Mendeteksi penyimpangan data (pratinjau) pada himpunan data
BERLAKU UNTUK: SDK Python azureml v1
SDK Python azureml v1
Pelajari cara memantau penyimpangan data dan mengatur pemberitahuan saat penyimpangan tinggi.
Dengan pemantauan himpunan data Azure Machine Learning (pratinjau), Anda bisa:
- Menganalisis penyimpangan dalam data Anda untuk memahami perubahannya dari waktu ke waktu.
- Memantau data model untuk perbedaan antara pelatihan dan himpunan data penyajian. Mulailah dengan mengumpulkan data model dari model yang disebarkan.
- Memantau data baru untuk perbedaan antara garis besar dan target himpunan data apa pun.
- Membuat profil fitur dalam data untuk melacak bagaimana properti statistik berubah dari waktu ke waktu.
- Menyiapkan pemberitahuan tentang penyimpangan data untuk pemberitahuan awal terhadap potensi masalah.
- Membuat versi himpunan data baru saat Anda menentukan data memiliki terlalu banyak penyimpangan.
Himpunan data Azure Pembelajaran Mesin digunakan untuk membuat monitor. Himpunan data harus menyertakan kolom tanda waktu.
Anda bisa melihat metrik penyimpangan data dengan Python SDK atau di studio Azure Machine Learning. Metrik dan wawasan lain tersedia melalui sumber daya Azure Application Insights yang terkait dengan ruang kerja Azure Machine Learning.
Penting
Deteksi penyimpangan data untuk himpunan data saat ini berada dalam pratinjau publik. Versi pratinjau disediakan tanpa perjanjian tingkat layanan, dan tidak disarankan untuk beban kerja produksi. Fitur tertentu mungkin tidak didukung atau mungkin memiliki kemampuan terbatas. Untuk mengetahui informasi selengkapnya, lihat Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure.
Prasyarat
Untuk membuat dan bekerja dengan pemantauan himpunan data, Anda memerlukan:
- Langganan Azure. Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai. Coba versi gratis atau berbayar Azure Machine Learning sekarang.
- Ruang kerja Azure Machine Learning.
- Azure Machine Learning SDK untuk Python diinstal, yang menyertakan paket azureml-datasets.
- Data terstruktur (tabular) dengan tanda waktu yang ditentukan dalam jalur file, nama file, atau kolom dalam data.
Apa itu penyimpangan data?
Akurasi model turun dari waktu ke waktu, sebagian besar karena penyimpangan data. Untuk model pembelajaran mesin, penyimpangan data adalah perubahan data input model yang mengarah pada penurunan kinerja model. Pemantauan penyimpangan data membantu mendeteksi masalah performa model ini.
Penyebab penyimpangan data meliputi:
- Perubahan proses upstram, seperti sensor yang diganti yang mengubah satuan pengukuran dari inci menjadi sentimeter.
- Masalah kualitas data, seperti sensor yang rusak selalu membaca 0.
- Penyimpangan alami dalam data, seperti perubahan suhu rata-rata dengan musim.
- Perubahan dalam hubungan antar-fitur, atau pergeseran kovariat.
Azure Machine Learning menyederhanakan deteksi penyimpangan dengan menghitung satu metrik yang mengabstraksi kompleksitas himpunan data yang dibandingkan. Himpunan data ini mungkin memiliki ratusan fitur dan puluhan ribu baris. Setelah penyimpangan terdeteksi, Anda menelusuri paling detail fitur mana yang menyebabkan penyimpangan. Kemudian, Anda memeriksa metrik tingkat fitur untuk menelusuri kesalahan dan mengisolasi akar penyebab penyimpangan.
Pendekatan top down ini memudahkan untuk memantau data alih-alih teknik berbasis aturan tradisional. Teknik berbasis aturan seperti rentang data yang diizinkan atau nilai unik yang diizinkan bisa memakan waktu dan rawan kesalahan.
Di Azure Machine Learning, Anda menggunakan pemantauan himpunan data untuk mendeteksi dan memberi tahu tentang penyimpangan data.
Pemantauan himpunan data
Dengan pemantauan himpunan data, Anda bisa:
- Mendeteksi dan memberi tahu tentang penyimpangan data pada data baru dalam himpunan data.
- Analisis data historis untuk penyimpangan.
- Buat profil data baru dari waktu ke waktu.
Algoritma penyimpangan data memberikan ukuran keseluruhan perubahan data dan indikasi fitur mana yang bertanggung jawab untuk penyelidikan lebih lanjut. Pemantauan himpunan data menghasilkan banyak metrik lain dengan membuat profil data baru dalam himpunan timeseries data.
Pemberitahuan kustom bisa diatur pada semua metrik yang dibuat oleh pemantauan melalui Azure Application Insights. Pemantauan himpunan data bisa digunakan untuk mengambil masalah data dengan cepat dan mengurangi waktu untuk menelusuri kesalahan masalah dengan mengidentifikasi kemungkinan penyebabnya.
