Peringkat semantik di Azure AI Search
Dalam Azure AI Search, peringkat semantik secara terukur meningkatkan relevansi pencarian dengan menggunakan pemahaman bahasa untuk mererank hasil pencarian. Artikel ini adalah pengantar tingkat tinggi. Bagian di akhir mencakup ketersediaan dan harga.
Peringkat semantik adalah fitur premium, ditagih berdasarkan penggunaan. Kami menyarankan artikel ini untuk latar belakang, tetapi jika Anda lebih suka memulai, ikuti langkah-langkah berikut:
- Periksa ketersediaan regional
- Masuk ke portal Azure untuk memverifikasi bahwa layanan pencarian Anda adalah Dasar atau lebih tinggi
- Aktifkan peringkat semantik dan pilih paket harga
- Menyiapkan konfigurasi semantik dalam indeks pencarian
- Menyiapkan kueri untuk mengembalikan keterangan dan sorotan semantik
- Secara opsional, kembalikan jawaban semantik
Catatan
Peringkat semantik tidak menggunakan AI atau vektor generatif. Jika Anda mencari dukungan vektor dan pencarian kesamaan? Lihat Pencarian vektor di Pencarian Azure AI untuk detailnya.
Apa itu peringkat semantik?
Peringkat semantik adalah kumpulan kemampuan terkait kueri yang meningkatkan kualitas hasil pencarian berpangkat BM25 awal atau berpangkat RRF untuk kueri berbasis teks. Saat Anda mengaktifkannya di layanan pencarian, peringkat semantik memperluas alur eksekusi kueri dengan dua cara:
Pertama, ia menambahkan peringkat sekunder atas kumpulan hasil awal yang dinilai menggunakan BM25 atau RRF. Peringkat sekunder ini menggunakan model pembelajaran mendalam multibahasa yang diadaptasi dari Microsoft Bing untuk mempromosikan hasil yang paling relevan secara semantik.
Kedua, fitur ini mengekstrak dan mengembalikan keterangan dan jawaban dalam respons yang dapat Anda render pada halaman pencarian untuk meningkatkan pengalaman pencarian pengguna.
Berikut adalah kemampuan reranker semantik.
| Fitur | Deskripsi |
|---|---|
| Pangkat semantik | Menggunakan konteks atau arti semantik dari kueri untuk menghitung skor relevansi baru atas hasil yang telah diprakarsai sebelumnya. |
| Keterangan dan sorotan semantik | Mengekstrak kalimat dan frasa verbatim dari dokumen yang paling baik meringkas konten, dengan sorotan atas bagian kunci untuk pemindaian yang mudah. Keterangan yang meringkas hasil berguna saat bidang konten individual terlalu padat untuk halaman hasil pencarian. Teks yang disorot meningkatkan istilah dan frasa yang paling relevan agar pengguna dapat dengan cepat menentukan mengapa kecocokan dianggap relevan. |
| Jawaban semantik | Substruktur opsional dan ekstra yang dikembalikan dari kueri semantik. Ini memberikan jawaban langsung ke kueri yang terlihat seperti pertanyaan. Ini mengharuskan dokumen memiliki teks dengan karakteristik jawaban. |
Cara kerja pemeringkat semantik
Peringkat semantik memberi umpan kueri dan hasil ke model pemahaman bahasa yang dihosting oleh Microsoft dan memindai untuk kecocokan yang lebih baik.
Ilustrasi berikut menjelaskan konsepnya. Pertimbangkan istilah "modal". Ini memiliki arti yang berbeda tergantung pada apakah konteksnya adalah keuangan, hukum, geografi, atau tata bahasa. Melalui pemahaman bahasa, peringkat semantik dapat mendeteksi konteks dan mempromosikan hasil yang sesuai dengan niat kueri.
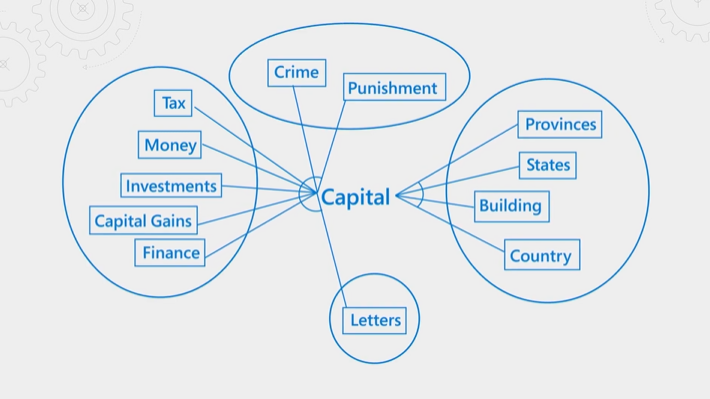
Peringkat semantik adalah sumber daya dan waktu intensif. Untuk menyelesaikan pemrosesan dalam latensi yang diharapkan dari operasi kueri, input ke ranker semantik dikonsolidasikan dan dikurangi sehingga langkah reranking dapat diselesaikan secepat mungkin.
Ada dua langkah untuk peringkat semantik: ringkasan dan penilaian. Output terdiri dari hasil, keterangan, dan jawaban yang dikoreksi ulang.
Cara input dikumpulkan dan dirangkum
Dalam peringkat semantik, subsistem kueri meneruskan hasil pencarian sebagai input ke model ringkasan dan peringkat. Karena model peringkat memiliki batasan ukuran input dan sedang memproses intensif, hasil pencarian harus berukuran dan terstruktur (dirangkum) untuk penanganan yang efisien.
Peringkat semantik dimulai dengan hasil berperingkat BM25 dari kueri teks atau hasil berperingkat RRF dari kueri hibrid. Hanya bidang teks yang digunakan dalam latihan reranking, dan hanya 50 hasil teratas yang mengalami kemajuan ke peringkat semantik, bahkan jika hasil menyertakan lebih dari 50. Biasanya, bidang yang digunakan dalam peringkat semantik bersifat informasi dan deskriptif.
Untuk setiap dokumen dalam hasil pencarian, model ringkasan menerima hingga 2.000 token, di mana token sekitar 10 karakter. Input dirakit dari bidang "judul", "kata kunci", dan "konten" yang tercantum dalam konfigurasi semantik.
String yang terlalu panjang dipangkas untuk memastikan panjang keseluruhan memenuhi persyaratan input langkah ringkasan. Latihan pemangkasan ini adalah mengapa penting untuk menambahkan bidang ke konfigurasi semantik Anda dalam urutan prioritas. Jika Anda memiliki dokumen yang sangat besar dengan bidang teks-berat, apa pun setelah batas maksimum diabaikan.
Bidang semantik Batas token "judul" 128 token "kata kunci 128 token "konten" token yang tersisa Output ringkasan adalah string ringkasan untuk setiap dokumen, terdiri dari informasi yang paling relevan dari setiap bidang. String ringkasan dikirim ke ranker untuk penilaian, dan ke model pemahaman pembacaan mesin untuk keterangan dan jawaban.
Panjang maksimum setiap string ringkasan yang dihasilkan yang diteruskan ke ranker semantik adalah 256 token.
Output ranker semantik
Dari setiap string ringkasan, model pemahaman pembacaan mesin menemukan bagian yang paling representatif.
Outputnya adalah:
Keterangan semantik untuk dokumen. Setiap keterangan tersedia dalam versi teks biasa dan versi sorotan, dan sering kurang dari 200 kata per dokumen.
Jawaban semantik opsional, dengan asumsi Anda menentukan
answersparameter, kueri diajukan sebagai pertanyaan, dan bagian ditemukan dalam string panjang yang memberikan kemungkinan jawaban atas pertanyaan.
Keterangan dan jawaban selalu teks verbatim dari indeks Anda. Tidak ada model AI generatif dalam alur kerja ini yang membuat atau menyusun konten baru.
Bagaimana ringkasan dinilai
Penilaian dilakukan melalui keterangan, dan konten lain dari string ringkasan yang mengisi panjang token 256.
Keterangan dievaluasi untuk relevansi konseptual dan semantik, relatif terhadap kueri yang disediakan.
@search.rerankerScore ditetapkan ke setiap dokumen berdasarkan relevansi semantik dokumen untuk kueri yang diberikan. Skor berkisar dari 4 hingga 0 (tinggi hingga rendah), di mana skor yang lebih tinggi menunjukkan relevansi yang lebih tinggi.
Kecocokan tercantum dalam urutan turun berdasarkan skor dan disertakan dalam payload respons kueri. Muatan mencakup jawaban, teks biasa, dan keterangan yang disorot, dan bidang apa pun yang Anda tandai sebagai dapat diambil atau ditentukan dalam klausa tertentu.
Catatan
Mulai 14 Juli 2023, distribusi @search.rerankerScore berubah. Efek pada skor tidak dapat ditentukan kecuali melalui pengujian. Jika Anda memiliki dependensi ambang batas yang keras pada properti respons ini, jalankan ulang pengujian Anda untuk memahami nilai baru untuk ambang batas Anda.
Kemampuan dan batasan semantik
Peringkat semantik adalah teknologi yang lebih baru sehingga penting untuk menetapkan harapan tentang apa yang dapat dan tidak dapat dilakukan. Apa yang dapat dilakukannya:
Promosikan kecocokan yang secara semantik lebih dekat dengan niat kueri asli.
Temukan string untuk digunakan sebagai keterangan dan jawaban. Keterangan dan jawaban dikembalikan dalam respons dan dapat dirender di halaman hasil pencarian.
Peringkat semantik apa yang tidak dapat dilakukan adalah menjalankan ulang kueri di seluruh korpus untuk menemukan hasil yang relevan secara semantik. Peringkat semantik mereranks set hasil yang ada, yang terdiri dari 50 hasil teratas sebagaimana dinilai oleh algoritma peringkat default. Selain itu, peringkat semantik tidak dapat membuat informasi atau string baru. Keterangan dan jawaban diekstrak verbatim dari konten Anda sehingga jika hasilnya tidak menyertakan teks seperti jawaban, model bahasa tidak akan menghasilkannya.
Meskipun peringkat semantik tidak bermanfaat dalam setiap skenario, konten tertentu dapat memperoleh manfaat secara signifikan dari kemampuannya. Model bahasa dalam peringkat semantik bekerja paling baik pada konten yang dapat dicari yang kaya informasi dan terstruktur sebagai prosa. Basis pengetahuan, dokumentasi online, atau dokumen yang berisi konten deskriptif melihat keuntungan terbanyak dari kemampuan peringkat semantik.
Teknologi yang mendasar berasal dari Bing dan Microsoft Research, dan diintegrasikan ke dalam infrastruktur Azure AI Search sebagai fitur add-on. Untuk informasi selengkapnya tentang riset dan investasi AI yang mendukung peringkat semantik, lihat Bagaimana AI dari Bing mendukung Azure AI Search (Blog Penelitian Microsoft).
Video berikut memberikan gambaran umum tentang kemampuan.
Availabilitas dan harga
Peringkat semantik tersedia pada layanan pencarian di tingkat Dasar dan yang lebih tinggi, tergantung pada ketersediaan regional.
Saat Anda mengaktifkan pemeringkat semantik, pilih paket harga untuk fitur tersebut:
- Pada volume kueri yang lebih rendah (di bawah 1000 bulanan), peringkat semantik gratis.
- Pada volume kueri yang lebih tinggi, pilih paket harga standar.
Halaman harga Azure AI Search menunjukkan tingkat penagihan untuk mata uang dan interval yang berbeda.
Biaya untuk peringkat semantik dipungut saat permintaan kueri disertakan queryType=semantic dan string pencarian tidak kosong (misalnya, search=pet friendly hotels in New York). Jika string pencarian Anda kosong (search=*), Anda tidak dikenakan biaya, bahkan jika queryType diatur ke semantik.