Cara memilih algoritma untuk Azure Machine Learning
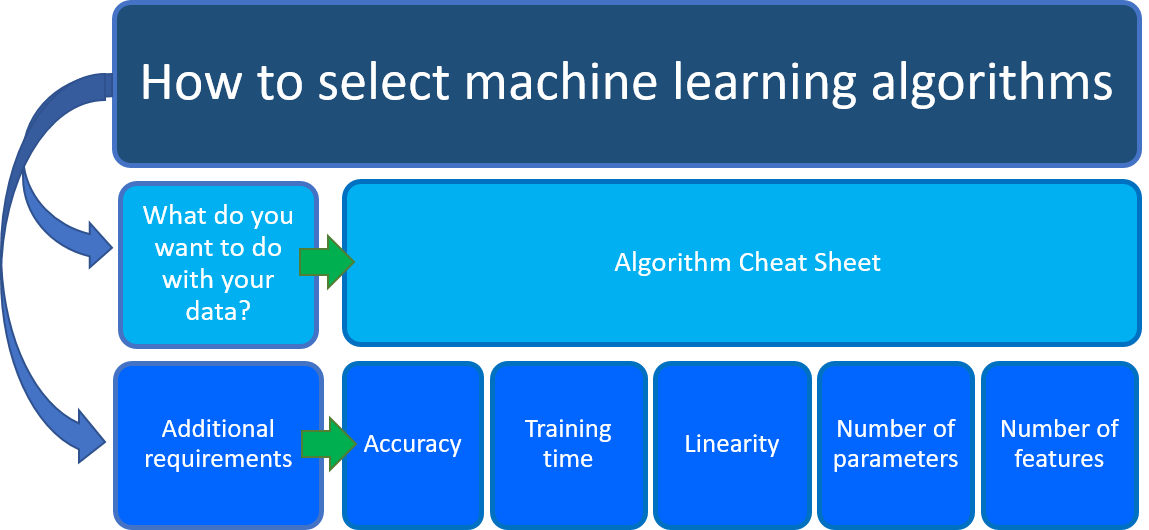
Pertanyaan umum adalah "Algoritma pembelajaran mesin mana yang harus saya gunakan?" Algoritma yang Anda pilih tergantung pada terutama dua aspek berbeda dari skenario ilmu data Anda:
Apa yang ingin Anda lakukan dengan data Anda? Secara khusus, apa pertanyaan bisnis yang ingin Anda jawab dengan belajar dari data Anda sebelumnya?
Apa saja persyaratan skenario ilmu data Anda? Secara khusus, apa keakuratan, waktu pelatihan, linieritas, jumlah parameter, dan jumlah fitur yang didukung solusi Anda?
Catatan
Perancang mendukung dua jenis komponen, komponen bawaan klasik (v1) dan komponen kustom (v2). Kedua jenis komponen ini TIDAK kompatibel.
Komponen bawaan klasik menyediakan komponen bawaan sebagian besar untuk pemrosesan data dan tugas pembelajaran mesin tradisional seperti regresi dan klasifikasi. Jenis komponen ini terus didukung tetapi tidak akan ada komponen baru yang ditambahkan.
Komponen kustom memungkinkan Anda membungkus kode Anda sendiri sebagai komponen. Ini mendukung berbagi komponen di seluruh ruang kerja dan penulisan tanpa hambatan di seluruh antarmuka Studio, CLI v2, dan SDK v2.
Untuk proyek baru, kami sangat menyarankan Anda menggunakan komponen kustom, yang kompatibel dengan AzureML V2 dan akan terus menerima pembaruan baru.
Artikel ini berlaku untuk komponen bawaan klasik dan tidak kompatibel dengan CLI v2 dan SDK v2.
Skenario bisnis dan Referensi Cepat Algoritma Pembelajaran Mesin
Referensi Cepat Algoritma Pembelajaran Mesin Azure membantu Anda dengan pertimbangan pertama: Apa yang ingin Anda lakukan dengan data Anda? Pada Pembelajaran Mesin Algoritma Cheat Sheet, cari tugas yang ingin Anda lakukan, lalu temukan algoritma perancang Azure Pembelajaran Mesin untuk solusi analitik prediktif.
