data. Anda dapat melakukan ini dengan Lookup/GetMetadata + ForEach + Copy. Lihat Menyalin file dari beberapa kontainer atau Memigrasikan data dari Amazon S3 ke ADLS Gen2 atau templat solusi Penyalinan massal dengan tabel kontrol sebagai contoh umum.
Gunakan Azure IR di wilayah penyimpanan data sumber yang sama atau dekat.
"Transfer - menulis ke sink" mengalami durasi kerja yang panjang:
Adopsi praktik terbaik pemuatan data khusus konektor jika berlaku. Misalnya, saat menyalin data ke Azure Synapse Analytics, gunakan pernyataan PolyBase atau COPY.
Periksa apakah layanan melaporkan kesalahan pembatasan pada sink atau jika penyimpanan data berada di bawah status pemanfaatan tinggi. Jika demikian, kurangi beban kerja Anda di penyimpanan data, atau coba hubungi administrator penyimpanan data untuk meningkatkan batas pembatasan atau sumber daya yang tersedia.
Periksa sumber salinan dan pola sink Anda:
Jika pola penyalinan Anda mendukung lebih dari 4 Unit Integrasi Data (DIU) - lihat bagian ini secara detail, umumnya Anda dapat mencoba meningkatkan DIU untuk mendapatkan kinerja yang lebih baik.
Jika tidak, setel penyalinan paralel secara bertahap, perhatikan bahwa terlalu banyak penyalinan paralel bahkan dapat memperburuk kinerja.
Gunakan Azure IR di wilayah penyimpanan data sink yang sama atau dekat.
Memecahkan masalah aktivitas penyalinan di IR yang dihost sendiri
Ikuti langkah penyetelan performa untuk merencanakan dan melakukan uji performa untuk skenario Anda.
Saat kinerja penyalinan tidak memenuhi harapan, untuk memecahkan masalah aktivitas penyalinan tunggal yang berjalan di Azure Integration Runtime, jika Anda melihat tips penyetelan kinerja yang muncul dalam tampilan pemantauan penyalinan, terapkan saran tersebut, lalu coba lagi. Jika tidak, pahami detail eksekusi aktivitas penyalinan, periksa tahap mana yang memiliki durasi terpanjang, dan terapkan panduan di bawah ini untuk meningkatkan kinerja penyalinan:
"Antrean" mengalami durasi panjang: itu berarti aktivitas penyalinan menunggu lama dalam antrean sampai IR yang dihost sendiri memiliki sumber daya untuk dieksekusi. Periksa kapasitas dan penggunaan IR, dan tingkatkan atau perbesar sesuai dengan beban kerja.
"Transfer - Waktu ke byte pertama" mengalami durasi kerja yang panjang: itu berarti kueri sumber membutuhkan waktu lama untuk mengembalikan data apa pun. Periksa dan optimalkan kueri atau server. Jika memerlukan bantuan lebih lanjut, hubungi tim penyimpanan data.
"Transfer - Sumber daftar" mengalami durasi kerja yang lama: itu berarti enumerasi file sumber atau partisi data database sumber lambat.
Periksa apakah mesin IR yang dihost sendiri memiliki latensi rendah yang terhubung ke penyimpanan data sumber. Jika sumber berada di Azure, Anda dapat menggunakan alat ini untuk memeriksa latensi dari mesin IR yang dihost sendiri ke wilayah Azure, semakin sedikit semakin baik.
Saat menyalin data dari sumber berbasis file, jika Anda menggunakan filter wildcard pada jalur folder atau nama file (
wildcardFolderPathatauwildcardFileName), atau menggunakan filter waktu yang terakhir dimodifikasi file (modifiedDatetimeStartataumodifiedDatetimeEnd), perhatikan bahwa filter tersebut akan mengakibatkan aktivitas penyalinan yang mencantumkan semua file di bawah folder yang ditentukan ke sisi klien lalu menerapkan filter. Enumerasi file semacam itu bisa menjadi penyempitan terutama ketika hanya sekumpulan kecil file yang memenuhi aturan filter.Periksa apakah Anda dapat menyalin file berdasarkan jalur atau nama file yang dipartisi datetime. Cara seperti itu tidak membebani sumber daftar.
