Komponen Model Evaluasi
Artikel ini menjelaskan komponen dalam perancang Azure Machine Learning.
Gunakan komponen ini untuk mengukur akurasi model terlatih. Anda memberikan himpunan data yang berisi skor yang dihasilkan dari model, dan komponen Model Evaluasi menghitung kumpulan metrik evaluasi standar industri.
Metrik yang ditampilkan Model Evaluasi bergantung pada jenis model yang sedang Anda evaluasi:
- Model Klasifikasi
- Model Regresi
- Model Pengklusteran
Tip
Jika Anda baru dalam evaluasi model, kami merekomendasikan seri video oleh Dr. Stephen Elston, sebagai bagian dari kursus pembelajaran mesin dari EdX.
Cara menggunakan Model Evaluasi
Hubungkan output Himpunan data yang dicetak dari Model Skor atau output himpunan data Hasil dari Tetapkan Data ke Kluster ke port input kiri Model Evaluasi.
Catatan
Jika menggunakan komponen seperti "Pilih Kolom di Himpunan Data" untuk memilih bagian dari himpunan data input, pastikan kolom label Aktual (digunakan dalam pelatihan), kolom 'Probabilitas Skor' dan kolom 'Label Skor' ada untuk menghitung metrik seperti AUC, Akurasi untuk klasifikasi biner/deteksi anomali. Kolom label aktual, kolom 'Label Skor' ada untuk menghitung metrik klasifikasi/regresi multi-kelas. Kolom 'Tugas', kolom 'DistancesToClusterCenter no.X' (X adalah indeks centroid, mulai dari 0, ..., Jumlah centroid-1) ada untuk menghitung metrik untuk pengklusteran.
Penting
- Untuk mengevaluasi hasil, himpunan data output harus berisi nama kolom skor tertentu, yang memenuhi persyaratan komponen Model Evaluasi.
- Kolom
Labelsakan dianggap sebagai label aktual. - Untuk tugas regresi, himpunan data yang akan dievaluasi harus memiliki satu kolom bernama
Regression Scored Labels, yang mewakili label yang diberi skor. - Untuk tugas klasifikasi biner, himpunan data yang akan dievaluasi harus memiliki dua kolom, bernama
Binary Class Scored LabelsdanBinary Class Scored Probabilities, yang masing-masing mewakili label yang diberi skor dan probabilitas. - Untuk tugas multi klasifikasi, himpunan data yang akan dievaluasi harus memiliki satu kolom bernama
Multi Class Scored Labels, yang mewakili label yang diberi skor. Jika output dari komponen upstream tidak memiliki kolom ini, Anda perlu mengubah sesuai dengan persyaratan di atas.
[Opsional] Hubungkan output Himpunan data yang diberi skor dari Model Skor atau output himpunan data Hasil dari Tetapkan Data ke Kluster untuk model kedua ke port input kananModel Evaluasi. Anda dapat dengan mudah membandingkan hasil dari dua model berbeda pada data yang sama. Kedua algoritma input harus memiliki jenis algoritma yang sama. Atau, Anda dapat membandingkan skor dari dua eksekusi yang berbeda melalui data yang sama dengan parameter yang berbeda.
Catatan
Jenis algoritma mengacu pada 'Klasifikasi Dua Kelas', 'Klasifikasi Multi-kelas', 'Regresi', 'Pengklusteran' di bagian 'Algoritma Pembelajaran Mesin'.
Kirimkan alur untuk membuat skor evaluasi.
Hasil
Setelah Anda menjalankan Model Evaluasi, pilih komponen untuk membuka panel navigasi Model Evaluasi di sebelah kanan. Kemudian, pilih tab Output + Log, dan pada tab tersebut bagian Output Data memiliki beberapa ikon. Ikon Visualisasi memiliki ikon grafik batang, dan merupakan cara pertama untuk melihat hasilnya.