Secara konseptual, ada tiga skenario utama untuk menyiapkan pemantauan himpunan data di Azure Machine Learning.
| Skenario | Deskripsi |
|---|---|
| Memantau data penyajian model untuk penyimpangan dari data pelatihan | Hasil dari skenario ini bisa diinterpretasikan sebagai pemantauan proksi untuk akurasi model, karena akurasi model menurun saat data memberikan penyimpangan data dari data pelatihan. |
| Memantau himpunan data rangkaian waktu untuk penyimpangan dari periode waktu sebelumnya. | Skenario ini lebih umum, dan bisa digunakan untuk memantau himpunan data yang terlibat di upstram atau downstream pembuatan model. Himpunan data target harus memiliki kolom tanda waktu. Himpunan data garis besar bisa menjadi himpunan data tabular apa pun yang memiliki kesamaan fitur dengan himpunan data target. |
| Lakukan analisis pada data sebelumnya. | Skenario ini bisa digunakan untuk memahami data historis dan menginformasikan keputusan dalam pengaturan untuk pemantauan himpunan data. |
Pemantauan himpunan data bergantung pada layanan Azure berikut.
| Layanan Azure | Deskripsi |
|---|---|
| Dataset | Penyimpangan menggunakan himpunan data Pembelajaran Mesin untuk mengambil data pelatihan dan membandingkan data untuk pelatihan model. Membuat profil data digunakan untuk membuat beberapa metrik yang dilaporkan seperti nilai min, maks, yang berbeda, jumlah nilai yang berbeda. |