Desainer Pembelajaran Mesin menyediakan portofolio algoritma yang komprehensif, seperti Hutan Keputusan Multikelas, sistem RekomendasiRegresi Jaringan Neural, Jaringan Neural Multikelas, dan Pengklusteran K-Means. Setiap algoritma dirancang untuk mengatasi berbagai jenis masalah pembelajaran mesin. Lihat Algoritma perancang Pembelajaran Mesin dan referensi komponen untuk daftar lengkap bersama dengan dokumentasi tentang cara kerja setiap algoritma dan cara menyetel parameter untuk mengoptimalkan algoritma.
Catatan
Unduh tips praktis di sini: Tips Praktis Algoritma Pembelajaran Mesin (11x17 in.)
Seiring dengan panduan dalam Referensi Cepat Algoritma Azure Machine Learning, ingat persyaratan lain saat memilih algoritma pembelajaran mesin untuk solusi Anda. Berikut adalah faktor tambahan yang perlu dipertimbangkan, seperti akurasi, waktu pelatihan, linieritas, jumlah parameter dan jumlah fitur.
Perbandingan algoritma pembelajaran mesin
Beberapa algoritma pembelajaran membuat asumsi tertentu tentang struktur data atau hasil yang diinginkan. Jika Anda dapat menemukan yang sesuai dengan kebutuhan Anda, itu dapat memberi Anda hasil yang lebih berguna, prediksi yang lebih akurat, atau waktu pelatihan yang lebih cepat.
Tabel berikut ini merangkum beberapa karakteristik algoritma yang paling penting dari keluarga klasifikasi, regresi, dan pengelompokan:
| Algorithm | Akurasi | Waktu Pelatihan | Linearitas | Parameter | Catatan |
|---|---|---|---|---|---|
| Keluarga klasifikasi | |||||
| Regresi Logistik Dua Kelas | Bagus | Cepat | Ya | 4 | |
| Hutan keputusan dua Kelas | Baik Sekali | Sedang | Tidak | 5 | Memperlihatkan waktu penilaian yang lebih lambat. Menyarankan untuk tidak bekerja dengan Multikelas One-vs-All, karena waktu penilaian yang lebih lambat yang disebabkan oleh penguncian tapak dalam mengakumulasi prediksi pohon |
| Pohon keputusan yang didorong dua Kelas | Baik Sekali | Sedang | Tidak | 6 | Jejak memori besar |
| Jaringan neural dua kelas | Bagus | Sedang | Tidak | 8 | |
| Perceptron rata-rata dua kelas | Bagus | Sedang | Ya | 4 | |
| Mesin vektor dukungan dua kelas | Bagus | Cepat | Ya | 5 | Bagus untuk set fitur besar |
| Regresi logistik multikelas | Bagus | Cepat | Ya | 4 | |
| Hutan keputusan multikelas | Baik Sekali | Sedang | Tidak | 5 | Memperlihatkan waktu penilaian yang lebih lambat |
| Pohon keputusan multikelas yang ditingkatkan | Baik Sekali | Sedang | Tidak | 6 | Cenderung meningkatkan akurasi dengan beberapa risiko kecil pada cakupan yang lebih sedikit |
| Jaringan neural Multikelas | Bagus | Sedang | Tidak | 8 | |
| Multikelas one-vs-all | - | - | - | - | Lihat properti dari metode dua kelas yang dipilih |
| Keluarga regresi | |||||
| Regresi Linear | Bagus | Cepat | Ya | 4 | |
| Regresi hutan keputusan | Baik Sekali | Sedang | Tidak | 5 | |
| Regresi pohon keputusan yang ditingkatkan | Baik Sekali | Sedang | Tidak | 6 | Jejak memori besar |
| Regresi jaringan neural | Bagus | Sedang | Tidak | 8 | |
| Keluarga pengklusteran | |||||
| Pengklusteran K-means | Baik Sekali | Sedang | Ya | 8 | Algoritma pengklusteran |
Persyaratan untuk skenario ilmu data
Setelah mengetahui apa yang ingin Anda lakukan dengan data Anda, Anda perlu menentukan persyaratan tambahan untuk solusi Anda.
Buat pilihan dan mungkin kemungkinan konsekuensi untuk persyaratan berikut:
- Akurasi
- Waktu Pelatihan
- Linearitas
- Jumlah parameter
- Jumlah fitur
Akurasi
Akurasi dalam pembelajaran mesin mengukur efektivitas model sebagai proporsi hasil yang benar untuk total kasus. Dalam perancang Pembelajaran Mesin, komponen Model Evaluasi menghitung kumpulan metrik evaluasi standar industri. Anda dapat menggunakan komponen ini untuk mengukur akurasi model terlatih.
