Teks Praproses
Artikel ini menjelaskan komponen dalam perancang Azure Machine Learning.
Gunakan komponen Teks Preprocess untuk membersihkan dan menyederhanakan teks. Ini mendukung operasi pemrosesan teks umum berikut:
- Penghapusan kata-kata henti
- Menggunakan regex untuk menelusuri dan mengganti string target tertentu
- Lemmatisasi, yang mengubah beberapa kata terkait menjadi bentuk kanonis tunggal
- Normalisasi kasus
- Penghapusan kelas karakter tertentu, seperti angka, karakter khusus, dan urutan karakter berulang seperti "aaaa"
- Identifikasi serta penghapusan email dan URL
Komponen Teks Preprocess saat ini hanya mendukung bahasa Inggris.
Mengonfigurasi Prapemrosesan Teks
Tambahkan komponen Teks Praproses ke alur Anda di Azure Machine Learning. Anda dapat menemukan komponen ini di bawah Analitik Teks.
Sambungkan himpunan data yang memiliki setidaknya satu kolom yang berisi teks.
Pilih bahasa dari menu drop-downBahasa.
Kolom teks yang akan dibersihkan: Pilih kolom yang ingin Anda proses terlebih dahulu.
Hapus kata henti: Pilih opsi ini jika Anda ingin menerapkan daftar kata henti yang sudah ditentukan sebelumnya ke kolom teks.
Daftar kata henti bergantung pada bahasa dan dapat dikustomisasi.
Lemmatisasi: Pilih opsi ini jika Anda ingin kata direpresentasikan dalam bentuk kanonisnya. Opsi ini berguna untuk mengurangi jumlah kemunculan unik token teks serupa.
Proses lemmatisasi sangat bergantung pada bahasa.
Mendeteksi kalimat: Pilih opsi ini jika Anda ingin komponen menyisipkan tanda batas kalimat saat melakukan analisis.
Komponen ini menggunakan serangkaian tiga karakter pipa
|||untuk mewakili pemberhenti kalimat.Lakukan operasi temukan-dan-ganti opsional menggunakan regex. Regex akan diproses terlebih dahulu, sebelum opsi bawaan lainnya.
- Regex kustom: Tentukan teks yang Anda cari.
- String penggantian kustom: Tentukan nilai penggantian tunggal.
Normalkan huruf menjadi huruf kecil: Pilih opsi ini jika Anda ingin mengubah karakter huruf besar ASCII ke bentuk huruf kecilnya.
Jika karakter tidak dinormalkan, kata yang sama dalam huruf besar dan huruf kecil dianggap sebagai dua kata yang berbeda.
Anda juga dapat menghapus jenis karakter atau urutan karakter berikut dari teks output yang diproses:
Hapus angka: Pilih opsi ini untuk menghapus semua karakter numerik untuk bahasa yang ditentukan. Nomor identifikasi bergantung pada domain dan bahasa. Jika karakter numerik adalah bagian integral dari kata yang diketahui, angka tersebut mungkin tidak dihapus. Pelajari selengkapnya di Catatan teknis.
Hapus karakter khusus: Gunakan opsi ini untuk menghapus karakter khusus non-alfanumerik.
Hapus karakter duplikat: Pilih opsi ini untuk menghapus karakter tambahan dalam urutan apa pun yang diulang lebih dari dua kali. Misalnya, urutan seperti "aaaaa" akan dikurangi menjadi "aa".
Hapus alamat email: Pilih opsi ini untuk menghapus urutan format apa pun
<string>@<string>.Hapus URL: Pilih opsi untuk menghapus urutan apa pun yang menyertakan awalan URL berikut:
http,https,ftp,www
Luaskan penyingkatan kata kerja: Opsi ini hanya berlaku untuk bahasa yang menggunakan penyingkatan kata kerja; saat ini, hanya tersedia dalam bahasa Inggris.
Misalnya, dengan memilih opsi ini, Anda dapat mengganti frasa "tak akan tinggal di sana" dengan"tidak akan tinggal di sana" .
Normalkan garis miring terbalik menjadi garis miring: Pilih opsi ini untuk memetakan semua instans
\\ke/.Pilih token di karakter khusus: Pilih opsi ini jika Anda ingin memisahkan kata pada karakter seperti
&,-, dan sebagainya. Opsi ini juga dapat mengurangi karakter khusus jika berulang lebih dari dua kali.Misalnya, string
MS---WORDdipisahkan menjadi tiga token,MS,-, danWORD.Kirimkan alur.
Catatan teknis
Komponen preprocess-text di Studio(klasik) dan perancang menggunakan model bahasa yang berbeda. Perancang menggunakan beberapa model yang dilatih CNN tugas dari spaCy. Model yang berbeda memberikan tagger kelas kata dan tokenizer yang berbeda, yang mengarah ke hasil yang berbeda.
Berikut adalah beberapa contohnya:
| Konfigurasi | Hasil output |
|---|---|
| Dengan semua opsi dipilih Penjelasan: Untuk kasus seperti '3test' di 'WC-3 3test 4test', perancang menghapus seluruh kata '3test', karena dalam konteks ini, pemberi tag kelas kata menentukan token '3test' ini sebagai angka, dan menurut kelas kata, komponen menghapusnya. |
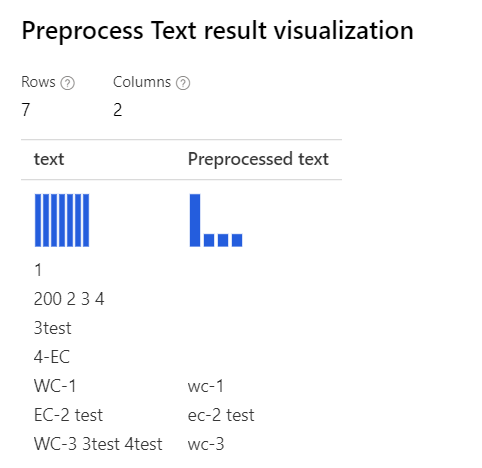
|
Dengan hanya Removing number yang dipilih Penjelasan: Untuk kasus seperti '3test', '4-EC', perancang pentoken tidak memisahkan kasus, dan memperlakukannya sebagai token secara keseluruhan. Jadi, modul tidak akan menghapus angka dalam kata tersebut. |

|
Anda juga dapat menggunakan regex untuk memperoleh hasil yang disesuaikan:
| Konfigurasi | Hasil output |
|---|---|
| Dengan semua opsi dipilih Regex kustom: (\s+)*(-|\d+)(\s+)*String penggantian kustom: \1 \2 \3 |

|
Dengan hanya Removing number dipilih Regex kustom: (\s+)*(-|\d+)(\s+)*String penggantian kustom \1 \2 \3 |
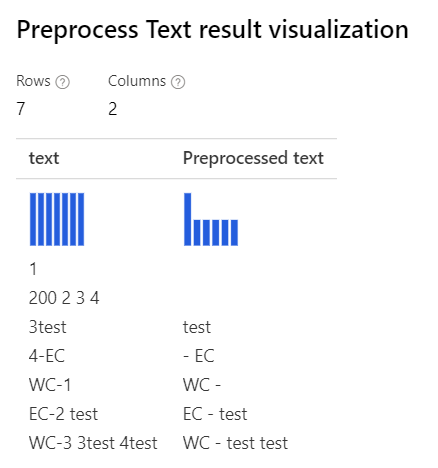
|
Langkah berikutnya
Lihat set komponen yang tersedia untuk Azure Machine Learning.