Transformasi sink di pemetaan aliran data
BERLAKU UNTUK: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Aliran data tersedia di Alur Azure Data Factory dan Azure Synapse. Artikel ini berlaku untuk memetakan aliran data. Jika Anda baru mengenal transformasi, silakan lihat artikel pengantar Transformasi data menggunakan aliran data pemetaan.
Setelah Anda selesai mengubah data Anda, tulislah menjadi penyimpanan tujuan dengan menggunakan transformasi sink. Setiap aliran data memerlukan setidaknya satu transformasi sink, tetapi Anda dapat menulis ke sink sebanyak yang diperlukan untuk menyelesaikan alur transformasi Anda. Untuk menulis ke sink tambahan, buat aliran baru melalui cabang baru dan pemisahan bersyarat.
Setiap transformasi sink dikaitkan dengan satu himpunan data atau layanan tertaut. Transformasi sink menentukan bentuk dan lokasi data yang ingin Anda tulis.
Himpunan data sebaris
Saat Anda membuat transformasi sink, pilih apakah informasi sink Anda ditentukan di dalam objek himpunan data atau dalam transformasi sink. Sebagian besar format hanya tersedia dalam satu atau lainnya. Untuk mempelajari cara menggunakan konektor tertentu, lihat dokumen konektor yang sesuai.
Saat format didukung untuk sebaris dan dalam objek himpunan data, ada keuntungan untuk keduanya. Objek himpunan data adalah entitas yang dapat digunakan kembali dalam aliran data dan aktivitas lain seperti Salin. Entitas yang dapat digunakan kembali ini sangat berguna ketika Anda menggunakan skema yang diperkuat. Himpunan data tidak berbasis di Spark. Terkadang, Anda mungkin perlu mengambil alih pengaturan atau proyeksi skema tertentu dalam transformasi sink.
Himpunan data sebaris disarankan saat Anda menggunakan skema fleksibel, instans sink satu kali, atau sink yang berparameter. Jika sink Anda sangat berparameter, himpunan data sebaris memungkinkan Anda untuk tidak membuat objek "dummy". Himpunan data sebaris berbasis di Spark sedangkan propertinya berasal dari aliran data.
Untuk menggunakan himpunan data sebaris, pilih format yang Anda inginkan di pemilih Jenis sink. Daripada memilih himpunan data sink, pilihlah layanan tertaut yang ingin Anda sambungkan.
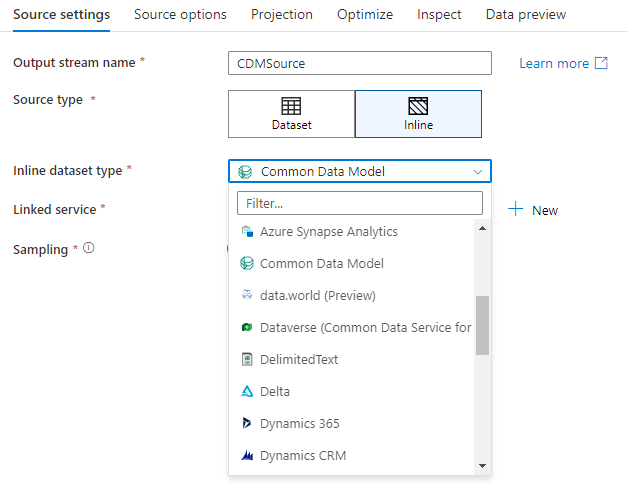
DB Workspace (hanya ruang kerja Synapse)
Saat menggunakan aliran data di ruang kerja Azure Synapse, Anda akan memiliki opsi tambahan untuk melakukan sink data Anda secara langsung ke jenis database yang ada di dalam ruang kerja Synapse Anda. Tindakan ini akan mengurangi kebutuhan untuk menambahkan layanan tertaut atau kumpulan data untuk database tersebut. Database yang dibuat melalui templat database Azure Synapse juga dapat diakses saat Anda memilih Workspace DB.
