Mulai Cepat: Buat kluster Apache Hadoop di Azure HDInsight menggunakan portal Microsoft Azure
Dalam artikel ini, Anda akan mempelajari cara membuat kluster Apache Hadoop di HDInsight menggunakan portal Microsoft Azure, lalu menjalankan pekerjaan Apache Hive di HDInsight. Sebagian besar pekerjaan Hadoop adalah tugas batch. Anda membuat kluster, menjalankan beberapa pekerjaan, lalu menghapus kluster. Dalam artikel ini, Anda akan melakukan ketiga tugas tersebut. Untuk penjelasan mendalam tentang konfigurasi yang tersedia, lihat Siapkan kluster di HDInsight. Untuk informasi tambahan mengenai penggunaan portal untuk membuat kluster, lihat Membuat kluster di portal.
Dalam mulai cepat ini, Anda akan menggunakan portal Microsoft Azure untuk membuat kluster Hadoop HDInsight. Anda juga dapat membuat kluster menggunakan templat Azure Resource Manager.
Saat ini, HDInsight hadir dengan tujuh jenis kluster yang berbeda. Setiap jenis kluster mendukung set komponen yang berbeda. Semua jenis kluster mendukung Apache Hive. Untuk daftar komponen yang didukung di HDInsight, lihat Apa yang baru dalam versi kluster Apache Hadoop yang disediakan oleh HDInsight?
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
Buat kluster Apache Hadoop
Di bagian ini, Anda membuat kluster Hadoop di HDInsight menggunakan portal Microsoft Azure.
Masuk ke portal Azure.
Dari menu di bagian atas, pilih + Buat sumber daya.
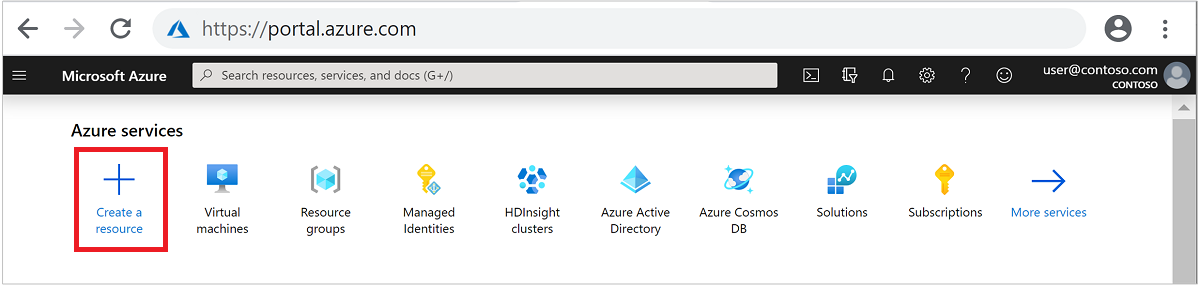
Pilih Analitik>Azure HDInsight untuk masuk ke halaman Buat kluster HDInsight.
Pada tab Dasar, berikan informasi berikut ini:
Properti Deskripsi Langganan Dari daftar dropdown, pilih langganan Azure yang digunakan untuk kluster. Grup sumber daya Dari daftar dorp-down, pilih grup sumber daya yang sudah ada, atau pilih Buat baru. Nama kluster Masukkan nama yang unik secara global. Nama ini dapat terdiri hingga 59 karakter termasuk huruf, angka, dan tanda hubung. Karakter pertama dan terakhir dari nama tersebut tidak boleh berupa tanda hubung. Wilayah Dari daftar drop-down, pilih wilayah tempat kluster dibuat. Pilih wilayah yang lebih dekat dengan Anda untuk performa yang lebih baik. Jenis kluster Pilih Pilih jenis kluster. Kemudian pilih Hadoop sebagai jenis kluster. Versi Dari daftar dropdown, pilih versi. Gunakan versi default jika Anda tidak tahu versi mana yang harus dipilih. Nama pengguna dan kata sandi untuk masuk kluster Nama login default adalah admin. Panjang kata sandi harus minimal 10 karakter dan harus berisi setidaknya satu digit, satu huruf besar, dan satu huruf kecil, satu karakter non-alfanumerik (kecuali karakter ' ` "). Pastikan Anda tidak memberikan sandi umum seperti "Pass@word1".Nama pengguna Secure Shell (SSH) Nama pengguna default adalah sshuser. Anda dapat memberikan nama lain untuk nama pengguna SSH.Menggunakan sandi login kluster untuk SSH Pilih kotak centang ini untuk menggunakan kata sandi yang sama untuk pengguna SSH seperti yang Anda sediakan untuk pengguna masuk kluster. 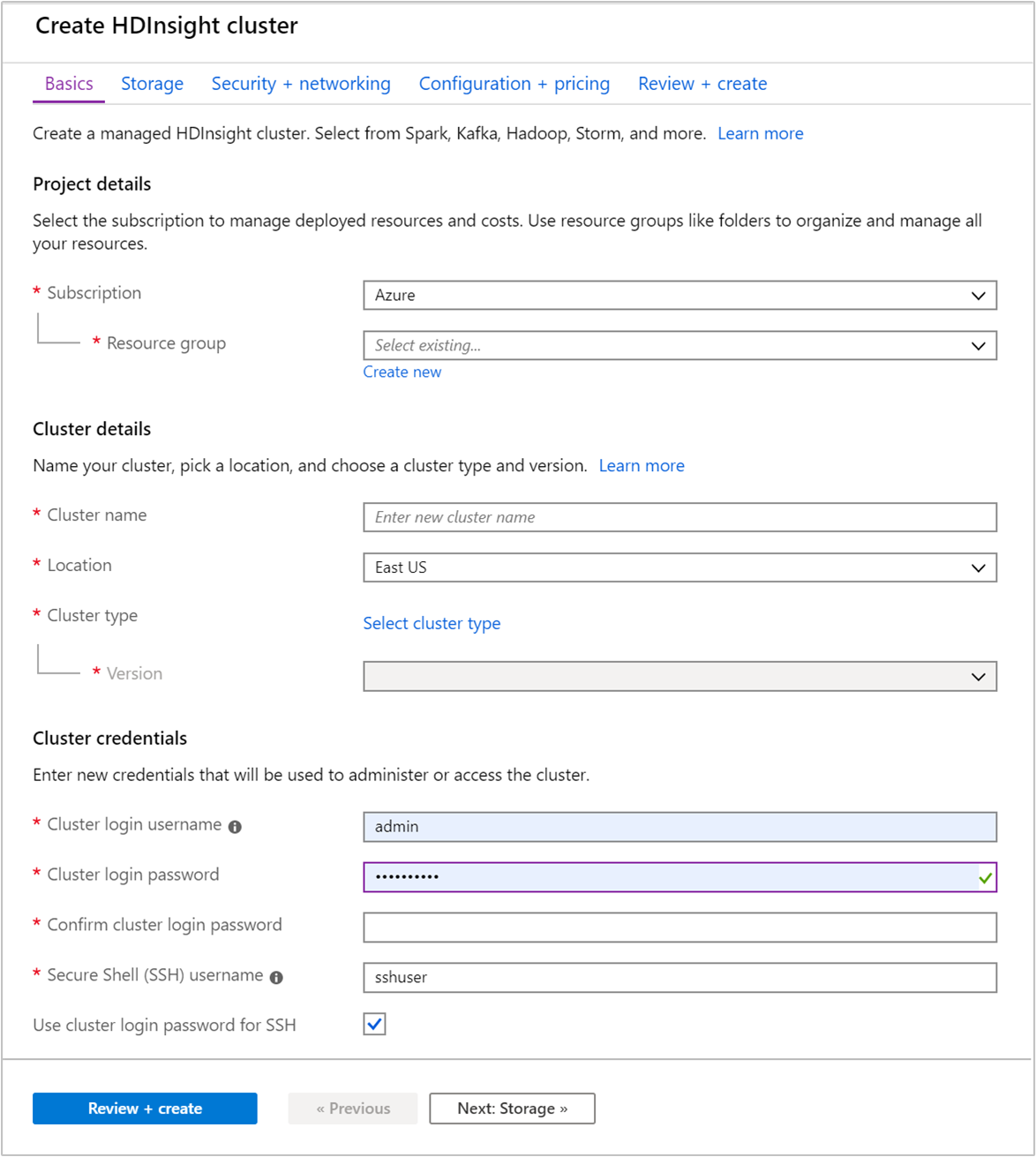
Pilih Berikutnya: Penyimpanan >> untuk melanjutkan ke pengaturan penyimpanan.
Dari tab Penyimpanan, berikan nilai berikut ini:
Properti Deskripsi Jenis penyimpanan utama Gunakan nilai default Azure Storage. Metode pemilihan Gunakan nilai default Pilih dari daftar. Akun penyimpanan primer Gunakan daftar drop-down untuk memilih akun penyimpanan yang sudah ada, atau pilih Buat baru. Jika Anda membuat akun baru, namanya harus terdiri dari 3 sampai 24 karakter, dan hanya bisa menyertakan angka serta huruf kecil Kontainer Gunakan nilai yang diisi otomatis. 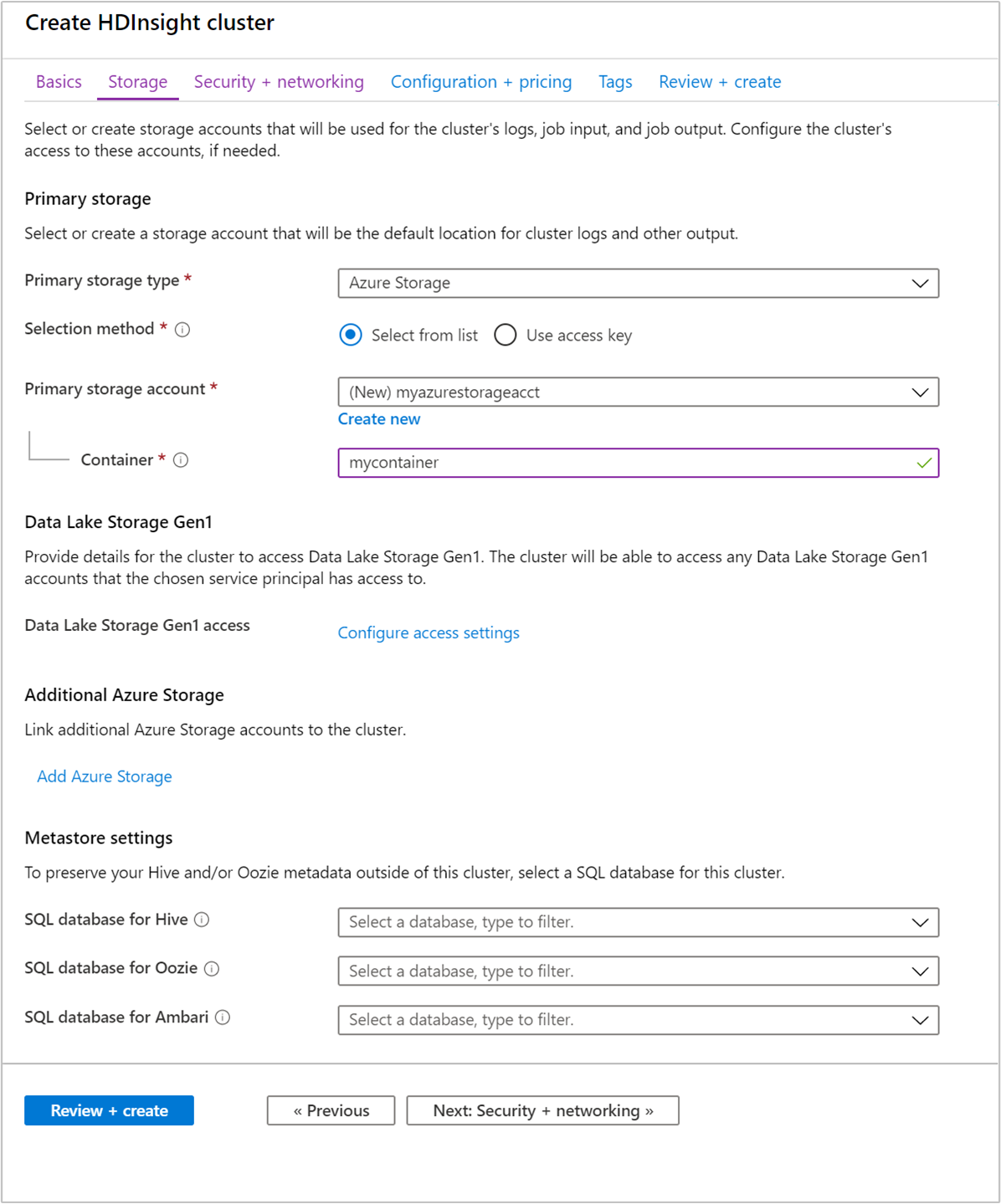
Setiap kluster memiliki akun Azure Storage, Azure Data Lake Gen1, atau dependensi
Azure Data Lake Storage Gen2. Hal ini disebut sebagai akun penyimpanan default. Kluster HDInsight dan akun penyimpanan defaultnya harus berada di wilayah Azure yang sama. Menghapus kluster tidak menghapus akun penyimpanan.Pilih tab Tinjau + buat.
Dari tab Tinjau + buat, verifikasi nilai yang Anda pilih pada langkah-langkah sebelumnya.
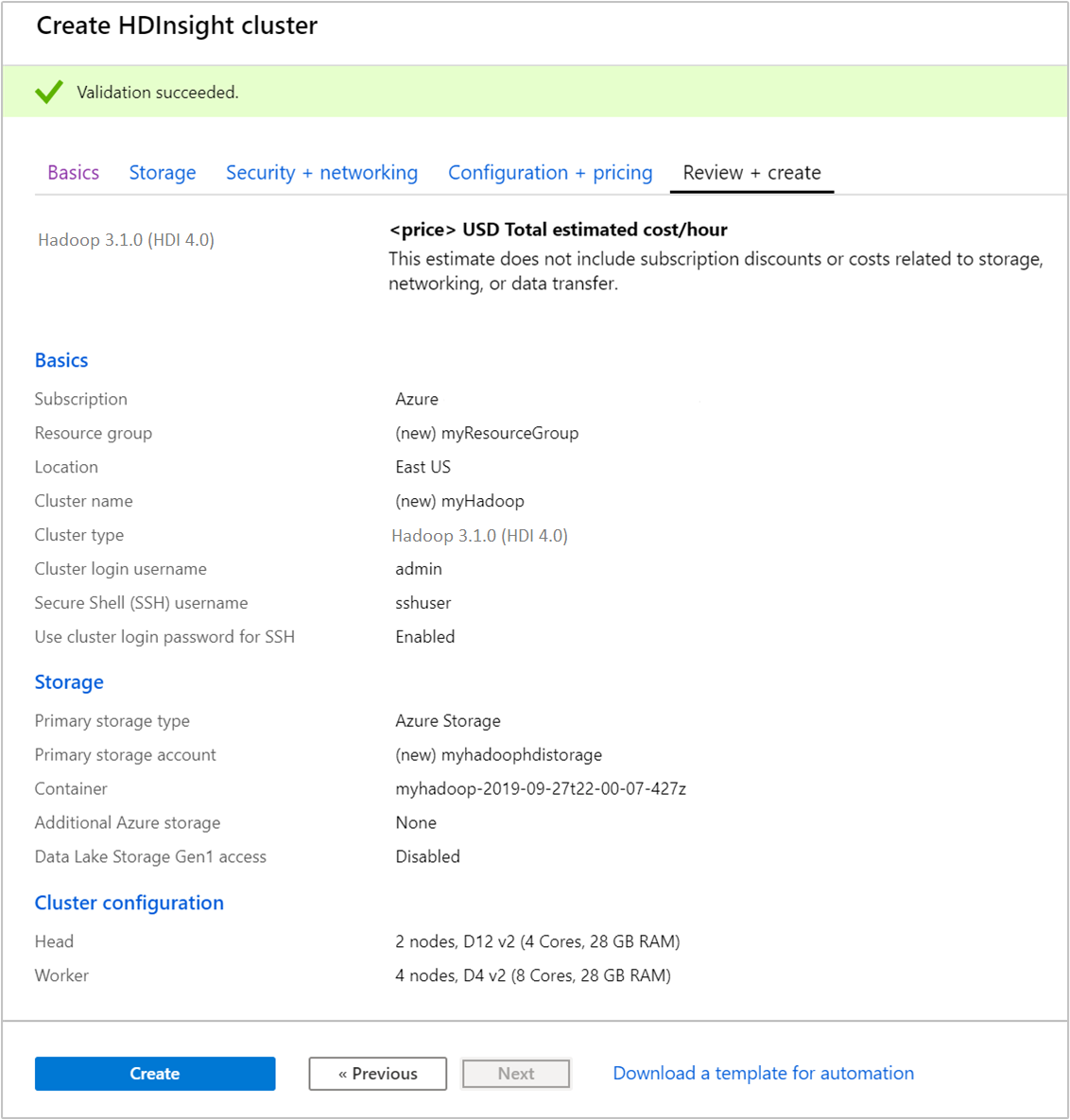
Pilih Buat. Dibutuhkan sekitar 20 menit untuk membuat kluster.
Setelah kluster dibuat, Anda akan melihat halaman gambaran umum kluster di portal Microsoft Azure.

Menjalankan kueri Apache Hive
Apache Hive adalah komponen paling populer yang digunakan dalam HDInsight. Ada banyak cara untuk menjalankan pekerjaan Apache Hive di HDInsight. Dalam mulai cepat ini, Anda akan menggunakan tampilan Ambari Apache Hive dari portal. Untuk metode lain untuk mengirimkan pekerjaan Apache Hive, lihat Menggunakan Apache Hive di HDInsight.
Catatan
Apache Hive View tidak tersedia di HDInsight 4.0.
Untuk membuka Ambari, dari cuplikan layar sebelumnya, pilih Dasbor Kluster. Anda juga dapat menelusuri ke
https://ClusterName.azurehdinsight.netdi manaClusterNameadalah kluster yang Anda buat di bagian sebelumnya.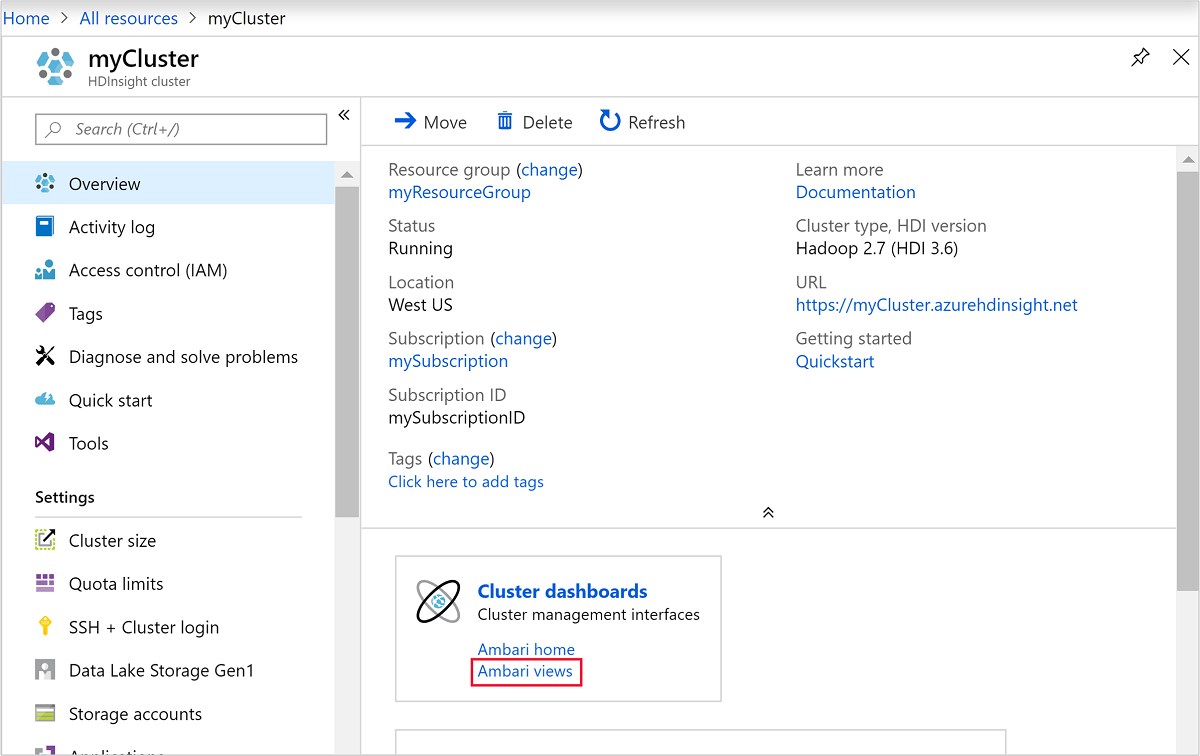
Masukkan nama pengguna dan kata sandi Hadoop yang Anda tentukan saat membuat kluster. Nama pengguna default adalah
admin.Buka Tampilan Apache Hive seperti yang ditunjukkan pada cuplikan layar berikut:
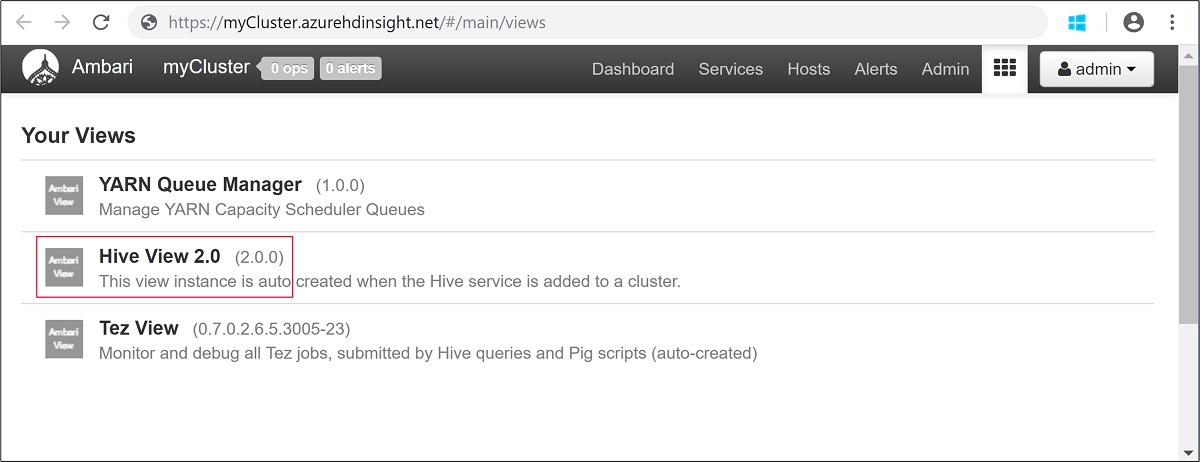
Di tab QUERY, tempelkan pernyataan HiveQL berikut ini ke dalam lembar kerja:
SHOW TABLES;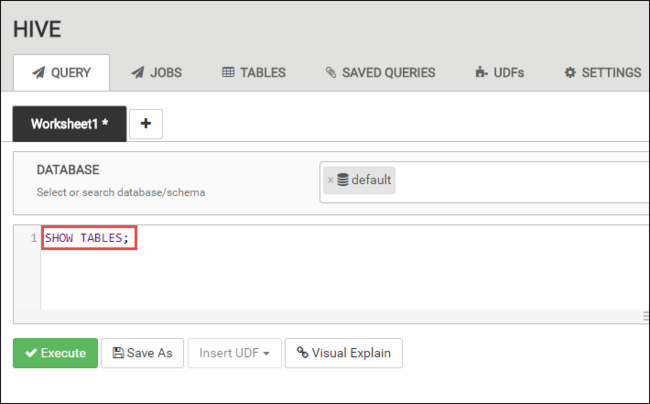
Pilih Jalankan. Tab HASIL muncul di bawah tab KUERI dan menampilkan informasi tentang pekerjaan tersebut.
Setelah kueri selesai, tab QUERY akan menampilkan hasil operasi. Anda akan melihat satu tabel yang disebut hivesampletable. Sampel tabel Apache Hive ini dilengkapi dengan semua kluster HDInsight.
Ulangi langkah 4 dan langkah 5 untuk menjalankan kueri berikut ini:
SELECT * FROM hivesampletable;Anda juga bisa menyimpan hasil kueri. Pilih tombol menu di sebelah kanan, dan tentukan apakah Anda ingin mengunduh hasilnya sebagai file CSV atau menyimpannya ke akun penyimpanan yang terkait dengan kluster.
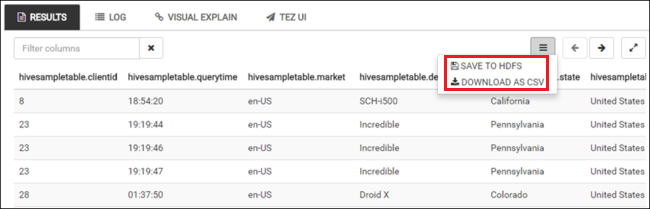
Setelah menyelesaikan pekerjaan Apache Hive, Anda bisa mengekspor hasilnya ke Azure SQL Database atau database SQL Server, Anda juga bisa memvisualisasikan hasilnya menggunakan Excel. Untuk informasi selengkapnya tentang menggunakan Hive di HDInsight, lihat Menggunakan Apache Hive dan HiveQL dengan Apache Hadoop di HDInsight untuk menganalisis file Apache log4j sampel.
Membersihkan sumber daya
Setelah Anda menyelesaikan mulai cepat, Anda dapat menghapus kluster. Dengan HDInsight, data Anda disimpan di Azure Storage, sehingga Anda dapat menghapus kluster dengan aman saat tidak digunakan. Anda juga dikenakan biaya untuk klaster HDInsight, bahkan saat tidak digunakan. Karena biaya untuk kluster berkali-kali lebih banyak daripada biaya untuk penyimpanan, masuk akal secara ekonomis untuk menghapus kluster saat tidak digunakan.
Catatan
Jika Anda segera melanjutkan ke artikel berikutnya untuk mempelajari cara menjalankan operasi ETL menggunakan Hadoop di HDInsight, Anda mungkin ingin membiarkan kluster tetap berjalan. Hal ini karena dalam tutorial Anda harus membuat kluster Hadoop lagi. Namun, jika Anda tidak akan langsung menuju ke artikel berikutnya, Anda harus menghapus kluster sekarang.
Untuk menghapus kluster dan/atau akun penyimpanan default
Kembali ke tab browser tempat Anda memiliki portal Microsoft Azure. Anda akan berada di halaman gambaran umum kluster. Jika Anda hanya ingin menghapus kluster tetapi ingin mempertahankan akun penyimpanan default, pilih Hapus.
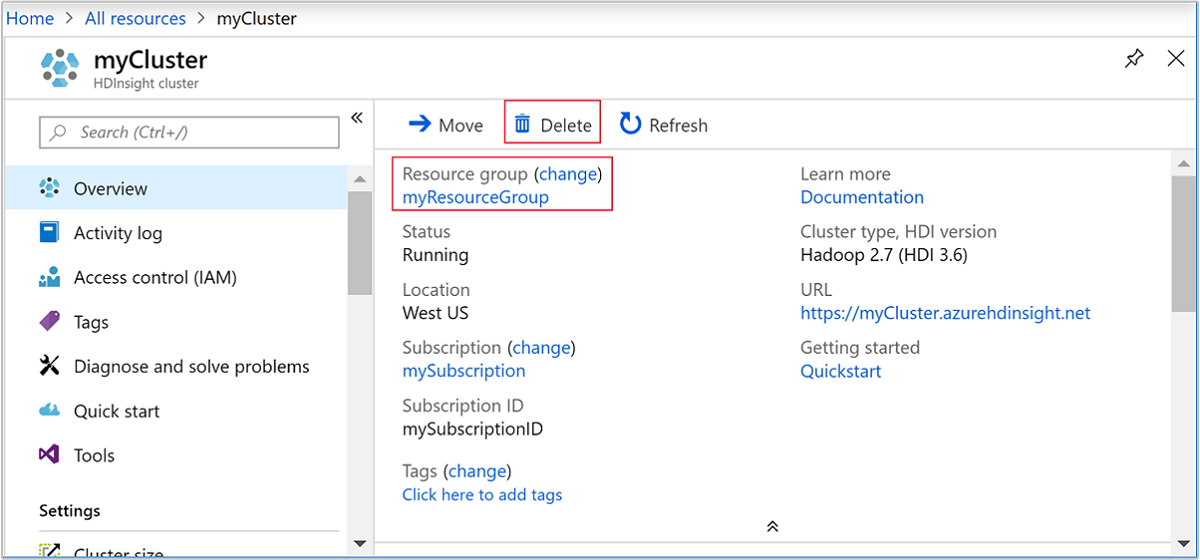
Jika Anda ingin menghapus kluster serta akun penyimpanan defaultnya, pilih nama grup sumber daya (yang disorot di cuplikan layar sebelumnya) untuk membuka halaman grup sumber daya.
Pilih Hapus grup sumber daya untuk menghapus grup sumber daya, yang berisi kluster dan akun penyimpanan default. Perhatikan bahwa menghapus grup sumber daya juga akan menghapus akun penyimpanan. Jika Anda ingin menyimpan akun penyimpanan, pilih untuk menghapus kluster saja.
Langkah berikutnya
Dalam mulai cepat ini, Anda akan mempelajari cara membuat kluster HDInsight berbasis Linux menggunakan templat Resource Manager, dan cara melakukan kueri Apache Hive dasar. Pada artikel berikutnya, Anda akan mempelajari cara melakukan operasi ekstrak, ubah, dan muat (ETL) menggunakan Hadoop di HDInsight.