Mendapatkan jawaban yang paling akurat mungkin tidak selalu diperlukan. Terkadang perkiraan memadai, tergantung pada apa yang ingin Anda gunakan. Jika demikian, Anda mungkin dapat memotong waktu pemrosesan Anda secara dramatis dengan tetap dengan metode perkiraan yang lebih. Metode perkiraan juga secara alami cenderung menghindari overfitting.
Ada tiga cara untuk menggunakan komponen Model Evaluasi:
- Hasilkan skor atas data pelatihan Anda untuk mengevaluasi model
- Hasilkan skor pada model, tetapi bandingkan skor tersebut dengan skor pada set pengujian yang dipesan
- Bandingkan skor untuk dua model yang berbeda tetapi terkait, menggunakan kumpulan data yang sama
Untuk daftar lengkap metrik dan pendekatan yang dapat Anda gunakan untuk mengevaluasi keakuratan model pembelajaran mesin, lihat komponen Model Evaluasi.
Waktu Pelatihan
Dalam pembelajaran yang diawasi, pelatihan berarti menggunakan data historis untuk membangun model pembelajaran mesin yang meminimalkan kesalahan. Jumlah menit atau jam yang diperlukan untuk melatih model sangat bervariasi di antara algoritma. Waktu pelatihan sering terkait erat dengan akurasi; yang biasanya menyertai yang lain.
Selain itu, beberapa algoritma lebih sensitif terhadap jumlah titik data daripada yang lain. Anda mungkin memilih algoritma tertentu karena Anda memiliki batasan waktu, terutama ketika himpunan data yang besar.
Dalam desainer Pembelajaran Mesin, membuat dan menggunakan model pembelajaran mesin biasanya merupakan proses tiga langkah:
Konfigurasikan model, dengan memilih jenis algoritma tertentu, lalu definisikan parameter atau hyperparameternya.
Berikan kumpulan data yang diberi label, dan memiliki data yang kompatibel dengan algoritma. Hubungkan data dan model ke komponen Model Pelatihan.
Setelah pelatihan selesai, gunakan model terlatih dengan salah satu komponen penilaian, untuk membuat prediksi pada data baru.
Linearitas
Linearitas dalam statistik dan pembelajaran mesin berarti bahwa ada hubungan linier antara variabel dan konstanta dalam set data Anda. Misalnya, algoritma klasifikasi linear mengasumsikan bahwa class dapat dipisahkan oleh garis lurus (atau analognya yang lebih tinggi dimensinya).
Banyak algoritma pembelajaran mesin memanfaatkan linieritas. Di perancang Azure Machine Learning, mereka meliputi:
Algoritma regresi linear mengasumsikan bahwa tren data mengikuti garis lurus. Asumsi ini tidak buruk untuk beberapa masalah, tetapi bagi yang lain itu mengurangi akurasi. Terlepas dari kekurangannya, algoritma linier populer sebagai strategi pertama. Mereka cenderung secara algoritma sederhana dan cepat untuk melatih.
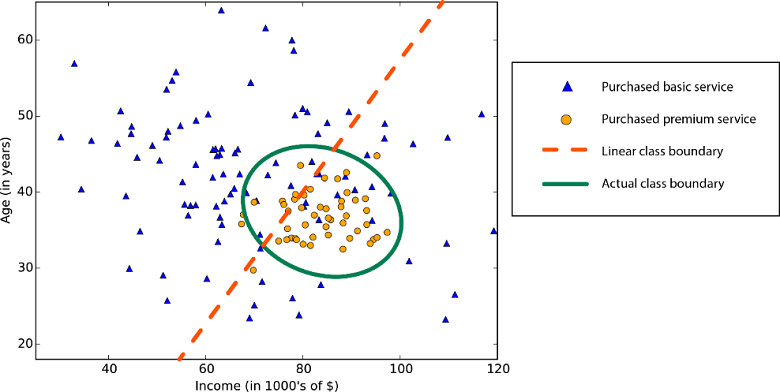
Batas kelas tidak linier: Mengandalkan algoritma klasifikasi linier akan mengakibatkan akuraasi rendah.
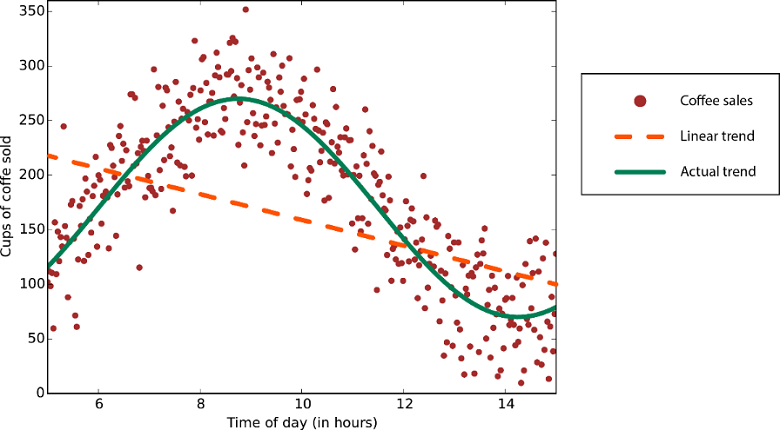
Data dengan tren tidak linier: Menggunakan metode regresi linier akan menghasilkan kesalahan lebih besar yang tidak diperlukan.
Jumlah parameter
Parameter adalah tombol yang didapat ilmuwan data saat menyiapkan algoritma. Mereka adalah angka yang mempengaruhi perilaku algoritma, seperti toleransi kesalahan atau jumlah iterasi, atau opsi antara varian tentang bagaimana algoritma berperilaku. Waktu pelatihan dan akurasi algoritma kadang-kadang bisa sensitif untuk mendapatkan pengaturan yang tepat. Biasanya, algoritma dengan sejumlah besar parameter membutuhkan uji coba dan kesalahan terbanyak untuk menemukan kombinasi yang baik.
Atau, ada komponen penyetelan Model Hiperparameter dalam perancang Pembelajaran Mesin: Tujuan komponen ini adalah untuk menentukan hyperparameter optimal untuk model pembelajaran mesin. Komponen ini membangun dan menguji beberapa model dengan menggunakan kombinasi pengaturan yang berbeda. Hal tersebut membandingkan metrik di semua model untuk mendapatkan kombinasi pengaturan.
Meskipun ini adalah cara yang bagus untuk memastikan Anda telah membentangkan ruang parameter, waktu yang diperlukan untuk melatih model yang meningkat secara eksponensial dengan jumlah parameter. Yang terbalik adalah bahwa memiliki banyak parameter biasanya menunjukkan bahwa algoritma memiliki fleksibilitas yang lebih besar. Hal tersebut sering dapat mencapai akurasi yang sangat baik, asalkan Anda dapat menemukan kombinasi pengaturan parameter yang tepat.
Jumlah fitur
Dalam pembelajaran mesin, fitur adalah variabel yang dapat diukur dari fenomena yang ingin Anda analisis. Untuk jenis data tertentu, jumlah fitur bisa sangat besar dibandingkan dengan jumlah poin data. Ini sering terjadi dengan genetika atau data tekstual.
Baynyak fitur yang dapat mengurangi beberapa algoritma pembelajaran, membuat waktu pelatihan tidak terlalu lama. Mesin vektor pendukung sangat cocok untuk skenario dengan sejumlah fitur yang banyak. Untuk alasan ini, mereka telah digunakan dalam banyak aplikasi dari pengambilan informasi hingga klasifikasi teks dan gambar. Mesin vektor pendukung dapat digunakan untuk tugas klasifikasi dan regresi.
Pemilihan fitur mengacu pada proses penerapan tes statistik ke input, diberikan output yang ditentukan. Tujuannya adalah untuk menentukan kolom mana yang bersifat prediktif dari output yang dihasilkan. Komponen Pemilihan Fitur Berbasis Filter di perancang Pembelajaran Mesin menyediakan beberapa algoritma fitur pemilihan untuk dipilih. Komponen ini mencakup metode korelasi seperti korelasi Pearson dan nilai chi kuadrat.
Anda juga dapat menggunakan komponen Kepentingan Fitur Permutasi untuk menghitung serangkaian skor penting fitur untuk himpunan data Anda. Anda kemudian dapat memanfaatkan skor ini untuk membantu Anda menentukan fitur terbaik untuk digunakan dalam model.
Langkah berikutnya
- Pelajari selengkapnya tentang perancang Azure Machine Learning
- Untuk deskripsi semua algoritma pembelajaran mesin yang tersedia di perancang Azure Machine Learning, lihat algoritma perancang Pembelajaran Mesin dan referensi komponen
- Untuk mempelajari hubungan antara pembelajaran mendalam, pembelajaran mesin, dan AI, lihat Pembelajaran Mendalam vs. Pembelajaran Mesin