Optimasi penyimpanan data untuk Apache Spark
Artikel ini membahas cara mengoptimalkan manajemen memori kluster Apache Spark Anda untuk performa terbaik di Microsoft Azure HDInsight.
Gambaran Umum
Spark beroperasi dengan menempatkan data dalam memori. Jadi mengelola sumber daya memori adalah aspek kunci dari mengoptimalkan eksekusi pekerjaan Spark. Ada beberapa teknik yang dapat Anda terapkan untuk menggunakan memori kluster Anda secara efisien.
- Pilih partisi data yang lebih kecil dan akun untuk ukuran, jenis, dan distribusi data dalam strategi partisi Anda.
- Pertimbangkan
Kryo data serializationyang lebih baru dan lebih efisien daripada serialisasi Java default. - Pilihlah penggunaan YARN, karena memisahkan
spark-submitberdasarkan batch. - Pantau dan sesuaikan pengaturan konfigurasi Spark.
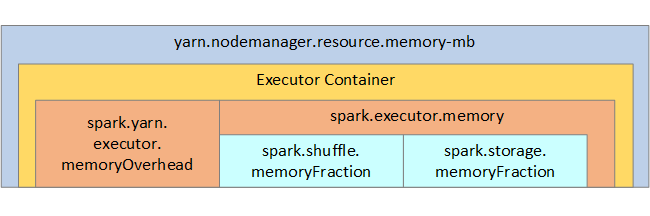
Untuk referensi Anda, struktur memori Spark dan beberapa parameter memori eksekutor utama ditampilkan pada gambar berikutnya.
Pertimbangan memori Spark
Jika Anda menggunakan APACHE Hadoop YARN, maka YARN mengontrol memori yang digunakan oleh semua kontainer pada setiap simpul Spark. Diagram berikut memperlihatkan objek kunci dan hubungannya.
Untuk mengatasi pesan 'kehabisan memori', cobalah:
- Tinjau Pengacakan Manajemen DAG. Kurangi dengan reduksi sisi peta, data sumber pra-partisi (atau bucketize), maksimalkan acak tunggal, dan kurangi jumlah data yang dikirim.
- Pilihlah
ReduceByKeydengan batas memori tetap hinggaGroupByKeyyang menyediakan agregasi, windowing, dan fungsi lainnya tetapi memiliki batas memori tidak terbatas ann. - Pilihlah
TreeReduce, yang melakukan lebih banyak pekerjaan pada eksekutor atau partisi, daripadaReduce, yang melakukan semua pekerjaan pada driver. - Gunakan DataFrames daripada objek RDD tingkat bawah.
- Buat ComplexTypes yang merangkum tindakan, seperti "Top N", berbagai agregasi, atau operasi windowing.
Untuk langkah-langkah pemecahan masalah tambahan, lihat Pengecualian OutOfMemoryError untuk Apache Spark di Microsoft Azure HDInsight.