Mengonfigurasikan pengaturan Apache Spark
Klaster HDInsight Spark menyertakan instalasi pustaka Apache Spark. Setiap klaster HDInsight menyertakan parameter konfigurasi default untuk semua layanan yang diinstal, termasuk Spark. Aspek utama dalam pengelolaan klaster HDInsight Apache Hadoop adalah memantau beban kerja, termasuk Spark Jobs. Untuk menjalankan pekerjaan Spark dengan maksimal, pertimbangkan konfigurasi klaster fisik saat menentukan konfigurasi logika klaster.
Klaster HDInsight Apache Spark default mencakup node berikut: tiga node Apache ZooKeeper, dua node head, dan satu atau lebih node pekerja:
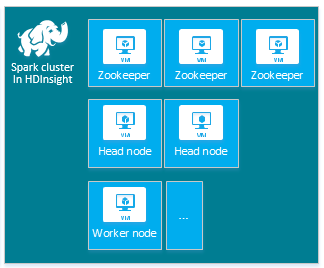
Jumlah VM dan ukuran VM untuk node di klaster HDInsight Anda dapat memengaruhi konfigurasi Spark Anda. Nilai konfigurasi HDInsight non-default seringkali memerlukan nilai konfigurasi Spark non-default. Ketika membuat klaster HDInsight Spark, Anda akan melihat ukuran VM yang disarankan untuk setiap komponen. Saat ini ukuran VM Linux yang dioptimalkan memori untuk Azure adalah D12 v2 atau lebih besar.
Versi Apache Spark
Gunakan versi Spark terbaik untuk klaster Anda. Layanan HDInsight mencakup beberapa versi Spark dan HDInsight itu sendiri. Setiap versi Spark menyertakan set pengaturan klaster default.
Ketika Anda membuat klaster baru, ada beberapa versi Spark yang bisa dipilih. Untuk daftar lengkap, lihat Komponen dan Versi HDInsight.
Catatan
Versi default Apache Spark di layanan HDInsight dapat berubah tanpa pemberitahuan. Jika Anda memiliki ketergantungan versi, Microsoft menyarankan agar Anda menentukan versi tertentu tersebut saat membuat klaster menggunakan .NET SDK, Azure PowerShell, dan Azure Classic CLI.
Apache Spark memiliki tiga lokasi konfigurasi sistem:
- Properti Spark mengontrol sebagian besar parameter aplikasi dan dapat diatur dengan menggunakan objek
SparkConf, atau melalui properti sistem Java. - Variabel lingkungan dapat digunakan untuk mengatur pengaturan per-mesin, seperti alamat IP, melalui skrip
conf/spark-env.shpada setiap node. - Pengelogan dapat dikonfigurasi melalui
log4j.properties.
Ketika Anda memilih versi Spark tertentu, klaster Anda menyertakan pengaturan konfigurasi default. Anda dapat mengubah nilai konfigurasi Spark default dengan menggunakan file konfigurasi Spark kustom. Contoh ditunjukkan di bawah ini.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
Contoh yang ditunjukkan di atas menimpa beberapa nilai default untuk lima parameter konfigurasi Spark. Nilai-nilai ini adalah kodek kompresi, Apache Hadoop MapReduce memisahkan ukuran minimum dan ukuran blok parket. Juga, partisi Spark SQL dan nilai default ukuran file terbuka. Perubahan konfigurasi ini dipilih karena data dan pekerjaan terkait (dalam contoh ini, data genomik) memiliki karakteristik khusus. Karakteristik ini akan bekerja lebih baik menggunakan pengaturan konfigurasi kustom ini.
Melihat pengaturan konfigurasi klaster
Pastikan pengaturan konfigurasi klaster HDInsight saat ini sebelum Anda melakukan pengoptimalan kinerja pada klaster. Luncurkan HDInsight Dashboard dari portal Microsoft Azure dengan mengeklik tautan Dasbor pada panel klaster Spark. Masuklah dengan nama pengguna dan sandi administrator klaster.
