Latih model TensorFlow dalam skala besar dengan Azure Machine Learning
BERLAKU UNTUK: Python SDK azure-ai-ml v2 (saat ini)
Python SDK azure-ai-ml v2 (saat ini)
Dalam artikel ini, pelajari cara menjalankan skrip pelatihan TensorFlow Anda dalam skala besar menggunakan Azure Pembelajaran Mesin Python SDK v2.
Contoh kode dalam artikel ini melatih model TensorFlow untuk mengklasifikasikan digit tulisan tangan, menggunakan jaringan neural dalam (DNN); mendaftarkan model; dan menyebarkannya ke titik akhir online.
Baik Anda mengembangkan model TensorFlow dari awal atau membawa model yang ada ke cloud, Anda dapat menggunakan Azure Pembelajaran Mesin untuk menskalakan pekerjaan pelatihan sumber terbuka menggunakan sumber daya komputasi cloud elastis. Anda dapat membuat, menyebarkan, membuat versi, dan memantau model tingkat produksi dengan Azure Machine Learning.
Prasyarat
Untuk mendapatkan manfaat dari artikel ini, Anda perlu:
- Mengakses langganan Azure. Jika Anda belum memilikinya, buat akun gratis.
- Jalankan kode dalam artikel ini menggunakan instans komputasi Azure Pembelajaran Mesin atau notebook Jupyter Anda sendiri.
- Instans komputasi Azure Pembelajaran Mesin—tidak ada unduhan atau penginstalan yang diperlukan
- Selesaikan tutorial Buat sumber daya untuk memulai untuk membuat server notebook khusus yang telah dimuat sebelumnya dengan SDK dan repositori sampel.
- Di folder pembelajaran mendalam sampel di server notebook, temukan buku catatan yang telah selesai dan diperluas dengan menavigasi ke direktori ini: pekerjaan python >> sdk > v2 > tensorflow > single-step > train-hyperparameter-tune-deploy-with-tensorflow.
- Server notebook Jupyter Anda
- Instans komputasi Azure Pembelajaran Mesin—tidak ada unduhan atau penginstalan yang diperlukan
- Unduh file berikut:
- tf_mnist.py skrip pelatihan
- score.py skrip penilaian
- contoh file permintaan sample-request.json
Anda juga dapat menemukan versi Jupyter Notebook yang telah selesai dari panduan ini di halaman sampel GitHub.
Sebelum dapat menjalankan kode dalam artikel ini untuk membuat kluster GPU, Anda harus meminta peningkatan kuota untuk ruang kerja Anda.
Menyiapkan pekerjaan
Bagian ini menyiapkan pekerjaan untuk pelatihan dengan memuat paket Python yang diperlukan, menyambungkan ke ruang kerja, membuat sumber daya komputasi untuk menjalankan pekerjaan perintah, dan membuat lingkungan untuk menjalankan pekerjaan.
Menyambungkan ke ruang kerja
Pertama, Anda perlu menyambungkan ke ruang kerja Azure Pembelajaran Mesin Anda. Ruang kerja Azure Machine Learning adalah sumber daya tingkat teratas untuk layanan ini. Ini memberi Anda tempat terpusat untuk bekerja dengan semua artefak yang Anda buat saat menggunakan Azure Pembelajaran Mesin.
Kami menggunakan DefaultAzureCredential untuk mendapatkan akses ke ruang kerja. Kredensial ini harus mampu menangani sebagian besar skenario autentikasi Azure SDK.
Jika DefaultAzureCredential tidak berfungsi untuk Anda, lihat azure-identity reference documentation atau Set up authentication untuk kredensial yang tersedia lainnya.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()Jika Anda lebih suka menggunakan browser untuk masuk dan mengautentikasi, Anda harus membatalkan komentar kode berikut dan menggunakannya sebagai gantinya.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
Selanjutnya, dapatkan handel ke ruang kerja dengan memberikan ID Langganan, nama Grup Sumber Daya, dan nama ruang kerja Anda. Untuk menemukan parameter ini:
- Cari nama ruang kerja Anda di sudut kanan atas toolbar studio Azure Pembelajaran Mesin.
- Pilih nama ruang kerja Anda untuk menampilkan Grup Sumber Daya dan ID Langganan Anda.