Catatan
Konektor DB Ruang Kerja Azure Synapse saat ini sedang dalam pratinjau publik dan hanya dapat bekerja dengan database Spark Lake saat ini
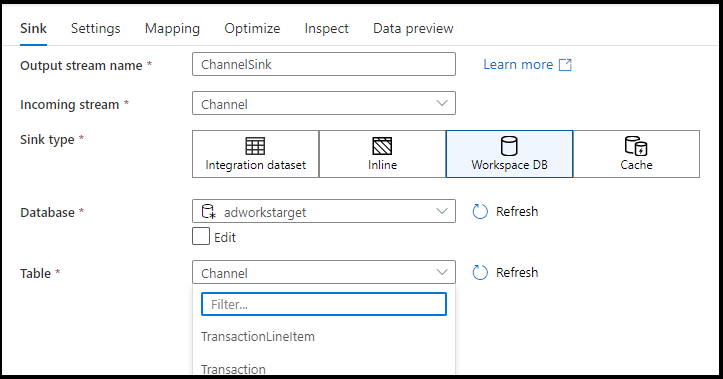
Jenis sink yang didukung
Pemetaan aliran data mengikuti pendekatan ekstrak, muat, dan transformasi (ELT) dan bekerja dengan himpunan data penahapan yang semuanya ada di Azure. Saat ini, himpunan data berikut dapat digunakan dalam transformasi sink.
| Konektor | Format | Himpunan data/sebaris |
|---|---|---|
| Penyimpanan Blob Azure | Avro Teks dibatasi Delta JSON ORC Parquet |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB for NoSQL | ✓/- | |
| Azure Data Lake Storage Gen1 | Avro Teks dibatasi JSON ORC Parquet |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage Gen2 | Avro Common Data Model Teks dibatasi Delta JSON ORC Parquet |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database untuk MySQL | ✓/✓ | |
| Azure Database untuk PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Azure SQL Database | ✓/✓ | |
| Instans Terkelola Azure SQL | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Fabric Lakehouse | ✓/✓ | |
| SFTP | Avro Teks dibatasi JSON ORC Parquet |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Snowflake | ✓/✓ | |
| SQL Server | ✓/✓ |
Pengaturan khusus untuk konektor ini terdapat di tab Pengaturan. Contoh skrip aliran informasi dan data pada pengaturan ini terdapat di dokumentasi konektor.
Layanan ini memiliki akses ke lebih dari 90 konektor asli. Untuk menulis data ke sumber lain dari aliran data Anda, gunakan Aktivitas Salin untuk memuat data tersebut dari sink yang didukung.
Pengaturan sink
Setelah menambahkan sink, konfigurasikan melalui tab Sink. Di sini Anda dapat memilih atau membuat himpunan data yang ditulis sink Anda. Nilai pengembangan untuk parameter himpunan data dapat dikonfigurasi dalam Pengaturan debug. (Mode debug harus dinyalakan.)
Video berikut menjelaskan sejumlah opsi sink yang berbeda untuk jenis file yang dibatasi teks.
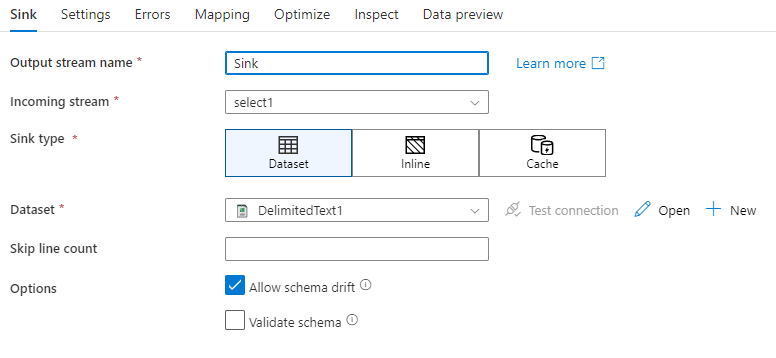
Drift skema: Drift skema adalah kemampuan layanan untuk menangani skema fleksibel secara native dalam aliran data Anda tanpa perlu secara eksplisit menentukan perubahan kolom. Aktifkan Perbolehkan drift skema untuk menulis kolom tambahan di atas apa yang ditentukan dalam skema data sink.
Skema validasi:Jika skema validasi dipilih, aliran data akan gagal jika ada kolom dalam proyeksi sink tidak ditemukan di sink simpan, atau jika tipe data tidak cocok. Gunakan pengaturan ini untuk menegakkan bahwa skema sink memenuhi kontrak proyeksi yang Anda tentukan. Ini berguna dalam skenario sink database untuk memberi sinyal bahwa nama atau jenis kolom telah berubah.
Sink cache
Sink cache adalah ketika aliran data menulis data ke dalam cache Spark alih-alih penyimpanan data. Dalam pemetaan aliran data, Anda dapat mereferensikan data ini dalam alur yang sama berkali-kali menggunakan pencarian cache. Ini berguna saat Anda ingin mereferensikan data sebagai bagian dari ekspresi tetapi tidak ingin secara eksplisit menggabungkan kolom ke dalamnya. Contoh umum di mana sink cache bisa membantu mencari nilai maksimal di penyimpanan data dan mencocokkan kode galat ke database pesan kesalahan.
Untuk menulis ke sink cache, tambahkan transformasi sink dan pilih Cache sebagai jenis sink. Tidak seperti jenis sink lainnya, Anda tidak perlu memilih himpunan data atau layanan tertaut karena Anda tidak menulis ke penyimpanan eksternal.
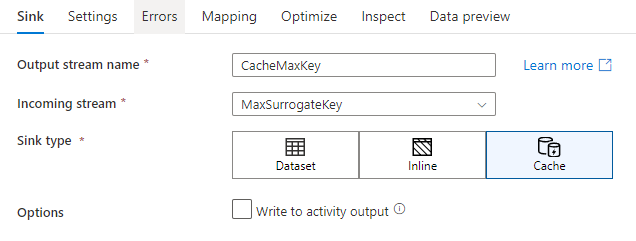
Di pengaturan sink, Anda dapat menentukan kolom kunci sink cache secara opsional. Ini digunakan sebagai kondisi pencocokan saat menggunakan fungsi lookup() dalam pencarian cache. Jika Anda menentukan kolom kunci, Anda tidak bisa menggunakan fungsi outputs() dalam pencarian cache. Untuk mempelajari selengkapnya tentang sintaks pencarian cache, lihat pencarian cache.
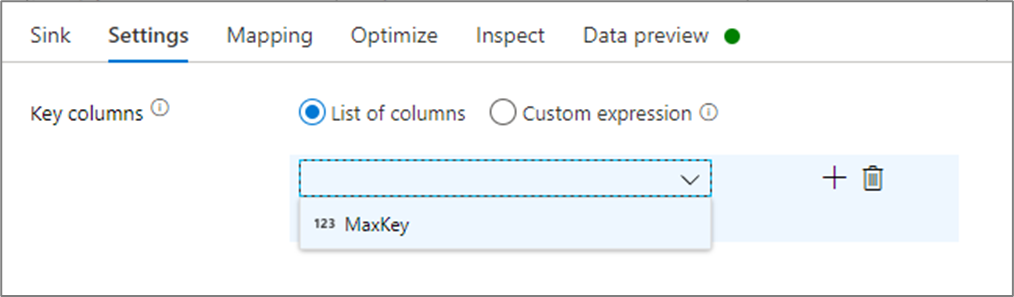
Misalnya, jika saya menentukan satu kolom kunci column1 di sink cache yang bernama cacheExample, panggilan cacheExample#lookup() akan memiliki satu parameter yang menentukan baris mana di sink cache yang cocok. Fungsi ini menghasilkan kolom kompleks tunggal dengan subkolom untuk setiap kolom yang dipetakan.
Catatan
Sink cache harus berada dalam aliran data yang sepenuhnya independen dari transformasi apa pun yang merujuknya melalui pencarian cache. Sink cache juga harus menjadi sink yang pertama kali ditulis.
Menulis ke output aktivitas Sink yang di-cache dapat secara opsional menulis data output ke input aktivitas alur berikutnya. Ini akan memungkinkan Anda untuk dengan cepat dan mudah mengeluarkan data dari aktivitas aliran data Anda tanpa perlu menyimpan data di penyimpanan data.
Perbarui() metode
Untuk jenis sink database, tab Pengaturan akan menyertakan properti "Perbarui metode". Defaultnya adalah sisipkan tetapi juga menyertakan opsi kotak centang untuk pembaruan, upsert, dan hapus. Untuk menggunakan opsi tambahan tersebut, Anda harus menambahkan transformasi Alter Row sebelum sink. Alter Row akan memungkinkan Anda menentukan kondisi untuk setiap tindakan database. Jika sumber Anda adalah sumber pengaktifan CDC asli, maka Anda dapat mengatur metode pembaruan tanpa Alter Row karena ADF sudah mengetahui penanda baris untuk menyisipkan, memperbarui, upsert, dan menghapus.
