Siapkan AutoML untuk melatih model visi komputer dengan Python (v1)
BERLAKU UNTUK: SDK Python azureml v1
SDK Python azureml v1
Penting
Beberapa perintah CLI Azure dalam artikel ini menggunakan ekstensi azure-cli-ml, atau v1, untuk Azure Machine Learning. Dukungan untuk ekstensi v1 akan berakhir pada 30 September 2025. Anda dapat memasang dan menggunakan ekstensi v1 hingga tanggal tersebut.
Kami menyarankan agar Anda beralih ke ekstensi ml, atau v2 sebelum 30 September 2025. Untuk informasi selengkapnya mengenai ekstensi v2, lihat Ekstensi Azure ML CLI dan Python SDK v2.
Penting
Fitur ini masih dalam pratinjau umum. Versi pratinjau ini disediakan tanpa perjanjian tingkat layanan. Fitur tertentu mungkin tidak didukung atau mungkin memiliki kemampuan terbatas. Untuk mengetahui informasi selengkapnya, lihat Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure.
Pada artikel ini, Anda belajar cara melatih model computer vision pada data gambar dengan ML otomatis di Azure Machine Learning Python SDK.
ML otomatis mendukung pelatihan model untuk tugas computer vision seperti klasifikasi gambar, deteksi objek, dan segmentasi instans. Penulisan model AutoML untuk tugas computer vision saat ini didukung via Azure Machine Learning Python SDK. Eksekusi eksperimen, model, dan output yang dihasilkan dapat diakses dari antarmuka pengguna studio Azure Machine Learning. Pelajari selengkapnya tentang ml otomatis untuk tugas computer vision pada data gambar.
Catatan
ML otomatis untuk tugas computer vision hanya tersedia melalui Azure Machine Learning Python SDK.
Prasyarat
Ruang kerja Azure Machine Learning. Untuk membuat ruang kerja, lihat Membuat sumber daya ruang kerja.
Azure Machine Learning Python SDK yang diinstal. Untuk menginstal SDK Anda dapat baik,
Buat instans komputasi, yang secara otomatis menginstal SDK dan dikonfigurasi sebelumnya untuk alur kerja ML. Untuk informasi selengkapnya, lihat Membuat dan mengelola instans komputasi Azure Machine Learning.
Instal
automlpaket sendiri, yang mencakup instalasi default SDK.
Catatan
Hanya Python 3.7 dan 3.8 yang kompatibel dengan dukungan ML otomatis untuk tugas visi komputer.
Memilih jenis tugas Anda
ML otomatis untuk gambar mendukung jenis tugas berikut:
| Jenis tugas | Sintaks konfigurasi AutoMLImage |
|---|---|
| klasifikasi gambar | ImageTask.IMAGE_CLASSIFICATION |
| multi-label klasifikasi gambar | ImageTask.IMAGE_CLASSIFICATION_MULTILABEL |
| deteksi objek gambar | ImageTask.IMAGE_OBJECT_DETECTION |
| segmentasi instans gambar | ImageTask.IMAGE_INSTANCE_SEGMENTATION |
Jenis tugas ini adalah parameter yang diperlukan dan diteruskan dalam menggunakan parameter task dalam AutoMLImageConfig.
Misalnya:
from azureml.train.automl import AutoMLImageConfig
from azureml.automl.core.shared.constants import ImageTask
automl_image_config = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION)
Data pelatihan dan validasi
Untuk membuat model computer vision, Anda perlu membawa data gambar berlabel sebagai input untuk pelatihan model dalam bentuk TabularDataset Azure Machine Learning. Anda dapat menggunakan TabularDataset yang telah Anda ekspor dari proyek pelabelan data, atau membuat TabularDataset baru dengan data pelatihan berlabel Anda.
Jika data pelatihan Anda dalam format yang berbeda (seperti, pascal VOC atau COCO), Anda dapat menerapkan skrip helper yang disertakan dengan notebook sampel untuk mengonversi data ke JSONL. Pelajari selengkapnya tentang cara menyiapkan data untuk tugas computer vision dengan ML otomatis.
