Mengintegrasikan Apache Spark dan Apache Hive dengan Hive Warehouse Connector di Azure HDInsight
Apache Hive Warehouse Connector (HWC) adalah pustaka yang memungkinkan Anda untuk bekerja lebih mudah dengan Apache Spark dan Apache Hive. Ia mendukung tugas-tugas seperti pemindahan data antara tabel Spark DataFrames dan Hive. Juga, dengan mengarahkan data streaming Spark ke dalam tabel Hive. Hive Warehouse Connector berfungsi seperti jembatan antara Spark dan Hive. Ia juga mendukung Scala, Java, dan Python sebagai bahasa pemrograman untuk pengembangan.
Hive Warehouse Connector memungkinkan Anda untuk memanfaatkan fitur unik Hive dan Spark untuk membangun aplikasi big-data yang kuat.
Apache Hive menawarkan dukungan untuk transaksi database yang bersifat Atom, Konsisten, Terisolasi, dan Tahan Lama (ACID). Untuk informasi selengkapnya tentang ACID dan transaksi di Hive, lihat Transaksi Hive. Hive juga menawarkan kontrol keamanan terperinci melalui Apache Ranger dan Low Latency Analytical Processing (LLAP) yang tidak tersedia di Apache Spark.
Apache Spark memiliki API Streaming Terstruktur yang memberikan kemampuan streaming yang tidak tersedia di Apache Hive. Dimulai dengan HDInsight 4.0, Apache Spark 2.3.1 & di atasnya, dan Apache Hive 3.1.0 memiliki katalog metastore terpisah, yang membuat interoperabilitas sulit.
Hive Warehouse Connector (HWC) memudahkan penggunaan Spark dan Hive secara bersamaan. Pustaka HWC memuat data dari daemon LLAP ke eksekutor Spark secara paralel. Proses ini lebih efisien dan lebih mudah beradaptasi daripada koneksi JDBC standar dari Spark ke Apache Hive. Hal ini memunculkan dua mode eksekusi berbeda untuk HWC:
- Mode Hive JDBC melalui HiveServer2
- Mode Hive LLAP menggunakan daemon LLAP [Disarankan]
Secara default, HWC dikonfigurasi untuk menggunakan daemon Hive LLAP. Untuk menjalankan kueri Apache Hive (baca dan tulis) menggunakan mode di atas dengan API masing-masing, lihat API HWC.

Beberapa operasi yang didukung oleh Hive Warehouse Connector adalah:
- Penjelasan tabel
- Pembuatan tabel untuk data berformat ORC
- Pemilihan data Hive dan pengambilan DataFrame
- Penulisan DataFrame ke Hive dalam batch
- Pelaksanaan pernyataan pembaruan Apache Hive
- Pembacaan data tabel dari Hive, pengubahannya di Spark, dan penulisannya ke tabel Hive baru
- Penulisan DataFrame atau Spark stream ke Hive menggunakan HiveStreaming
Penyiapan Hive Warehouse Connector
Penting
- Instans HiveServer2 Interactive yang diinstal pada klaster Paket Keamanan Perusahaan Spark 2.4 tidak mendukung untuk digunakan dengan Hive Warehouse Connector. Sebagai gantinya, Anda harus mengonfigurasi klaster Apache HiveServer2 Interactive terpisah untuk menghosting beban kerja HiveServer2 Interactive Anda. Konfigurasi Hive Warehouse Connector yang menggunakan satu klaster Spark 2.4 tidak didukung.
- Pustaka Hive Warehouse Connector(HWC) tidak mendukung untuk digunakan dengan Klaster Interactive Query tempat fitur Workload Management (WLM) diaktifkan.
Dalam skenario di mana Anda hanya memiliki beban kerja Spark dan ingin menggunakan Pustaka HWC, pastikan klaster Interactive Query tidak mengaktifkan fitur Workload Management (konfigurasihive.server2.tez.interactive.queuetidak diatur dalam konfigurasi Hive).
