Mengakses data dari penyimpanan cloud Azure selama pengembangan interaktif
BERLAKU UNTUK: Python SDK azure-ai-ml v2 (saat ini)
Python SDK azure-ai-ml v2 (saat ini)
Proyek pembelajaran mesin biasanya dimulai dengan analisis data eksploratif (EDA), praproses data (pembersihan, rekayasa fitur), dan mencakup pembuatan prototipe model ML untuk memvalidasi hipotesis. Fase proyek prototipe ini bersifat sangat interaktif, dan meminjamkan dirinya untuk pengembangan dalam notebook Jupyter, atau IDE dengan konsol interaktif Python. Dalam artikel ini, Anda akan mempelajari cara:
- Akses data dari Azure Pembelajaran Mesin Datastores URI seolah-olah itu adalah sistem file.
- Mewujudkan data ke dalam Panda menggunakan
mltablepustaka Python. - Mewujudkan aset data Azure Pembelajaran Mesin ke Panda menggunakan
mltablepustaka Python. - Materialisasi data melalui unduhan eksplisit dengan
azcopyutilitas.
Prasyarat
- Ruang kerja Azure Machine Learning. Untuk informasi selengkapnya, lihat Mengelola ruang kerja Azure Pembelajaran Mesin di portal atau dengan Python SDK (v2).
- Azure Pembelajaran Mesin Datastore. Untuk informasi selengkapnya, lihat Membuat penyimpanan data.
Tip
Panduan dalam artikel ini menjelaskan akses data selama pengembangan interaktif. Ini berlaku untuk host apa pun yang dapat menjalankan sesi Python. Ini dapat mencakup komputer lokal Anda, VM cloud, GitHub Codespace, dll. Sebaiknya gunakan instans komputasi Azure Pembelajaran Mesin - stasiun kerja cloud yang dikelola sepenuhnya dan telah dikonfigurasi sebelumnya. Untuk informasi selengkapnya, lihat Membuat instans komputasi Azure Pembelajaran Mesin.
Penting
Pastikan Anda memiliki pustaka terbaru azure-fsspec dan mltable python yang terinstal di lingkungan python Anda:
pip install -U azureml-fsspec mltable
Mengakses data dari URI datastore, seperti sistem file
Datastore Azure Pembelajaran Mesin adalah referensi ke akun penyimpanan Azure yang sudah ada. Manfaat pembuatan dan penggunaan datastore meliputi:
- API umum yang mudah digunakan untuk berinteraksi dengan jenis penyimpanan yang berbeda (Blob/Files/ADLS).
- Penemuan datastore yang berguna dengan mudah dalam operasi tim.
- Dukungan akses berbasis kredensial (misalnya, token SAS) dan berbasis identitas (gunakan akses ID Microsoft Entra atau identitas Manged), untuk mengakses data.
- Untuk akses berbasis kredensial, informasi koneksi diamankan, untuk membatalkan paparan kunci dalam skrip.
- Telusuri data dan salin-tempel URI datastore di Antarmuka Pengguna Studio.
URI Datastore adalah Pengidentifikasi Sumber Daya Seragam, yang merupakan referensi ke lokasi penyimpanan (jalur) di akun penyimpanan Azure Anda. URI datastore memiliki format ini:
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
URI Datastore ini adalah implementasi yang diketahui dari spesifikasi Filesystem (fsspec): antarmuka pythonic terpadu ke sistem file dan penyimpanan byte lokal, jarak jauh, dan tersemat.
Anda dapat memasang azureml-fsspec paket pip dan paket dependensinya azureml-dataprep . Kemudian, Anda dapat menggunakan implementasi Azure Pembelajaran Mesin Datastorefsspec.
Implementasi Azure Pembelajaran Mesin Datastore fsspec secara otomatis menangani passthrough kredensial/identitas yang digunakan azure Pembelajaran Mesin datastore. Anda dapat menghindari paparan kunci akun dalam skrip Anda, dan prosedur masuk tambahan, pada instans komputasi.