| Alur dan komputasi Azure Pembelajaran Mesin | Pekerjaan penghitungan drift dihosting di alur Azure Pembelajaran Mesin. Pekerjaan dipicu sesuai permintaan atau sesuai jadwal untuk berjalan pada komputasi yang dikonfigurasi pada waktu pembuatan pemantauan penyimpangan. |
| Application Insights | Penyimpangan memancarkan metrik ke Application Insights milik ruang kerja pembelajaran mesin. |
| Penyimpanan blob Azure | Penyimpangan memancarkan metrik dalam format json ke penyimpanan blob Azure. |
Himpunan data garis besar dan target
Anda memantau himpunan data Azure Pembelajaran Mesin untuk penyimpangan data. Saat membuat monitor himpunan data, Anda mereferensikan:
- Himpunan data garis besar - biasanya himpunan data pelatihan untuk model.
- Target himpunan data - biasanya data input model - dibandingkan dari waktu ke waktu dengan himpunan data garis besar Anda. Perbandingan ini berarti bahwa himpunan data target Anda harus memiliki kolom tanda waktu yang ditentukan.
Monitor membandingkan himpunan data garis besar dan target.
Membuat himpunan data target
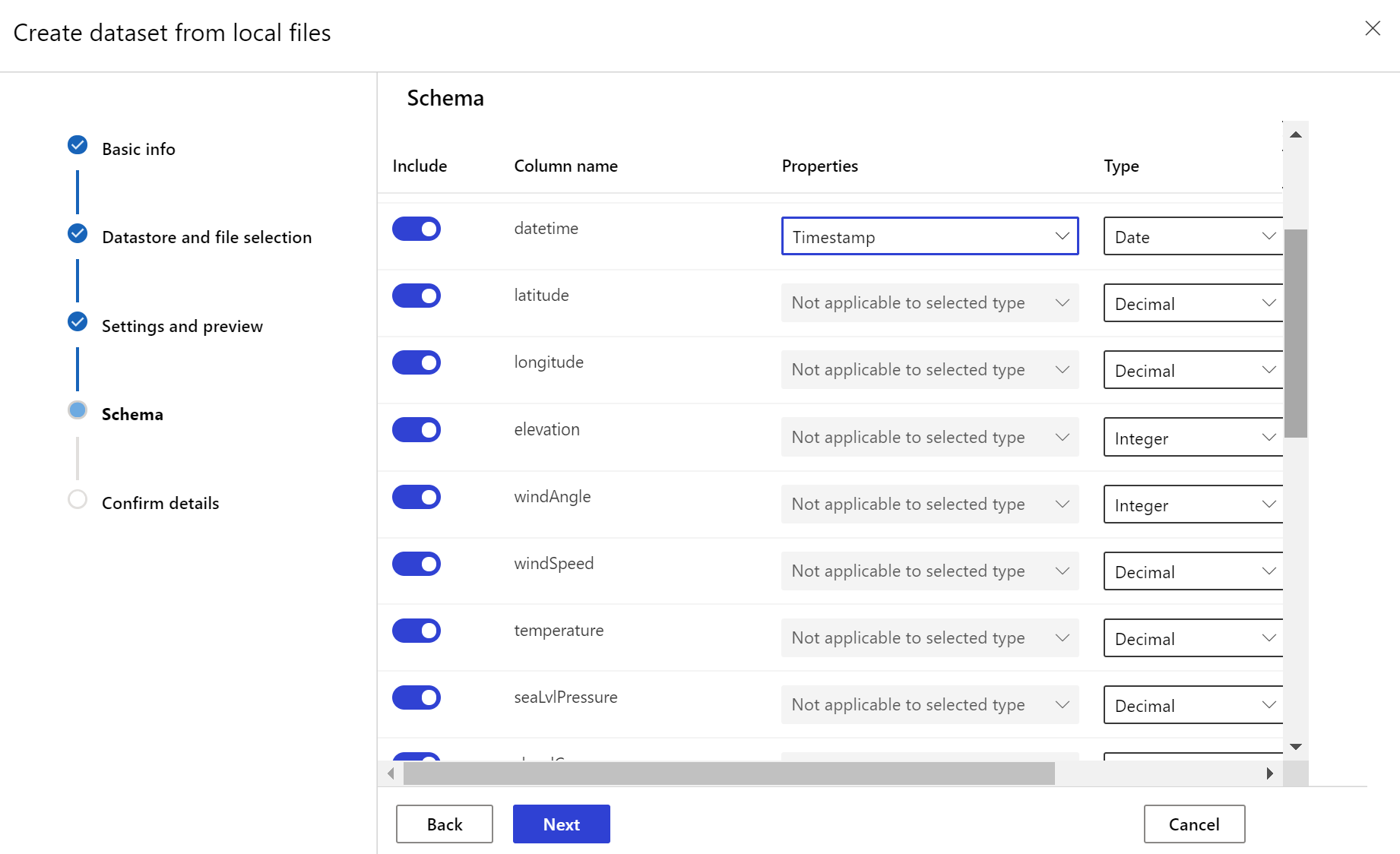
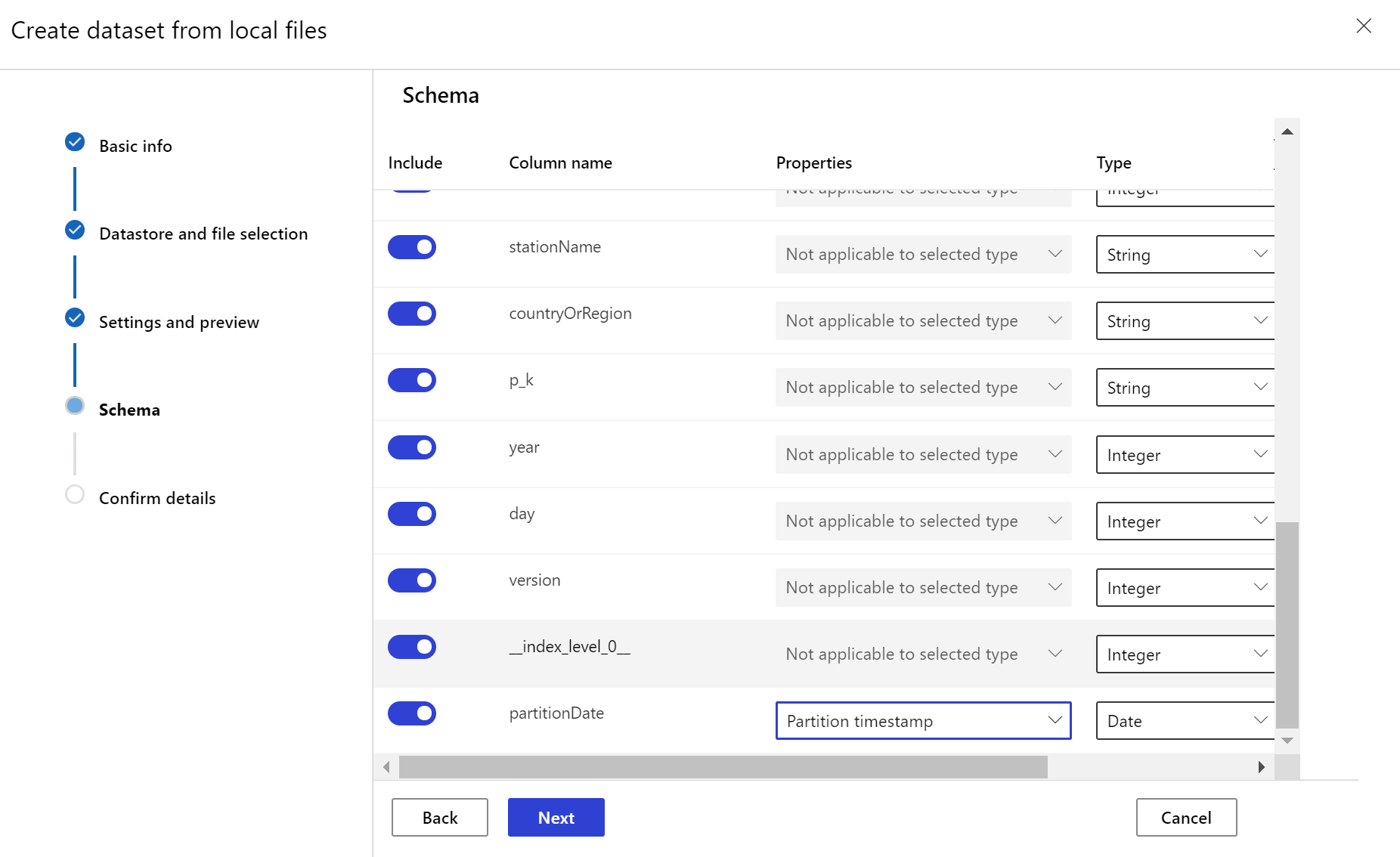
Himpunan data target memerlukan kumpulan sifat timeseries di dalamnya dengan menentukan tanda waktu baik dari kolom dalam data atau kolom virtual yang berasal dari pola jalur file. Buat himpunan data dengan tanda waktu melalui Python SDK atau studio Azure Machine Learning. Kolom yang mewakili “tanda waktu” harus ditentukan untuk menambahkan sifat timeseries ke himpunan data. Jika data Anda dipartisi ke dalam struktur folder dengan info waktu, seperti '{yyyy/MM/dd}', buat kolom virtual melalui pengaturan pola jalur dan tetapkan sebagai "tanda waktu partisi" untuk mengaktifkan fungsi API deret waktu.
