Tutorial: Mengambil data Azure Event Hubs dalam format parquet dan menganalisis dengan Azure Synapse Analytics
Tutorial ini menunjukkan kepada Anda cara menggunakan editor tanpa kode Azure Stream Analytics untuk membuat pekerjaan yang mengambil data Azure Event Hubs untuk Azure Data Lake Storage Gen2 dalam format parkek.
Dalam tutorial ini, Anda akan mempelajari cara:
- Menyebarkan generator peristiwa yang mengirim peristiwa sampel ke pusat aktivitas
- Membuat pekerjaan Analisis Aliran menggunakan editor tanpa kode
- Meninjau data input dan skema
- Mengonfigurasi Azure Data Lake Storage Gen2 ke data hub peristiwa mana yang akan diambil
- Menjalankan pekerjaan Analisis Aliran
- Menggunakan Azure Synapse Analytics untuk mengkueri file parket
Prasyarat
Sebelum memulai, pastikan Anda telah menyelesaikan langkah-langkah berikut:
- Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum memulai.
- Sebarkan aplikasi generator peristiwa TollApp ke Azure. Atur parameter 'interval' ke 1, dan gunakan grup sumber daya baru untuk langkah ini.
- Buat ruang kerja Azure Synapse Analytics dengan akun Data Lake Storage Gen2.
Tidak menggunakan editor kode untuk membuat pekerjaan Azure Stream Analytics
Temukan Grup Sumber Daya tempat generator peristiwa TollApp disebarkan.
Pilih namespace Azure Event Hubs.
Pada halaman Namespace Pusat Aktivitas, pilih Pusat Aktivitas di bawah Entitas pada menu sebelah kiri.
Pilih
entrystreaminstans.
Pada halaman Instans Event Hubs, pilih Proses data di bagian Fitur di menu sebelah kiri.
Pilih Mulai pada petak peta Ambil data ke ADLS Gen2 dalam format Parket.

Beri nama pekerjaan
parquetcaptureAnda dan pilih Buat.
Pada halaman konfigurasi pusat aktivitas, konfirmasikan pengaturan berikut, lalu pilih Sambungkan.
Grup Konsumen: Default
Jenis serialisasi data input Anda: JSON
Mode autentikasi yang akan digunakan pekerjaan untuk menyambungkan ke pusat aktivitas Anda: String koneksi.

Dalam beberapa detik, Anda akan melihat contoh data input dan skema. Anda dapat memilih untuk menghapus bidang, mengganti nama bidang, atau mengubah jenis data.

Pilih petak peta Azure Data Lake Storage Gen2 di kanvas Anda dan konfigurasikan dengan menentukan
- Langganan tempat akun Azure Data Lake Gen2 Anda berada
- Nama akun penyimpanan, yang harus merupakan akun ADLS Gen2 yang sama dengan yang digunakan dengan ruang kerja Azure Synapse Analytics Anda yang dilakukan di bagian Prasyarat.
- Kontainer di mana file Parket akan dibuat.
- Pola jalur diatur ke {date}/{time}
- Pola tanggal dan waktu sebagai default yyyy-mm-dd dan HH.
- Pilih Sambungkan

Pilih Simpan di pita atas untuk menyimpan pekerjaan Anda, lalu pilih Mulai untuk menjalankan pekerjaan Anda. Setelah pekerjaan dimulai, pilih X di sudut kanan untuk menutup halaman pekerjaan Azure Stream Analytics .

Anda kemudian akan melihat daftar semua pekerjaan Analisis Aliran yang dibuat menggunakan editor tanpa kode. Dan dalam dua menit, pekerjaan Anda akan masuk ke status Berjalan. Pilih tombol Refresh pada halaman untuk melihat status berubah dari Dibuat -> Mulai -> Berjalan.









Melihat output di akun Azure Data Lake Storage Gen 2 Anda
Temukan akun Azure Data Lake Storage Gen2 yang telah Anda gunakan di langkah sebelumnya.
Pilih kontainer yang telah Anda buat di langkah sebelumnya. Anda akan melihat file parket yang dibuat berdasarkan pola jalur {date}/{time} yang digunakan pada langkah sebelumnya.
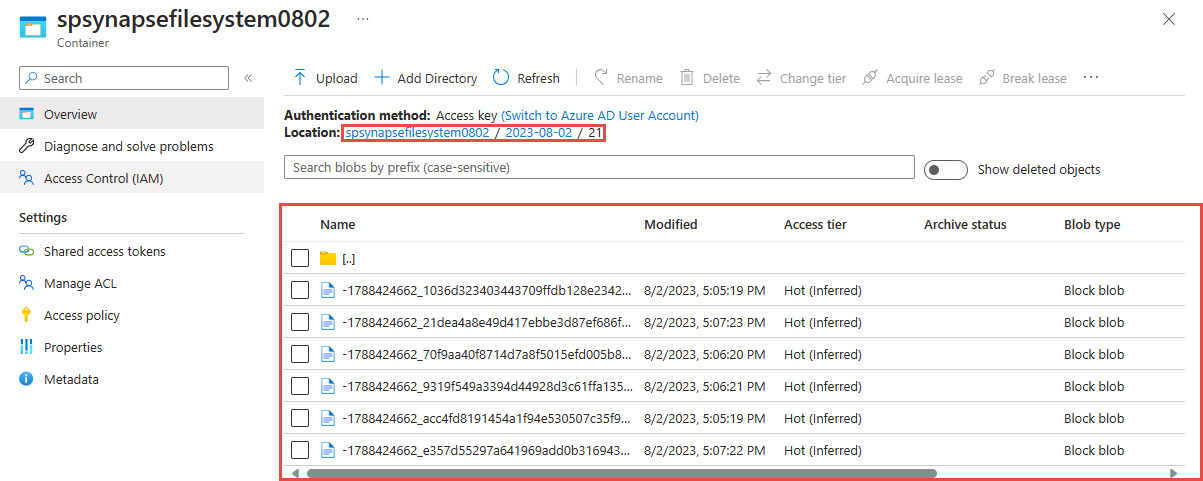
Kueri yang diambil data dalam format Parquet dengan Azure Synapse Analytics
Kueri menggunakan Azure Synapse Spark
Temukan ruang kerja Azure Synapse Analytics Anda dan buka Synapse Studio.
Buat kumpulan Apache Spark tanpa server di ruang kerja Anda jika belum ada.
Di Synapse Studio, buka hub Kembangkan dan buat Notebook baru.
Buat sel kode baru dan tempel kode berikut di sel tersebut: Ganti kontainer dan adlsname dengan nama kontainer dan akun ADLS Gen2 yang digunakan pada langkah sebelumnya.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()Untuk Lampirkan ke pada toolbar, pilih kumpulan Spark Anda dari daftar dropdown.
Pilih Jalankan Semua untuk melihat hasilnya


Kueri menggunakan Azure Synapse Serverless SQL
Di hub Kembangkan, buat skrip SQL baru.
Tempel skrip berikut dan Jalankan menggunakan Bawaan titik akhir SQL tanpa server. Ganti kontainer dan adlsname dengan nama kontainer dan akun ADLS Gen2 yang digunakan pada langkah sebelumnya.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*/*.parquet', FORMAT='PARQUET' ) AS [result]

Membersihkan sumber daya
- Temukan instans Pusat Aktivitas Anda dan lihat daftar pekerjaan Analisis Aliran di bawah bagian Proses Data. Hentikan semua pekerjaan yang sedang berjalan.
- Buka grup sumber daya yang Anda gunakan saat menyebarkan generator peristiwa TollApp.
- Pilih Hapus grup sumber daya. Ketik nama grup sumber daya untuk mengonfirmasi penghapusan.
Langkah berikutnya
Dalam tutorial ini, Anda mempelajari cara membuat tugas Stream Analytics menggunakan editor tanpa kode untuk menangkap aliran data Event Hubs dalam format Parket. Anda kemudian menggunakan Azure Synapse Analytics untuk membuat kueri file parket menggunakan Synapse Spark dan Synapse SQL.