Misalnya, Anda dapat langsung menggunakan URI Datastore di Pandas. Contoh ini menunjukkan cara membaca file CSV:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Tip
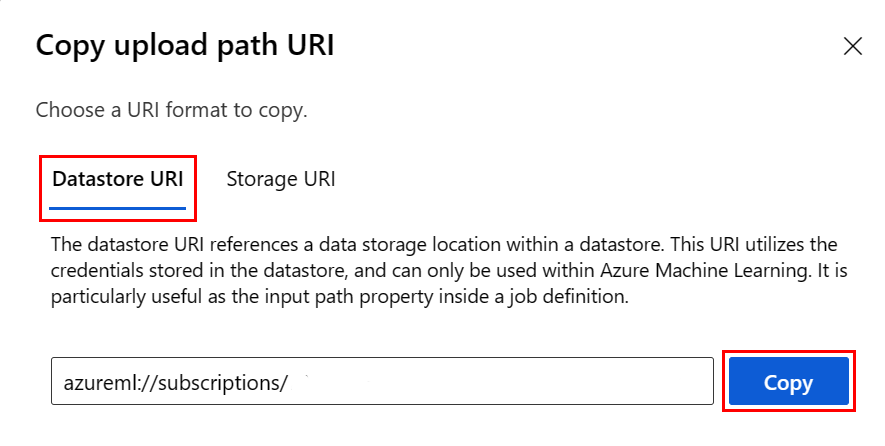
Daripada mengingat format URI datastore, Anda dapat menyalin dan menempelkan URI datastore dari Studio UI dengan langkah-langkah berikut:
- Pilih Data dari menu sebelah kiri, lalu pilih tab Penyimpanan data .
- Pilih nama penyimpanan data Anda, lalu Telusuri.
- Temukan file/folder yang ingin Anda baca ke Pandas, dan pilih elipsis (...) di sampingnya. Pilih Salin URI dari menu. Anda dapat memilih URI Datastore untuk disalin ke buku catatan/skrip Anda.
Anda juga dapat membuat instans sistem file Azure Pembelajaran Mesin, untuk menangani perintah seperti sistem file - misalnya ls, , globexists. open
- Metode ini
ls()mencantumkan file dalam direktori tertentu. Anda dapat menggunakan ls(), ls(.), ls (<<folder_level_1>/<folder_level_2>) untuk mencantumkan file. Kami mendukung '.' dan '..', di jalur relatif. - Metode ini
glob()mendukung '*' dan '**' globbing. - Metode mengembalikan
exists()nilai Boolean yang menunjukkan apakah file tertentu ada di direktori akar saat ini. - Metode ini
open()mengembalikan objek seperti file, yang dapat diteruskan ke pustaka lain yang mengharapkan untuk bekerja dengan file python. Kode Anda juga dapat menggunakan objek ini, seolah-olah itu adalah objek file python normal. Objek seperti file ini menghormati penggunaanwithkonteks, seperti yang ditunjukkan dalam contoh ini:
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore*s*/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
Mengunggah file melalui AzureMachine Pembelajaran FileSystem
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath adalah jalur lokal, dan rpath merupakan jalur jarak jauh.
Jika folder yang Anda tentukan rpath belum ada, kami akan membuat folder untuk Anda.
Kami mendukung tiga mode 'timpa':
- TAMBAHKAN: jika file dengan nama yang sama ada di jalur tujuan, ini menyimpan file asli
- FAIL_ON_FILE_CONFLICT: jika file dengan nama yang sama ada di jalur tujuan, ini akan menimbulkan kesalahan
- MERGE_WITH_OVERWRITE: jika file dengan nama yang sama ada di jalur tujuan, ini menimpa file yang ada dengan file baru
Mengunduh file melalui AzureMachine Pembelajaran FileSystem
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
Contoh
Contoh-contoh ini menunjukkan penggunaan spesifikasi sistem file dalam skenario umum.
Membaca satu file CSV ke Pandas
Anda dapat membaca satu file CSV ke Panda seperti yang ditunjukkan:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Membaca folder file CSV ke Pandas
Metode Pandas read_csv() tidak mendukung pembacaan folder file CSV. Anda harus meng-glob jalur csv, dan menggabungkannya ke bingkai data dengan metode Pandas concat() . Sampel kode berikutnya menunjukkan cara mencapai perangkaian ini dengan sistem file Azure Pembelajaran Mesin:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Membaca file CSV ke Dask
Contoh ini menunjukkan cara membaca file CSV ke dalam bingkai data Dask:
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Membaca folder file parket ke Pandas
Sebagai bagian dari proses ETL, file Parquet biasanya ditulis ke folder, yang kemudian dapat memancarkan file yang relevan dengan ETL seperti kemajuan, penerapan, dll. Contoh ini menunjukkan file yang dibuat dari proses ETL (file yang dimulai dengan _) yang kemudian menghasilkan file parquet data.