Pemetaan bidang
Mirip dengan memilih transformasi, pada tab Pemetaan sink, Anda bisa memutuskan kolom masuk mana yang akan ditulis. Secara default, semua kolom input, termasuk kolom yang di-drift, dipetakan. Perilaku ini dikenal sebagai automapping.
Saat Anda menonaktifkan automapping, Anda bisa menambahkan pemetaan berbasis kolom tetap atau pemetaan berbasis aturan. Dengan pemetaan berbasis aturan, Anda dapat menulis ekspresi dengan pencocokan pola. Peta pemetaan nama kolom logis dan fisik tetap. Untuk informasi selengkapnya tentang pemetaan berbasis aturan, lihat Pola kolom dalam pemetaan aliran data.
Urutan sink kustom
Secara default, data ditulis ke beberapa sink dalam urutan yang tidak ditentukan. Mesin eksekusi menulis data secara paralel saat logika transformasi selesai, dan urutan sink mungkin berbeda-beda setiap kali dijalankan. Untuk menentukan urutan sink yang tepat, aktifkan Urutan sink kustom pada tab Umum dari aliran data. Ketika diaktifkan, sink ditulis secara berurutan dalam urutan naik.
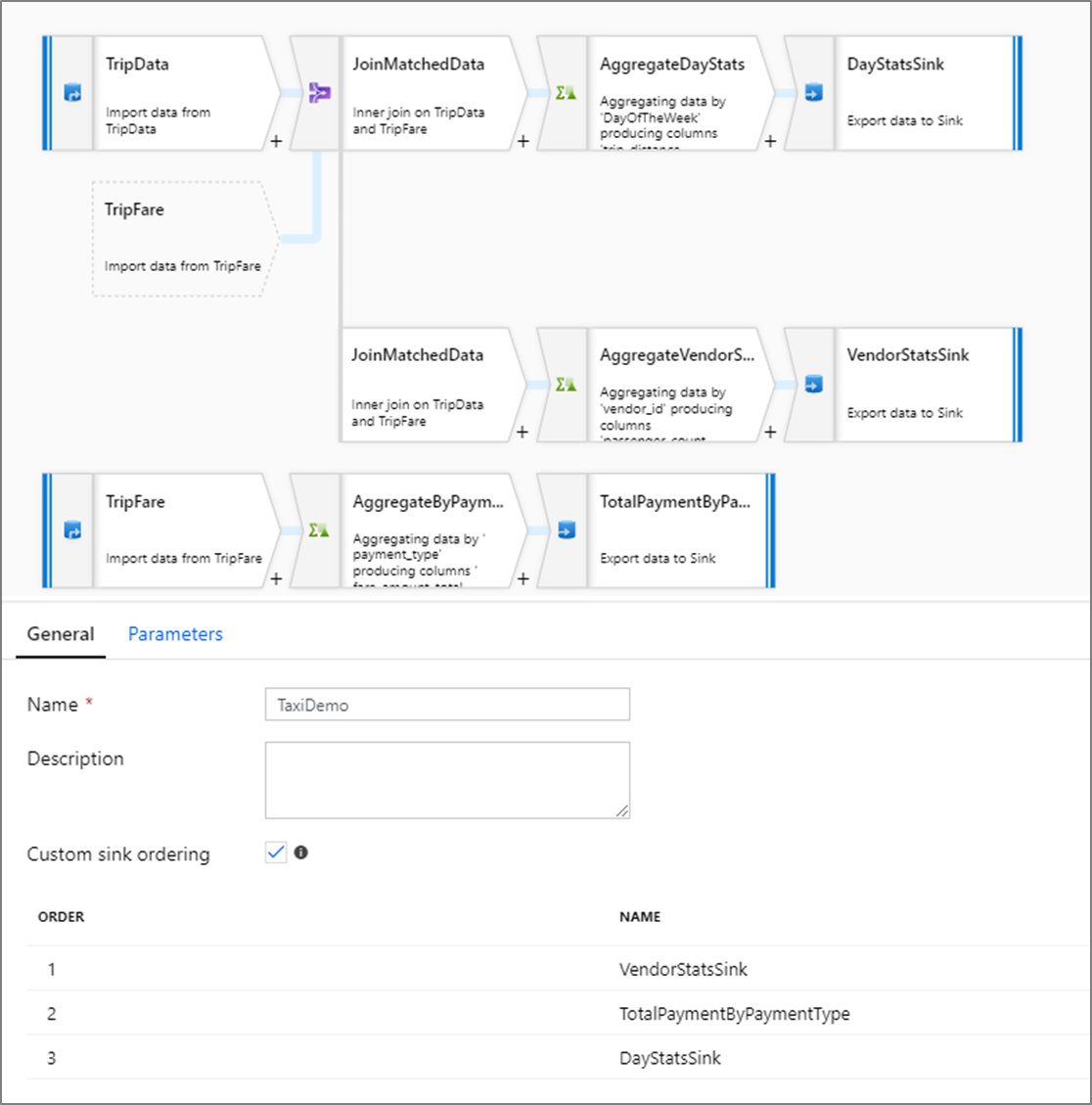
Catatan
Saat menggunakan pencarian cache, pastikan bahwa urutan sink Anda memiliki sink yang di-cache diatur ke 1, yang terendah (atau pertama) dalam urutan.
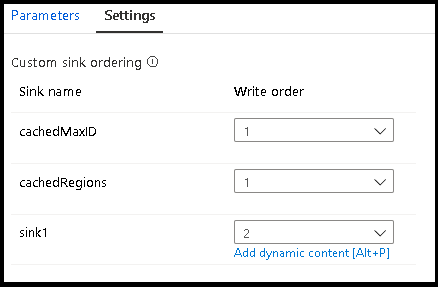
Grup sink
Anda dapat mengelompokkan sink bersama dengan menerapkan nomor urutan yang sama untuk serangkaian sink. Layanan ini akan memperlakukan sink tersebut sebagai kelompok yang dapat mengeksekusi secara paralel. Opsi untuk eksekusi paralel akan muncul dalam aktivitas aliran data alur.
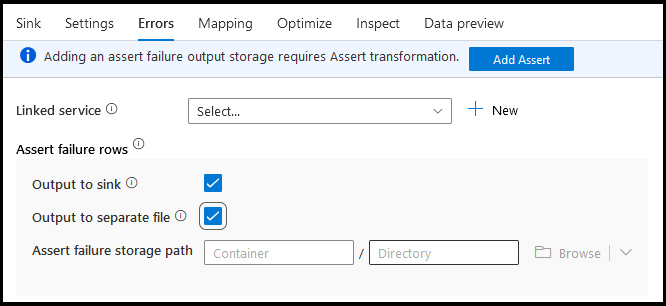
Kesalahan
Pada tab kesalahan sink, Anda dapat mengonfigurasi penanganan baris kesalahan guna menangkap dan mengalihkan output untuk kesalahan driver database dan pernyataan yang gagal.
Saat menulis ke database, baris data tertentu mungkin gagal karena batasan yang ditetapkan oleh tujuan. Secara default, eksekusi aliran data akan gagal pada kesalahan pertama yang diperolehnya. Di konektor tertentu, Anda dapat memilih untuk Melanjutkan kesalahan yang memungkinkan aliran data Anda selesai meskipun baris individual memiliki kesalahan. Saat ini, kemampuan ini hanya tersedia di Azure SQL Database dan Azure Synapse. Untuk informasi selengkapnya, lihat penanganan baris kesalahan di Azure SQL DB.
Di bawah ini adalah tutorial video tentang cara menggunakan penanganan baris kesalahan database secara otomatis dalam transformasi sink Anda.
Untuk menegaskan baris kegagalan, Anda dapat menggunakan transformasi penegasan upstram dalam aliran data Anda dan kemudian mengarahkan ulang pernyataan yang gagal ke file output di sini di tab kesalahan sink. Anda juga memiliki opsi di sini untuk mengabaikan baris dengan kegagalan pernyataan dan tidak menampilkan baris tersebut sama sekali ke penyimpanan data tujuan sink.
Pratinjau data dalam sink
Saat mengambil pratinjau data dalam mode debug, tidak ada data yang akan ditulis ke sink Anda. Rekam jepret seperti apa data akan dikembalikan, tetapi tidak ada yang akan ditulis ke tujuan Anda. Untuk menguji data penulisan ke sink Anda, jalankan debug alur dari kanvas alur.
Skrip aliran data
Contoh
Di bawah ini adalah contoh transformasi sink dan skrip aliran datanya:
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Konten terkait
Sekarang setelah Anda membuat aliran data, tambahkan aktivitas aliran data ke alur Anda.