Untuk klasifikasi biner, setelah Anda mengklik Ikon visualisasi, Anda dapat memvisualisasikan matriks kebingungan biner. Untuk multi-klasifikasi, Anda dapat menemukan file plot matriks kebingungan di bagian tab Output + Log seperti berikut ini:
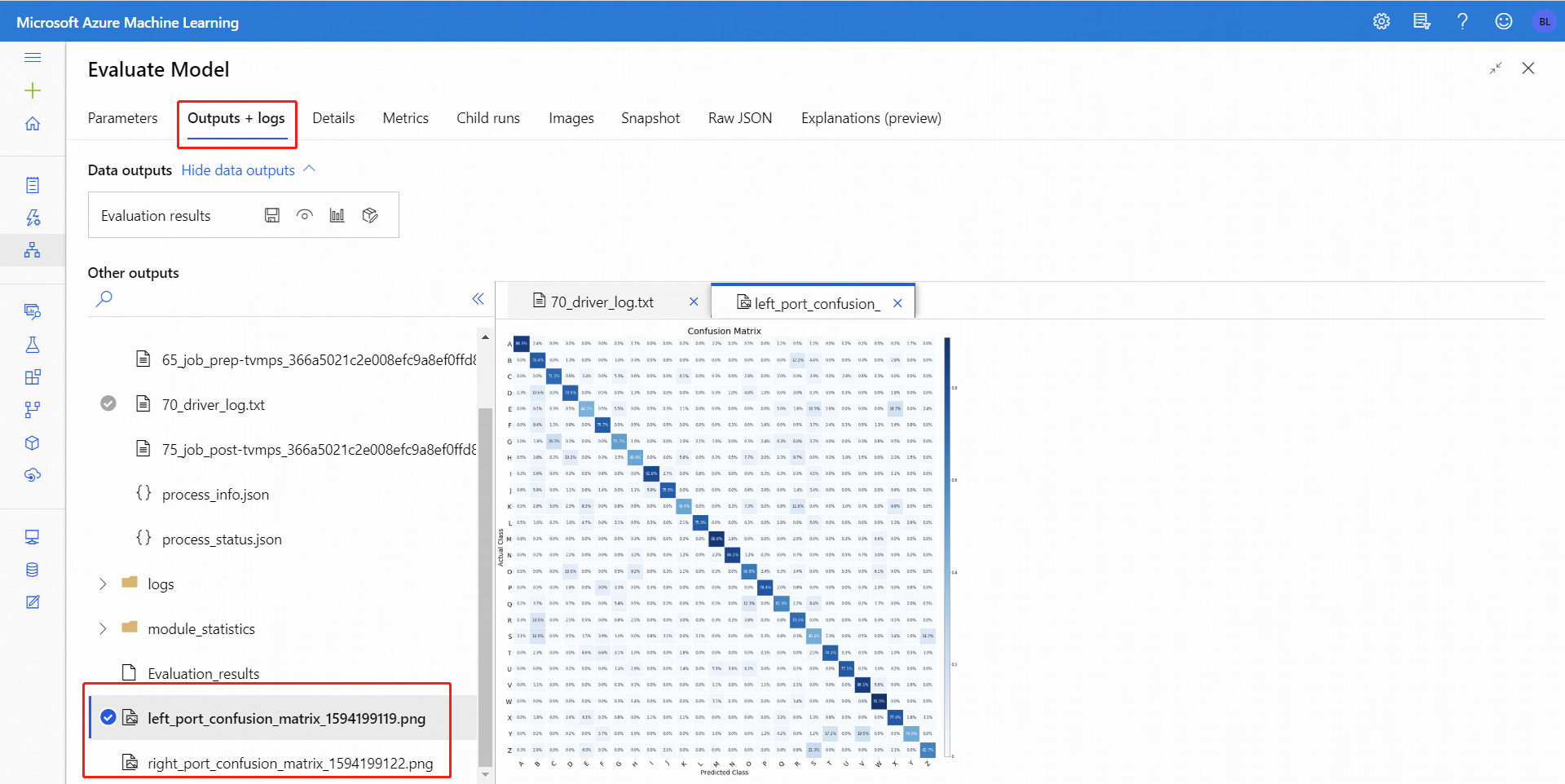
Jika Anda menghubungkan himpunan data ke kedua input Model Evaluasi, hasilnya akan berisi metrik untuk kedua himpunan data, atau kedua model. Model atau data yang dilampirkan ke port kiri disajikan terlebih dahulu dalam laporan, diikuti dengan metrik untuk himpunan data, atau model yang terpasang di port sebelah kanan.
Misalnya, gambar berikut mewakili perbandingan hasil dari dua model pengelompokan yang dibangun pada data yang sama, tetapi dengan parameter yang berbeda.
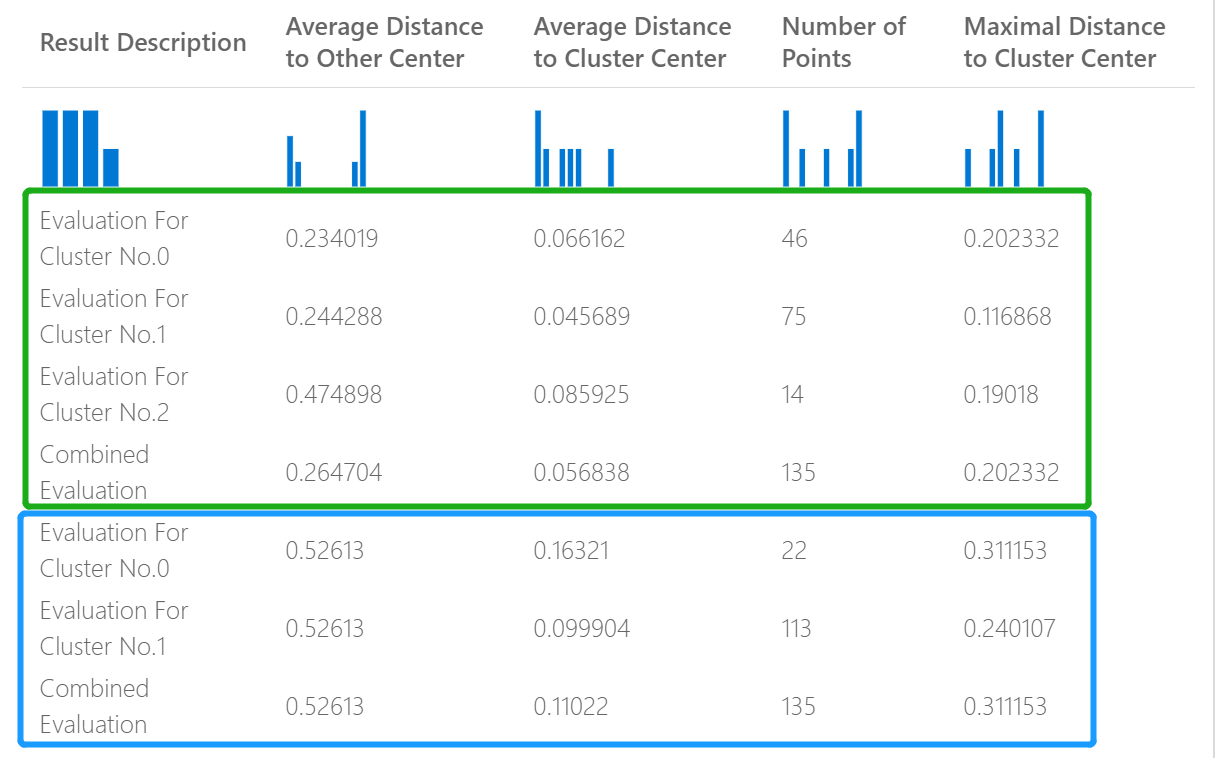
Karena ini adalah model pengklusteran, hasil evaluasinya berbeda dengan jika Anda membandingkan skor dari dua model regresi, atau membandingkan dua model klasifikasi. Namun, presentasi keseluruhannya sama.
Metrik
Bagian ini menjelaskan metrik yang ditampilkan untuk jenis model tertentu yang didukung untuk digunakan dengan Model Evaluasi:
Metrik untuk model klasifikasi
Metrik berikut dilaporkan saat mengevaluasi model klasifikasi biner.
Akurasi mengukur kebaikan model klasifikasi sebagai proporsi hasil sebenarnya terhadap total kasus.
Presisi adalah proporsi hasil yang benar atas semua hasil positif. Presisi = TP/(TP+FP)
Pengenalan adalah sebagian kecil dari jumlah total instans yang relevan yang benar-benar diambil. Pengenalan = TP/(TP+FN)
Skor F1 dihitung sebagai rata-rata tertimbang presisi dan pengenalan antara 0 dan 1, di mana nilai skor F1 yang ideal adalah 1.
AUC mengukur area di bawah kurva yang diplot dengan true positive pada sumbu y dan false positive pada sumbu x. Metrik ini berguna karena menyediakan satu angka yang memungkinkan Anda membandingkan model dari berbagai jenis. AUC adalah klasifikasi ambang invarian. Hal ini mengukur kualitas prediksi model terlepas dari ambang klasifikasi yang dipilih.
Metrik untuk model regresi
Metrik yang ditampilkan untuk model regresi dirancang untuk memperkirakan jumlah kesalahan. Model dianggap cocok dengan data dengan baik jika perbedaan antara nilai yang diamati dan diprediksi kecil. Namun, melihat pola residu (perbedaan antara satu titik prediksi dan nilai aktualnya yang sesuai) dapat memberi tahu Anda banyak tentang potensi bias dalam model.
Metrik berikut dilaporkan untuk mengevaluasi model regresi linier. Model re gression lainnya seperti Regresi Kuantil Hutan Cepat mungkin memiliki metrik yang berbeda.
Mean absolute error (MAE) mengukur seberapa dekat prediksi dengan hasil aktual; dengan demikian, skor yang lebih rendah lebih baik.
Root mean squared error (RMSE) membuat nilai tunggal yang meringkas kesalahan dalam model. Dengan mengkuadratkan selisihnya, metrik mengabaikan perbedaan antara prediksi yang berlebihan dan prediksi yang kurang.
Relative absolute error (RAE) adalah perbedaan absolut relatif antara nilai yang diharapkan dan aktual; relatif karena perbedaan rata-rata dibagi dengan rata-rata aritmatika.
Relative squared error (RSE) juga menormalkan kesalahan kuadrat total dari nilai yang diprediksi dengan membaginya dengan kesalahan kuadrat total dari nilai aktual.
Koefisien determinasi, sering disebut sebagai R2, mewakili kekuatan prediktif model sebagai nilai antara 0 dan 1. Nol berarti modelnya acak (tidak menjelaskan apa-apa); 1 berarti ada kecocokan yang sempurna. Namun, Anda harus berhati-hati dalam menafsirkan nilai R2, karena nilai yang rendah dapat sepenuhnya normal dan nilai yang tinggi dapat bersifat mencurigakan.
Metrik untuk model pengklusteran
Karena model pengklusteran berbeda secara signifikan dari model klasifikasi dan regresi dalam banyak hal, Model Evaluasi juga menampilkan serangkaian statistik yang berbeda untuk model pengklusteran.
Statistik yang ditampikan untuk model pengklusteran menjelaskan berapa banyak poin data yang ditetapkan ke setiap kluster, jumlah pemisahan antar kluster, dan seberapa ketat poin data yang dikelompokkan dalam setiap kluster.
Statistik untuk model pengklusteran rata-rata di seluruh himpunan data, dengan baris tambahan yang berisi statistik per kluster.
Metrik berikut dilaporkan untuk mengevaluasi model pengklusteran.
Skor di kolom, Jarak Rata-Rata ke Pusat Lainnya, menunjukkan seberapa dekat, rata-rata, setiap titik dalam kluster dengan pusat semua kluster lainnya.
Skor di kolom, Jarak Rata-Rata ke Pusat Cluster, mewakili kedekatan semua titik dalam sebuah kluster dengan pusat kluster tersebut.
Kolom Jumlah Poin menunjukkan berapa banyak titik data yang ditetapkan untuk setiap kluster, beserta dengan jumlah total keseluruhan titik data di kluster mana pun.
Jika jumlah poin data yang ditetapkan ke kluster kurang dari jumlah total poin data yang tersedia, itu berarti bahwa poin data tidak dapat ditetapkan ke kluster.
Skor di kolom, Jarak Maksimal ke Pusat Kluster, mewakili jarak maksimum antara setiap titik dan sentroid kluster titik tersebut.
Jika angka ini tinggi, berarti kluster tersebar luas. Anda harus meninjau statistik ini bersama dengan Jarak Rata-Rata ke Pusat Kluster untuk menentukan penyebaran kluster.
Skor Evaluasi Gabungan di bagian bawah setiap bagian hasil mencantumkan skor rata-rata untuk kluster yang dibuat dalam model tertentu.
Langkah berikutnya
Lihat kumpulan komponen yang tersedia untuk Azure Machine Learning.