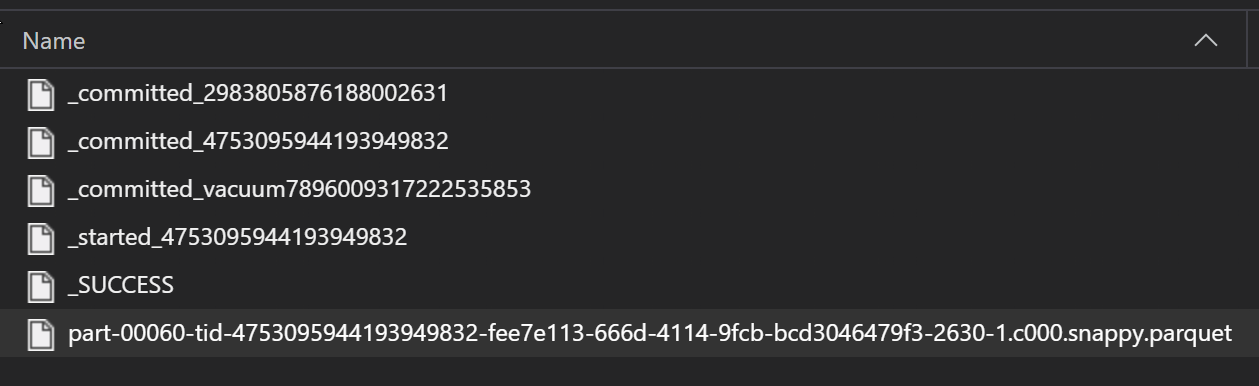
Dalam skenario ini, Anda hanya akan membaca file parket di folder, dan mengabaikan file proses ETL. Sampel kode ini menunjukkan bagaimana pola glob hanya dapat membaca file parket dalam folder:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Mengakses data dari sistem file Azure Databricks Anda (dbfs)
Spesifikasi sistem file (fsspec) memiliki berbagai implementasi yang diketahui, termasuk Sistem File Databricks (dbfs).
Untuk mengakses data dari dbfs Yang Anda butuhkan:
- Nama instans, dalam bentuk
adb-<some-number>.<two digits>.azuredatabricks.net. Anda dapat menemukan nilai ini di URL ruang kerja Azure Databricks Anda. - Token Akses Pribadi (PAT); untuk informasi selengkapnya tentang pembuatan PAT, lihat Autentikasi menggunakan token akses pribadi Azure Databricks
Dengan nilai-nilai ini, Anda harus membuat variabel lingkungan pada instans komputasi Anda untuk token PAT:
export ADB_PAT=<pat_token>
Anda kemudian dapat mengakses data di Panda seperti yang ditunjukkan dalam contoh ini:
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
Membaca gambar dengan pillow
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
Contoh himpunan data kustom PyTorch
Dalam contoh ini, Anda membuat himpunan data kustom PyTorch untuk memproses gambar. Kami berasumsi bahwa file anotasi (dalam format CSV) ada, dengan struktur keseluruhan ini:
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
Subfolder menyimpan gambar-gambar ini, sesuai dengan labelnya:
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
Kelas PyTorch Dataset kustom harus menerapkan tiga fungsi: __init__, , __len__dan __getitem__, seperti yang ditunjukkan di sini:
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
Anda kemudian dapat membuat instans himpunan data seperti yang ditunjukkan di sini:
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
Mewujudkan data ke panda menggunakan mltable pustaka
Pustaka mltable juga dapat membantu mengakses data di penyimpanan cloud. Membaca data ke Pandas dengan mltable memiliki format umum ini:
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
Jalur yang didukung
Pustaka mltable mendukung pembacaan data tabular dari berbagai jenis jalur:
| Lokasi | Contoh |
|---|---|
| Jalur pada komputer lokal Anda | ./home/username/data/my_data |
| Jalur pada server http milik publik | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Jalur pada Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| Datastore Azure Pembelajaran Mesin bentuk panjang | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
Catatan
mltablemelakukan passthrough kredensial pengguna untuk jalur di Azure Storage dan azure Pembelajaran Mesin datastore. Jika Anda tidak memiliki izin untuk mengakses data pada penyimpanan yang mendasar, Anda tidak dapat mengakses data.