BERLAKU UNTUK:SDK Python azureml v1
Metode with_timestamp_columns() kelas Dataset menentukan kolom stempel waktu untuk himpunan data.
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
Tip
Untuk contoh lengkap penggunaan sifat timeseries himpunan data, lihat contoh buku catatan atau dokumentasi SDK himpunan data.

Membuat pemantauan himpunan data
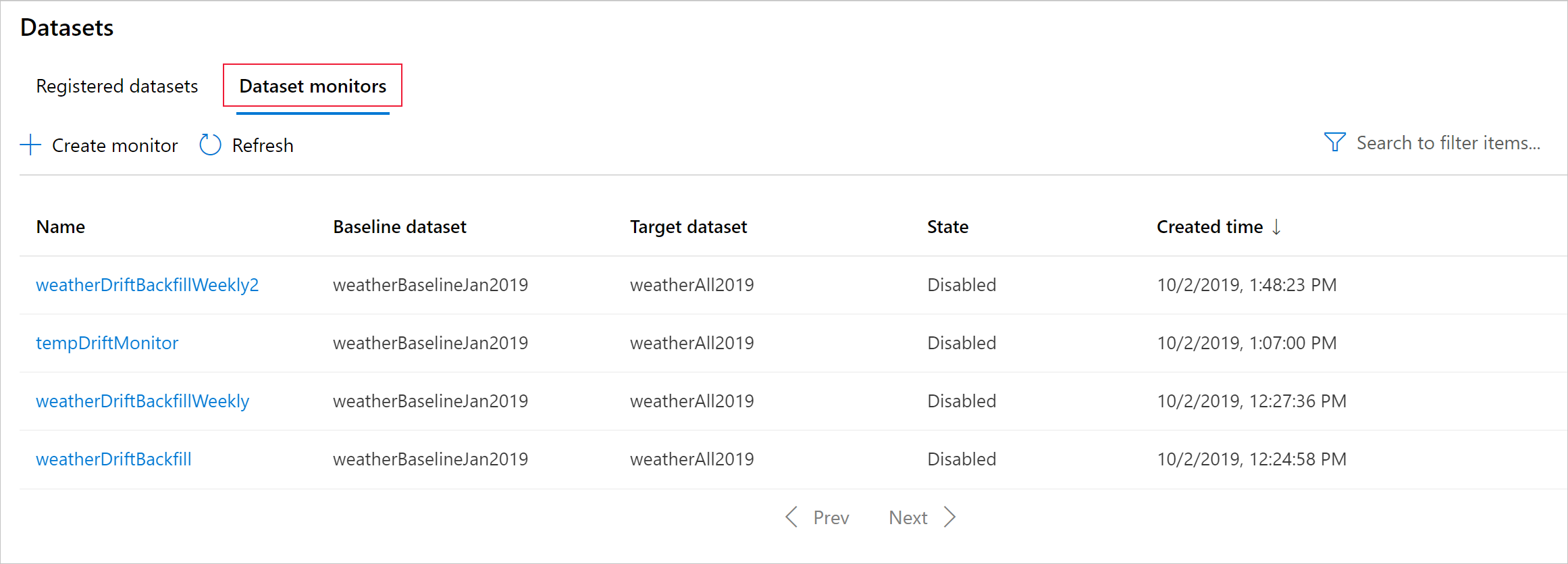
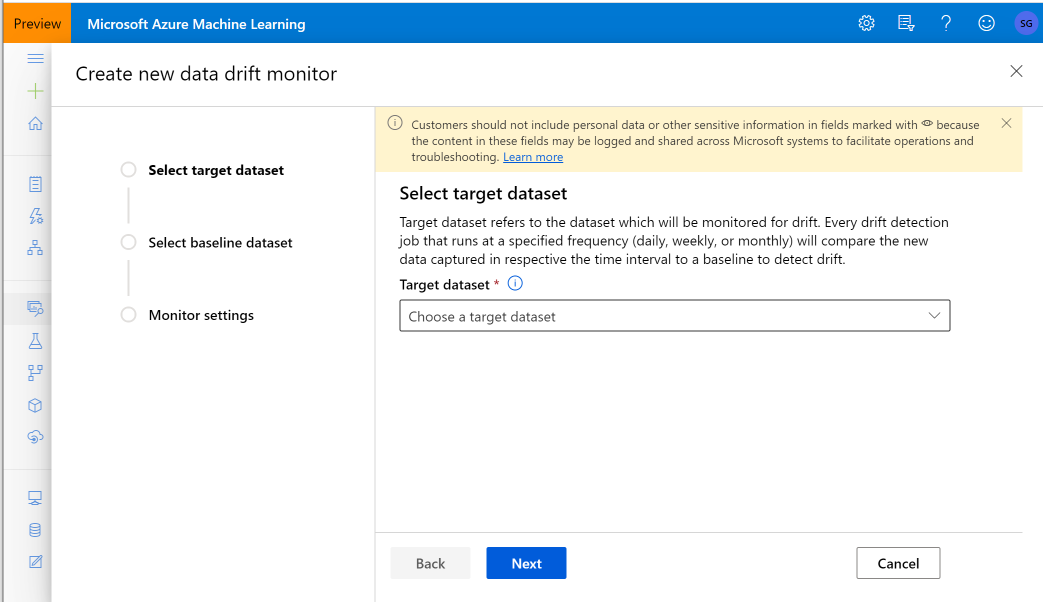
Buat pemantauan himpunan data untuk mendeteksi dan memberi tahu tentang penyimpanan data pada himpunan data baru. Gunakan SDK Python atau studio Azure Machine Learning.
Seperti yang dijelaskan nanti, monitor himpunan data berjalan pada interval frekuensi yang ditetapkan (harian, mingguan, bulanan). Ini menganalisis data baru yang tersedia dalam himpunan data target sejak eksekusi terakhirnya. Dalam beberapa kasus, analisis data terbaru tersebut mungkin tidak cukup:
- Data baru dari sumber upstream tertunda karena alur data yang rusak, dan data baru ini tidak tersedia saat monitor himpunan data berjalan.
- Himpunan data rangkaian waktu hanya memiliki data historis, dan Anda ingin menganalisis pola penyimpangan dalam himpunan data dari waktu ke waktu. Misalnya: bandingkan lalu lintas yang mengalir ke situs web, di musim dingin dan musim panas, untuk mengidentifikasi pola musiman.