Periksa apakah Anda dapat menggunakan filter asli penyimpanan data sebagai gantinya, khususnya "prefiks" untuk Amazon S3/Penyimpanan Azure Blob/Azure Files dan "listAfter/listBefore" untuk ADLS Gen1. Filter tersebut adalah filter sisi server penyimpanan data dan akan memiliki kinerja yang jauh lebih baik.
Pertimbangkan untuk membagi satu kumpulan data besar menjadi beberapa kumpulan data yang lebih kecil, dan biarkan pekerjaan salinan tersebut berjalan bersama setiap bagian dari data. Anda dapat melakukan ini dengan Lookup/GetMetadata + ForEach + Copy. Lihat Menyalin file dari beberapa kontainer atau Memigrasikan data dari Amazon S3 ke templat solusi ADLS Gen2 sebagai contoh umum.
Periksa apakah layanan melaporkan kesalahan pembatasan pada sumber atau jika penyimpanan data Anda berada di bawah status pemanfaatan tinggi. Jika demikian, kurangi beban kerja Anda di penyimpanan data, atau coba hubungi administrator penyimpanan data untuk meningkatkan batas pembatasan atau sumber daya yang tersedia.
"Transfer - membaca dari sumber" mengalami durasi kerja yang panjang:
Periksa apakah mesin IR yang dihost sendiri memiliki latensi rendah yang terhubung ke penyimpanan data sumber. Jika sumber berada di Azure, Anda dapat menggunakan alat ini untuk memeriksa latensi dari mesin IR yang dihost sendiri ke wilayah Azure, semakin sedikit semakin baik.
Periksa apakah mesin IR yang dihost sendiri memiliki bandwidth masuk yang cukup untuk membaca dan mentransfer data secara efisien. Jika penyimpanan data sumber berada di Azure, Anda dapat menggunakan alat ini untuk memeriksa kecepatan pengunduhan.
Periksa tren penggunaan CPU dan memori IR yang dihost sendiri di portal Azure -> pabrik data Anda atau ruang kerja Synapse -> halaman gambaran umum. Pertimbangkan untuk meningkatkan/memperbesar IR jika penggunaan CPU tinggi atau memori yang tersedia rendah.
Adopsi praktik terbaik pemuatan data khusus konektor jika berlaku. Contohnya:
Saat menyalin data dari Oracle, Netezza, Teradata, SAP Hana, SAP Table, dan SAP Open Hub), aktifkan opsi partisi data untuk menyalin data secara paralel.
Saat menyalin data dari HDFS, konfigurasikan untuk menggunakan DistCp.
Saat menyalin data dari Amazon Redshift, konfigurasikan untuk menggunakan Redshift UNLOAD.
Periksa apakah layanan melaporkan kesalahan pembatasan pada sumber atau jika penyimpanan data berada di bawah status pemanfaatan tinggi. Jika demikian, kurangi beban kerja Anda di penyimpanan data, atau coba hubungi administrator penyimpanan data untuk meningkatkan batas pembatasan atau sumber daya yang tersedia.
Periksa sumber salinan dan pola sink Anda:
Jika Anda menyalin data dari penyimpanan data yang mendukung opsi partisi, pertimbangkan untuk secara bertahap menyetel penyalinan paralel, perhatikan bahwa terlalu banyak penyalinan paralel bahkan dapat memperburuk kinerja.
Jika tidak, pertimbangkan untuk membagi satu kumpulan data besar menjadi beberapa kumpulan data yang lebih kecil, dan biarkan pekerjaan salinan tersebut berjalan bersama setiap bagian dari data. Anda dapat melakukan ini dengan Lookup/GetMetadata + ForEach + Copy. Lihat Menyalin file dari beberapa kontainer atau Memigrasikan data dari Amazon S3 ke ADLS Gen2 atau templat solusi Penyalinan massal dengan tabel kontrol sebagai contoh umum.
"Transfer - menulis ke sink" mengalami durasi kerja yang panjang:
Adopsi praktik terbaik pemuatan data khusus konektor jika berlaku. Misalnya, saat menyalin data ke Azure Synapse Analytics, gunakan pernyataan PolyBase atau COPY.
Periksa apakah mesin IR yang dihost sendiri memiliki latensi rendah yang terhubung ke penyimpanan data sink. Jika sink berada di Azure, Anda dapat menggunakan alat ini untuk memeriksa latensi dari mesin IR yang dihost sendiri ke wilayah Azure, semakin sedikit semakin baik.