Peringatan
Pembuatan TabularDatasets dari data dalam format JSONL didukung hanya oleh SDK dan CLI untuk kemampuan ini. Membuat himpunan data melalui antarmuka pengguna tidak didukung saat ini. Sampai sekarang, UI tidak dapat mengenali jenis data StreamInfo, yang merupakan jenis data yang digunakan untuk URL gambar dalam format JSONL.
Catatan
Himpunan data pelatihan harus memiliki setidaknya 10 gambar agar dapat mengirimkan eksekusi AutoML.
Sampel skema JSONL
Struktur TabularDataset tergantung pada tugas yang ada. Untuk jenis tugas computer vision, ia terdiri dari bidang berikut:
| Bidang | Deskripsi |
|---|---|
image_url |
Berisi filepath sebagai objek StreamInfo |
image_details |
Informasi metadata gambar terdiri dari tinggi, lebar, dan format. Bidang ini opsional dan karenanya mungkin ada atau mungkin tidak ada. |
label |
Representasi json dari label gambar, berdasarkan jenis tugas. |
Berikut ini adalah file JSONL sampel untuk klasifikasi gambar:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "AmlDatastore://image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Kode berikut ini adalah file JSONL sampel untuk deteksi objek:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "AmlDatastore://image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Mengkonsumsi data
Setelah data Anda dalam format JSONL, Anda dapat membuat TabularDataset dengan kode berikut:
ws = Workspace.from_config()
ds = ws.get_default_datastore()
from azureml.core import Dataset
training_dataset = Dataset.Tabular.from_json_lines_files(
path=ds.path('odFridgeObjects/odFridgeObjects.jsonl'),
set_column_types={'image_url': DataType.to_stream(ds.workspace)})
training_dataset = training_dataset.register(workspace=ws, name=training_dataset_name)
ML otomatis tidak memaksakan batasan pada pelatihan atau validasi ukuran data untuk tugas computer vision. Ukuran himpunan data maksimum hanya dibatasi oleh lapisan penyimpanan di belakang himpunan data (yaitu blob store). Tidak ada jumlah minimum gambar atau label. Namun, kami sarankan untuk memulai dengan minimal 10-15 sampel per label untuk memastikan model output cukup terlatih. Semakin tinggi jumlah total label/kelas, semakin banyak sampel yang Anda butuhkan per label.
Data pelatihan diperlukan dan diteruskan menggunakan parameter training_data. Anda dapat secara opsional menentukan TabularDataset lain sebagai himpunan data validasi yang akan digunakan untuk model Anda dengan parameter validation_data AutoMLImageConfig. Jika tidak ada himpunan data validasi yang ditentukan, 20% data pelatihan Anda akan digunakan untuk validasi secara default, kecuali jika Anda melewati argumen validation_size dengan nilai yang berbeda.
Misalnya:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(training_data=training_dataset)
Komputasi untuk menjalankan eksperimen
Berikan target komputasi untuk ML otomatis untuk melakukan pelatihan model. Model ML otomatis untuk tugas computer vision memerlukan GPU SKU dan mendukung keluarga NC dan ND. Kami merekomendasikan seri NCsv3 (dengan v100 GPU) untuk pelatihan yang lebih cepat. Target komputasi dengan multi-GPU VM SKU memanfaatkan beberapa GPU untuk juga mempercepat pelatihan. Selain itu, ketika Anda mengatur target komputasi dengan beberapa node Anda dapat melakukan pelatihan model yang lebih cepat melalui paralelisme saat menyetel hiperparameter untuk model Anda.
Catatan
Jika Anda menggunakan instans komputasi sebagai target komputasi Anda, pastikan bahwa beberapa pekerjaan AutoML tidak dijalankan secara bersamaan. Selain itu, pastikan bahwa max_concurrent_iterations diatur ke 1 di sumber daya eksperimen Anda.
Target komputasi ini adalah parameter yang diperlukan dan diteruskan menggunakan parameter compute_target pada AutoMLImageConfig. Misalnya:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(compute_target=compute_target)
Mengonfigurasi algoritma model dan hiperparameter
Dengan dukungan untuk tugas-tugas computer vision, Anda dapat mengontrol algoritma model dan membersihkan hiperparameter. Algoritma model dan hiperparameter ini diteruskan sebagai ruang parameter untuk pembersihan.
Algoritma model diperlukan dan diteruskan melalui parameter model_name. Anda dapat menentukan satu model_name atau memilih antara beberapa.
Algoritma model yang didukung
Tabel berikut merangkum model yang didukung untuk setiap tugas computer vision.
| Task | Algoritma model | Sintaks literal stringdefault_model* dilambangkan dengan * |
|---|---|---|
| Klasifikasi gambar (multi-kelas dan multi-label) |
MobileNet: Model ringan untuk aplikasi seluler ResNet: Jaringan residual ResNeSt: Jaringan perhatian terpisah SE-ResNeXt50: Jaringan Squeeze-and-Excitation ViT: Jaringan transformator visi |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (kecil) vitb16r224* (dasar) vitl16r224 (besar) |
| Deteksi objek | YOLOv5: Model deteksi objek satu tahap RCNN ResNet FPN yang lebih cepat: Model deteksi objek dua tahap RetinaNet ResNet FPN: mengatasi ketidakseimbangan kelas dengan Focal Loss Catatan: Lihat model_size hiperparameter untuk ukuran model YOLOv5. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Segmentasi instans | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn maskrcnn_resnet50_fpn |
Selain mengendalikan algoritma model, Anda juga dapat menyetel hiperparameter yang digunakan untuk pelatihan model. Meskipun banyak hiperparameter yang terpapar adalah agnostik model, ada instans di mana hiperparameter spesifik tugas atau spesifik model. Pelajari lebih lanjut hyperparameter yang tersedia untuk instans ini.
Augmentasi data
Secara umum, performa model pembelajaran mendalam sering dapat meningkat dengan lebih banyak data. Augmentasi data adalah teknik praktis untuk memperkuat ukuran data dan varianbilitas himpunan data yang membantu mencegah overfitting dan meningkatkan kemampuan generalisasi model pada data yang tidak diketahui. ML otomatis menerapkan teknik augmentasi data yang berbeda berdasarkan tugas computer vision, sebelum mengumpan gambar input ke model. Saat ini, tidak ada hiperparameter yang terbuka untuk mengontrol augmentasi data.
| Task | Himpunan data terdampak | Teknik augmentasi data yang diterapkan |
|---|---|---|
| Klasifikasi gambar (multi-kelas dan multi-label) | Pelatihan Validasi dan Uji |
Mengubah ukuran dan memangkas secara acak, flip horizontal, jitter warna (kecerahan, kontras, saturasi, dan warna), normalisasi menggunakan rata-rata dan simpangan baku ImageNet yang bijaksana Mengubah ukuran, potong tengah, normalisasi |
| Deteksi objek, segmentasi instans | Pelatihan Validasi dan Uji |
Pemangkasan acak di sekitar kotak pembatas, perluas, balik horizontal, normalisasi, ubah ukuran Normalisasi, pengubahan ukuran |
| Deteksi objek menggunakan yolov5 | Pelatihan Validasi dan Uji |
Mosaik, affine acak (rotasi, terjemahan, skala, geser), flip horizontal Mengubah ukuran letterbox |
Mengonfigurasi pengaturan eksperimen Anda
Sebelum melakukan penyisiran besar untuk mencari model dan hiperparameter yang optimal, kami sarankan mencoba nilai default untuk mendapatkan garis besar pertama. Selanjutnya, Anda dapat menjelajahi beberapa hiperparameter untuk model yang sama sebelum menyapu beberapa model dan parameternya. Dengan cara ini, Anda dapat menggunakan pendekatan yang lebih berulang, karena dengan beberapa model dan beberapa hiperparameter untuk masing-masing, ruang pencarian berkembang secara eksponensial dan Anda memerlukan lebih banyak iterasi untuk menemukan konfigurasi optimal.
Jika Anda ingin menggunakan nilai hiperparameter default untuk algoritma tertentu (misalnya yolov5), Anda dapat menentukan konfigurasi untuk AutoML Image Anda berjalan sebagai berikut:
from azureml.train.automl import AutoMLImageConfig
from azureml.train.hyperdrive import GridParameterSampling, choice
from azureml.automl.core.shared.constants import ImageTask
automl_image_config_yolov5 = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION,
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
hyperparameter_sampling=GridParameterSampling({'model_name': choice('yolov5')}),
iterations=1)
Setelah Anda membangun model garis besar, Anda mungkin ingin mengoptimalkan performa model untuk menyapu algoritma model dan ruang hiperparameter. Anda dapat menggunakan konfigurasi sampel berikut untuk menyapu hiperparameter untuk setiap algoritma, memilih dari berbagai nilai untuk learning_rate, optimizer, lr_scheduler, dll, untuk menghasilkan model dengan metrik utama yang optimal. Jika nilai hiperparameter tidak ditentukan, nilai default digunakan untuk algoritma yang ditentukan.
Metrik utama
Metrik utama yang digunakan untuk optimasi model dan penyetelan hiperparameter tergantung pada jenis tugas. Penggunaan nilai metrik utama lainnya saat ini tidak didukung.
accuracyuntuk IMAGE_CLASSIFICATIONiouuntuk IMAGE_CLASSIFICATION_MULTILABELmean_average_precisionuntuk IMAGE_OBJECT_DETECTIONmean_average_precisionuntuk IMAGE_INSTANCE_SEGMENTATION
Anggaran eksperimen
Anda dapat secara opsional menentukan anggaran waktu maksimum untuk eksperimen AutoML Vision Anda menggunakan experiment_timeout_hours - jumlah waktu dalam beberapa jam sebelum percobaan berakhir. Jika tidak ada yang ditentukan, batas waktu percobaan default adalah tujuh hari (maksimum 60 hari).
Menyapu hiperparameter untuk model Anda
Ketika melatih model computer vision, performa model sangat tergantung pada nilai hiperparameter yang dipilih. Sering kali, Anda mungkin ingin menyetel hiperparameter untuk mendapatkan performa yang optimal. Dengan dukungan untuk tugas computer vision dalam ML otomatis, Anda dapat menyapu hiperparameter untuk menemukan pengaturan optimal untuk model Anda. Fitur ini menerapkan kemampuan penyetelan hyperparameter dalam Azure Machine Learning. Pelajari cara menyetel hiperparameter.
Menentukan ruang pencarian parameter
Anda dapat menentukan algoritma model dan hiperparameter untuk menyapu di ruang parameter.
- Lihat Mengonfigurasi algoritma model dan hyperparameter untuk daftar algoritma model dan hyperparameter yang didukung untuk setiap jenis tugas.
- Lihat Hyperparameter untuk tugas visi komputer untuk setiap jenis tugas visi komputer.
- Lihat detail tentang distribusi yang didukung untuk hiperparameter diskret dan berkelanjutan.
Metode pengambilan sampel untuk sapuan
Saat menyapu hiperparameter, Anda perlu menentukan metode pengambilan sampel yang digunakan untuk menyapu ruang parameter yang ditentukan. Saat ini, metode pengambilan sampel berikut didukung dengan parameter hyperparameter_sampling:
Catatan
Saat ini hanya pengambilan sampel acak dan kisi yang mendukung ruang hiperparameter bersyar.
Kebijakan penghentian dini
Anda dapat secara otomatis mengakhiri eksekusi berperforma buruk dengan kebijakan penghentian dini. Penghentian dini meningkatkan efisiensi komputasi, menghemat sumber daya komputasi yang seharusnya dihabiskan untuk konfigurasi yang kurang menjanjikan. ML otomatis untuk gambar mendukung kebijakan penghentian dini berikut menggunakan parameter early_termination_policy. Jika tidak ada kebijakan penghentian yang ditentukan, semua konfigurasi dijalankan hingga selesai.
Pelajari lebih lanjut tentang cara mengonfigurasi kebijakan penghentian dini untuk sapuan hiperparameter Anda.
Sumber daya untuk sapuan
Anda dapat mengontrol sumber daya yang dihabiskan untuk sapuan hiperparameter Anda dengan menentukan iterations dan max_concurrent_iterations untuk sapuan.
| Parameter | Detail |
|---|---|
iterations |
Parameter yang diperlukan untuk jumlah maksimum konfigurasi untuk menyapu. Harus bilangan bulat antara 1 dan 1000. Saat menjelajahi hanya hiperparameter default untuk algoritma model tertentu, atur parameter ini menjadi 1. |
max_concurrent_iterations |
Jumlah maksimum eksekusi yang dapat berjalan bersamaan. Jika tidak ditentukan, semua eksekusi diluncurkan secara paralel. Jika ditentukan, harus bilangan bulat antara 1 dan 100. CATATAN: Jumlah eksekusi bersamaan dibatasi pada sumber daya yang tersedia dalam target komputasi yang ditentukan. Pastikan bahwa target komputasi memiliki sumber daya yang tersedia untuk konkurensi yang diinginkan. |
Catatan
Untuk sampel konfigurasi sapuan lengkap, silakan lihat tutorial ini.
Argumen
Anda dapat melewati pengaturan atau parameter tetap yang tidak berubah selama sapuan ruang parameter sebagai argumen. Argumen dilewatkan dalam pasangan nama-nilai dan nama harus diawali dengan dua tanda pisah.
from azureml.train.automl import AutoMLImageConfig
arguments = ["--early_stopping", 1, "--evaluation_frequency", 2]
automl_image_config = AutoMLImageConfig(arguments=arguments)
Pelatihan bertahap (opsional)
Setelah pelatihan selesai, Anda memiliki opsi untuk melatih model lebih lanjut dengan memuat titik pemeriksaan model terlatih. Untuk pelatihan bertahap, Anda dapat menggunakan himpunan data yang sama atau yang berbeda.
Ada dua opsi yang tersedia untuk pelatihan bertahap. Anda dapat,
- Meneruskan ID eksekusi sebagai tempat untuk memuat titik pemeriksaan yang Anda inginkan.
- Meneruskan titik pemeriksaan melalui FileDataset.
Meneruskan titik pemeriksaan melalui ID eksekusi
Untuk menemukan ID eksekusi dari model yang diinginkan, Anda dapat menggunakan kode berikut.
# find a run id to get a model checkpoint from
target_checkpoint_run = automl_image_run.get_best_child()
Untuk meneruskan titik pemeriksaan melalui ID eksekusi, Anda perlu menggunakan parameter checkpoint_run_id.
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_run_id= target_checkpoint_run.id,
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Meneruskan titik pemeriksaan melalui FileDataset
Untuk meneruskan titik pemeriksaan melalui FileDataset, Anda perlu menggunakan parameter checkpoint_dataset_id dan checkpoint_filename.
# download the checkpoint from the previous run
model_name = "outputs/model.pt"
model_local = "checkpoints/model_yolo.pt"
target_checkpoint_run.download_file(name=model_name, output_file_path=model_local)
# upload the checkpoint to the blob store
ds.upload(src_dir="checkpoints", target_path='checkpoints')
# create a FileDatset for the checkpoint and register it with your workspace
ds_path = ds.path('checkpoints/model_yolo.pt')
checkpoint_yolo = Dataset.File.from_files(path=ds_path)
checkpoint_yolo = checkpoint_yolo.register(workspace=ws, name='yolo_checkpoint')
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_dataset_id= checkpoint_yolo.id,
checkpoint_filename='model_yolo.pt',
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Mengirimkan eksekusi
Ketika objek AutoMLImageConfig Anda siap, Anda dapat mengirimkan percobaan.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-image-object-detection")
automl_image_run = experiment.submit(automl_image_config)
Output dan metrik evaluasi
Eksekusi pelatihan ML otomatis menghasilkan file model output, metrik evaluasi, artefak log dan penyebaran seperti file penilaian dan file lingkungan yang dapat ditampilkan dari output dan log serta tab metrik eksekusi turunan.
Tip
Periksa cara menavigasi ke hasil pekerjaan dari bagian Menampilkan hasil eksekusi.
Untuk definisi dan contoh bagan performa dan metrik yang disediakan untuk setiap proses, lihat Mengevaluasi hasil eksperimen pembelajaran mesin otomatis
Mendaftarkan dan menggunakan model
Setelah eksekusi selesai, Anda dapat mendaftarkan model yang dibuat dari eksekusi terbaik (konfigurasi yang menghasilkan metrik utama terbaik)
best_child_run = automl_image_run.get_best_child()
model_name = best_child_run.properties['model_name']
model = best_child_run.register_model(model_name = model_name, model_path='outputs/model.pt')
Setelah Anda mendaftarkan model yang ingin Anda gunakan, Anda dapat menyebarkannya sebagai layanan web pada Azure Container Instances (ACI) atau Azure Kubernetes Service (AKS). ACI adalah pilihan tepat untuk menguji penyebaran, sementara AKS lebih cocok untuk penggunaan produksi berskala tinggi.
Contoh ini menyebarkan model sebagai layanan web di AKS. Untuk menerapkan di AKS, pertama-tama buat kluster komputasi AKS atau gunakan kluster AKS yang ada. Anda dapat menggunakan GPU atau CPU VM SKU untuk kluster penyebaran Anda.
from azureml.core.compute import ComputeTarget, AksCompute
from azureml.exceptions import ComputeTargetException
# Choose a name for your cluster
aks_name = "cluster-aks-gpu"
# Check to see if the cluster already exists
try:
aks_target = ComputeTarget(workspace=ws, name=aks_name)
print('Found existing compute target')
except ComputeTargetException:
print('Creating a new compute target...')
# Provision AKS cluster with GPU machine
prov_config = AksCompute.provisioning_configuration(vm_size="STANDARD_NC6",
location="eastus2")
# Create the cluster
aks_target = ComputeTarget.create(workspace=ws,
name=aks_name,
provisioning_configuration=prov_config)
aks_target.wait_for_completion(show_output=True)
Lalu, Anda dapat mentukan konfigurasi inferensi, yang menjelaskan cara menyiapkan layanan web yang berisi model Anda. Anda dapat menggunakan skrip penilaian dan lingkungan dari pelatihan yang berjalan dalam konfigurasi inferensi Anda.
from azureml.core.model import InferenceConfig
best_child_run.download_file('outputs/scoring_file_v_1_0_0.py', output_file_path='score.py')
environment = best_child_run.get_environment()
inference_config = InferenceConfig(entry_script='score.py', environment=environment)
Kemudian Anda dapat menyebarkan model tersebut sebagai layanan web AKS.
# Deploy the model from the best run as an AKS web service
from azureml.core.webservice import AksWebservice
from azureml.core.webservice import Webservice
from azureml.core.model import Model
from azureml.core.environment import Environment
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
cpu_cores=1,
memory_gb=50,
enable_app_insights=True)
aks_service = Model.deploy(ws,
models=[model],
inference_config=inference_config,
deployment_config=aks_config,
deployment_target=aks_target,
name='automl-image-test',
overwrite=True)
aks_service.wait_for_deployment(show_output=True)
print(aks_service.state)
Alternatifnya, Anda dapat menyebarkan model dari antarmuka pengguna studio Azure Machine Learning. Navigasikan ke model yang ingin Anda sebarkan di tab Model eksekusi ML otomatis dan pilih Sebarkan.
Anda dapat mengonfigurasi nama titik akhir penyebaran model dan kluster inferensi untuk digunakan untuk penyebaran model Anda di panel Sebarkan model.