- Anda baru menggunakan Monitor Himpunan Data. Anda ingin mengevaluasi cara kerja fitur dengan data yang ada sebelum menyiapkannya untuk memantau hari-hari mendatang. Dalam skenario seperti itu, Anda dapat mengirimkan eksekusi sesuai permintaan, dengan rentang tanggal himpunan data target tertentu, untuk membandingkan dengan himpunan data garis besar.
Fungsi isi ulang menjalankan pekerjaan isi ulang, untuk rentang tanggal mulai dan berakhir yang ditentukan. Pekerjaan isi ulang mengisi titik data yang diharapkan hilang dalam himpunan data, sebagai cara untuk memastikan akurasi dan kelengkapan data.
BERLAKU UNTUK:SDK Python azureml v1
Lihat dokumentasi referensi Python SDK tentang penyimpangan data untuk detail selengkapnya.
Contoh berikut menunjukkan cara membuat pemantauan himpunan data menggunakan Python SDK
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
Tip
Untuk contoh lengkap menyiapkan detektor himpunan data timeseries dan penyimpangan data, lihat contoh buku catatan kami.
Memahami hasil penyimpangan data
Bagian ini menunjukkan kepada Anda hasil pemantauan himpunan data, yang ditemukan di halaman Himpunan data / Himpunan data di Azure studio. Anda dapat memperbarui pengaturan, dan menganalisis data yang ada untuk periode waktu tertentu di halaman ini.
Mulailah dengan wawasan tingkat atas tentang besaran penyimpangan data dan sorotan fitur untuk diselidiki lebih lanjut.