Periksa apakah mesin IR yang dihost sendiri memiliki bandwidth keluar yang cukup untuk mentransfer dan menulis data secara efisien. Jika penyimpanan data sink berada di Azure, Anda dapat menggunakan alat ini untuk memeriksa kecepatan pengunggahan.
Periksa apakah tren penggunaan CPU dan memori IR yang dihost sendiri di portal Azure -> pabrik data Anda atau ruang kerja Synapse -> halaman gambaran umum. Pertimbangkan untuk meningkatkan/memperbesar IR jika penggunaan CPU tinggi atau memori yang tersedia rendah.
Periksa apakah layanan melaporkan kesalahan pembatasan pada sink atau jika penyimpanan data berada di bawah status pemanfaatan tinggi. Jika demikian, kurangi beban kerja Anda di penyimpanan data, atau coba hubungi administrator penyimpanan data untuk meningkatkan batas pembatasan atau sumber daya yang tersedia.
Pertimbangkan untuk menyetel penyalinan paralel secara bertahap, perhatikan bahwa terlalu banyak penyalinan paralel bahkan dapat memperburuk kinerja.
Konektor dan kinerja IR
Bagian ini mengeksplorasi beberapa panduan pemecahan masalah kinerja untuk jenis konektor tertentu atau runtime integrasi.
Waktu eksekusi aktivitas bervariasi menggunakan Azure IR vs Azure VNet IR
Waktu eksekusi aktivitas bervariasi saat set data didasarkan pada Microsoft Integration Runtime yang berbeda.
Gejala: Cukup alihkan dropdown Layanan Tertaut dalam set data untuk melakukan aktivitas alur yang sama, tetapi memiliki runtime yang berbeda secara drastis. Ketika set data didasarkan pada Runtime Integrasi Microsoft Azure Virtual Network Terkelola, dibutuhkan lebih banyak waktu rata-rata daripada yang dijalankan saat berdasarkan Microsoft Integration Runtime Default.
Penyebab: Dengan memeriksa detail alur berjalan, Anda dapat melihat bahwa alur yang lambat berjalan di IR VNet Terkelola (Jaringan Virtual) saat yang normal berjalan di Azure IR. Secara desain, IR VNet Terkelola membutuhkan waktu antrean yang lebih lama daripada Azure IR karena kami tidak memesan satu node komputasi per instans layanan, sehingga ada pemanasan untuk setiap aktivitas penyalinan saat akan memulai, dan itu terjadi terutama pada VNet gabungan daripada Azure IR.
Kinerja rendah saat memuat data ke Azure SQL Database
Gejala: Menyalin data ke Azure SQL Database menjadi lambat.
Penyebab: Akar penyebab masalah sebagian besar dipicu oleh penyempitan sisi Azure SQL Database. Berikut adalah kemungkinan penyebabnya:
Tingkat Azure SQL Database tidak cukup tinggi.
Penggunaan DTU Azure SQL Database mendekati 100%. Anda dapat memantau kinerja dan mempertimbangkan untuk memutakhirkan tingkat Azure SQL Database.
Indeks tidak disetel dengan benar. Hapus semua indeks sebelum pemuatan data dan buat ulang setelah pemuatan selesai.
WriteBatchSize tidak cukup besar agar sesuai dengan ukuran baris skema. Cobalah untuk memperbesar properti untuk masalah ini.
Alih-alih inset massal, prosedur yang disimpan sedang digunakan, yang diharapkan memiliki kinerja yang lebih buruk.
Waktu habis atau kinerja lambat saat menguraikan file Excel besar
Gejala:
Saat membuat kumpulan data Excel dan mengimpor skema dari koneksi/toko, mempratinjau data, daftar, atau merefresh lembar kerja, Anda mungkin mengalami kesalahan waktu habis jika ukuran file excel berukuran besar.
Saat Anda menggunakan aktivitas penyalinan untuk menyalin data dari file Excel besar (>= 100 MB) ke penyimpanan data lain, Anda mungkin mengalami performa yang lambat atau masalah OOM.
Penyebab:
Untuk operasi seperti mengimpor skema, mempratinjau data, dan mencantumkan lembar kerja pada set data excel, batas waktu adalah 100 dtk dan statis. Untuk file Excel besar, operasi ini mungkin tidak selesai dalam nilai waktu habis.
