Menyambungkan ke tabel Common Data Model di Azure Data Lake Storage
Catatan
Azure Active Directory kini menjadi Microsoft Entra ID. Pelajari lebih lanjut
Menyerap data untuk Dynamics 365 Customer Insights - Data menggunakan akun Anda Azure Data Lake Storage dengan tabel Common Data Model. Penyerapan data bisa penuh atau bertambah bertahap.
Prasyarat
Namespace Azure Data Lake Storage layanan hierarki akun harus diaktifkan. Data harus disimpan dalam format folder hierarki yang mendefinisikan folder akar dan memiliki subfolder untuk setiap tabel. Subfolder dapat memiliki folder data lengkap atau data inkremental.
Untuk mengautentikasi dengan Microsoft Entra perwakilan layanan, pastikan itu dikonfigurasi di penyewa Anda. Untuk informasi selengkapnya, lihat Menyambungkan ke Azure Data Lake Storage akun dengan Microsoft Entra perwakilan layanan.
Tempat Azure Data Lake Storage Anda ingin menyambungkan dan menyerap data harus berada di wilayah Dynamics 365 Customer Insights Azure yang sama dengan lingkungan dan langganan harus berada di penyewa yang sama. Koneksi ke folder Common Data Model dari Data Lake di kawasan Azure berbeda tidak didukung. Untuk mengetahui wilayah lingkungan Azure, buka Pengaturan>Sistem>Tentang di Customer Insights - Data.
Data yang disimpan dalam layanan online dapat disimpan di lokasi yang berbeda dari tempat data diproses atau disimpan. Dengan mengimpor atau menghubungkan ke data yang disimpan dalam layanan online, Anda setuju bahwa data dapat ditransfer. Pelajari selengkapnya di Pusat Kepercayaan Microsoft.
Perwakilan Customer Insights - Data layanan harus berada dalam salah satu peran berikut untuk mengakses akun penyimpanan. Untuk informasi selengkapnya, lihat Memberikan izin kepada perwakilan layanan untuk mengakses akun penyimpanan.
- Pembaca Data Blob Penyimpanan
- pemilik Data Blob Penyimpanan
- Kontributor data Blob penyimpanan
Saat menyambungkan ke penyimpanan Azure Anda menggunakan opsi langganan Azure, pengguna yang menyiapkan koneksi sumber data memerlukan setidaknya izin kontributor Data Blob Penyimpanan di akun penyimpanan.
Saat menyambungkan ke penyimpanan Azure Anda menggunakan opsi sumber daya Azure, pengguna yang menyiapkan koneksi sumber data memerlukan setidaknya izin untuk tindakan Microsoft.Storage/storageAccounts/read pada akun penyimpanan. Peran bawaan Azure yang menyertakan tindakan ini adalah peran Pembaca. Untuk membatasi akses hanya ke tindakan yang diperlukan,buat peran kustom Azure yang hanya menyertakan tindakan ini.
Untuk kinerja optimal, ukuran partisi harus 1 GB atau kurang dan jumlah file partisi dalam folder tidak boleh melebihi 1000.
Data di Data Lake Storage Anda harus mengikuti standar Common Data Model untuk penyimpanan data Anda dan memiliki manifes Common Data Model untuk mewakili skema file data (*.csv atau *.parquet). Manifes harus memberikan detail tabel seperti kolom tabel dan tipe data, serta lokasi file data dan jenis file. Untuk informasi selengkapnya, lihat Manifes Common Data Model. Jika manifes tidak ada, pengguna Admin dengan pemilik Data Blob Penyimpanan atau akses kontributor Data Blob Penyimpanan dapat menentukan skema saat menyerap data.
Catatan
Jika salah satu bidang dalam berkas .parquet memiliki tipe data Int96, data mungkin tidak ditampilkan pada halaman tabel . Sebaiknya gunakan tipe data standar, seperti format stempel waktu Unix (yang mewakili waktu sebagai jumlah detik sejak 1 Januari 1970, pada tengah malam UTC).
Pembatasan
- Customer Insights - Data tidak mendukung kolom tipe desimal dengan presisi lebih besar dari 16.
Menyambungkan ke Azure Data Lake Storage
Buka Sumber> dataData.
Pilih Tambahkan sumber data.
Pilih tabel Common Data Model Azure Data Lake.

Masukkan nama sumber data dan Deskripsi opsional. Nama ini dirujuk dalam proses hilir dan tidak mungkin mengubahnya setelah membuat sumber data.
Pilih salah satu opsi berikut untuk Hubungkan penyimpanan Anda menggunakan. Untuk informasi selengkapnya, lihat Menyambungkan ke Azure Data Lake Storage akun dengan Microsoft Entra perwakilan layanan.
- Sumber daya Azure: Masukkan Id Sumber Daya. (private-link.md).
- Langganan Azure: Pilih Langganan lalu Grup sumber daya dan Akun penyimpanan.
Catatan
Anda memerlukan salah satu peran berikut ke kontainer untuk membuat sumber data:
- Storage Blob Data Pembaca cukup untuk membaca dari akun penyimpanan dan menyerap data Customer Insights - Data.
- Storage Blob Data kontributor atau Pemilik diperlukan jika Anda ingin mengedit file manifes secara langsung Customer Insights - Data.
Memiliki peran di akun penyimpanan akan memberikan peran yang sama di semua kontainernya.
Secara opsional, jika Anda ingin menyerap data dari akun penyimpanan melalui Azure Private Link, pilih Aktifkan Private Link. Untuk informasi selengkapnya, lihat Private Link.
Pilih nama Kontainer yang berisi data dan skema (file model.json atau manifest.json) untuk mengimpor data, dan pilih Berikutnya.
Catatan
File model.json atau manifest.json yang terkait dengan sumber data lain di lingkungan tidak akan ditampilkan dalam daftar. Namun, file model.json atau manifest.json yang sama dapat digunakan untuk sumber data di beberapa lingkungan.
Untuk membuat skema baru, buka Membuat file skema baru.
Untuk menggunakan skema yang ada, navigasikan ke folder yang berisi file model.json atau manifest.cdm.json. Anda dapat mencari di dalam direktori untuk menemukan file.
Pilih file json dan pilih Berikutnya. Daftar tabel yang tersedia ditampilkan.

Pilih tabel yang ingin Anda sertakan.

Tip
Untuk mengedit tabel di antarmuka pengeditan JSON, pilih tabel lalu Edit file skema. Buat perubahan dan pilih Simpan.
Untuk tabel terpilih yang memerlukan penyerapan inkremental,Tampilan wajib di bagian Refresh bertahap. Untuk setiap tabel ini, lihat Mengonfigurasi refresh bertahap untuk sumber data Azure Data Lake.
Untuk tabel yang dipilih di mana kunci utama belum ditentukan,Diperlukan ditampilkan di bawah Kunci utama. Untuk masing-masing tabel ini:
- Pilih Diperlukan. Panel Edit tabel ditampilkan.
- Pilih Kunci utama. Kunci utama adalah atribut unik untuk tabel. Agar atribut menjadi kunci primer yang valid, ia seharusnya tidak menyertakan nilai duplikat, nilai yang tidak ada, atau nilai null. Atribut tipe data string, integer, dan GUID didukung sebagai kunci utama.
- Secara opsional, ubah pola partisi.
- Pilih Tutup untuk menyimpan dan menutup panel.
Pilih jumlah Kolom untuk setiap tabel yang disertakan. Halaman Kelola atribut akan ditampilkan.

- Buat kolom baru, edit, atau hapus kolom yang ada. Anda dapat mengubah nama, format data, atau menambahkan tipe semantik.
- Untuk mengaktifkan analitik dan kemampuan lainnya, pilih Pembuatan profil data untuk seluruh tabel atau untuk kolom tertentu. Secara default, tidak ada tabel yang diaktifkan untuk pembuatan profil data.
- Pilih Selesai.
Pilih Simpan. Halaman Sumber data terbuka memperlihatkan sumber data baru dalam status Refresh .
Tip
Ada status untuk tugas dan proses. Sebagian besar proses bergantung pada proses hulu lainnya, seperti sumber data dan refresh pembuatanprofil data.
Pilih status untuk membuka panel Detail kemajuan dan melihat kemajuan tugas. Untuk membatalkan pekerjaan, pilih Batalkan pekerjaan di bagian bawah panel.
Di bawah setiap tugas, Anda dapat memilih Lihat detail untuk informasi kemajuan selengkapnya, seperti waktu pemrosesan, tanggal pemrosesan terakhir, serta kesalahan dan peringatan yang berlaku terkait dengan tugas atau proses. Pilih Lihat status sistem di bagian bawah panel untuk melihat proses lain dalam sistem.

Memuat data dapat memakan waktu. Setelah refresh berhasil, data yang diserap dapat ditinjau dari halaman Tabel .
Membuat file skema baru
Pilih Buat file skema.
Masukkan nama untuk file dan pilih Simpan.
Pilih Tabel baru. Panel Tabel Baru ditampilkan.
Masukkan nama tabel dan pilih lokasi File data.
- Beberapa file .csv atau .parquet: Telusuri ke folder akar, pilih jenis pola, dan masukkan ekspresi.
- File .csv atau .parquet tunggal: Telusuri ke file .csv atau .parquet dan pilih.
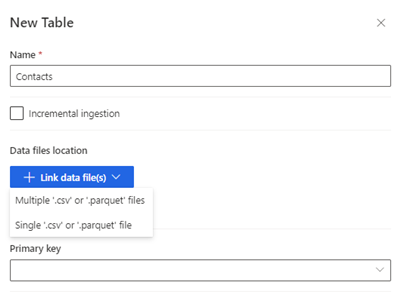
Pilih Simpan.

Pilih tentukan atribut untuk menambahkan atribut secara manual, atau pilih buat atribut secara otomatis. Untuk menentukan atribut, masukkan nama, pilih format data dan jenis semantik opsional. Untuk atribut yang dibuat secara otomatis:
Setelah atribut dibuat secara otomatis, pilih Tinjau atribut. Halaman Kelola atribut akan ditampilkan.
Pastikan format data sudah benar untuk setiap atribut.
Untuk mengaktifkan analitik dan kemampuan lainnya, pilih Pembuatan profil data untuk seluruh tabel atau untuk kolom tertentu. Secara default, tidak ada tabel yang diaktifkan untuk pembuatan profil data.
Pilih Selesai. Halaman Pilih tabel akan ditampilkan.
Terus tambahkan tabel dan kolom, jika ada.
Setelah semua tabel ditambahkan, pilih Sertakan untuk menyertakan tabel dalam penyerapan sumber data.
Untuk tabel terpilih yang memerlukan penyerapan inkremental,Tampilan wajib di bagian Refresh bertahap. Untuk setiap tabel ini, lihat Mengonfigurasi refresh bertahap untuk sumber data Azure Data Lake.
Untuk tabel yang dipilih di mana kunci utama belum ditentukan,Diperlukan ditampilkan di bawah Kunci utama. Untuk masing-masing tabel ini:
- Pilih Diperlukan. Panel Edit tabel ditampilkan.
- Pilih Kunci utama. Kunci utama adalah atribut unik untuk tabel. Agar atribut menjadi kunci primer yang valid, ia seharusnya tidak menyertakan nilai duplikat, nilai yang tidak ada, atau nilai null. Atribut tipe data string, integer, dan GUID didukung sebagai kunci utama.
- Secara opsional, ubah pola partisi.
- Pilih Tutup untuk menyimpan dan menutup panel.
Pilih Simpan. Halaman Sumber data terbuka memperlihatkan sumber data baru dalam status Refresh .
Tip
Ada status untuk tugas dan proses. Sebagian besar proses bergantung pada proses hulu lainnya, seperti sumber data dan refresh pembuatanprofil data.
Pilih status untuk membuka panel Detail kemajuan dan melihat kemajuan tugas. Untuk membatalkan pekerjaan, pilih Batalkan pekerjaan di bagian bawah panel.
Di bawah setiap tugas, Anda dapat memilih Lihat detail untuk informasi kemajuan selengkapnya, seperti waktu pemrosesan, tanggal pemrosesan terakhir, serta kesalahan dan peringatan yang berlaku terkait dengan tugas atau proses. Pilih Lihat status sistem di bagian bawah panel untuk melihat proses lain dalam sistem.
Memuat data dapat memakan waktu. Setelah refresh berhasil, data yang diserap dapat ditinjau dari >halaman Tabel Data .
Sunting sumber data Azure Data Lake Storage
Anda dapat memperbarui opsi Sambungkan ke akun penyimpanan menggunakan . Untuk informasi selengkapnya, lihat Menyambungkan ke Azure Data Lake Storage akun dengan Microsoft Entra perwakilan layanan. Untuk menyambungkan ke kontainer lain dari akun penyimpanan Anda, atau mengubah nama akun,buat koneksi sumber data baru.
Buka Sumber> dataData. Di samping sumber data yang ingin diperbarui, pilih Edit.
Ubah salah satu informasi berikut:
KETERANGAN
Hubungkan penyimpanan Anda menggunakan dan informasi koneksi. Anda tidak dapat mengubah informasi Kontainer saat memperbarui koneksi.
Catatan
Salah satu peran berikut harus ditetapkan ke akun penyimpanan atau kontainer:
- Pembaca Data Blob Penyimpanan
- pemilik Data Blob Penyimpanan
- Kontributor data Blob penyimpanan
Gunakan identitas terkelola untuk Azure dengan Anda Azure Data Lake Storage ???
Aktifkan Private Link jika Anda ingin menyerap data dari akun penyimpanan melalui Azure Private Link. Untuk informasi selengkapnya, lihat Private Link.
Pilih Selanjutnya.
Ubah salah satu hal berikut:
Buka file model.json atau manifest.json yang berbeda dengan kumpulan tabel yang berbeda dari kontainer.
Untuk menambahkan tabel tambahan untuk diserap, pilih Tabel baru.
Untuk menghapus tabel yang sudah dipilih jika tidak ada dependensi, pilih tabel dan Hapus.
Penting
Jika ada dependensi pada file model.json atau manifest.json yang ada dan kumpulan tabel, Anda akan melihat pesan kesalahan dan tidak dapat memilih file model.json atau manifest.json lain. Hilangkan dependensi tersebut sebelum mengubah file model.json atau manifest.json atau buat sumber data baru dengan file model.json atau manifest.json yang ingin Anda gunakan untuk menghindari dependensi dihapus.
Untuk mengubah lokasi file data atau kunci utama, pilih Edit.
Untuk mengubah data penyerapan inkremental, lihat Mengonfigurasi refresh inkremental untuk sumber data Azure Data Lake.
Hanya ubah nama tabel agar sesuai dengan nama tabel di file .json.
Catatan
Selalu simpan nama tabel sama dengan nama tabel di file model.json atau manifest.json setelah penyerapan. Customer Insights - Data memvalidasi semua nama tabel dengan model.json atau manifest.json selama setiap refresh sistem. Jika nama tabel berubah, kesalahan terjadi karena Customer Insights - Data tidak dapat menemukan nama tabel baru dalam berkas .json. Jika nama tabel yang diserap secara tidak sengaja diubah, edit nama tabel agar sesuai dengan nama dalam file .json.
Pilih Kolom untuk menambahkan atau mengubahnya, atau untuk mengaktifkan pembuatan profil data. Kemudian pilih Selesai.
PilihSimpan untuk menerapkan perubahan dan kembali ke halaman Sumber data .
Tip
Ada status untuk tugas dan proses. Sebagian besar proses bergantung pada proses hulu lainnya, seperti sumber data dan refresh pembuatanprofil data.
Pilih status untuk membuka panel Detail kemajuan dan melihat kemajuan tugas. Untuk membatalkan pekerjaan, pilih Batalkan pekerjaan di bagian bawah panel.
Di bawah setiap tugas, Anda dapat memilih Lihat detail untuk informasi kemajuan selengkapnya, seperti waktu pemrosesan, tanggal pemrosesan terakhir, serta kesalahan dan peringatan yang berlaku terkait dengan tugas atau proses. Pilih Lihat status sistem di bagian bawah panel untuk melihat proses lain dalam sistem.