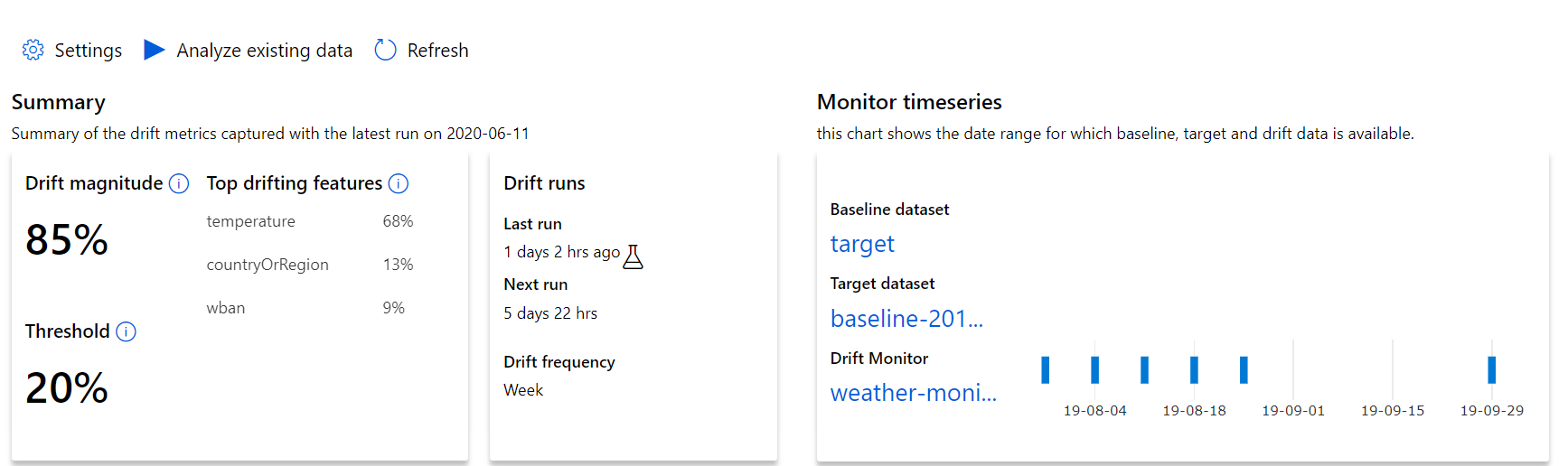
| Metrik | Deskripsi |
|---|---|
| Besaran penyimpangan data | Persentase penyimpangan antara himpunan data garis besar dan target dari waktu ke waktu. Persentase ini berkisar dari 0 hingga 100, 0 menunjukkan himpunan data yang identik dan 100 menunjukkan model penyimpangan data Azure Pembelajaran Mesin dapat sepenuhnya membedakan dua himpunan data. Kebisingan dalam persentase tepat yang diukur diharapkan karena teknik pembelajaran mesin digunakan untuk membuat besaran ini. |
| Fitur penyimpangan teratas | Fitur penyimpangan teratas: Menampilkan fitur dari himpunan data yang paling banyak menyimpang dan karenanya paling berkontribusi terhadap metrik Besaran Penyimpangan. Karena pergeseran kovariat, distribusi fitur yang mendasar tidak selalu perlu diubah untuk memiliki kepentingan fitur yang relatif tinggi. |
| Ambang | Besaran Penyimpangan Data di luar ambang batas yang ditetapkan memicu pemberitahuan. Konfigurasikan nilai ambang batas di pengaturan monitor. |
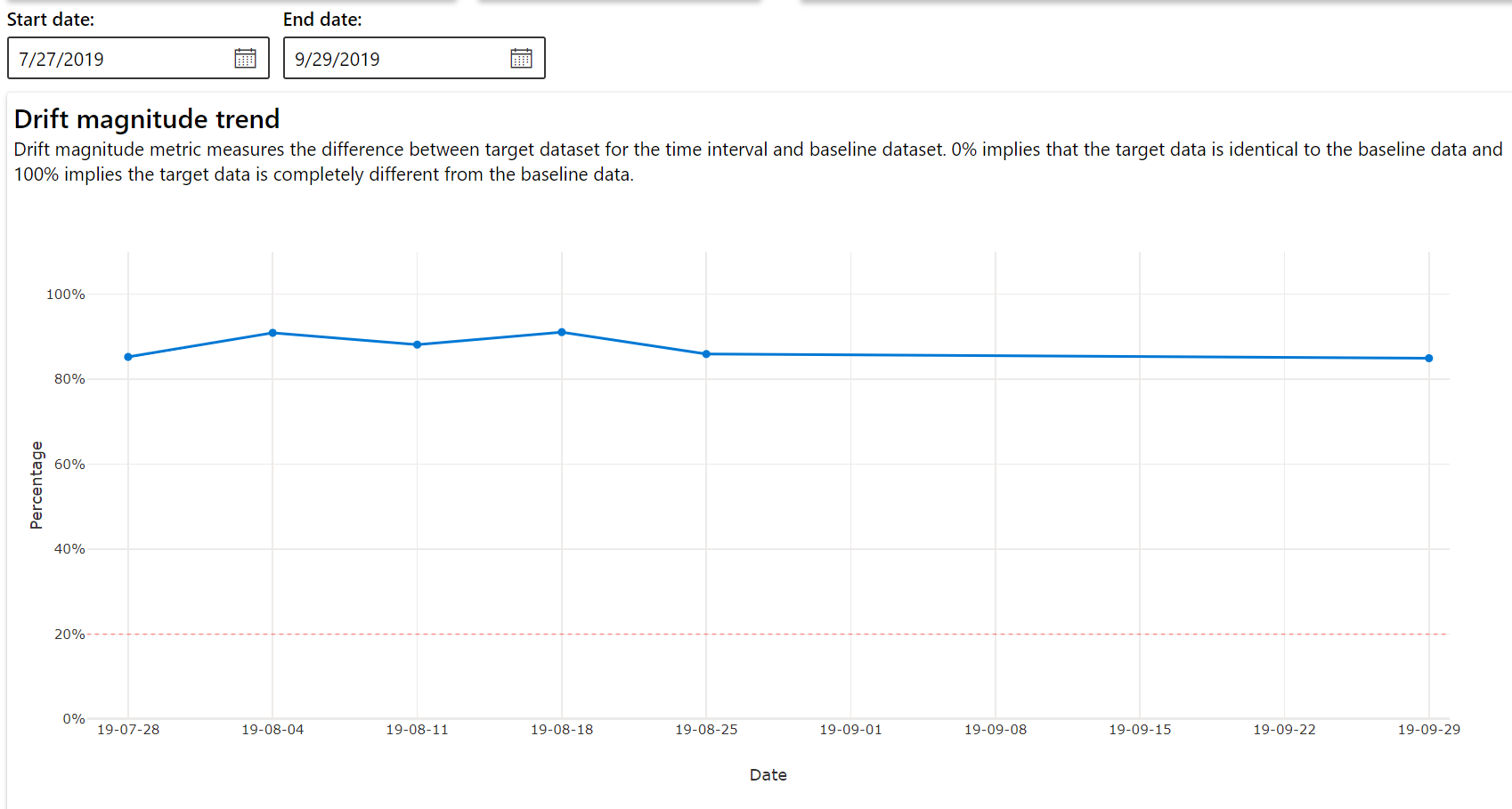
Tren besaran penyimpangan
Lihat cara himpunan data berbeda dari himpunan data target dalam periode waktu yang ditentukan. Semakin dekat ke 100%, semakin banyak perbedaan dua himpunan data.
Besaran penyimpangan berdasarkan fitur
Bagian ini berisi wawasan tingkat fitur tentang perubahan distribusi fitur yang dipilih, dan statistik lainnya, dari waktu ke waktu.