Untuk skenario di mana beban kerja Spark (HWC) dan beban kerja asli LLAP ada, Anda perlu membuat dua Klaster Interactive Query terpisah dengan berbagi database metastore. Satu klaster untuk beban kerja LLAP asli di mana fitur WLM dapat diaktifkan berdasarkan kebutuhan dan klaster lain untuk beban kerja HWC saja di mana fitur WLM tidak boleh dikonfigurasikan. Penting untuk dicatat bahwa Anda dapat melihat paket sumber daya WLM dari kedua kluster meskipun diaktifkan hanya dalam satu kluster. Jangan membuat perubahan apa pun pada rencana sumber daya di klaster tempat fitur WLM dinonaktifkan karena dapat memengaruhi fungsionalitas WLM di klaster lain. - Meskipun Spark mendukung bahasa komputasi R untuk menyederhanakan analisis datanya, Pustaka Hive Warehouse Connector (HWC) tidak didukung untuk digunakan dengan R. Untuk menjalankan beban kerja HWC, Anda dapat menjalankan kueri dari Spark ke Hive menggunakan API HiveWarehouseSession gaya JDBC yang hanya mendukung Scala, Java, dan Python.
- Menjalankan kueri (baik baca dan tulis) melalui HiveServer2 melalui mode JDBC tidak didukung untuk jenis data kompleks seperti jenis Array/Struct/Map.
- HWC hanya mendukung menulis dalam format file ORC. Penulisan non-ORC (misalnya: format file parquet dan teks) tidak didukung melalui HWC.
Hive Warehouse Connector membutuhkan klaster terpisah untuk beban kerja Spark dan Interactive Query. Ikuti langkah-langkah ini untuk menyiapkan klaster ini di Azure HDInsight.
Jenis & versi Kluster yang Didukung
| Versi HWC | Versi Spark | Versi InteractiveQuery |
|---|---|---|
| v1 | Spark 2.4 | HDI 4.0 | Interactive Query 3.1 | HDI 4.0 |
| v2 | Spark 3.1 | HDI 5.0 | Interactive Query 3.1 | HDI 5.0 |
Buat kluster
Buat klaster HDInsight Spark 4.0 dengan akun penyimpanan dan jaringan virtual Azure kustom. Untuk informasi tentang pembuatan klaster di jaringan virtual Azure, lihat Menambahkan HDInsight ke jaringan virtual yang sudah ada.
Buat klaster HDInsight Interactive Query (LLAP) 4.0 dengan akun penyimpanan yang sama dan jaringan virtual Azure sebagai klaster Spark.
Mengonfigurasi pengaturan HWC
Mengumpulkan informasi awal
Dari browser web, arahkan ke
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVEdi mana LLAPCLUSTERNAME adalah nama klaster Interactive Query Anda.Arahkan ke Ringkasan>URL JDBC Interaktif HiveServer2 dan catat nilainya. Nilainya mungkin mirip dengan:
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive.Arahkan ke Konfigurasi>Tingkat Lanjut>hive-site Tingkat Lanjut>hive.zookeeper.quorum dan catat nilainya. Nilainya mungkin mirip dengan:
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181.Arahkan ke Konfigurasi>Tingkat Lanjut>Umum>hive.metastore.uris dan catat nilainya. Nilainya mungkin mirip dengan:
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083.Arahkan ke Konfigurasi>Tingkat Lanjut>hive-interactive-site Tingkat Lanjut>hive.llap.daemon.service.hosts dan catat nilainya. Nilainya mungkin mirip dengan:
@llap0.
Mengonfigurasi pengaturan klaster Spark
Dari browser web, arahkan ke
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configsdi mana CLUSTERNAME adalah nama klaster Apache Spark Anda.Perluas spark2-default Kustom.