File, folder, dan glob
mltable mendukung pembacaan dari:
- file - misalnya:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv - folder - misalnya
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/ - pola glob - misalnya
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv - kombinasi pola file, folder, dan/atau globbing
mltable fleksibilitas memungkinkan materialisasi data, menjadi satu dataframe, dari kombinasi sumber daya penyimpanan lokal dan cloud, dan kombinasi file/folder/glob. Contohnya:
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
Format file yang didukung
mltable mendukung format file berikut:
- Teks Berbatas (misalnya: file CSV):
mltable.from_delimited_files(paths=[path]) - Parquet:
mltable.from_parquet_files(paths=[path]) - Delta:
mltable.from_delta_lake(paths=[path]) - Format baris JSON:
mltable.from_json_lines_files(paths=[path])
Contoh
Membaca file CSV
Perbarui tempat penampung (<>) dalam cuplikan kode ini dengan detail spesifik Anda:
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Membaca file parket dalam folder
Contoh ini menunjukkan cara mltable menggunakan pola glob - seperti kartubebas - untuk memastikan bahwa hanya file parket yang dibaca.
Perbarui tempat penampung (<>) dalam cuplikan kode ini dengan detail spesifik Anda:
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Membaca aset data
Bagian ini memperlihatkan cara mengakses aset data Azure Pembelajaran Mesin Anda di Pandas.
Aset tabel
Jika sebelumnya Anda membuat aset tabel di Azure Pembelajaran Mesin (mltable, atau V1 TabularDataset), Anda dapat memuat aset tabel tersebut ke Pandas dengan kode ini:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
Aset file
Jika Anda mendaftarkan aset file (file CSV, misalnya), Anda dapat membaca aset tersebut ke dalam bingkai data Pandas dengan kode ini:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Aset folder
Jika Anda mendaftarkan aset folder (uri_folder atau V1 FileDataset) - misalnya, folder yang berisi file CSV - Anda dapat membaca aset tersebut ke dalam bingkai data Pandas dengan kode ini:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Catatan tentang membaca dan memproses volume data besar dengan Panda
Tip
Panda tidak dirancang untuk menangani himpunan data besar - Panda hanya dapat memproses data yang dapat masuk ke dalam memori instans komputasi.
Untuk himpunan data besar, sebaiknya gunakan Azure Pembelajaran Mesin Spark terkelola. Ini menyediakan API PySpark Pandas.
Anda mungkin ingin melakukan iterasi dengan cepat pada subset himpunan data besar yang lebih kecil sebelum meningkatkan skala ke pekerjaan asinkron jarak jauh. mltable menyediakan fungsionalitas bawaan untuk mendapatkan sampel data besar menggunakan metode take_random_sample :
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
Anda juga dapat mengambil subset data besar dengan operasi ini:
Mengunduh data menggunakan azcopy utilitas
azcopy Gunakan utilitas untuk mengunduh data ke SSD lokal host Anda (komputer lokal, VM cloud, Azure Pembelajaran Mesin Compute Instance), ke dalam sistem file lokal. azcopy Utilitas, yang telah diinstal sebelumnya pada instans komputasi Azure Pembelajaran Mesin, akan menangani ini. Jika Anda tidak menggunakan instans komputasi Azure Pembelajaran Mesin atau Ilmu Data Virtual Machine (DSVM), Anda mungkin perlu menginstal azcopy. Lihat azcopy untuk informasi selengkapnya.
Perhatian
Kami tidak merekomendasikan unduhan data ke /home/azureuser/cloudfiles/code lokasi pada instans komputasi. Lokasi ini dirancang untuk menyimpan artefak buku catatan dan kode, bukan data. Membaca data dari lokasi ini akan menimbulkan overhead performa yang signifikan saat pelatihan. Sebagai gantinya, kami merekomendasikan penyimpanan data di home/azureuser, yang merupakan SSD lokal dari simpul komputasi.
Buka terminal dan buat direktori baru, misalnya:
mkdir /home/azureuser/data
Masuk ke azcopy menggunakan:
azcopy login
Selanjutnya, Anda dapat menyalin data menggunakan URI penyimpanan
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST