Pemecahan masalah alur pembelajaran mesin
BERLAKU UNTUK: Python SDK azureml v1
Python SDK azureml v1
Dalam artikel ini, Anda mempelajari cara memecahkan masalah saat Anda mendapatkan kesalahan dalam menjalankan alur pembelajaran mesin di Azure Machine Learning SDK dan desainer Azure Machine Learning.
Tips pemecahan masalah
Tabel berikut berisi masalah umum selama pengembangan alur, dengan solusi potensial.
| Masalah | Solusi yang mungkin |
|---|---|
Tidak dapat meneruskan data ke PipelineData direktori |
Pastikan Anda telah membuat direktori dalam skrip yang sesuai dengan tempat alur Anda mengharapkan data output langkah. Dalam kebanyakan kasus, argumen input menentukan direktori output, lalu Anda membuat direktori secara eksplisit. Gunakan os.makedirs(args.output_dir, exist_ok=True) untuk membuat direktori output. Lihat tutorial untuk contoh skrip penskoran yang menunjukkan pola desain ini. |
| Bug dependensi | Jika Anda melihat kesalahan dependensi di alur jarak jauh yang tidak terjadi saat pengujian lokal, konfirmasikan dependensi dan versi lingkungan jarak jauh Anda yang cocok dengan yang ada di lingkungan pengujian Anda. (Lihat Membangun, penembolokan, dan menggunakan kembali lingkungan |
| Kesalahan ambigu dengan target komputasi | Coba hapus dan buat ulang target komputasi. Membuat ulang target komputasi cepat dan dapat menyelesaikan beberapa masalah sementara. |
| Alur tidak menggunakan kembali langkah-langkah berikut | Penggunaan kembali langkah berikut diaktifkan secara default, tetapi pastikan Anda belum menonaktifkannya dalam langkah alur. Jika penggunaan kembali dinonaktifkan, allow_reuse parameter dalam langkah diatur ke False. |
| Pengoperasian ulang alur tidak perlu dilakukan | Untuk memastikan bahwa langkah-langkah berikut hanya akan diulang ketika data atau skrip yang mendasarinya berubah, memisahkan direktori kode sumber Anda untuk setiap langkah. Jika Anda menggunakan direktori sumber yang sama untuk beberapa langkah, Anda mungkin mengalami tayangan ulang yang tidak perlu. Gunakan source_directory parameter pada objek langkah alur untuk mengarahkan ke direktori terisolasi Anda untuk langkah tersebut, dan pastikan Anda tidak menggunakan jalur yang source_directory sama untuk beberapa langkah. |
| Langkah melambat atas epoch pelatihan atau perilaku looping lainnya | Coba alihkan setiap penulisan file, termasuk pembuatan log, dari as_mount() ke as_upload(). Mode pasang menggunakan sistem file virtual jarak jauh serta mengunggah seluruh file setiap kali ditambahkan. |
| Target komputasi membutuhkan waktu lama untuk memulai | Gambar docker untuk target komputasi dimuat dari Azure Container Registry (ACR). Secara default, Azure Machine Learning membuat ACR yang menggunakan tingkat layanan dasar. Mengubah ACR untuk ruang kerja Anda ke tingkat standar atau premium dapat mengurangi waktu yang diperlukan untuk membuat dan memuat gambar. Untuk informasi selengkapnya, lihat Tingkat layanan Azure Container Registry. |
Kesalahan autentikasi
Jika Anda melakukan operasi manajemen pada target komputasi dari pekerjaan jarak jauh, Anda menerima salah satu kesalahan berikut:
{"code":"Unauthorized","statusCode":401,"message":"Unauthorized","details":[{"code":"InvalidOrExpiredToken","message":"The request token was either invalid or expired. Please try again with a valid token."}]}
{"error":{"code":"AuthenticationFailed","message":"Authentication failed."}}
Misalnya, Anda menerima kesalahan jika mencoba membuat atau melampirkan target komputasi dari Alur ML yang dikirimkan untuk eksekusi jarak jauh.
Pemecahan masalah ParallelRunStep
Skrip untuk ParallelRunStepharus berisi dua fungsi:
init(): Gunakan fungsi ini untuk persiapan yang mahal atau umum untuk inferensi nanti. Misalnya, gunakan untuk memuat model ke objek global. Fungsi ini hanya dipanggil sekali pada awal proses.run(mini_batch): Fungsi berjalan untuk setiapmini_batchinstans.mini_batch:ParallelRunStepmemanggil metode eksekusi dan meneruskan daftar atau pandaDataFramesebagai argumen ke metode . Setiap entri dalam mini_batch adalah jalur file jika input adalahFileDatasetatau panda jikaDataFrameinput adalahTabularDataset.response: metode eksekusi alur() harus mengembalikan pandasDataFrameatau array. Misalnya append_row output_action elemen yang dikembalikan ini ditambahkan ke dalam file output umum. Misalnya summary_only, isi elemen diabaikan. Untuk semua tindakan output, setiap elemen output yang dikembalikan menunjukkan satu keberhasilan menjalankan elemen input dalam mini-batch input. Pastikan bahwa data yang cukup disertakan dalam hasil eksekusi alur untuk memetakan input untuk menjalankan hasil output. Output eksekusi ditulis dalam file output dan tidak dijamin berurutan, Anda harus menggunakan beberapa kunci dalam output untuk memetakannya ke input.
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
Jika Anda memiliki file atau folder lain dalam direktori yang sama dengan skrip inferensi, Anda bisa mereferensikannya dengan menemukan direktori kerja saat ini.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
Parameter untuk ParallelRunConfig
ParallelRunConfig adalah konfigurasi utama untuk instans ParallelRunStep dalam alur Azure Machine Learning. Anda menggunakannya untuk membungkus skrip Anda dan mengonfigurasi parameter yang diperlukan, termasuk semua entri berikut:
entry_script: Skrip pengguna sebagai jalur file lokal yang dijalankan secara paralel pada beberapa simpul. Jikasource_directoryada, gunakan jalur relatif. Jika tidak, gunakan jalur apa pun yang dapat diakses di komputer.mini_batch_size: Ukuran batch mini diteruskan ke satu panggilanrun(). (opsional; nilai default adalah10file untukFileDatasetdan1MBuntukTabularDataset.)- Untuk
FileDataset, ini adalah jumlah file dengan nilai minimum1. Anda dapat menggabungkan beberapa file ke dalam satu batch mini. - Untuk
TabularDataset, ini adalah ukuran data. Contoh nilai adalah1024,1024KB,10MB, dan1GB. Nilai yang disarankan adalah1MB. Mini-batch dariTabularDatasettidak akan pernah melewati batas file. Misalnya, jika Anda memiliki file .csv dengan berbagai ukuran, file terkecil adalah 100 KB dan yang terbesar adalah 10 MB. Jika Anda mengaturmini_batch_size = 1MB, maka file dengan ukuran yang lebih kecil dari 1 MB diperlakukan sebagai satu batch mini. File dengan ukuran lebih besar dari 1 MB dibagi menjadi beberapa batch mini.
- Untuk
error_threshold: Jumlah kegagalan rekamanTabularDatasetuntuk dan kegagalan fileFileDatasetuntuk itu harus diabaikan selama pemrosesan. Jika jumlah kesalahan untuk seluruh input berada di atas nilai ini, pekerjaan dibatalkan. Ambang kesalahan adalah untuk seluruh input dan bukan untuk batch mini individual yang dikirim ke metoderun(). Kisarannya adalah[-1, int.max]. Bagian-1tersebut mengindikasikan mengabaikan semua kegagalan selama pemrosesan.output_action: Salah satu nilai berikut menunjukkan bagaimana output diatur:summary_only: Skrip pengguna menyimpan output.ParallelRunStepmenggunakan output hanya untuk perhitungan ambang kesalahan.append_row: Untuk semua input, hanya satu file yang dibuat di folder output untuk menambahkan semua output yang dipisahkan oleh baris.
append_row_file_name: Untuk menyesuaikan nama file output untuk append_row output_action (opsional; nilai default adalahparallel_run_step.txt).source_directory: Jalur ke folder yang berisi semua file untuk dieksekusi pada target komputasi (opsional).compute_target: HanyaAmlComputeyang didukung.node_count: Jumlah node komputasi yang akan digunakan untuk menjalankan skrip pengguna.process_count_per_node: Jumlah proses per node. Praktik terbaik adalah mengatur ke jumlah GPU atau CPU satu node memiliki (opsional; nilai default adalah1).environment: Definisi lingkungan Python. Anda bisa mengonfigurasinya untuk menggunakan lingkungan Python yang ada atau untuk mengatur lingkungan sementara. Definisi ini juga bertanggung jawab untuk mengatur dependensi aplikasi yang diperlukan (opsional).logging_level: Log verbositas. Nilai dalam meningkatkan verbositas adalah:WARNING,INFO, danDEBUG. (opsional; nilai defaultnya adalahINFO)run_invocation_timeout: Waktu pemanggilan metoderun()habis dalam beberapa detik. (opsional; nilai default adalah60)run_max_try: Jumlah percobaan maksimumrun()untuk batch mini.run()gagal jika pengecualian ditetapkan, atau tidak ada yang dikembalikan ketikarun_invocation_timeouttercapai (opsional; nilai default adalah3).
Anda dapat menentukan mini_batch_size, node_count, process_count_per_node, logging_level, run_invocation_timeout, dan run_max_try sebagai PipelineParameter, sehingga ketika Anda mengirim ulang eksekusi alur, Anda dapat menyempurnakan nilai parameter. Dalam contoh ini, Anda menggunakan PipelineParameter untuk mini_batch_size dan Process_count_per_node dan Anda mengubah nilai-nilai ini saat mengirim ulang eksekusi nanti.
Parameter untuk membuat ParallelRunStep
Buat ParallelRunStep menggunakan skrip, konfigurasi lingkungan, dan parameter. Tentukan target komputasi yang sudah Anda lampirkan ke ruang kerja sebagai target eksekusi untuk skrip inferensi Anda. Gunakan ParallelRunStep untuk membuat langkah batch inferensi alur, yang mengambil semua parameter berikut:
name: Nama langkah, dengan batas penamaan berikut: 3-32 karakter, dan regex ^[a-z]([-a-z0-9]*[a-z0-9])?$.parallel_run_config: ObjekParallelRunConfig, seperti yang didefinisikan sebelumnya.inputs: Satu atau beberapa himpunan data Azure Machine Learning yang diketik tunggal yang akan dipartisi untuk pemrosesan paralel.side_inputs: Satu atau lebih data referensi atau himpunan data yang digunakan sebagai input samping tanpa perlu dipartisi.output:OutputFileDatasetConfigObjek yang sesuai dengan direktori output.arguments: Daftar argumen yang diteruskan ke skrip pengguna. Gunakan unknown_args untuk mengambilnya dalam skrip entri Anda (opsional).allow_reuse: Apakah langkah harus menggunakan kembali hasil sebelumnya ketika dijalankan dengan pengaturan/input yang sama. Jika parameter ini adalahFalse, eksekusi baru dihasilkan untuk langkah ini selama eksekusi alur. (opsional; nilai defaultnya adalahTrue.)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
Teknik debugging
Ada tiga teknik utama untuk alur penelusuran kesalahan:
- Men-debug langkah-langkah alur individual pada komputer lokal Anda
- Gunakan pencatatan dan Application Insightsi untuk mengisolasi dan mendiagnosis sumber masalah
- Melampirkan debugger jarak jauh ke alur yang berjalan di Azure
Skrip debug secara lokal
Salah satu kegagalan paling umum dalam alur adalah skrip domain tidak berjalan seperti yang diinginkan, atau berisi kesalahan runtime dalam konteks komputasi jarak jauh yang sulit di-debug.
Alur itu sendiri tidak dapat dijalankan secara lokal. Tetapi menjalankan skrip dalam isolasi pada komputer lokal Anda memungkinkan Anda untuk men-debug lebih cepat karena Anda tidak perlu menunggu proses komputasi dan build lingkungan. Beberapa pekerjaan pengembangan diperlukan untuk melakukan ini:
- Jika data Anda berada di datastore cloud, Anda perlu mengunduh data dan membuatnya tersedia untuk skrip Anda. Menggunakan sampel kecil data Anda adalah cara yang baik untuk mengurangi waktu proses dan dengan cepat mendapatkan umpan balik tentang perilaku skrip
- Jika Anda mencoba mensimulasikan langkah alur perantara, Anda mungkin perlu membangun jenis objek secara manual yang diharapkan skrip tertentu dari langkah sebelumnya
- Anda perlu menentukan lingkungan Anda sendiri, dan mereplikasi dependensi yang ditentukan di lingkungan komputasi jarak jauh Anda
Setelah Anda memiliki penyiapan skrip untuk dijalankan di lingkungan lokal Anda, lebih mudah untuk melakukan tugas penelusuran kesalahan seperti:
- Melampirkan konfigurasi debug kustom
- Menjeda eksekusi dan memeriksa status objek
- Tipe penangkapan atau kesalahan logika yang tidak akan diekspos hingga runtime
Tip
Setelah Anda dapat memverifikasi bahwa skrip Anda berjalan seperti yang diharapkan, langkah berikutnya yang baik adalah menjalankan skrip dalam alur satu langkah sebelum mencoba menjalankannya dalam alur dengan beberapa langkah.
Mengonfigurasi, menulis, dan meninjau log alur
Menguji skrip secara lokal adalah cara yang bagus untuk men-debug fragmen kode utama dan logika kompleks sebelum Anda mulai membangun alur. Pada titik tertentu Anda perlu men-debug skrip selama eksekusi alur aktual itu sendiri, terutama ketika mendiagnosis perilaku yang terjadi selama interaksi antara langkah-langkah alur. Kami merekomendasikan penggunaan print()pernyataan liberal dalam skrip langkah Anda sehingga Anda dapat melihat status objek dan nilai yang diharapkan selama eksekusi jarak jauh, mirip dengan cara Anda men-debug kode JavaScript.
Opsi dan perilaku pembuatan log
Tabel berikut ini menyediakan informasi untuk opsi debug yang berbeda untuk alur. Ini bukan daftar lengkap, karena opsi lain ada selain hanya Azure Machine Learning, Python, dan OpenCensus yang ditampilkan di sini.
| Pustaka | Jenis | Contoh | Tujuan | Sumber |
|---|---|---|---|---|
| Azure Machine Learning SDK | Metrik | run.log(name, val) |
UI Portal Azure Machine Learning | Cara melacak eksperimen azureml.core.Run class |
| Pencetakan/pencatatan Python | Log | print(val)logging.info(message) |
Log driver, desainer Azure Machine Learning | Cara melacak eksperimen Pencatatan Python |
| OpenCensus Python | Log | logger.addHandler(AzureLogHandler())logging.log(message) |
Application Insights - jejak | Debug alur dalam Application Insights OpenCensus Azure Monitor Exporters Cookbook pencatatan Python |
Contoh opsi pembuatan log
import logging
from azureml.core.run import Run
from opencensus.ext.azure.log_exporter import AzureLogHandler
run = Run.get_context()
# Azure Machine Learning Scalar value logging
run.log("scalar_value", 0.95)
# Python print statement
print("I am a python print statement, I will be sent to the driver logs.")
# Initialize Python logger
logger = logging.getLogger(__name__)
logger.setLevel(args.log_level)
# Plain Python logging statements
logger.debug("I am a plain debug statement, I will be sent to the driver logs.")
logger.info("I am a plain info statement, I will be sent to the driver logs.")
handler = AzureLogHandler(connection_string='<connection string>')
logger.addHandler(handler)
# Python logging with OpenCensus AzureLogHandler
logger.warning("I am an OpenCensus warning statement, find me in Application Insights!")
logger.error("I am an OpenCensus error statement with custom dimensions", {'step_id': run.id})
Desainer Azure Machine Learning
Untuk alur yang dibuat di desainer, Anda dapat menemukan file 70_driver_log di halaman penulisan, atau di halaman detail jalankan eksekusi alur.
Aktifkan pencatatan untuk titik akhir real-time
Untuk memecahkan masalah dan men-debug titik akhir real-time dalam desainer, Anda harus mengaktifkan pembuatan log Application Insight menggunakan SDK. Pencatatan memungkinkan Anda memecahkan masalah dan men-debug penyebaran model dan masalah penggunaan. Untuk informasi selengkapnya, lihat Pengelogan untuk model yang diterapkan.
Mendapatkan log dari halaman penulisan
Saat Anda mengirimkan eksekusi alur dan tetap berada di halaman penulisan, Anda dapat menemukan file log yang dihasilkan untuk setiap komponen saat setiap komponen selesai berjalan.
Pilih komponen yang telah selesai berjalan di kanvas pembuatan.
Di panel kanan komponen, buka tab Output + log.
Perluas panel kanan, dan pilih 70_driver_log.txt untuk menampilkan file di browser. Anda juga dapat mengunduh log secara lokal.
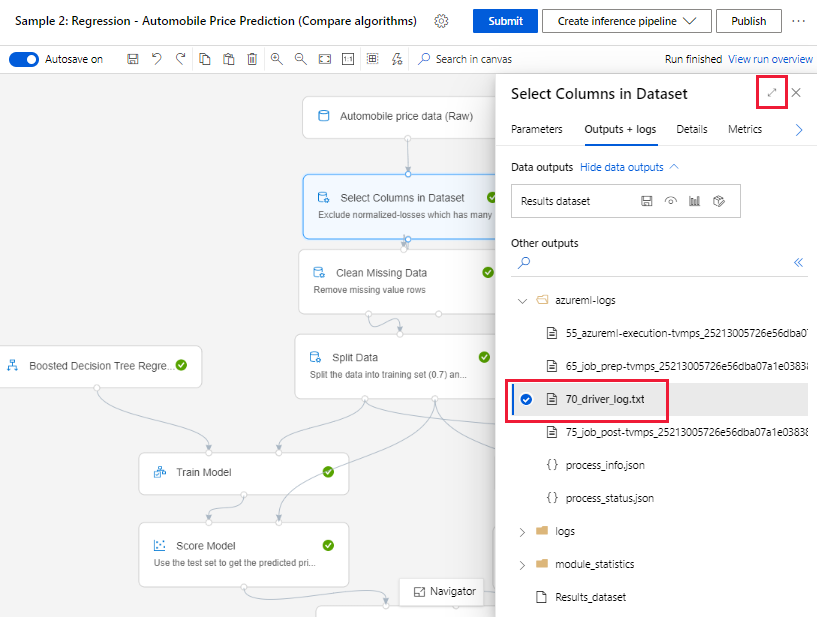
Dapatkan log dari eksekusi alur
Anda juga dapat menemukan file log untuk berjalan di tempat tertentu di halaman detail eksekusi alur, yang dapat ditemukan di bagian Alur atau Eksperimen studio.
Pilih eksekusi alur yang dibuat di desainer.
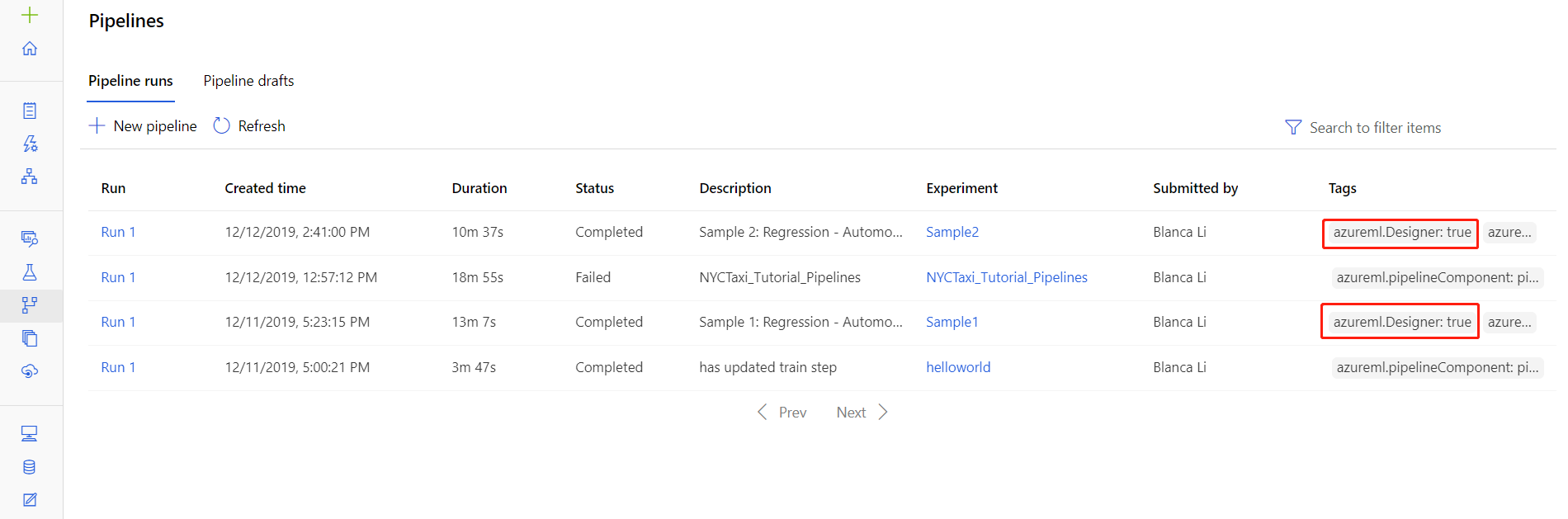
Pilih komponen di panel pratinjau.
Di panel kanan komponen, buka tab Output + log.
Luaskan panel kanan untuk melihat file std_log.txt di browser, atau pilih file untuk mengunduh log secara lokal.
Penting
Untuk memperbarui alur dari halaman detail eksekusi alur, Anda harus mengkloning eksekusi alur yang dijalankan ke draf alur baru. Eksekusi alur adalah rekam jepret dari alur. Ini mirip dengan file log, dan tidak dapat diubah.
Application Insights
Untuk informasi selengkapnya tentang menggunakan pustaka OpenCensus Python dengan cara ini, lihat panduan ini: Debug dan memecahkan masalah saluran pembelajaran mesin di Application Insights
Penelusuran kesalahan interaktif dengan Visual Studio Code
Dalam beberapa kasus, Anda mungkin perlu secara interaktif men-debug kode Python yang digunakan dalam alur ML Anda. Dengan menggunakan Visual Studio Code (VS Code) dan debugpy, Anda dapat melampirkan ke kode saat berjalan di lingkungan pelatihan. Untuk informasi lebih lanjut, kunjungi panduan penelusuran kesalahan interaktif di Visual Studio Code.
HyperdriveStep dan AutoMLStep gagal dengan isolasi jaringan
Setelah Anda menggunakan HyperdriveStep dan AutoMLStep, ketika Anda mencoba mendaftarkan model, Anda mungkin menerima kesalahan.
Anda menggunakan Azure Machine Learning SDK v1.
Ruang kerja Azure Machine Learning Anda dikonfigurasi untuk isolasi jaringan (VNet).
Alur Anda mencoba mendaftarkan model yang dihasilkan oleh langkah sebelumnya. Misalnya, dalam contoh berikut,
inputsparameter adalah saved_model dari HyperdriveStep:register_model_step = PythonScriptStep(script_name='register_model.py', name="register_model_step01", inputs=[saved_model], compute_target=cpu_cluster, arguments=["--saved-model", saved_model], allow_reuse=True, runconfig=rcfg)
Solusi Sementara
Penting
Perilaku ini tidak terjadi saat menggunakan Azure Machine Learning SDK v2.
Untuk mengatasi kesalahan ini, gunakan kelas Jalankan untuk membuat model dari HyperdriveStep atau AutoMLStep. Berikut ini adalah contoh skrip yang mendapatkan model output dari HyperdriveStep:
%%writefile $script_folder/model_download9.py
import argparse
from azureml.core import Run
from azureml.pipeline.core import PipelineRun
from azureml.core.experiment import Experiment
from azureml.train.hyperdrive import HyperDriveRun
from azureml.pipeline.steps import HyperDriveStepRun
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--hd_step_name',
type=str, dest='hd_step_name',
help='The name of the step that runs AutoML training within this pipeline')
args = parser.parse_args()
current_run = Run.get_context()
pipeline_run = PipelineRun(current_run.experiment, current_run.experiment.name)
hd_step_run = HyperDriveStepRun((pipeline_run.find_step_run(args.hd_step_name))[0])
hd_best_run = hd_step_run.get_best_run_by_primary_metric()
print(hd_best_run)
hd_best_run.download_file("outputs/model/saved_model.pb", "saved_model.pb")
print("Successfully downloaded model")
File kemudian dapat digunakan dari PythonScriptStep:
from azureml.pipeline.steps import PythonScriptStep
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-sdk")
conda_dep.add_pip_package("azureml-pipeline")
rcfg = RunConfiguration(conda_dependencies=conda_dep)
model_download_step = PythonScriptStep(
name="Download Model 9",
script_name="model_download9.py",
arguments=["--hd_step_name", hd_step_name],
compute_target=compute_target,
source_directory=script_folder,
allow_reuse=False,
runconfig=rcfg
)
Langkah berikutnya
Untuk tutorial lengkap menggunakan
ParallelRunStep, lihat Tutorial: Membangun alur Azure Machine Learning untuk batch penilaian.Untuk contoh lengkap memperlihatkan pembelajaran mesin otomatis dalam alur ML, lihat Menggunakan ML otomatis dalam alur pembelajaran Azure Machine Learning di Python.
Lihat referensi SDK untuk bantuan dengan paket azureml-pipelines-core dan paket azureml-pipelines-steps.
Lihat daftar pengecualian desainer dan kode kesalahan.