Ekstrak Fitur N-Gram dari referensi komponen Teks
Artikel ini menjelaskan komponen dalam perancang Azure Machine Learning. Gunakan komponen Ekstrak Fitur N-Gram dari Teks untuk menampilkan data teks tidak terstruktur.
Konfigurasi Ekstrak Fitur N-Gram dari komponen Teks
Komponen mendukung skenario berikut untuk menggunakan kamus n-gram:
Buat kamus n-gram baru dari kolom teks bebas.
Gunakan sekumpulan fitur teks yang ada untuk menampilkan kolom teks bebas.
Beri skor atau sebarkan model yang menggunakan n-gram.
Membuat kamus n-gram baru
Tambahkan Ekstrak Fitur N-Gram dari komponen Teks ke alur, dan hubungkan himpunan data yang memiliki teks yang ingin Anda proses.
Gunakan kolom Teks untuk memilih kolom jenis untai (karakter) yang berisi teks yang ingin Anda ekstrak. Karena hasilnya banyak kata-kata, Anda hanya dapat memproses satu kolom setiap satu waktu.
Atur Mode Kosakata ke Buat untuk menunjukkan bahwa Anda membuat daftar baru fitur n-gram.
Atur ukuran N-Grams untuk menunjukkan ukuran maksimum n-gram untuk mengekstrak dan menyimpan.
Misalnya, jika Anda memasukkan 3, unigram, bigram, dan trigram akan dibuat.
Fungsi pembobotan menentukan cara membangun vektor fitur dokumen dan cara mengekstrak kosakata dari dokumen.
Bobot Biner: Menetapkan nilai kehadiran biner ke n-gram yang diekstrak. Nilai untuk setiap n-gram adalah 1 ketika ada dalam dokumen, dan sebaliknya 0.
Bobot TF: Menetapkan skor frekuensi istilah (TF) ke n-gram yang diekstrak. Nilai untuk setiap n-gram adalah frekuensi kemunculannya dalam dokumen.
Bobot IDF: Menetapkan skor frekuensi dokumen terbalik (IDF) ke n-gram yang diekstrak. Nilai untuk setiap n-gram adalah log ukuran korpus dibagi dengan frekuensi kejadiannya di seluruh korpus.
IDF = log of corpus_size / document_frequencyBobot TF-IDF: Menetapkan skor frekuensi istilah/frekuensi dokumen terbalik (TF/IDF) ke n-gram yang diekstrak. Nilai untuk setiap n-gram adalah skor TF-nya dikalikan dengan skor IDF-nya.
Atur Panjang kata minimum ke jumlah minimum huruf yang dapat digunakan dalam satu kata dalam n-gram.
Gunakan Panjang kata maksimum ke jumlah maksimum huruf yang dapat digunakan dalam satu kata dalam n-gram.
Secara default, hingga 25 karakter per kata atau token diperbolehkan.
Gunakan Frekuensi absolut dokumen minimum n-gram untuk mengatur kemunculan minimum yang diperlukan agar n-gram dimasukkan dalam kamus n-gram.
Misalnya, jika Anda menggunakan nilai default 5, n-gram apa pun harus muncul setidaknya lima kali dalam korpus untuk dimasukkan dalam kamus n-gram.
Atur Rasio dokumen n-gram maksimum ke rasio maksimum jumlah baris yang berisi n-gram tertentu, di atas jumlah baris dalam keseluruhan korpus.
Misalnya, rasio 1 akan menunjukkan bahwa, bahkan jika n-gram tertentu ada di setiap baris, n-gram dapat ditambahkan ke kamus n-gram. Lebih biasanya, kata yang terjadi di setiap baris akan dianggap sebagai kata tidak penting dan akan dihapus. Untuk memfilter kata tidak penting yang bergantung pada domain, coba kurangi rasio ini.