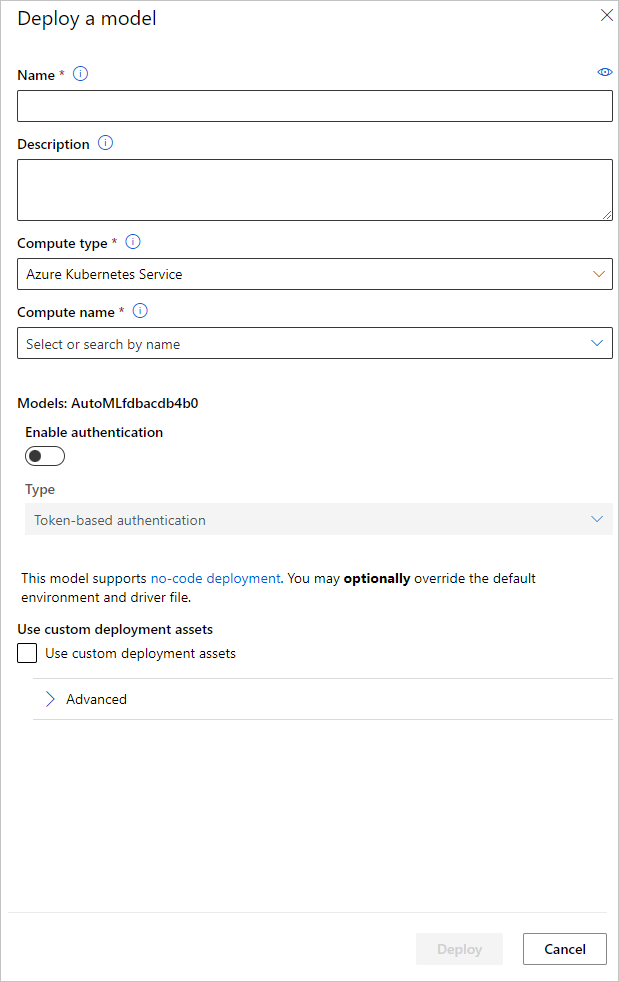
Memperbarui konfigurasi inferensi
Pada langkah sebelumnya, kami mengunduh file penilaian outputs/scoring_file_v_1_0_0.py dari model terbaik ke dalam file score.py lokal dan kami menggunakannya untuk membuat objek InferenceConfig. Skrip ini dapat dimodifikasi untuk mengubah pengaturan inferensi khusus model jika diperlukan setelah diunduh dan sebelum membuat InferenceConfig. Misalnya, ini adalah bagian kode yang menginisialisasi model dalam file penilaian:
...
def init():
...
try:
logger.info("Loading model from path: {}.".format(model_path))
model_settings = {...}
model = load_model(TASK_TYPE, model_path, **model_settings)
logger.info("Loading successful.")
except Exception as e:
logging_utilities.log_traceback(e, logger)
raise
...
Masing-masing tugas (dan beberapa model) memiliki set parameter dalam kamus model_settings. Secara default, kami menggunakan nilai yang sama untuk parameter yang digunakan selama pelatihan dan validasi. Tergantung pada perilaku yang kita butuhkan ketika menggunakan model untuk inferensi, kita dapat mengubah parameter ini. Di bawah ini Anda dapat menemukan daftar parameter untuk setiap jenis dan model tugas.
| Task | Nama Parameter | Default |
|---|---|---|
| Klasifikasi gambar (multi-kelas dan multi-label) | valid_resize_sizevalid_crop_size |
256 224 |
| Deteksi objek | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0,3 0,5 100 |
Deteksi objek menggunakan yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 Sedang 0.1 0,5 |
| Segmentasi instans | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0,3 0,5 100 0,5 100 Salah JPG |
Untuk deskripsi terperinci mengenai hyperparameter khusus tugas, silakan lihat Hyperparameter untuk tugas visi komputer dalam pembelajaran mesin otomatis.
Jika Anda ingin menggunakan pemetakan, dan ingin mengontrol perilaku pemetakan, parameter berikut tersedia: tile_grid_size, tile_overlap_ratio, dan tile_predictions_nms_thresh. Untuk detail lebih lanjut tentang parameter ini, silakan periksa Melatih model deteksi objek kecil menggunakan AutoML.
Contoh buku catatan
Tinjau contoh kode terperinci dan kasus penggunaan di repositori buku catatan GitHub untuk sampel pembelajaran mesin otomatis. Silakan periksa folder dengan awalan 'image-' untuk sampel khusus untuk membangun model visi komputer.