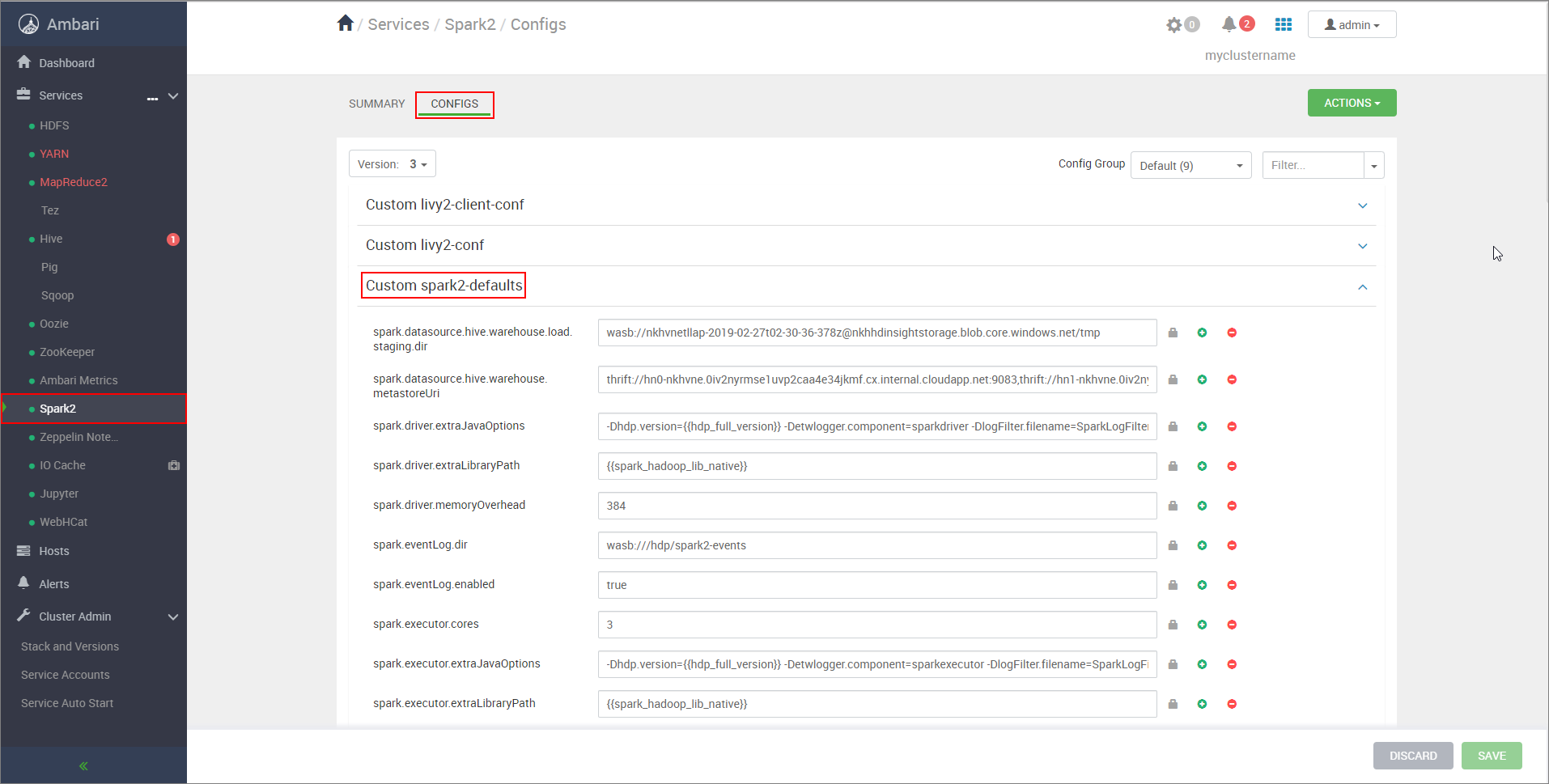
Pilih Tambahkan Properti... untuk menambahkan konfigurasi berikut:
Konfigurasi Nilai spark.datasource.hive.warehouse.load.staging.dirJika Anda menggunakan Akun Penyimpanan ADLS Gen2, gunakan abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp
Jika Anda menggunakan Akun Azure Blob Storage, gunakanwasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp.
Atur ke direktori penahapan yang kompatibel dengan HDFS yang sesuai. Jika Anda memiliki dua kluster yang berbeda, direktori penahapan harus menjadi folder di direktori penahapan akun penyimpanan kluster LLAP sehingga HiveServer2 memiliki akses ke dalamnya. GantiSTORAGE_ACCOUNT_NAMEdengan nama akun penyimpanan yang digunakan oleh klaster, danSTORAGE_CONTAINER_NAMEdengan nama kontainer penyimpanan.spark.sql.hive.hiveserver2.jdbc.urlNilai yang Anda peroleh sebelumnya dari URL JDBC Interaktif HiveServer2 spark.datasource.hive.warehouse.metastoreUriNilai yang Anda peroleh sebelumnya dari hive.metastore.uris. spark.security.credentials.hiveserver2.enabledtrueuntuk mode klaster YARN danfalseuntuk mode klien YARN.spark.hadoop.hive.zookeeper.quorumNilai yang Anda peroleh sebelumnya dari hive.zookeeper.quorum. spark.hadoop.hive.llap.daemon.service.hostsNilai yang Anda peroleh sebelumnya dari hive.llap.daemon.service.hosts. Simpan perubahan dan mulai ulang semua komponen yang terdampak.
Mengonfigurasi klaster HWC for Paket Keamanan Perusahaan (ESP)
Paket Keamanan Perusahaan (ESP) menyediakan kemampuan tingkat perusahaan seperti autentikasi berbasis Active Directory, dukungan multi-pengguna, dan kontrol akses berbasis peran untuk klaster Apache Hadoop di Azure HDInsight. Untuk informasi selengkapnya tentang ESP, lihat Menggunakan Paket Keamanan Perusahaan di HDInsight.
Terlepas dari konfigurasi yang disebutkan di bagian sebelumnya, tambahkan konfigurasi berikut untuk menggunakan HWC pada klaster ESP.
Dari UI web Ambari dari klaster Spark, arahkan ke Spark2>CONFIGS>spark2-defaults Kustom.
Perbarui properti berikut ini.
Konfigurasi Nilai spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>Dari browser web, arahkan ke
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summarydi mana CLUSTERNAME adalah nama klaster Interactive Query Anda. Klik HiveServer2 Interactive. Anda akan melihat Nama Domain yang Sepenuhnya Memenuhi Syarat (FQDN) dari simpul kepala tempat LLAP berjalan seperti yang ditunjukkan pada cuplikan layar. Ganti<llap-headnode>dengan nilai ini.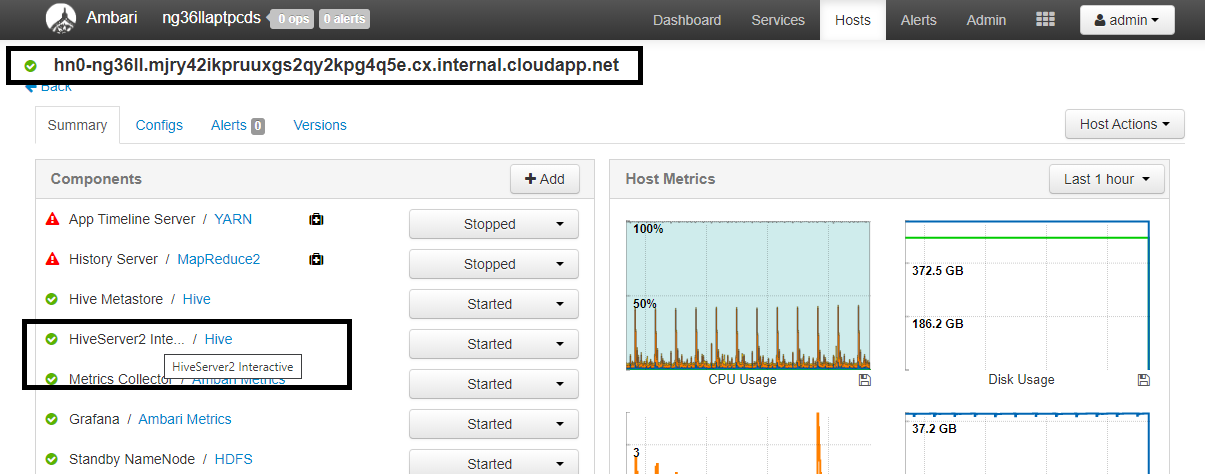
Gunakan perintah ssh untuk terhubung ke klaster Interactive Query Anda. Cari parameter
default_realmdalam file/etc/krb5.conf. Ganti<AAD-DOMAIN>dengan nilai ini sebagai string huruf besar, jika tidak, kredensial tidak akan ditemukan.
Contohnya,
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET.
Simpan perubahan dan mulai ulang komponen sesuai kebutuhan.
Penggunaan Hive Warehouse Connector
Anda dapat memilih di antara beberapa metode berbeda untuk terhubung ke klaster Interactive Query Anda dan menjalankan kueri menggunakan Hive Warehouse Connector. Metode yang didukung mencakup alat berikut:
Di bawah ini adalah beberapa contoh untuk terhubung ke HWC dari Spark.
Spark shell
Ini adalah cara untuk menjalankan Spark secara interaktif melalui versi modifikasi dari shell Scala.
Gunakan perintah ssh untuk terhubung ke klaster Apache Spark Anda. Edit perintah di bawah ini dengan mengganti CLUSTERNAME dengan nama klaster Anda, lalu masukkan perintah:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netDari sesi ssh Anda, jalankan perintah berikut untuk mencatat versi
hive-warehouse-connector-assembly:ls /usr/hdp/current/hive_warehouse_connectorEdit kode di bawah ini dengan versi
hive-warehouse-connector-assemblyyang diidentifikasi di atas. Kemudian jalankan perintah untuk memulai spark shell:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseSetelah Anda memulai shell spark, instans Apache Hive Warehouse Koneksi or dapat dimulai menggunakan perintah berikut:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Spark-submit
Spark-submit adalah utilitas untuk mengirimkan program Spark apa pun (atau pekerjaan) Spark apa pun ke kluster Spark.
