Mentransformasikan data dengan menjalankan aktivitas Jar di Azure Databricks
BERLAKU UNTUK: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Aktivitas Azure Databricks Jar dalam alur menjalankan Spark Jar di kluster Azure Databricks Anda. Artikel ini membangun artikel aktivitas transformasi data, yang menyajikan gambaran umum tentang transformasi data dan aktivitas transformasi yang didukung. Azure Databricks adalah platform terkelola untuk menjalankan Apache Spark.
Untuk pengenalan dan demonstrasi sebelas menit dari fitur ini, tonton video berikut:
Menambahkan aktivitas Jar untuk Azure Databricks ke alur dengan antarmuka pengguna
Agar dapat menggunakan aktivitas Jar untuk Azure Databricks dalam suatu alur, selesaikan langkah-langkah berikut:
Cari Jar di panel Aktivitas alur, dan seret aktivitas Jar ke kanvas alur.
Pilih aktivitas Jar baru di kanvas jika belum dipilih.
Pilih tab Azure Databricks untuk memilih atau membuat layanan tertaut Azure Databricks baru yang akan menjalankan aktivitas Jar.
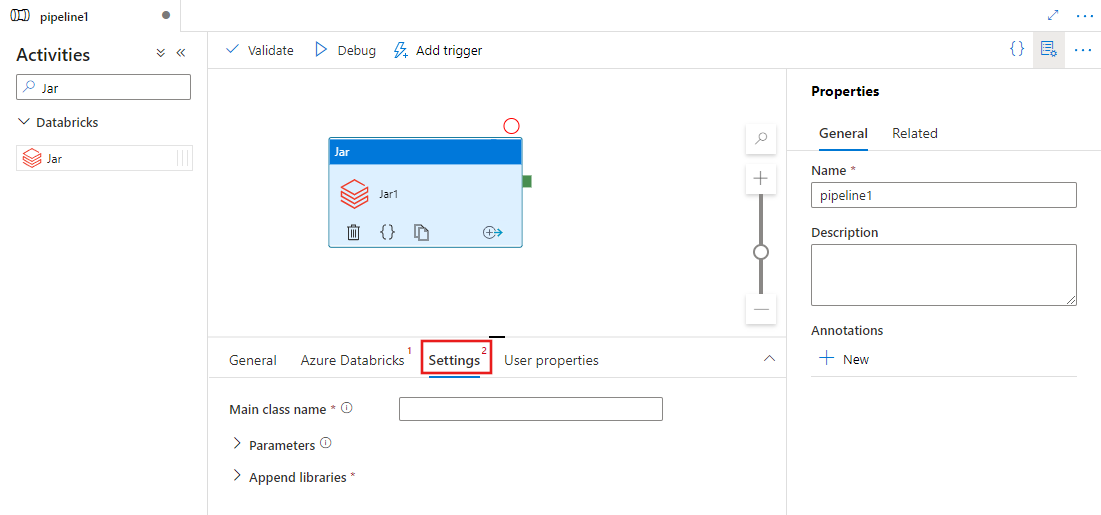
Pilih tab Pengaturan dan tentukan nama kelas yang akan dijalankan di Azure Databricks, parameter opsional yang akan diteruskan ke Jar, dan pustaka yang akan diinstal di kluster untuk menjalankan pekerjaan.
Definisi aktivitas Databricks Jar
Berikut contoh definisi JSON dari Aktivitas Jar Databricks:
{
"name": "SparkJarActivity",
"type": "DatabricksSparkJar",
"linkedServiceName": {
"referenceName": "AzureDatabricks",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mainClassName": "org.apache.spark.examples.SparkPi",
"parameters": [ "10" ],
"libraries": [
{
"jar": "dbfs:/docs/sparkpi.jar"
}
]
}
}
Properti aktivitas Databricks Jar
Tabel berikut menjelaskan properti JSON yang digunakan dalam definisi JSON:
| Properti | Deskripsi | Wajib |
|---|---|---|
| nama | Nama aktivitas di dalam alur. | Ya |
| description | Teks yang menjelaskan apa yang dilakukan aktivitas. | Tidak |
| jenis | Untuk Databricks Jar Activity, jenis aktivitasnya adalah DatabricksSparkJar. | Ya |
| linkedServiceName | Nama Layanan Tertaut Databricks tempat aktivitas Jar berjalan. Untuk mempelajari layanan tertaut ini, lihat artikel Layanan tertaut komputasi. | Ya |
| mainClassName | Nama lengkap kelas yang berisi metode utama yang akan dijalankan. Kelas ini harus terkandung dalam JAR yang disediakan sebagai pustaka. File JAR dapat berisi beberapa kelas. Masing-masing kelas dapat berisi metode utama. | Ya |
| parameter | Parameter yang akan diteruskan ke metode utama. Properti ini adalah array untai (karakter). | Tidak |
| pustaka | Daftar pustaka yang akan diinstal di kluster yang akan menjalankan pekerjaan. Daftar ini dapat berupa larik dari <string, objek> | Ya (setidaknya satu berisi metode mainClassName) |
Catatan
Masalah Yang Diketahui - Ketika menggunakan Kluster interaktif yang sama untuk menjalankan aktivitas Databricks Jar bersamaan (tanpa menghidupkan ulang kluster), ada masalah yang diketahui dalam Databricks tempat parameter aktivitas pertama akan digunakan dengan mengikuti kegiatan juga. Oleh karena itu mengakibatkan parameter yang salah diteruskan ke pekerjaan berikutnya. Untuk mengurangi hal ini, gunakan Kluster job sebagai gantinya.
Pustaka yang didukung untuk aktivitas databricks
Dalam definisi aktivitas Databricks sebelumnya, Anda menentukan jenis pustaka ini: jar, egg, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Untuk informasi selengkapnya, lihat Dokumentasi Databricks untuk mengetahui jenis pustaka.
Cara mengunggah pustaka di Databricks
Anda dapat menggunakan antarmuka pengguna Ruang Kerja:
Untuk mendapatkan jalur dbfs dari pustaka yang ditambahkan menggunakan antarmuka pengguna, Anda dapat menggunakan Databricks CLI.
Biasanya, pustaka Jar disimpan di bawah dbfs:/FileStore/jars saat menggunakan antarmuka pengguna. Anda dapat mencantumkan semuanya melalui CLI: databricks fs ls dbfs:/FileStore/job-jars
Atau, Anda dapat menggunakan Databricks CLI:
Menggunakan Databricks CLI (langkah penginstalan)
Sebagai contoh, untuk menyalin JAR ke dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar
Konten terkait
Untuk pengenalan dan demonstrasi sebelas menit dari fitur ini, tonton video berikut.