Apache Ambari Web UI muncul, dengan dasbor metrik penggunaan sumber daya klaster utama. Ambari Dashboard menampilkan konfigurasi Apache Spark, dan layanan terinstal lainnya kepada Anda. Dashboard menyertakan tab Riwayat Konfigurasi, tempat Anda melihat informasi tentang layanan yang terpasang, termasuk Spark.
Untuk melihat nilai konfigurasi untuk Apache Spark, pilih Riwayat Konfigurasi, lalu pilih Spark2. Pilih tab Konfigurasi, lalu pilih tautan Spark (atau Spark2, tergantung dari versi Anda) di daftar layanan. Anda melihat daftar nilai konfigurasi untuk klaster Anda:
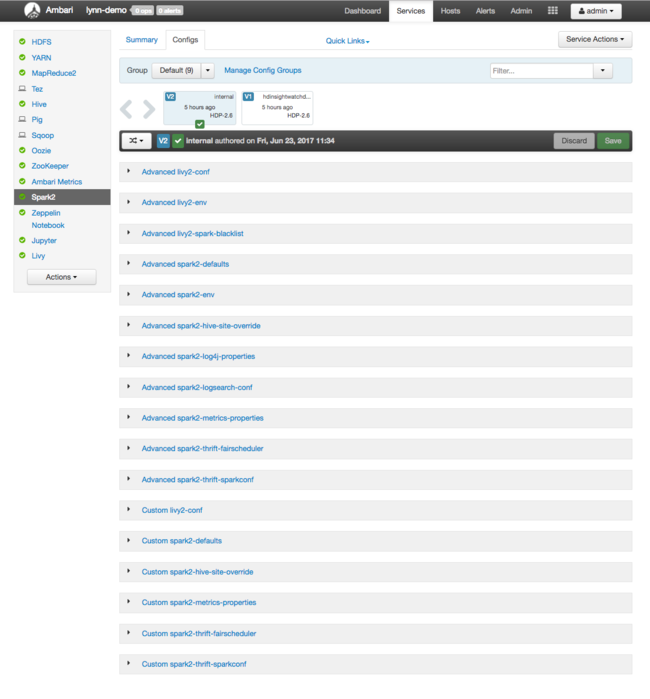
Untuk melihat dan mengubah nilai konfigurasi Spark individual, pilih tautan apa pun dengan "spark" di judul. Konfigurasi untuk Spark mencakup nilai konfigurasi kustom dan tingkat lanjut dalam kategori berikut:
- Spark2-defaults Kustom
- Spark2-metrics-properties Kustom
- Spark2-defaults Tingkat Lanjut
- Spark2-env Tingkat Lanjut
- Spark2-hive-site-override Tingkat Lanjut
Jika Anda membuat set nilai konfigurasi non-default, riwayat pembaruan Anda akan terlihat. Riwayat konfigurasi ini dapat membantu untuk melihat konfigurasi non-default mana yang memiliki kinerja optimal.
Catatan
Untuk melihat, tetapi bukan untuk mengubah, pengaturan konfigurasi klaster Spark umum, pilih tab Lingkungan pada antarmuka UI Spark Job tingkat atas.
Mengonfigurasi eksekutor Spark
Diagram berikut menampilkan objek Spark utama: program driver dan Spark Context terkaitnya, serta manajer klaster dan node pekerja n-nya. Setiap node pekerja menyertakan Executor, tembolok, dan instans tugas n.
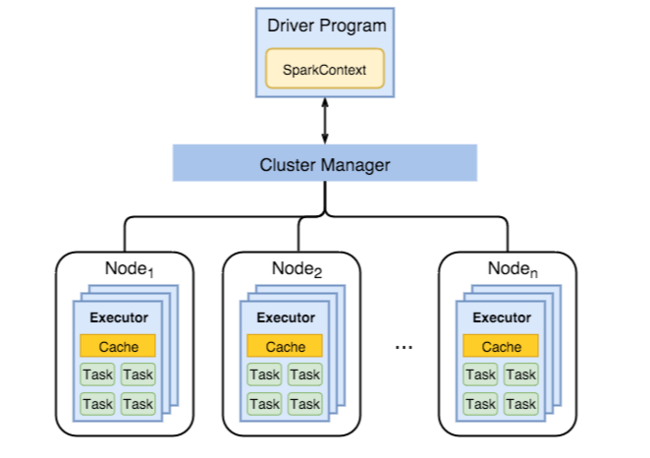
Pekerjaan Spark menggunakan sumber daya pekerja, terutama memori, jadi penyesuaian nilai konfigurasi Spark untuk Executor node pekerja merupakan hal yang umum.
Tiga parameter utama yang sering disesuaikan untuk menyetel konfigurasi Spark untuk meningkatkan persyaratan aplikasi adalah spark.executor.instances, spark.executor.cores, dan spark.executor.memory. Executor adalah proses yang diluncurkan untuk aplikasi Spark. Executor berjalan pada node pekerja dan bertanggung jawab atas tugas untuk aplikasi. Jumlah node pekerja dan ukuran node pekerja menentukan jumlah eksekutor, dan ukuran eksekutor. Nilai-nilai ini disimpan di spark-defaults.conf pada node head klaster. Anda dapat mengedit nilai-nilai ini dalam klaster yang sedang berjalan dengan memilih Spark-defaults kustom di UI web Ambari. Setelah membuat perubahan, Anda diminta oleh UI untuk Mulai ulang semua layanan yang terdampak.
Catatan
Ketiga parameter konfigurasi ini dapat dikonfigurasi pada tingkat klaster (untuk semua aplikasi yang berjalan pada klaster) dan juga ditentukan untuk setiap aplikasi individu.
Sumber informasi lain tentang sumber daya yang digunakan oleh Spark Executor adalah UI Spark Application. Di UI, Executors menampilkan tampilan Ringkasan dan Rincian konfigurasi dan sumber daya yang digunakan. Tentukan apakah akan mengubah nilai eksekutor untuk seluruh klaster, atau set eksekusi pekerjaan tertentu.
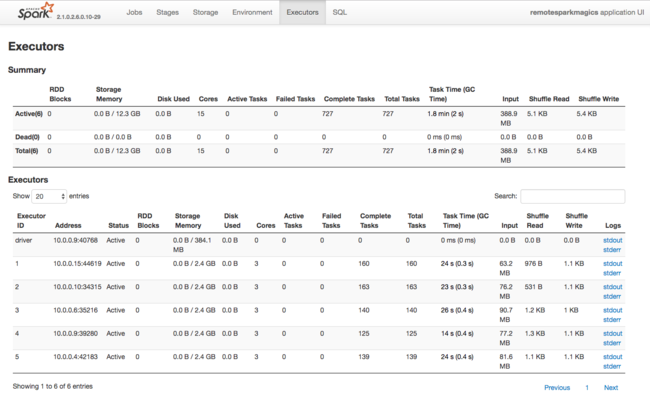
Atau Anda dapat menggunakan Ambari REST API untuk memverifikasi pengaturan konfigurasi klaster HDInsight dan Spark secara terprogram. Informasi lebih lanjut tersedia di Referensi Apache Ambari API pada GitHub.
Bergantung pada beban kerja Spark, Anda dapat menentukan bahwa konfigurasi Spark non-default menyediakan eksekusi pekerjaan Spark yang lebih dioptimalkan. Lakukan pengujian tolok ukur dengan beban kerja sampel untuk memvalidasi konfigurasi kluster non-default. Beberapa parameter umum yang mungkin Anda pertimbangkan untuk disesuaikan adalah:
| Parameter | Deskripsi |
|---|---|
| --num-executors | Mengatur jumlah eksekutor. |
| --executor-cores | Set jumlah inti untuk setiap eksekutor. Kami menyarankan penggunaan eksekutor berukuran sedang, karena proses lain juga mengonsumsi sebagian memori yang tersedia. |
| --executor-memory | Mengontrol ukuran memori (ukuran heap) dari setiap eksekutor pada YARN Apache Hadoop, dan Anda harus menyisakan sebagian memori untuk overhead eksekusi. |
Berikut adalah contoh dua node pekerja dengan nilai konfigurasi yang berbeda:

Daftar berikut menunjukkan parameter memori eksekutor Spark utama.
| Parameter | Deskripsi |
|---|---|
| spark.executor.memory | Menentukan jumlah total memori yang tersedia untuk eksekutor. |
| spark.storage.memoryFraction | (default ~60%) menentukan jumlah memori yang tersedia untuk menyimpan RDD yang dipertahankan. |
| spark.shuffle.memoryFraction | (default ~20%) menentukan jumlah memori yang dicadangkan untuk kocokan. |
| spark.storage.unrollFraction dan spark.storage.safetyFraction | (total ~30% dari total memori) - nilai-nilai ini digunakan secara internal oleh Spark dan tidak boleh diubah. |
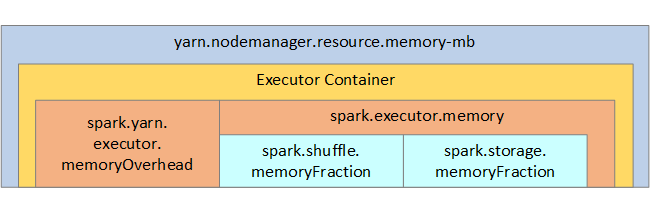
YARN mengontrol jumlah maksimum memori yang digunakan oleh kontainer pada setiap node Spark. Diagram berikut menampilkan hubungan per-node antara objek konfigurasi YARN dan objek Spark.
Mengubah parameter untuk aplikasi yang berjalan di Jupyter Notebook
Klaster Spark di HDInsight menyertakan sejumlah komponen secara default. Masing-masing komponen ini mencakup nilai konfigurasi default, yang dapat ditimpa sesuai kebutuhan.
| Komponen | Deskripsi |
|---|---|
| Spark Core | Spark Core, Spark SQL, Spark streaming API, GraphX, dan Apache Spark MLlib. |
| Anaconda | Pengelola paket python. |
| Apache Livy | Apache Spark REST API digunakan untuk mengirimkan pekerjaan jarak jauh ke klaster HDInsight Spark. |
| Jupyter Notebooks dan Apache Zeppelin Notebooks | UI berbasis browser interaktif untuk berinteraksi dengan klaster Spark Anda. |
| Driver ODBC | Menghubungkan klaster Spark di HDInsight ke alat kecerdasan bisnis (BI) seperti Microsoft Power BI dan Tableau. |
Untuk aplikasi yang berjalan di Jupyter Notebook, gunakan perintah %%configure untuk membuat perubahan konfigurasi dari dalam notebook itu sendiri. Perubahan konfigurasi ini akan diterapkan ke pekerjaan Spark yang dijalankan dari instans notebook Anda. Buat perubahan tersebut di awal aplikasi, sebelum Anda menjalankan sel kode pertama Anda. Konfigurasi yang diubah diterapkan ke sesi Livy saat dibuat.
Catatan
Untuk mengubah konfigurasi pada tahap selanjutnya dalam aplikasi, gunakan parameter -f (paksa). Akan tetapi, semua kemajuan dalam aplikasi akan hilang.
Kode di bawah ini menunjukkan cara mengubah konfigurasi untuk aplikasi yang berjalan di Jupyter Notebook.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Kesimpulan
Pantau pengaturan konfigurasi inti untuk memastikan pekerjaan Spark Anda berjalan dengan cara yang dapat diprediksi dan berfungsi baik. Pengaturan ini membantu menentukan konfigurasi klaster Spark terbaik untuk beban kerja tertentu Anda. Anda juga perlu memantau eksekusi dari eksekusi pekerjaan Spark yang sudah berjalan lama dan/atau yang menghabiskan sumber daya. Tantangan paling umum berpusat di sekitar tekanan memori dari konfigurasi yang tidak tepat, seperti eksekutor berukuran salah. Juga operasi dan tugas jangka panjang, yang mengakibatkan operasi Cartesian.