Pekerjaan spark-submit akan menyiapkan dan mengonfigurasi Spark dan Apache Hive Warehouse Koneksi or sesuai instruksi kami, menjalankan program yang kami berikan kepadanya, lalu melepaskan sumber daya yang sedang digunakan dengan bersih.
Setelah Anda membuat kode scala/java bersama dengan dependensi ke dalam jar perakitan, gunakan perintah di bawah ini untuk meluncurkan aplikasi Spark. Ganti <VERSION>, dan <APP_JAR_PATH> dengan nilai aktual.
Mode Klien YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarMode Klaster YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
Utilitas ini juga digunakan ketika kita telah menulis seluruh aplikasi dalam pySpark dan dikemas ke dalam .py file (Python), sehingga kita dapat mengirimkan seluruh kode ke kluster Spark untuk dieksekusi.
Untuk aplikasi Python, teruskan file .py di tempat /<APP_JAR_PATH>/myHwcAppProject.jar, dan tambahkan file konfigurasi di bawah ini (Python .zip) ke jalur pencarian dengan --py-files.
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
Menjalankan kueri pada klaster Paket Keamanan Perusahaan (ESP)
Gunakan kinit sebelum memulai spark-shell atau spark-submit. Ganti USERNAME dengan nama akun domain dengan izin untuk mengakses klaster, lalu jalankan perintah berikut:
kinit USERNAME
Mengamankan data pada klaster Spark ESP
Buat tabel
demodengan beberapa data sampel dengan memasukkan perintah berikut ini:create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');Tampilkan konten tabel dengan perintah berikut ini. Sebelum Anda menerapkan kebijakan,
demotabel memperlihatkan kolom lengkap.hive.executeQuery("SELECT * FROM demo").show()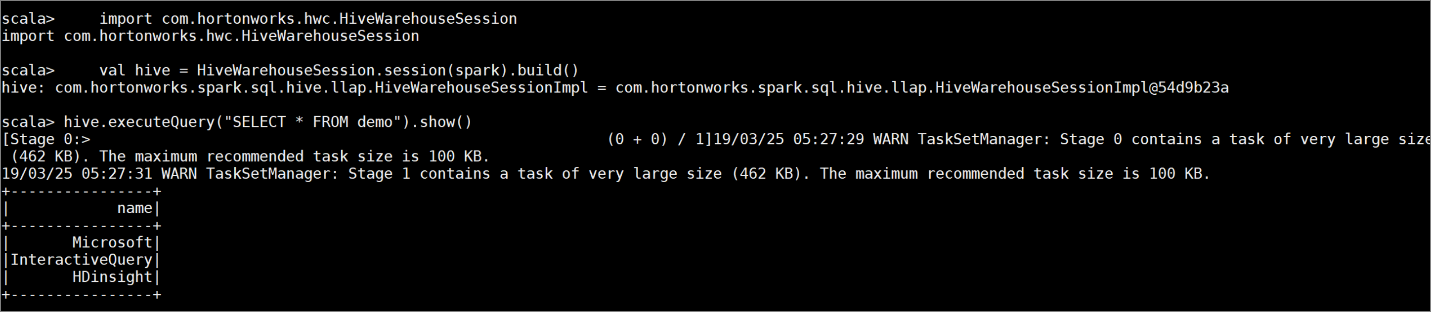
Terapkan kebijakan masking kolom yang hanya menampilkan empat karakter terakhir kolom.
Buka Ranger Admin UI di
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/.Klik pada layanan Apache Hive untuk klaster Anda di bawah Hive.

Klik pada tab Masking lalu Tambahkan Kebijakan Baru

Berikan nama kebijakan yang diinginkan. Pilih database: Default, tabel Hive: demo, kolom Hive: nama, Pengguna: rsadmin2, Tipe Akses: pilih, dan Masker parsial: tampilkan 4 terakhir dari menu Pilih Opsi Masking. Klik Tambahkan.

Tampilkan lagi konten tabel. Setelah menerapkan kebijakan ranger, kita hanya dapat melihat empat karakter terakhir dari kolom.