- Salin nilai untuk Grup Sumber Daya dan ID Langganan ke dalam kode.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)Hasil menjalankan skrip ini adalah handel ruang kerja yang Anda gunakan untuk mengelola sumber daya dan pekerjaan lain.
Catatan
- Membuat
MLClienttidak akan menghubungkan klien ke ruang kerja. Inisialisasi klien malas dan akan menunggu untuk pertama kalinya perlu melakukan panggilan. Dalam artikel ini, ini akan terjadi selama pembuatan komputasi.
Buat sumber daya komputasi
Azure Pembelajaran Mesin memerlukan sumber daya komputasi untuk menjalankan pekerjaan. Sumber daya ini dapat berupa mesin tunggal atau multi-simpul dengan OS Linux atau Windows, atau kain komputasi tertentu seperti Spark.
Dalam contoh skrip berikut, kami menyediakan Linux compute cluster. Anda dapat melihat Azure Machine Learning pricing halaman untuk daftar lengkap ukuran dan harga VM. Karena kita memerlukan kluster GPU untuk contoh ini, mari kita pilih model STANDARD_NC6 dan buat komputasi Azure Pembelajaran Mesin.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)Membuat lingkungan pekerjaan
Untuk menjalankan pekerjaan Azure Pembelajaran Mesin, Anda memerlukan lingkungan. Lingkungan Azure Pembelajaran Mesin merangkum dependensi (seperti runtime perangkat lunak dan pustaka) yang diperlukan untuk menjalankan skrip pelatihan pembelajaran mesin Anda pada sumber daya komputasi Anda. Lingkungan ini mirip dengan lingkungan Python di komputer lokal Anda.
Azure Pembelajaran Mesin memungkinkan Anda menggunakan lingkungan yang dikumpulkan (atau siap) —berguna untuk skenario pelatihan dan inferensi umum—atau membuat lingkungan kustom menggunakan gambar Docker atau konfigurasi Conda.
Dalam artikel ini, Anda menggunakan kembali lingkungan AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpuAzure Pembelajaran Mesin yang dikumpulkan. Anda menggunakan versi terbaru lingkungan ini menggunakan arahan @latest .
curated_env_name = "AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu@latest"Mengonfigurasi dan mengirimkan pekerjaan pelatihan Anda
Di bagian ini, kita mulai dengan memperkenalkan data untuk pelatihan. Kami kemudian membahas cara menjalankan pekerjaan pelatihan, menggunakan skrip pelatihan yang telah kami sediakan. Anda belajar membangun pekerjaan pelatihan dengan mengonfigurasi perintah untuk menjalankan skrip pelatihan. Kemudian, Anda mengirimkan pekerjaan pelatihan untuk dijalankan di Azure Pembelajaran Mesin.
Mendapatkan data pelatihan
Anda akan menggunakan data dari database Modified National Institute of Standards and Technology (MNIST) dari digit tulisan tangan. Data ini bersumber dari situs web Yan LeCun dan disimpan di akun penyimpanan Azure.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"Untuk informasi selengkapnya tentang himpunan data MNIST, kunjungi situs web Yan LeCun.
Menyiapkan skrip pelatihan
Dalam artikel ini, kami telah menyediakan skrip pelatihan tf_mnist.py. Dalam praktiknya, Anda harus dapat mengambil skrip pelatihan kustom apa adanya dan menjalankannya dengan Azure Pembelajaran Mesin tanpa harus mengubah kode Anda.
Skrip pelatihan yang disediakan melakukan hal berikut:
- menangani pra-pemrosesan data, memisahkan data menjadi data pengujian dan pelatihan;
- melatih model, menggunakan data; Dan
- mengembalikan model output.
Selama eksekusi alur, Anda menggunakan MLFlow untuk mencatat parameter dan metrik. Untuk mempelajari cara mengaktifkan pelacakan MLFlow, lihat Melacak eksperimen dan model ML dengan MLflow.