Himpunan data target juga dibuat profilnya dari waktu ke waktu. Jarak statistik antara distribusi garis besar setiap fitur dibandingkan dengan himpunan data target dari waktu ke waktu. Secara konseptual, ini menyerupai besaran penyimpangan data. Namun, jarak statistik ini untuk fitur individu daripada semua fitur. Min, maks, dan rata-rata juga tersedia.
Di studio Azure Pembelajaran Mesin, pilih bilah di grafik untuk melihat detail tingkat fitur untuk tanggal tersebut. Secara default, Anda melihat distribusi himpunan data dasar dan distribusi pekerjaan terbaru dari fitur yang sama.

Metrik ini juga bisa diambil di Python SDK melalui metode get_metrics() pada objek DataDriftDetector.
Detail fitur
Terakhir, gulir ke bawah untuk melihat detail untuk setiap fitur individual. Gunakan menu drop-down di atas bagan untuk memilih fitur, dan juga pilih metrik yang ingin Anda lihat.
Metrik dalam bagan bergantung pada jenis fitur.
Fitur numerik
Metrik Deskripsi Jarak Wasserstein Jumlah minimum pekerjaan untuk mengubah distribusi garis besar menjadi distribusi target. Nilai rata-rata Nilai rata-rata fitur. Nilai min Nilai minimal fitur. Nilai maks Nilai maksimal fitur. Fitur kategoris
Metrik Deskripsi Jarak Euclidian Dihitung untuk kolom kategoris. Jarak Euclidean dihitung pada dua vektor, dibuat dari distribusi empiris kolom kategoris yang sama dari dua himpunan data. 0 menunjukkan tidak ada perbedaan dalam distribusi empiris. Semakin menyimpang dari 0, semakin banyak kolom ini menyimpang. Tren bisa diamati dari plot seri waktu metrik ini dan bisa membantu dalam mengungkap fitur penyimpangan. Nilai unik Jumlah nilai unik (kardinalitas) fitur.