Penting
Tingkat terjadinya kata-kata tertentu tidak seragam. Bervariasi dari dokumen ke dokumen. Misalnya, jika Anda menganalisis komentar pelanggan tentang produk tertentu, nama produk mungkin frekuensinya sangat tinggi dan dekat dengan kata tidak penting, tetapi menjadi istilah yang signifikan dalam konteks lain.
Pilih opsi Normalkan vektor fitur n-gram untuk menormalkan vektor fitur. Jika opsi ini diaktifkan, setiap vektor fitur n-gram dibagi dengan norma L2-nya.
Kirim alur.
Menggunakan kamus n-gram yang ada
Tambahkan Ekstrak Fitur N-Gram dari komponen Teks ke alur, dan hubungkan himpunan data yang berisi teks yang ingin Anda proses ke port Himpunan data.
Gunakan kolom Teks untuk memilih kolom teks yang berisi teks yang ingin Anda tampilkan. Secara default, komponen memilih semua kolom dengan jenis string. Untuk hasil terbaik, proses satu kolom setiap satu waktu.
Tambahkan himpunan data tersimpan yang berisi kamus n-gram yang dibuat sebelumnya, dan sambungkan ke port kosakata Input. Anda juga dapat menghubungkan output Kosakata hasil dari instans upstream dari Ekstrak Fitur N-Gram dari komponen Teks.
Untuk mode Kosakata, pilih opsi perbarui ReadOnly dari daftar drop-down.
Opsi ReadOnly mewakili korpus input untuk kosakata input. Daripada menghitung frekuensi istilah dari himpunan data teks baru (di input kiri), bobot n-gram dari kosakata input diterapkan apa adanya.
Tip
Gunakan opsi ini saat Anda mencetak pengklasifikasi teks.
Untuk semua opsi lainnya, lihat deskripsi properti di bagian sebelumnya.
Kirim alur.
Membangun alur inferensi yang menggunakan n-gram untuk menyebarkan titik akhir real time
Alur pelatihan yang berisi Ekstrak Fitur N-Gram Dari Teks dan Model Skor untuk membuat prediksi pada himpunan data pengujian, dibangun dalam struktur berikut:
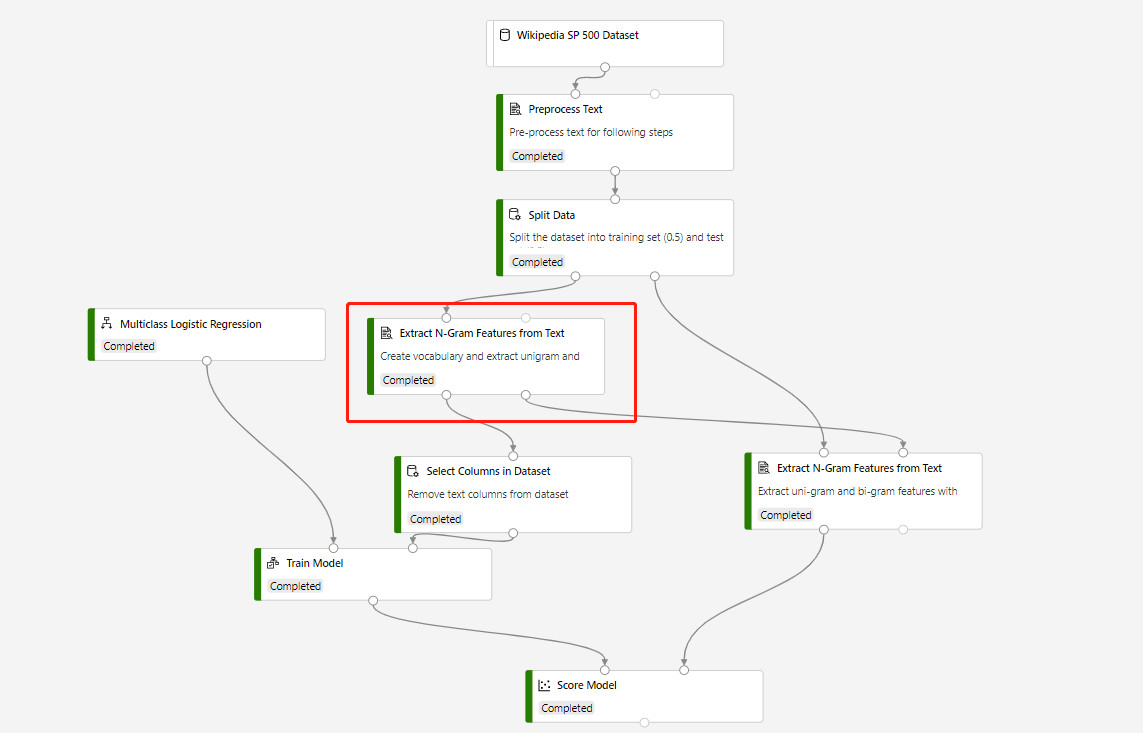
Mode kosakata komponen Ekstrak Fitur N-Grams Dari Teks yang dilingkari adalah Buat, dan Mode kosakata dari komponen yang terhubung ke komponen Model Skor adalah ReadOnly.
Setelah berhasil mengirimkan alur pelatihan di atas, Anda dapat mendaftarkan output dari komponen yang dilingkari sebagai himpunan data.
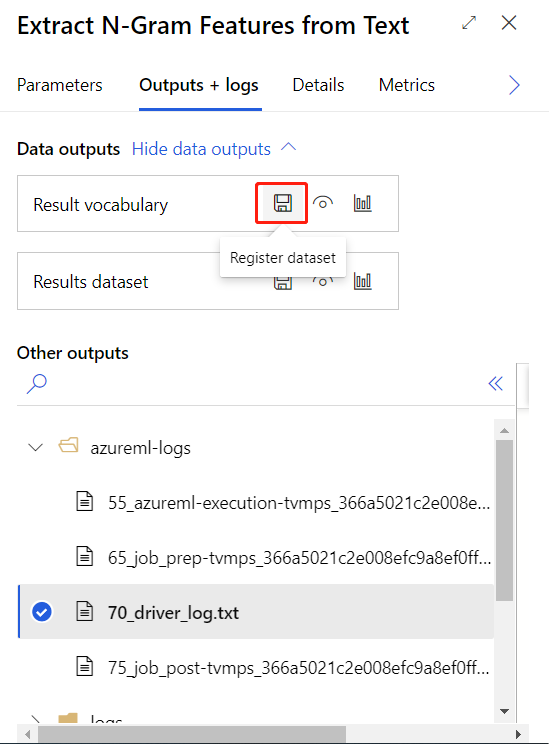
Kemudian Anda dapat membuat alur inferensi real time. Setelah membuat alur inferensi, Anda perlu menyesuaikan alur inferensi Anda secara manual seperti berikut:
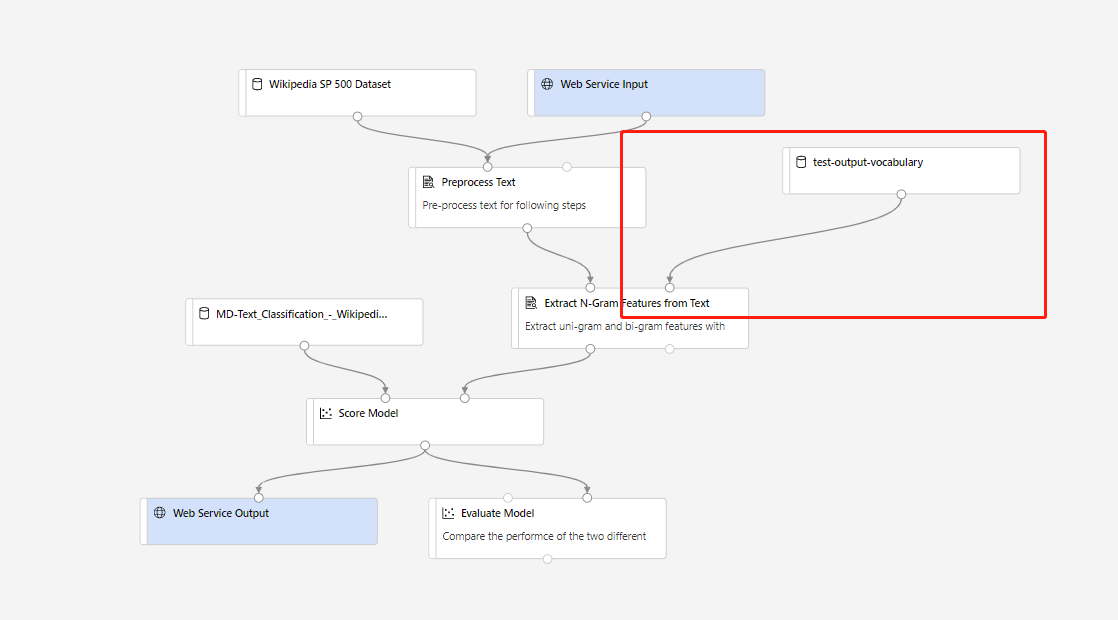
Kemudian kirimkan alur inferensi, dan sebarkan titik akhir real time.
Hasil
Ekstrak Fitur N-Gram dari komponen Teks membuat dua jenis output:
Himpunan data hasil: Output ini adalah ringkasan dari teks dianalisis yang dikombinasikan dengan n-gram yang diekstraksi. Kolom yang tidak Anda pilih di opsi Kolom teks diteruskan ke output. Untuk setiap kolom teks yang Anda analisis, komponen membuat kolom berikut:
- Matriks kemunculan n-gram: Komponen membuat kolom untuk setiap n-gram yang ditemukan dalam korpus total dan menambahkan skor di setiap kolom untuk menunjukkan berat n-gram untuk baris tersebut.
Kosakata hasil: Kosakata berisi kamus n-gram aktual, bersama dengan skor frekuensi istilah yang dihasilkan sebagai bagian dari analisis. Anda dapat menyimpan himpunan data untuk digunakan kembali dengan sekumpulan input yang berbeda, atau untuk pembaruan yang lebih baru. Anda juga dapat menggunakan kembali kosakata untuk pemodelan dan penilaian.
