Meningkatkan performa beban kerja Apache Spark menggunakan Microsoft Azure HDInsight IO Cache
Catatan
- IO Cache didukung hingga Spark 2.3 dan tidak akan didukung di Spark 2.4 (HDInsight 4.0) dan Spark 3.1.2 (HDInsight 5.0)
IO Cache adalah layanan penembolokan data untuk Microsoft Azure HDInsight yang meningkatkan performa pekerjaan Apache Spark. IO Cache juga berfungsi untuk beban kerja Apache TEZ dan Apache Hive, yang dapat dijalankan pada kluster Apache Spark. IO Cache menggunakan komponen penembolokan sumber terbuka yang disebut RubiX. RubiX adalah tembolok disk lokal yang digunakan dengan mesin analitik big data yang mengakses data dari sistem penyimpanan cloud. RubiX dianggap unik di antara sistem penembolokan karena menggunakan Solid-State Drive (SSD) daripada mencadangkan memori operasi untuk tujuan penembolokan. Layanan IO Cache meluncurkan dan mengelola Server Metadata RubiX pada setiap simpul pekerja kluster. Ia juga mengonfigurasikan semua layanan kluster untuk penggunaan transparan tembolok RubiX.
Sebagian besar SSD menyediakan bandwidth lebih dari 1 GByte per detik. Bandwidth ini, yang dilengkapi dengan tembolok file dalam memori sistem operasi, menyediakan bandwidth yang cukup untuk memuat mesin pemrosesan komputasi big data, seperti Apache Spark. Memori pengoperasian dibiarkan tersedia bagi Apache Spark untuk memproses tugas yang sangat bergantung pada memori, seperti kocokan. Penggunaan eksklusif memori pengoperasian memungkinkan Apache Spark untuk mencapai penggunaan sumber daya yang optimal.
Catatan
IO Cache saat ini menggunakan RubiX sebagai komponen penembolokan, tetapi ini bisa saja berubah dalam versi layanan yang akan datang. Silakan menggunakan antarmuka IO Cache dan jangan bergantung secara langsung pada implementasi RubiX. IO Cache hanya didukung dengan Azure BLOB Storage untuk saat ini.
Manfaat Microsoft Azure HDInsight IO Cache
Penggunaan IO Cache memberikan peningkatan performa untuk pekerjaan yang membaca data dari Azure Blob Storage.
Anda tidak perlu membuat perubahan apa pun pada pekerjaan Spark Anda untuk melihat peningkatan performa saat menggunakan IO Cache. Ketika IO Cache dinonaktifkan, kode Spark ini akan membaca data dari jarak jauh dari Azure Blob Storage: spark.read.load('wasbs:///myfolder/data.parquet').count(). Ketika IO Cache diaktifkan, baris kode yang sama menyebabkan penembolokan pembacaaan melalui IO Cache. Pada pembacaan berikut, data dibaca secara lokal dari SSD. simpul pekerja pada kluster HDInsight dilengkapi dengan drive SSD khusus yang terpasang secara lokal. HDInsight IO Cache menggunakan SSD lokal ini untuk penembolokan, yang memberikan tingkat latensi terendah dan memaksimalkan bandwidth.
Memulai
Microsoft Azure HDInsight IO Cache dinonaktifkan secara default dalam pratinjau. IO Cache tersedia pada kluster Microsoft Azure HDInsight 3.6+ Spark, yang menjalankan Apache Spark 2.3. Untuk mengaktifkan IO Cache pada HDInsight 4.0, lakukan langkah-langkah berikut:
Dari browser web, arahkan ke
https://CLUSTERNAME.azurehdinsight.net, di manaCLUSTERNAMEmerupakan nama kluster Anda.Pilih layanan IO Cache di sebelah kiri.
Pilih Tindakan (Tindakan Layanan dalam HDI 3.6) dan Aktifkan.
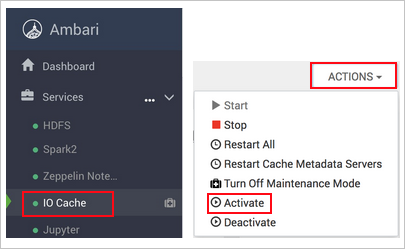
Pastikan untuk memulai ulang semua layanan yang terdampak pada kluster.
Catatan
Meskipun bilah kemajuan terlihat diaktifkan, IO Cache sebenarnya tidak diaktifkan sampai Anda memulai ulang layanan lain yang terdampak.
Pemecahan Masalah
Anda mungkin mendapatkan eror ruang disk pada disk yang menjalankan pekerjaan Spark setelah mengaktifkan IO Cache. Eror ini terjadi karena Spark juga menggunakan penyimpanan disk lokal untuk menyimpan data selama operasi pengocokan. Spark bisa kehabisan ruang SSD setelah IO Cache diaktifkan dan ruang untuk penyimpanan Spark berkurang. Jumlah ruang yang digunakan oleh IO Cache secara default mencapai hingga setengah dari total ruang SSD. Penggunaan ruang disk untuk IO Cache dapat dikonfigurasi di Ambari. Jika Anda mendapatkan eror ruang disk, kurangi jumlah ruang SSD yang digunakan untuk IO Cache dan mulai ulang layanan. Untuk mengubah ruang yang diatur untuk IO Cache, lakukan langkah-langkah berikut:
Di Apache Ambari, pilih layanan HDFS di sebelah kiri.
Pilih tab Konfigurasi dan Tingkat Lanjut.
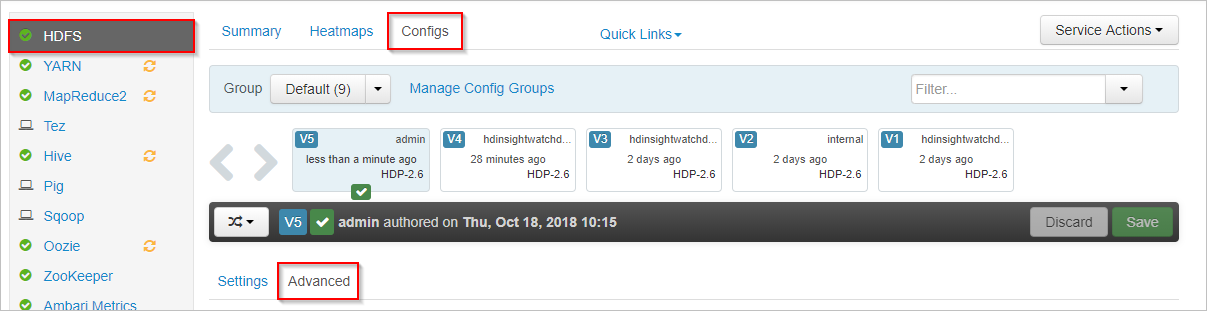
Gulir ke bawah dan perluas area Situs inti kustom.
Temukan properti hadoop.cache.data.fullness.percentage.
Ubah nilai dalam kotak.
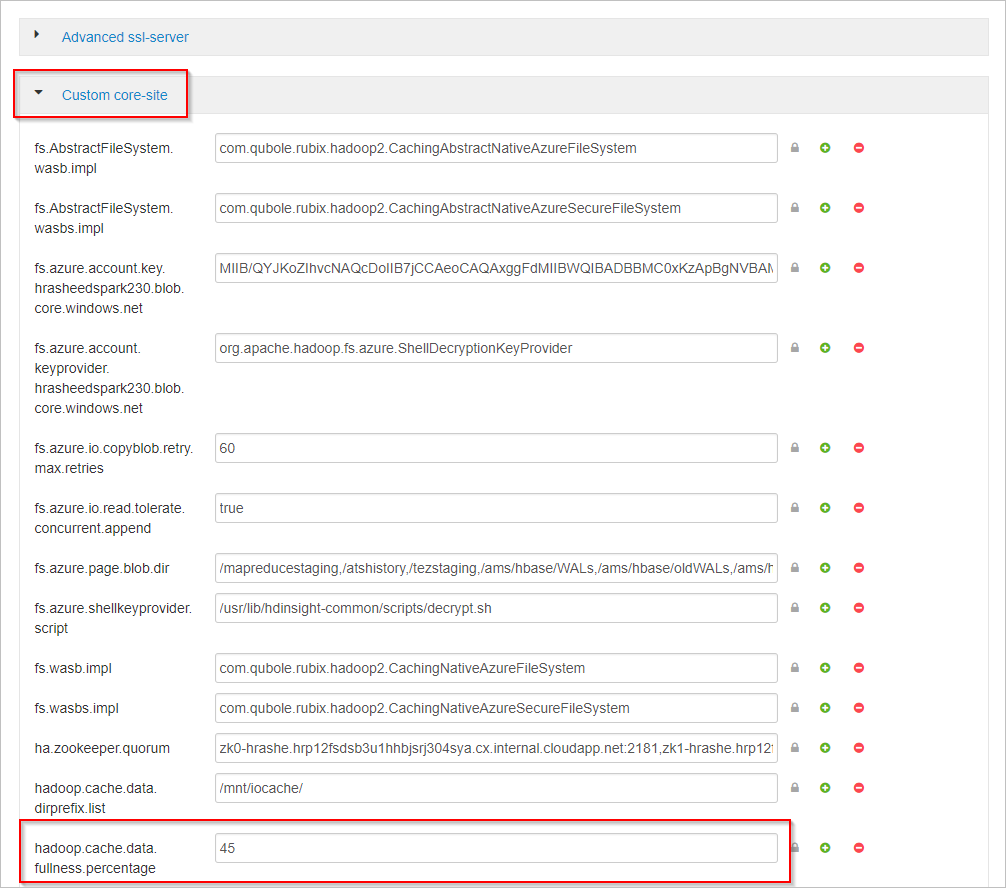
Pilih Simpan di kanan atas.
Pilih Mulai Ulang>Mulai Ulang Semua Yang Terdampak.

Pilih Konfirmasi Mulai Ulang Semua.
Jika tidak berhasil, nonaktifkan IO Cache.
Langkah berikutnya
Baca selengkapnya tentang IO Cache, termasuk tolok ukur performa dalam posting blog ini: Pekerjaan Apache Spark mendapatkan hingga 9x kecepatan dengan HDInsight IO Cache