Di bagan ini, pilih satu tanggal untuk membandingkan distribusi fitur antara target dan tanggal ini untuk fitur yang ditampilkan. Untuk fitur numerik, ini menunjukkan dua distribusi probabilitas. Jika fitur ini berupa angka, bagan batang akan ditampilkan.
Metrik, pemberitahuan, dan peristiwa
Metrik bisa dikueri di sumber daya Azure Application Insights yang terkait dengan ruang kerja pembelajaran mesin Anda. Anda memiliki akses ke semua fitur Application Insights termasuk menyiapkan aturan pemberitahuan kustom dan grup tindakan untuk memicu tindakan seperti, Email/SMS/Push/Voice atau Fungsi Azure. Lihat dokumentasi Application Insights lengkap untuk detailnya.
Untuk memulai, navigasi ke portal Azure dan pilih halaman Gambaran Umum ruang kerja Anda. Sumber daya Application Insights terkait ada di ujung kanan:

Pilih Log (Analitik) di bawah Pemantauan di panel kiri:
Metrik pemantauan himpunan data disimpan sebagai customMetrics. Anda bisa menulis dan menjalankan kueri setelah menyiapkan pemantauan himpunan data untuk menampilkannya:

Setelah mengidentifikasi metrik untuk menyiapkan aturan pemberitahuan, buat aturan pemberitahuan baru:
Anda bisa menggunakan grup tindakan yang sudah ada, atau membuat grup tindakan baru untuk menentukan tindakan yang akan diambil saat kondisi yang ditetapkan terpenuhi:

Pemecahan Masalah
Batasan dan masalah umum untuk pemantauan penyimpangan data:
Rentang waktu saat menganalisis data historis dibatasi hingga 31 interval pengaturan frekuensi pemantauan.
Pembatasan 200 fitur, kecuali daftar fitur tidak ditentukan (semua fitur yang digunakan).
Ukuran komputasi harus cukup besar untuk menangani data.
Pastikan himpunan data Anda memiliki data dalam tanggal mulai dan tanggal selesai untuk tugas pemantauan tertentu.
Pemantauan himpunan data hanya berfungsi pada himpunan data yang berisi 50 baris atau lebih.
Kolom, atau fitur, dalam himpunan data diklasifikasikan sebagai kategoris atau numerik berdasarkan kondisi dalam tabel berikut. Jika fitur tidak memenuhi kondisi ini - misalnya, kolom string jenis dengan >100 nilai unik - fitur tersebut dihilangkan dari algoritma penyimpangan data kami, tetapi masih difilmkan.
Jenis fitur Jenis Data Kondisi Batasan Kategoris string Jumlah nilai unik dalam fitur ini kurang dari 100 dan kurang dari 5% dari jumlah baris. Null diperlakukan sebagai kategorinya sendiri. Numerik int, float Nilai dalam fitur ini adalah jenis data numerik, dan tidak memenuhi kondisi untuk fitur kategoris. Fitur dihilangkan jika >15% nilai adalah null. Saat Anda telah membuat monitor penyimpangan data tetapi tidak dapat melihat data di halaman Monitor himpunan data di studio Azure Pembelajaran Mesin, coba yang berikut ini.
- Periksa apakah Anda telah memilih rentang tanggal yang tepat di bagian atas halaman.
- Pada tab Pemantau Himpunan Data, pilih link eksperimen untuk memeriksa status pekerjaan. Tautan ini berada di ujung kanan tabel.
- Jika pekerjaan berhasil diselesaikan, periksa log driver untuk melihat berapa banyak metrik yang telah dibuat atau jika ada pesan peringatan. Temukan log driver di tab Output + log setelah Anda memilih eksperimen.
Jika fungsi SDK
backfill()tidak menghasilkan output yang diharapkan, mungkin karena masalah autentikasi. Saat Anda membuat komputasi untuk diteruskan ke fungsi ini, jangan gunakanRun.get_context().experiment.workspace.compute_targets. Sebagai gantinya, gunakan ServicePrincipalAuthentication seperti berikut ini untuk membuat komputasi yang Anda masukkan ke fungsibackfill()tersebut:auth = ServicePrincipalAuthentication( tenant_id=tenant_id, service_principal_id=app_id, service_principal_password=client_secret ) ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx") compute = ws.compute_targets.get("xxx")Dari Pengumpul Data Model, diperlukan waktu hingga 10 menit agar data tiba di akun penyimpanan blob Anda. Namun, biasanya membutuhkan lebih sedikit waktu. Dalam skrip atau Buku Catatan, tunggu 10 menit untuk memastikan bahwa sel di bawah ini berhasil dijalankan.
import time time.sleep(600)
Langkah berikutnya
- Buka studio Azure Machine Learning atau buku catatan Python untuk menyiapkan pemantauan himpunan data.
- Lihat cara mentiapkan penyimpangan data di model yang disebarkan ke Azure Kubernetes Service.
- Siapkan pemantauan penyimpangan himpunan data dengan Azure Event Grid.