Kosakata hasil
Kosakata berisi kamus n-gram bersama dengan skor frekuensi istilah yang dihasilkan sebagai bagian dari analisis. Skor DF dan IDF dihasilkan terlepas dari opsi lain.
- ID: Pengidentifikasi yang dihasilkan untuk setiap n-gram unik.
- NGram: Sebuah n-gram. Spasi atau pemisah kata lainnya digantikan oleh karakter garis bawah.
- DF: Skor frekuensi istilah untuk n-gram dalam korpus asli.
- IDF: Skor frekuensi dokumen terbalik untuk n-gram dalam korpus asli.
Anda dapat memperbarui himpunan data ini secara manual, tetapi Anda mungkin menemui kesalahan. Contohnya:
- Kesalahan muncul jika komponen menemukan baris duplikat dengan kunci yang sama dalam kosakata input. Pastikan bahwa tidak ada dua baris dalam kosakata yang memiliki kata yang sama.
- Skema input himpunan data kosakata harus sama persis, termasuk nama kolom dan tipe kolom.
- Kolom ID dan kolom DF harus berjenis bilangan bulat.
- Kolom IDF harus berdasarkan jenis float.
Catatan
Jangan hubungkan output data ke komponen Latih Model secara langsung. Anda harus menghapus kolom teks bebas sebelum diumpankan ke Latih Model. Jika tidak, kolom teks bebas akan diperlakukan sebagai fitur kategoris.
Langkah berikutnya
Lihat set komponen yang tersedia untuk Azure Machine Learning.