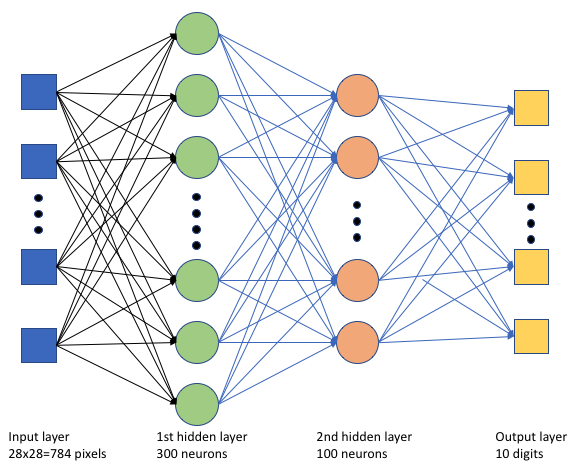
Dalam skrip tf_mnist.pypelatihan, kami membuat jaringan neural dalam sederhana (DNN). DNN ini memiliki:
- Lapisan input dengan 28 * 28 = 784 neuron. Setiap neuron mewakili piksel gambar.
- Dua lapisan tersembunyi. Lapisan tersembunyi pertama memiliki 300 neuron dan lapisan tersembunyi kedua memiliki 100 neuron.
- Lapisan output dengan 10 neuron. Setiap neuron mewakili label yang ditargetkan dari 0 hingga 9.
Membangun pekerjaan pelatihan
Sekarang setelah Anda memiliki semua aset yang diperlukan untuk menjalankan pekerjaan Anda, saatnya untuk membuatnya menggunakan Azure Pembelajaran Mesin Python SDK v2. Untuk contoh ini, kami membuat command.
Azure Pembelajaran Mesin command adalah sumber daya yang menentukan semua detail yang diperlukan untuk menjalankan kode pelatihan Anda di cloud. Detail ini mencakup input dan output, jenis perangkat keras yang akan digunakan, perangkat lunak untuk diinstal, dan cara menjalankan kode Anda. berisi command informasi untuk menjalankan satu perintah.
Mengonfigurasi perintah
Anda menggunakan tujuan command umum untuk menjalankan skrip pelatihan dan melakukan tugas yang Anda inginkan. Buat Command objek untuk menentukan detail konfigurasi pekerjaan pelatihan Anda.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=64,
first_layer_neurons=256,
second_layer_neurons=128,
learning_rate=0.01,
),
compute=gpu_compute_target,
environment=curated_env_name,
code="./src/",
command="python tf_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="tf-dnn-image-classify",
display_name="tensorflow-classify-mnist-digit-images-with-dnn",
)Input untuk perintah ini termasuk lokasi data, ukuran batch, jumlah neuron di lapisan pertama dan kedua, dan tingkat pembelajaran. Perhatikan bahwa kami telah melewati jalur web secara langsung sebagai input.
Untuk nilai parameter:
- menyediakan kluster komputasi
gpu_compute_target = "gpu-cluster"yang Anda buat untuk menjalankan perintah ini; - menyediakan lingkungan
curated_env_nameyang dikumpulkan yang Anda deklarasikan sebelumnya; - konfigurasikan tindakan baris perintah itu sendiri—dalam hal ini, perintahnya adalah
python tf_mnist.py. Anda dapat mengakses input dan output dalam perintah melalui${{ ... }}notasi; dan - mengonfigurasi metadata seperti nama tampilan dan nama eksperimen; di mana eksperimen adalah kontainer untuk semua iterasi yang dilakukan pada proyek tertentu. Semua pekerjaan yang dikirimkan dengan nama eksperimen yang sama akan dicantumkan di samping satu sama lain di studio Azure Pembelajaran Mesin.
- menyediakan kluster komputasi
Dalam contoh ini, Anda akan menggunakan
UserIdentityuntuk menjalankan perintah. Menggunakan identitas pengguna berarti bahwa perintah akan menggunakan identitas Anda untuk menjalankan pekerjaan dan mengakses data dari blob.
Mengirimkan pekerjaan
Sekarang saatnya untuk mengirimkan pekerjaan untuk dijalankan di Azure Pembelajaran Mesin. Kali ini, Anda akan menggunakan create_or_update pada ml_client.jobs.
ml_client.jobs.create_or_update(job)Setelah selesai, pekerjaan akan mendaftarkan model di ruang kerja Anda (sebagai hasil dari pelatihan) dan menghasilkan tautan untuk melihat pekerjaan di studio Azure Pembelajaran Mesin.
Peringatan
Azure Machine Learning menjalankan skrip pelatihan dengan menyalin seluruh direktori sumber. Jika Anda memiliki data sensitif yang tidak ingin Anda unggah, gunakan file .ignore atau jangan sertakan dalam direktori sumber.
Apa yang terjadi selama eksekusi pekerjaan
Saat pekerjaan dijalankan, pekerjaan akan melalui tahapan berikut:
Persiapan: Gambar docker dibuat sesuai dengan lingkungan yang ditentukan. Gambar diunggah ke registri kontainer ruang kerja dan di-cache untuk dijalankan nantinya. Log juga dialirkan ke riwayat pekerjaan dan dapat dilihat untuk memantau kemajuan. Jika lingkungan yang dikumpulkan ditentukan, pencadangan gambar cache yang dikumpulkan lingkungan akan digunakan.
Penskalakan: Kluster mencoba meningkatkan skala jika memerlukan lebih banyak simpul untuk menjalankan eksekusi daripada yang saat ini tersedia.
Berjalan: Semua skrip dalam src folder skrip diunggah ke target komputasi, penyimpanan data dipasang atau disalin, dan skrip dijalankan. Output dari stdout dan folder ./logs dialirkan ke riwayat pekerjaan dan dapat digunakan untuk memantau pekerjaan.
Menyetel hiperparameter model
Sekarang setelah Anda melihat cara melakukan eksekusi pelatihan TensorFlow menggunakan SDK, mari kita lihat apakah Anda dapat lebih meningkatkan akurasi model Anda. Anda dapat menyetel dan mengoptimalkan hiperparameter model Anda menggunakan kemampuan Azure Pembelajaran Mesinsweep.
Untuk menyetel hiperparameter model, tentukan ruang parameter untuk mencari selama pelatihan. Anda akan melakukan ini dengan mengganti beberapa parameter (batch_size, , first_layer_neurons, second_layer_neuronsdan learning_rate) yang diteruskan ke pekerjaan pelatihan dengan input khusus dari azure.ml.sweep paket.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[32, 64, 128]),
first_layer_neurons=Choice(values=[16, 64, 128, 256, 512]),
second_layer_neurons=Choice(values=[16, 64, 256, 512]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)Kemudian, Anda mengonfigurasi pembersihan pada pekerjaan perintah, menggunakan beberapa parameter khusus sapuan, seperti metrik utama untuk ditonton dan algoritma pengambilan sampel yang akan digunakan.
Dalam kode berikut, kami menggunakan pengambilan sampel acak untuk mencoba set konfigurasi hiperparameter yang berbeda dalam upaya untuk memaksimalkan metrik utama kami, validation_acc.
Kami juga mendefinisikan kebijakan penghentian dini— BanditPolicy. Kebijakan ini beroperasi dengan memeriksa pekerjaan setiap dua iterasi. Jika metrik utama, validation_acc, berada di luar rentang 10 persen teratas, Azure Pembelajaran Mesin mengakhiri pekerjaan. Ini menghemat model agar tidak terus menjelajahi hiperparameter yang tidak menunjukkan janji untuk membantu mencapai metrik target.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="validation_acc",
goal="Maximize",
max_total_trials=8,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)Sekarang, Anda dapat mengirimkan pekerjaan ini seperti sebelumnya. Kali ini, Anda akan menjalankan pekerjaan pembersihan yang menyapu pekerjaan kereta Anda.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)Anda dapat memantau pekerjaan dengan menggunakan tautan antarmuka pengguna studio yang disajikan selama pekerjaan berjalan.
Menemukan dan mendaftarkan model terbaik
Setelah semua eksekusi selesai, Anda dapat menemukan eksekusi yang menghasilkan model dengan akurasi tertinggi.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "model"
path="azureml://jobs/{}/outputs/artifacts/paths/outputs/model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="custom_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)Anda kemudian dapat mendaftarkan model ini.
registered_model = ml_client.models.create_or_update(model=model)Menyebarkan model sebagai titik akhir online
Setelah mendaftarkan model, Anda dapat menyebarkannya sebagai titik akhir online—yaitu, sebagai layanan web di cloud Azure.
Untuk menyebarkan layanan pembelajaran mesin, Anda biasanya memerlukan:
- Aset model yang ingin Anda sebarkan. Aset ini mencakup file model dan metadata yang sudah Anda daftarkan dalam pekerjaan pelatihan Anda.
- Beberapa kode yang akan dijalankan sebagai layanan. Kode menjalankan model pada permintaan input tertentu (skrip entri). Skrip entri ini menerima data yang dikirimkan ke layanan web yang disebarkan dan meneruskannya ke model. Setelah model memproses data, skrip mengembalikan respons model ke klien. Skrip khusus untuk model Anda dan harus memahami data yang diharapkan dan dikembalikan model. Saat Anda menggunakan model MLFlow, Azure Pembelajaran Mesin secara otomatis membuat skrip ini untuk Anda.
Untuk informasi selengkapnya tentang penyebaran, lihat Menyebarkan dan menilai model pembelajaran mesin dengan titik akhir online terkelola menggunakan Python SDK v2.
Membuat titik akhir online baru
Sebagai langkah pertama untuk menyebarkan model, Anda perlu membuat titik akhir online Anda. Nama titik akhir harus unik di seluruh wilayah Azure. Untuk artikel ini, Anda membuat nama unik menggunakan pengidentifikasi unik universal (UUID).
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "tff-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using TensorFlow",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")Setelah membuat titik akhir, Anda dapat mengambilnya sebagai berikut:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)Menyebarkan model ke titik akhir
Setelah membuat titik akhir, Anda dapat menyebarkan model dengan skrip entri. Titik akhir dapat memiliki beberapa penyebaran. Dengan menggunakan aturan, titik akhir kemudian dapat mengarahkan lalu lintas ke penyebaran ini.
Dalam kode berikut, Anda membuat satu penyebaran yang menangani 100% lalu lintas masuk. Kami menggunakan nama warna arbitrer (tff-blue) untuk penyebaran. Anda juga dapat menggunakan nama lain seperti tff-green atau tff-red untuk penyebaran. Kode untuk menyebarkan model ke titik akhir melakukan hal berikut:
- menyebarkan versi terbaik dari model yang Anda daftarkan sebelumnya;
- menilai model, menggunakan
score.pyfile; dan - menggunakan lingkungan yang dikumpulkan yang sama (yang Anda nyatakan sebelumnya) untuk melakukan inferensi.
model = registered_model
from azure.ai.ml.entities import CodeConfiguration
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="tff-blue",
endpoint_name=online_endpoint_name,
model=model,
code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
environment=curated_env_name,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Catatan
Harapkan penyebaran ini membutuhkan sedikit waktu untuk menyelesaikannya.
Menguji penyebaran dengan kueri sampel
Setelah menyebarkan model ke titik akhir, Anda dapat memprediksi output model yang disebarkan, menggunakan invoke metode pada titik akhir. Untuk menjalankan inferensi, gunakan file sample-request.json permintaan sampel dari folder permintaan .
# # predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request/sample-request.json",
deployment_name="tff-blue",
)Anda kemudian dapat mencetak prediksi yang dikembalikan dan memplotnya bersama dengan gambar input. Gunakan warna font merah dan gambar terbalik (putih pada hitam) untuk menyoroti sampel yang salah diklasifikasikan.
# compare actual value vs. the predicted values:
import matplotlib.pyplot as plt
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Catatan
Karena akurasi model tinggi, Anda mungkin harus menjalankan sel beberapa kali sebelum melihat sampel yang salah diklasifikasikan.
Membersihkan sumber daya
Jika Anda tidak akan menggunakan titik akhir, hapus untuk berhenti menggunakan sumber daya. Pastikan tidak ada penyebaran lain yang menggunakan titik akhir sebelum Anda menghapusnya.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Catatan
Harapkan pembersihan ini membutuhkan sedikit waktu untuk menyelesaikannya.
Langkah berikutnya
Dalam artikel ini, Anda melatih dan mendaftarkan model TensorFlow. Anda juga menyebarkan model ke titik akhir online. Lihat artikel lainnya ini untuk mempelajari selengkapnya tentang Azure Machine Learning.