Praktik terbaik untuk menggunakan Azure Data Lake Storage Gen2
Artikel ini memberikan panduan praktik terbaik yang membantu Anda mengoptimalkan kinerja, mengurangi biaya, dan mengamankan akun Azure Storage yang diaktifkan Data Lake Storage Gen2.
Untuk saran umum seputar penataan data lake, lihat artikel ini:
- Ringkasan Azure Data Lake Storage untuk manajemen data dan skenario analitik
- Sediakan tiga akun Azure Data Lake Storage Gen2 untuk setiap zona pendaratan data
Cari dokumentasi
Azure Data Lake Storage Gen2 bukan layanan atau jenis akun khusus. Ini adalah serangkaian kemampuan yang mendukung beban kerja analitik throughput tinggi. Dokumentasi Data Lake Storage Gen2 memberikan praktik dan panduan terbaik untuk menggunakan kemampuan ini. Untuk semua aspek lain dari manajemen akun seperti menyiapkan keamanan jaringan, merancang ketersediaan tinggi, dan pemulihan bencana, lihat konten dokumentasi penyimpanan Blob.
Mengevaluasi dukungan fitur dan masalah yang diketahui
Gunakan pola berikut saat Anda mengonfigurasi akun Anda untuk menggunakan fitur penyimpanan Blob.
Tinjau dukungan fitur Blob Storage di artikel akun Azure Storage untuk menentukan apakah fitur didukung sepenuhnya di akun Anda. Beberapa fitur belum didukung atau memiliki dukungan parsial di akun yang diaktifkan Data Lake Storage Gen2. Dukungan fitur selalu berkembang, jadi pastikan untuk meninjau artikel ini secara berkala untuk pembaruan.
Tinjau masalah yang diketahui dengan artikel Azure Data Lake Storage Gen2 untuk melihat apakah ada batasan atau panduan khusus di sekitar fitur yang ingin Anda gunakan.
Pindai artikel fitur untuk panduan apa pun yang khusus untuk akun yang diaktifkan Data Lake Storage Gen2.
Memahami istilah yang digunakan dalam dokumentasi
Saat Anda berpindah di antara set konten, Anda melihat beberapa perbedaan terminologi sedikit. Misalnya, konten yang ditampilkan dalam dokumentasi penyimpanan Blob, akan menggunakan istilah blob, bukan file. Secara teknis, file yang Anda serap ke akun penyimpanan Anda menjadi blob di akun Anda. Oleh karena itu, istilah ini benar. Namun, istilah blob dapat menyebabkan kebingungan jika Anda terbiasa dengan istilah file. Anda juga akan melihat istilah kontainer yang digunakan untuk merujuk ke sistem file. Anggap istilah-istilah ini sebagai sinonim.
Pertimbangkan premium
Jika beban kerja Anda memerlukan latensi konsisten yang rendah dan/atau memerlukan sejumlah besar operasi output input per detik (IOP), pertimbangkan untuk menggunakan akun penyimpanan blob blok premium. Jenis akun ini membuat data tersedia melalui perangkat keras dengan performa tinggi. Data disimpan pada solid-state drive (SSD) yang dioptimalkan untuk latensi rendah. SSD menyediakan throughput yang lebih tinggi dibanding hard drive tradisional. Biaya penyimpanan performa premium lebih tinggi, tetapi biaya transaksi lebih rendah. Oleh karena itu, jika beban kerja Anda menjalankan sejumlah besar transaksi, akun blob blok performa premium bisa ekonomis.
Jika akun penyimpanan Anda akan digunakan untuk analitik, kami sangat menyarankan agar Anda menggunakan Azure Data Lake Storage Gen2 bersama dengan akun penyimpanan blob blok premium. Kombinasi penggunaan akun penyimpanan blob blok premium bersama dengan akun yang mendukung Storage Data Lake ini disebut sebagai tingkat premium untuk Azure Data Lake Storage.
Optimalkan untuk konsumsi data
Saat mengkonsumsi data dari sistem sumber, perangkat keras sumber, perangkat keras jaringan sumber, atau konektivitas jaringan ke akun penyimpanan Anda dapat menjadi hambatan.
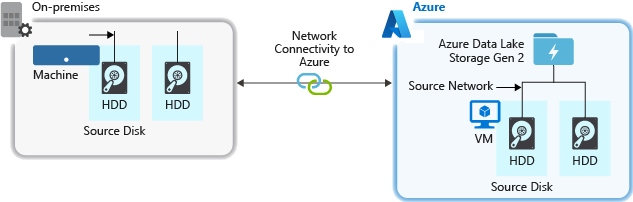
Perangkat keras sumber
Baik Anda menggunakan komputer lokal atau Komputer Virtual (VM) di Azure, pastikan untuk memilih perangkat keras yang sesuai dengan hati-hati. Untuk perangkat keras disk, pertimbangkan untuk menggunakan Solid State Drives (SSD) dan pilih perangkat keras disk yang memiliki spindle lebih cepat. Untuk perangkat keras jaringan, gunakan Network Interface Controllers (NIC) yang paling cepat. Di Azure, kami merekomendasikan Azure D14 VM yang memiliki perangkat keras disk dan jaringan yang sesuai.
Memverifikasi konektivitas jaringan ke akun penyimpanan
Konektivitas jaringan antara data sumber dan akun penyimpanan Anda terkadang bisa menjadi hambatan. Bila data sumber Anda lokal, pertimbangkan untuk menggunakan tautan khusus dengan Azure ExpressRoute. Jika data sumber Anda ada di Azure, kinerjanya paling baik saat data berada di wilayah Azure yang sama dengan akun yang diaktifkan Penyimpanan Data Lake Gen2 Anda.
Konfigurasikan alat penyerapan data untuk paralelisasi maksimum
Untuk mencapai kinerja terbaik, gunakan semua throughput yang tersedia dengan melakukan sebanyak mungkin baca dan tulis secara paralel.
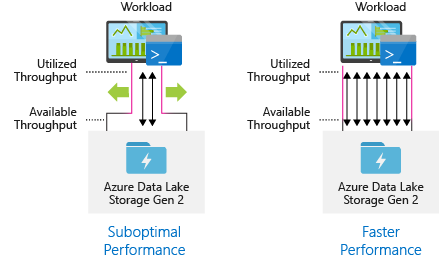
Tabel berikut merangkum pengaturan utama untuk beberapa alat penyerapan data populer.
| Alat | Pengaturan |
|---|---|
| DistCp | -m (pemeta) |
| Azure Data Factory | parallelCopies |
| Sqoop | fs.azure.block.size, -m (pemeta) |
Catatan
Performa keseluruhan operasi penyerapan Anda bergantung pada faktor lain yang khusus untuk alat yang Anda gunakan untuk menyerap data. Untuk panduan terbaru terbaik, lihat dokumentasi untuk setiap alat yang ingin Anda gunakan.
Akun Anda dapat diskalakan untuk menyediakan throughput yang diperlukan untuk semua skenario analitik. Secara default, akun yang diaktifkan Data Lake Storage Gen2 menyediakan throughput yang cukup dalam konfigurasi defaultnya untuk memenuhi kebutuhan kategori kasus penggunaan yang luas. Jika Anda mencapai batas default, akun dapat dikonfigurasi untuk memberikan lebih banyak throughput dengan menghubungi Dukungan Azure.
Struktur kumpulan data
Pertimbangkan praperencanaan struktur data Anda. Format file, ukuran file, dan struktur direktori semuanya dapat memengaruhi performa dan biaya.
Format file
Data dapat dikonsumsi dalam berbagai format. Data dapat muncul dalam format yang dapat dibaca manusia seperti JSON, CSV, atau XML atau sebagai format biner terkompresi seperti .tar.gz. Data juga bisa hadir dalam berbagai ukuran. Data dapat terdiri dari file berukuran besar (beberapa terabyte), seperti data dari ekspor tabel SQL dari sistem lokal Anda. Data juga bisa datang dalam bentuk sejumlah besar file kecil (beberapa kilobyte) seperti data dari peristiwa waktu nyata dari solusi Internet of things (IoT). Anda dapat mengoptimalkan efisiensi dan biaya dengan memilih format file dan ukuran file yang sesuai.
Hadoop mendukung serangkaian format file yang dioptimalkan untuk menyimpan dan memproses data terstruktur. Beberapa format yang umum adalah format Avro, Parket, dan Optimized Row Columnar (ORC). Semua format ini adalah format file biner yang dapat dibaca komputer. Mereka dikompresi untuk membantu Anda mengelola ukuran file. Mereka memiliki skema yang disematkan di setiap file, yang membuatnya mendeskripsikan diri sendiri. Perbedaan antara format ini adalah bagaimana data disimpan. Avro menyimpan data dalam format berbasis baris dan format Parket dan ORC menyimpan data dalam format kolom.
Pertimbangkan untuk menggunakan format file Avro dalam kasus di mana pola I/O Anda lebih banyak menulis, atau pola kueri mendukung pengambilan beberapa baris catatan secara keseluruhan. Misalnya, format Avro berfungsi dengan baik dengan bus pesan seperti Azure Event Hubs atau Kafka yang menulis beberapa peristiwa/pesan secara berturut-turut.
Pertimbangkan format file Parquet dan ORC saat pola I/O lebih banyak dibaca atau saat pola kueri difokuskan pada subkumpulan kolom dalam catatan. Transaksi baca dapat dioptimalkan untuk mengambil kolom tertentu sebagai ganti membaca seluruh catatan.
Apache Parquet adalah format file sumber terbuka yang dioptimalkan untuk membaca pipa analitik berat. Struktur penyimpanan kolumnar Parquet memungkinkan Anda melewati data yang tidak relevan. Kueri Anda jauh lebih efisien karena mereka dapat secara sempit membatasi data mana yang akan dikirim dari penyimpanan ke mesin analitik. Juga, karena tipe data yang serupa (untuk kolom) disimpan bersama, Parquet mendukung kompresi data yang efisien dan skema pengkodean yang dapat menurunkan biaya penyimpanan data. Layanan seperti Azure Synapse Analytics,Azure Databricks, dan Azure Data Factory memiliki fungsi asli yang memanfaatkan format file Parquet.
Ukuran file
File yang lebih besar menghasilkan performa yang lebih baik dan mengurangi biaya.
Biasanya, komputer analitik seperti HDInsight memiliki overhead per file yang melibatkan tugas-tugas seperti membuat daftar, memeriksa akses, dan melakukan berbagai operasi metadata. Jika Anda menyimpan banyak data file kecil, ini dapat berdampak negatif pada kinerja. Secara umum, atur data Anda ke dalam file berukuran lebih besar untuk performa yang lebih baik (berukuran 256 MB hingga 100 GB). Beberapa komputer dan aplikasi mungkin mengalami kesulitan memproses file secara efisien yang berukuran lebih dari 100 GB.
Meningkatkan ukuran file juga dapat mengurangi biaya transaksi. Operasi baca dan tulis ditagih dalam peningkatan 4 megabyte sehingga Anda akan dikenakan biaya untuk operasi apakah file tersebut berisi 4 megabyte atau hanya beberapa kilobyte. Untuk informasi harga, lihat Harga Azure Data Lake Storage.
Terkadang, alur data memiliki kontrol terbatas atas data mentah, yang memiliki banyak file kecil. Secara umum, kami menyarankan agar sistem Anda memiliki semacam proses agregasi file kecil menjadi lebih besar untuk digunakan oleh aplikasi hilir. Jika memproses data secara real time, Anda dapat menggunakan mesin streaming real time (seperti Azure Stream Analytics atau Spark Streaming) bersama dengan broker pesan (seperti Event Hubs atau Apache Kafka) untuk menyimpan data Anda sebagai file yang lebih besar. Saat Anda menggabungkan file kecil menjadi file yang lebih besar, pertimbangkan untuk menyimpannya dalam format yang dioptimalkan untuk pembacaan seperti Apache Parquet untuk pemrosesan downstream.
Struktur direktori
Setiap beban kerja memiliki persyaratan berbeda tentang cara data dikonsumsi, tetapi ini adalah beberapa tata letak umum yang perlu dipertimbangkan saat bekerja dengan Internet of Things (IoT), skenario batch, atau saat mengoptimalkan data deret waktu.
Struktur IoT
Dalam beban kerja IoT, terdapat sejumlah besar data yang diserap yang tersebar di sejumlah produk, perangkat, organisasi, dan pelanggan. Penting untuk merencanakan tata letak direktori di awal untuk organisasi, keamanan, dan pemrosesan data yang efisien untuk konsumen hilir. Template umum yang perlu dipertimbangkan mungkin adalah tata letak berikut:
- {Region}/{SubjectMatter(s)}/{yyyy}/{mm}/{dd}/{hh}/
Misalnya, struktur telemetri pendaratan untuk pesawat di Inggris mungkin akan terlihat seperti berikut:
- UK/Planes/BA1293/Engine1/2017/08/11/12/
Dalam contoh ini, dengan menempatkan tanggal di akhir struktur direktori, Anda dapat menggunakan ACL untuk mengamankan wilayah dan subjek penting bagi pengguna dan grup tertentu dengan lebih mudah. Jika Anda meletakkan struktur tanggal di awal, akan jauh lebih sulit untuk mengamankan wilayah dan subjek ini. Misalnya, jika Anda ingin menyediakan akses hanya ke data Inggris atau bidang tertentu, Anda harus menerapkan izin terpisah untuk berbagai direktori di bawah direktori setiap jam. Struktur ini juga akan meningkatkan jumlah direktori dengan pesat seiring berjalannya waktu.
Struktur pekerjaan batch
Pendekatan yang umum digunakan dalam pemrosesan batch adalah dengan menempatkan data ke dalam direktori "in". Kemudian, setelah data diproses, masukkan data baru ke direktori "out" untuk dikonsumsi proses hilir. Struktur direktori ini terkadang digunakan untuk pekerjaan yang memerlukan pemrosesan file individu dan mungkin tidak memerlukan pemrosesan paralel besar-besaran pada himpunan data besar. Seperti struktur IoT yang direkomendasikan di atas, struktur direktori yang baik memiliki direktori tingkat induk untuk hal-hal seperti wilayah dan subjek penting (misalnya, organisasi, produk, atau produsen). Pertimbangkan tanggal dan waktu dalam struktur untuk memungkinkan organisasi, pencarian terfilter, keamanan, dan otomatisasi yang lebih baik dalam pemrosesan. Tingkat granuralitas untuk struktur tanggal ditentukan oleh interval di mana data diunggah atau diproses, seperti per jam, hari, atau bahkan bulan.
Terkadang pemrosesan file tidak berhasil karena rusaknya data atau format yang tidak terduga. Dalam kasus seperti itu, struktur direktori mungkin mendapat keuntungan dengan memindahkan file ke folder /bad untuk pemeriksaan lebih lanjut. Pekerjaan batch mungkin juga menangani pelaporan atau pemberitahuan file-file buruk ini untuk intervensi manual. Mempertimbangkan struktur templat berikut ini:
- {Region}/{SubjectMatter(s)}/In/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Out/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Bad/{yyyy}/{mm}/{dd}/{hh}/
Misalnya, sebuah perusahaan pemasaran menerima ekstrak data harian pembaruan pelanggan dari klien mereka di Amerika Utara. Proses sebelum dan sesudahnya mungkin akan terlihat seperti cuplikan berikut:
- NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csv
- NA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
Dalam kasus umum data batch diproses langsung ke dalam database seperti Apache Hive atau database SQL tradisional, direktori /in atau /out tidak diperlukan karena output sudah masuk ke folder terpisah untuk tabel Apache Hive atau database eksternal. Misalnya, ekstrak harian dari pelanggan akan berakhir di direktori masing-masing. Kemudian, layanan seperti Azure Data Factory, Apache Oozie, atau Apache Airflow akan memicu pekerjaan Apache Hive atau Spark harian untuk memproses dan menulis data ke dalam tabel Hive.
Struktur data deret waktu
Untuk beban kerja Apache Hive, pemangkasan partisi data deret waktu dapat membantu beberapa kueri hanya membaca sebagian data, yang akan meningkatkan kinerja.
Saluran pipa yang menyerap data deret waktu, sering kali menempatkan file mereka dengan penamaan terstruktur untuk file dan folder. Di bawah ini adalah contoh yang umum kita lihat untuk data yang disusun berdasarkan tanggal:
/DataSet/YYYY/MM/DD/datafile_YYYY_MM_DD.tsv
Perhatikan bahwa informasi datetime muncul sebagai folder dan nama file.
Untuk tanggal dan waktu, berikut ini adalah pola umum
/DataSet/YYYY/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
Sekali lagi, pilihan yang Anda buat dengan folder dan organisasi file harus dioptimalkan untuk ukuran file yang lebih besar dan jumlah file yang wajar di setiap folder.
Menyiapkan keamanan
Mulailah dengan meninjau rekomendasi di artikel Rekomendasi keamanan untuk penyimpanan Blob. Anda akan menemukan panduan praktik terbaik tentang cara melindungi data Anda dari penghapusan yang tidak disengaja atau berbahaya, mengamankan data di belakang firewall, dan menggunakan ID Microsoft Entra sebagai dasar manajemen identitas.
Kemudian, tinjau artikel Model kontrol akses di Azure Data Lake Storage Gen2 untuk panduan yang khusus untuk akun yang diaktifkan Data Lake Storage Gen2. Artikel ini membantu Anda memahami cara menggunakan peran kontrol akses berbasis peran Azure (Azure RBAC) bersama dengan daftar kontrol akses (ACL) untuk menerapkan izin keamanan pada direktori dan file di sistem file hierarki Anda.
Menyerap, memproses, dan menganalisis
Ada banyak sumber data yang berbeda dan cara yang berbeda yang mana data tersebut dapat diserap ke dalam akun yang diaktifkan Data Lake Storage Gen2.
Misalnya, Anda dapat menyerap set besar data dari kluster HDInsight dan Hadoop atau set yang lebih kecil dari data ad hoc untuk aplikasi prototyping. Anda dapat menyerap data streaming yang dibuat oleh berbagai sumber seperti aplikasi, perangkat, dan sensor. Untuk jenis data ini, Anda dapat menggunakan alat untuk menangkap dan memproses data berdasarkan peristiwa demi peristiwa secara real time, lalu menulis peristiwa dalam batch ke akun Anda. Anda juga dapat menyerap log server web yang berisi informasi seperti riwayat permintaan halaman. Untuk data log, pertimbangkan untuk menulis skrip atau aplikasi kustom untuk mengunggahnya sehingga Anda akan memiliki fleksibilitas untuk menyertakan komponen pengunggahan data sebagai bagian dari aplikasi data besar Anda yang lebih besar.
Setelah data tersedia di akun, Anda dapat menjalankan analisis pada data tersebut, membuat visualisasi, dan bahkan mengunduh data ke komputer lokal Anda atau ke repositori lain seperti database Azure SQL atau instans SQL Server.
Tabel berikut merekomendasikan alat yang dapat Anda gunakan untuk menyerap, menganalisis, memvisualisasikan, dan mengunduh data. Gunakan tautan dalam tabel ini untuk menemukan panduan tentang cara mengonfigurasi dan menggunakan setiap alat.
| Tujuan | Panduan Alat & Alat |
|---|---|
| Menyerap data ad hoc | Azure portal, Azure PowerShell, Azure CLI, REST, Azure Storage Explorer, Apache DistCp, AzCopy |
| Menyerap data relasional | Azure Data Factory |
| Menyerap log server web | Azure PowerShell, Azure CLI, REST, Azure SDKs (.NET, Java, Python, dan Node.js), Azure Data Factory |
| Menyerap dari kluster HDInsight | Azure Data Factory, Apache DistCp, AzCopy |
| Menyerap dari kluster Hadoop | Azure Data Factory, Apache DistCp, WANdisco LiveData Migrator for Azure, Azure Data Box |
| Menyerap himpunan data besar (beberapa terabyte) | Azure ExpressRoute |
| Memproses & menganalisis data | Azure Synapse Analytics, Azure HDInsight, Databricks |
| Memvisualisasikan data | Power BI, Akselerasi kueri Azure Data Lake Storage |
| Mengunduh data | Portal Azure, PowerShell, Azure CLI, REST, Azure SDK (.NET, Java, Python, dan Node.js), Azure Storage Explorer, AzCopy, Azure Data Factory, Apache DistCp |
Catatan
Tabel ini tidak mencerminkan daftar lengkap layanan Azure yang mendukung Data Lake Storage Gen2. Untuk daftar layanan Azure yang didukung, serta tingkat dukungannya, lihat Layanan Azure yang mendukung Azure Data Lake Storage Gen2.
Memantau telemetri
Memantau penggunaan dan performa adalah bagian penting untuk mengoperasionalkan layanan Anda. Contohnya termasuk operasi yang sering, operasi dengan latensi tinggi, atau operasi yang menyebabkan pelambatan sisi layanan.
Semua telemetri untuk akun penyimpanan Anda tersedia melalui Log Azure Storage di Azure Monitor. Fitur ini mengintegrasikan akun penyimpanan Anda dengan Analisis Log dan Pusat Aktivitas, sekaligus memungkinkan Anda untuk mengarsipkan log ke akun penyimpanan lain. Untuk melihat daftar lengkap metrik dan log sumber daya serta skema terkaitnya, lihat Referensi data pemantauan Azure Storage.
Di mana Anda memilih untuk menyimpan log Anda tergantung pada bagaimana Anda berencana untuk mengaksesnya. Misalnya, jika Anda ingin mengakses log Anda hampir secara real time, dan dapat menghubungkan peristiwa di log dengan metrik lain dari Azure Monitor, Anda dapat menyimpan log Anda di ruang kerja Log Analytics. Kemudian, kueri log Anda dengan menggunakan kueri KQL dan penulis, yang menghitung StorageBlobLogs tabel di ruang kerja Anda.
Jika Anda ingin menyimpan log untuk kueri hampir real-time dan retensi jangka panjang, Anda dapat mengonfigurasi setelan diagnostik untuk mengirim log ke ruang kerja Log Analytics dan akun penyimpanan.
Jika Anda ingin mengakses log melalui mesin kueri lain seperti Splunk, Anda dapat mengonfigurasi pengaturan diagnostik untuk mengirim log ke pusat aktivitas dan menyerap log dari hub peristiwa ke tujuan yang Anda pilih.
Log Azure Storage di Azure Monitor dapat diaktifkan melalui portal Microsoft Azure, PowerShell, Azure CLI, dan templat Azure Resource Manager. Untuk penerapan skala besar, Azure Policy dapat digunakan dengan dukungan penuh untuk tugas perbaikan. Untuk informasi selengkapnya, lihat ciphertxt/AzureStoragePolicy.