Aktivitas penyalinan membaca seluruh file Excel ke dalam memori lalu menemukan lembar kerja dan sel yang ditentukan untuk membaca data. Perilaku ini disebabkan oleh penggunaan layanan SDK yang mendasarinya.
Resolusi:
Untuk mengimpor skema, Anda dapat menghasilkan file sampel yang lebih kecil, yang merupakan subset file asli, dan memilih "impor skema dari file sampel" alih-alih "impor skema dari koneksi/penyimpanan".
Untuk mencantumkan lembar kerja, di menu tarik-turun lembar kerja, Anda bisa mengklik "Edit" dan memasukkan nama/indeks lembar.
Untuk menyalin file excel berukuran besar (>100 MB) ke penyimpanan lain, Anda dapat menggunakan sumber Data Flow Excel yang melakukan streaming membaca dan memiliki performa yang baik.
Masalah OOM membaca file JSON/Excel/XML besar
Gejala: Saat Anda membaca file JSON/Excel/XML besar, Anda memenuhi masalah kehabisan memori (OOM) selama eksekusi aktivitas.
Penyebab:
- Untuk file XML besar: Masalah OOM membaca file XML besar adalah berdasarkan desain. Penyebabnya adalah bahwa seluruh file XML harus dibaca ke dalam memori karena merupakan objek tunggal, kemudian skema disimpulkan, dan data diambil.
- Untuk file Excel besar: Masalah OOM membaca file Excel besar adalah berdasarkan desain. Penyebabnya adalah bahwa SDK (POI/NPOI) yang digunakan harus membaca seluruh file excel ke dalam memori, lalu menyimpulkan skema dan mendapatkan data.
- Untuk file JSON besar: Masalah OOM membaca file JSON besar dirancang ketika file JSON adalah objek tunggal.
Rekomendasi: Terapkan salah satu opsi berikut untuk menyelesaikan masalah Anda.
- Opsi-1: Daftarkan runtime integrasi online yang dihost sendiri dengan komputer yang kuat (CPU/memori tinggi) untuk membaca data dari file besar Anda melalui aktivitas salin Anda.
- Opsi-2: Gunakan memori yang dioptimalkan dan kluster ukuran besar (misalnya, 48 core) untuk membaca data dari file besar Anda melalui aktivitas aliran data pemetaan.
- Opsi-3: Pisahkan file besar menjadi file kecil, lalu gunakan aktivitas salin atau pemetaan aliran data untuk membaca folder.
- Opsi-4: Jika Anda terjebak atau memenuhi masalah OOM selama menyalin folder XML/Excel/JSON, gunakan aktivitas foreach + aktivitas aliran data salin/pemetaan di alur Anda untuk menangani setiap file atau subfolder.
- Opsi-5: Lainnya:
- Untuk XML, gunakan aktivitas Notebook dengan kluster memori yang dioptimalkan untuk membaca data dari file jika setiap file memiliki skema yang sama. Saat ini, Spark memiliki implementasi yang berbeda untuk menangani XML.
- Untuk JSON, gunakan formulir dokumen yang berbeda (misalnya, Dokumen tunggal, Dokumen per baris dan Array dokumen) di pengaturan JSON di bawah pemetaan sumber aliran data. Jika konten file JSON adalah Dokumen per baris, itu mengonsumsi memori yang sangat sedikit.
Referensi lainnya
Berikut adalah pemantauan kinerja dan referensi penyetelan untuk beberapa penyimpanan data yang didukung:
- Azure Blob storage: Skalabilitas dan target kinerja untuk penyimpanan Blob dan daftar periksa Kinerja dan skalabilitas untuk penyimpanan Blob.
- Penyimpanan Azure Table: Skalabilitas dan target kinerja untuk penyimpanan Table dan daftar periksa Kinerja dan skalabilitas untuk penyimpanan Table.
- Microsoft Azure SQL Database: Anda dapat memantau kinerja dan memeriksa persentase Unit Transaksi Database (DTU).
- Azure Synapse Analytics: Kemampuannya diukur dalam Unit Gudang Data (DWU). Lihat Mengelola daya komputasi di Azure Synapse Analytics (Gambaran Umum).
- Azure Cosmos DB: Tingkat kinerja di Azure Cosmos DB.
- SQL Server: Memantau dan menyetel kinerja.
- Server file lokal: Penyetelan kinerja untuk server file.
Konten terkait
Lihat artikel aktivitas salin lainnya: