Memantau performa untuk grup ketersediaan AlwaysOn
Berlaku untuk:![]() SQL Server
SQL Server
Aspek performa Grup Ketersediaan AlwaysOn sangat penting untuk mempertahankan perjanjian tingkat layanan (SLA) untuk database misi penting Anda. Memahami bagaimana grup ketersediaan mengirim log ke replika sekunder dapat membantu Anda memperkirakan tujuan waktu pemulihan (RTO) dan tujuan titik pemulihan (RPO) implementasi ketersediaan Anda dan mengidentifikasi hambatan dalam grup ketersediaan atau replika yang berkinerja buruk. Artikel ini menjelaskan proses sinkronisasi, menunjukkan kepada Anda cara menghitung beberapa metrik utama, dan memberi Anda tautan ke beberapa skenario pemecahan masalah performa umum.
Proses sinkronisasi data
Untuk memperkirakan waktu sinkronisasi penuh dan mengidentifikasi hambatan, Anda perlu memahami proses sinkronisasi. Penyempitan performa dapat berada di mana saja dalam proses, dan menemukan hambatan dapat membantu Anda menggali lebih dalam masalah yang mendasar. Gambar dan tabel berikut mengilustrasikan proses sinkronisasi data:

| Sequence | Deskripsi langkah | Komentar | Metrik yang berguna |
|---|---|---|---|
| 1 | Pembuatan log | Data log dihapus ke disk. Log ini harus direplikasi ke replika sekunder. Rekaman log memasukkan antrean kirim. | SQL Server:Byte log database > di-flushed\sec |
| 2 | Tangkap | Log untuk setiap database diambil dan dikirim ke antrean mitra yang sesuai (satu per pasangan replika database). Proses penangkapan ini berjalan terus menerus selama replika ketersediaan terhubung dan pergerakan data tidak ditangguhkan karena alasan apa pun, dan pasangan replika database ditunjukkan untuk Disinkronkan atau Disinkronkan. Jika proses pengambilan tidak dapat memindai dan mengantrekan pesan dengan cukup cepat, antrean pengiriman log akan dibangun. | SQL Server:Availability Replica > Bytes Sent to Replica\sec, yang merupakan agregasi dari jumlah semua pesan database yang diantrekan untuk replika ketersediaan tersebut. log_send_queue_size (KB) dan log_bytes_send_rate (KB/detik) pada replika utama. |
| 3 | Kirim | Pesan dalam setiap antrean database-replika dihapus antrean dan dikirim melalui kawat ke replika sekunder masing-masing. | SQL Server:Byte Replika > Ketersediaan yang dikirim ke transport\sec |
| 4 | Terima dan cache | Setiap replika sekunder menerima dan menyimpan cache pesan. | Penghitung kinerja SQL Server:Byte Log Replika > Ketersediaan Diterima/detik |
| 5 | Mengeras | Log dihapus pada replika sekunder untuk pengerasan. Setelah flush log, pengakuan dikirim kembali ke replika utama. Setelah log diperkeras, kehilangan data dihindari. |
Penghitung kinerja SQL Server:Byte Log Database > Dihapus/dtk Jenis tunggu HADR_LOGCAPTURE_SYNC |
| 6 | Kembalikan | Ulangi halaman yang dibersihkan pada replika sekunder. Halaman disimpan dalam antrean pengulangan saat menunggu untuk direalone. | SQL Server:Database Replica > Redone Bytes/dtk redo_queue_size (KB) dan redo_rate. Jenis tunggu REDO_SYNC |
Gerbang kontrol aliran
Grup ketersediaan dirancang dengan gerbang kontrol aliran pada replika utama untuk menghindari konsumsi sumber daya yang berlebihan, seperti sumber daya jaringan dan memori, pada semua replika ketersediaan. Gerbang kontrol alur ini tidak memengaruhi status kesehatan sinkronisasi replika ketersediaan, tetapi dapat memengaruhi performa keseluruhan database ketersediaan Anda, termasuk RPO.
Setelah log diambil pada replika utama, log tunduk pada dua tingkat kontrol alur. Setelah ambang pesan dari salah satu gerbang tercapai, pesan log tidak lagi dikirim ke replika tertentu atau untuk database tertentu. Pesan dapat dikirim setelah pesan pengakuan diterima untuk pesan yang dikirim untuk membawa jumlah pesan terkirim di bawah ambang batas.
Selain gerbang kontrol alur, ada faktor lain yang dapat mencegah pesan log dikirim. Sinkronisasi replika memastikan bahwa pesan dikirim dan diterapkan dalam urutan nomor urutan log (LSN). Sebelum pesan log dikirim, LSN-nya juga memeriksa nomor LSN terendah yang diakui untuk memastikan bahwa itu kurang dari salah satu ambang batas (tergantung pada jenis pesan). Jika kesenjangan antara dua angka LSN lebih besar dari ambang batas, pesan tidak dikirim. Setelah celah berada di bawah ambang batas lagi, pesan dikirim.
SQL Server 2022 meningkatkan batasan jumlah pesan yang diizinkan setiap gerbang. Dengan menggunakan bendera pelacakan 12310, batas yang ditingkatkan juga tersedia untuk versi SQL Server berikut, dimulai dengan: SQL Server 2019 CU9, SQL Server 2017 CU18, dan SQL Server 2016 SP1 CU16.
Tabel berikut membandingkan batas pesan:
SQL Server 2022, dan versi SQL Server yang didukung (dimulai dengan SQL Server 2019 CU9, SQL Server 2017 CU18, dan SQL Server 2016 SP1 CU16) yang mengaktifkan bendera pelacakan 12310 lihat batas berikut:
| Tingkat | Jumlah gerbang | Jumlah pesan | Metrik yang berguna |
|---|---|---|---|
| Transportasi | 1 per replika ketersediaan | 16384 | Database_transport_flow_control_action peristiwa yang diperluas |
| Database | 1 per database ketersediaan | 7168 | DBMIRROR_SEND Hadron_database_flow_control_action peristiwa yang diperluas |
Dua penghitung kinerja yang berguna, SQL Server:Kontrol Aliran Replika > Ketersediaan/detik dan SQL Server:Availability Replica > Flow Control Time (ms/detik), menunjukkan kepada Anda, dalam detik terakhir, berapa kali kontrol aliran diaktifkan dan berapa banyak waktu yang dihabiskan untuk menunggu kontrol alur. Waktu tunggu yang lebih tinggi pada kontrol alur diterjemahkan ke RPO yang lebih tinggi. Untuk informasi selengkapnya tentang jenis masalah yang dapat menyebabkan waktu tunggu yang tinggi pada kontrol alur, lihat Memecahkan Masalah: Grup ketersediaan melebihi RPO.
Memperkirakan waktu failover (RTO)
RTO dalam SLA Anda tergantung pada waktu failover implementasi AlwaysOn Anda pada waktu tertentu, yang dapat dinyatakan dalam rumus berikut:

Penting
Jika grup ketersediaan berisi lebih dari satu database ketersediaan, maka database ketersediaan dengan Tfailover tertinggi menjadi nilai pembatasan untuk kepatuhan RTO.
Waktu deteksi kegagalan, Tdetection, adalah waktu yang diperlukan sistem untuk mendeteksi kegagalan. Kali ini tergantung pada pengaturan tingkat kluster dan bukan pada replika ketersediaan individual. Bergantung pada kondisi failover otomatis yang dikonfigurasi, failover dapat dipicu sebagai respons instan terhadap kesalahan internal SQL Server penting, seperti spinlock tanpa intim. Dalam hal ini, deteksi dapat secepat laporan kesalahan sp_server_diagnostics (Transact-SQL) dikirim ke kluster WSFC (interval default adalah 1/3 dari batas waktu pemeriksaan kesehatan). Failover juga dapat dipicu karena waktu habis, seperti batas waktu pemeriksaan kesehatan kluster telah kedaluwarsa (30 detik secara default) atau sewa antara DLL sumber daya dan instans SQL Server telah kedaluwarsa (20 detik secara default). Dalam hal ini, waktu deteksi adalah selama interval batas waktu. Untuk informasi selengkapnya, lihat Kebijakan failover fleksibel untuk failover otomatis grup ketersediaan (SQL Server).
Satu-satunya hal yang perlu dilakukan replika sekunder untuk menjadi siap untuk failover adalah agar pengulangan mengejar ke akhir log. Waktu pengulangan, Tredo, dihitung menggunakan rumus berikut:

di mana redo_queue adalah nilai dalam redo_queue_size dan redo_rate adalah nilai dalam redo_rate.
Waktu overhead failover, Toverhead, mencakup waktu yang diperlukan untuk mengalihkan kluster WSFC dan untuk membuat database online. Waktu ini biasanya singkat dan konstan.
Memperkirakan potensi kehilangan data (RPO)
RPO di SLA Anda tergantung pada kemungkinan hilangnya data implementasi Always On Anda pada waktu tertentu. Kemungkinan kehilangan data ini dapat dinyatakan dalam rumus berikut:

di mana log_send_queue adalah nilai log_send_queue_size dan laju pembuatan log adalah nilai SQL Server:Byte Log Database > Flushed/dtk.
Peringatan
Jika grup ketersediaan berisi lebih dari satu database ketersediaan, maka database ketersediaan dengan Tdata_loss tertinggi menjadi nilai pembatasan untuk kepatuhan RPO.
Antrean pengiriman log mewakili semua data yang dapat hilang dari kegagalan bencana. Pada pandangan pertama, penasaran bahwa tingkat pembuatan log digunakan alih-alih laju pengiriman log (lihat log_send_rate). Namun, ingatlah bahwa menggunakan laju pengiriman log hanya memberi Anda waktu untuk disinkronkan, sementara RPO mengukur kehilangan data berdasarkan seberapa cepat itu dihasilkan, bukan pada seberapa cepat itu disinkronkan.
Cara yang lebih sederhana untuk memperkirakan Tdata_loss adalah dengan menggunakan last_commit_time. DMV pada replika utama melaporkan nilai ini untuk semua replika. Anda dapat menghitung perbedaan antara nilai untuk replika utama dan nilai untuk replika sekunder untuk memperkirakan seberapa cepat log pada replika sekunder mengejar replika utama. Seperti yang dinyatakan sebelumnya, perhitungan ini tidak memberi tahu Anda potensi kehilangan data berdasarkan seberapa cepat log dihasilkan, tetapi seharusnya mendekati.
Memperkirakan RTO & RPO dengan dasbor SSMS
Di Grup Ketersediaan AlwaysOn, RTO dan RPO dihitung dan ditampilkan untuk database yang dihosting pada replika sekunder. Pada dasbor replika utama, RTO dan RPO dikelompokkan menurut replika sekunder.
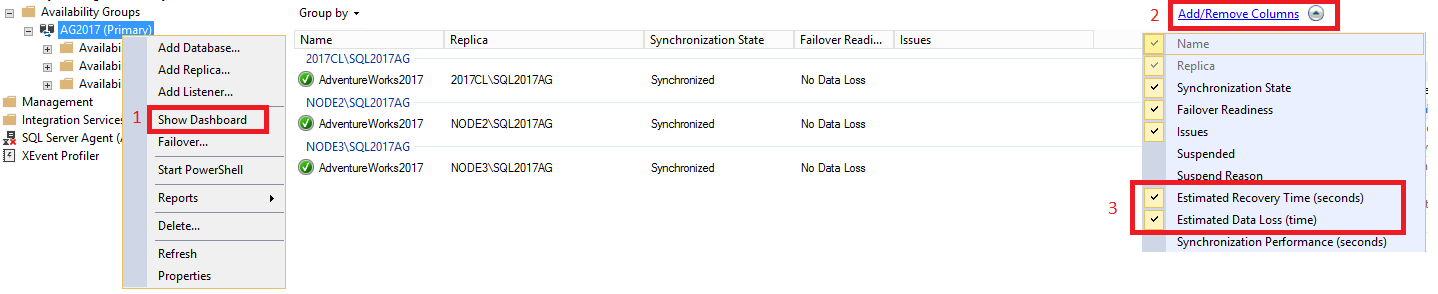
Untuk melihat RTO dan RPO di dalam dasbor, lakukan hal berikut:
Di SQL Server Management Studio, perluas simpul Ketersediaan Tinggi AlwaysOn, klik kanan nama grup ketersediaan Anda, dan pilih Tampilkan Dasbor.
Pilih Tambahkan/Hapus Kolom di bawah tab Kelompokkan menurut . Periksa Perkiraan Waktu Pemulihan(detik) [RTO] dan Perkiraan Kehilangan Data (waktu) [RPO].
Perhitungan RTO database sekunder
Perhitungan waktu pemulihan menentukan berapa banyak waktu yang diperlukan untuk memulihkan database sekunder setelah failover terjadi. Waktu failover biasanya pendek dan konstan. Waktu deteksi tergantung pada pengaturan tingkat kluster dan bukan pada replika ketersediaan individual.
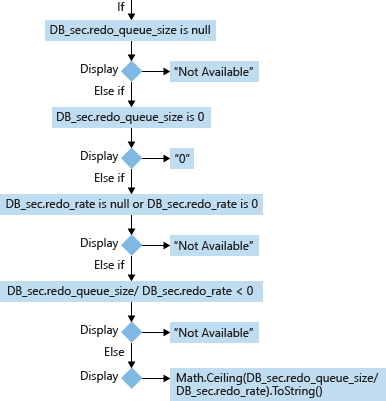
Untuk database sekunder (DB_sec), perhitungan dan tampilan RTO-nya didasarkan pada redo_queue_size dan redo_rate:
Kecuali kasus sudut, rumus untuk menghitung RTO database sekunder adalah:
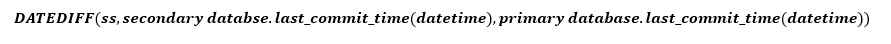
Perhitungan RPO database sekunder
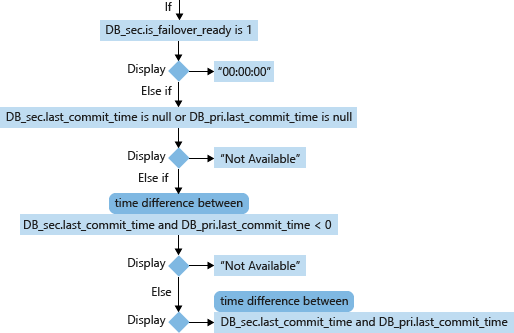
Untuk database sekunder (DB_sec), perhitungan dan tampilan RPO-nya didasarkan pada is_failover_ready, last_commit_time, dan database utamanya yang berkorelasi (DB_pri) last_commit_time. Ketika database.is_failover_ready sekunder = 1, maka daa disinkronkan, dan tidak ada kehilangan data yang akan terjadi setelah failover. Namun, jika nilai ini adalah 0, maka ada kesenjangan antara last_commit_time pada database utama dan last_commit_time pada database sekunder.
Untuk database utama, last_commit_time adalah waktu ketika transaksi terbaru telah dilakukan. Untuk database sekunder, last_commit_time adalah waktu penerapan terbaru untuk transaksi pada database utama yang telah berhasil diperkeras pada database sekunder juga. Angka ini harus sama untuk database utama dan sekunder. Kesenjangan antara kedua nilai ini adalah durasi di mana transaksi yang tertunda belum diperkeras pada database sekunder, dan akan hilang jika terjadi failover.
Penghitung Kinerja yang digunakan dalam rumus RTO/RPO
- redo_queue_size (KB) [digunakan dalam RTO]: Ukuran antrean pengulangan adalah ukuran log transaksi antara last_received_lsn dan last_redone_lsn. last_received_lsn adalah ID blok log yang mengidentifikasi titik di mana semua blok log telah diterima oleh replika sekunder yang menghosting database sekunder ini. Last_redone_lsn adalah nomor urutan log dari rekaman log terakhir yang direbus pada database sekunder. Berdasarkan kedua nilai ini, kita dapat menemukan ID blok log awal (last_received_lsn) dan blok log akhir (last_redone_lsn). Ruang antara kedua blok log ini kemudian dapat mewakili bagaimana mungkin blok log transaksi belum di-redone. Ini diukur dalam Kilobyte(KB).
- redo_rate (KB/dtk) [digunakan dalam RTO]: Nilai akumulatif yang mewakili pada periode waktu yang berlalu, berapa banyak log transaksi (KB) yang telah di-redone pada database sekunder dalam Kilobyte(KB)/escond.
- last_commit_time (Datetime) [digunakan dalam RPO]: Untuk database utama, last_commit_time adalah waktu ketika transaksi terbaru telah dilakukan. Untuk database sekunder, last_commit_time adalah waktu penerapan terbaru untuk transaksi pada database utama yang telah berhasil diperkeras pada database sekunder juga. Karena nilai ini pada sekunder harus disinkronkan dengan nilai yang sama pada primer, kesenjangan apa pun antara kedua nilai ini adalah perkiraan kehilangan data (RPO).
Memperkirakan RTO dan RPO menggunakan DMV
Dimungkinkan untuk mengkueri sys.dm_hadr_database_replica_states DMV dan sys.dm_hadr_database_replica_cluster_states untuk memperkirakan RPO dan RTO database. Kueri di bawah ini membuat prosedur tersimpan yang menyelesaikan kedua hal tersebut.
Catatan
Pastikan untuk membuat dan menjalankan prosedur tersimpan untuk memperkirakan RTO terlebih dahulu, karena nilai yang dihasilkannya diperlukan untuk menjalankan prosedur tersimpan untuk memperkirakan RPO.
Membuat prosedur tersimpan untuk memperkirakan RTO
- Pada replika sekunder target, buat prosedur tersimpan proc_calculate_RTO. Jika prosedur tersimpan ini sudah ada, letakkan terlebih dahulu, lalu buat ulang.
if object_id(N'proc_calculate_RTO', 'p') is not null
drop procedure proc_calculate_RTO
go
raiserror('creating procedure proc_calculate_RTO', 0,1) with nowait
go
--
-- name: proc_calculate_RTO
--
-- description: Calculate RTO of a secondary database.
--
-- parameters: @secondary_database_name nvarchar(max): name of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RTO
(
@secondary_database_name nvarchar(max)
)
as
begin
declare @db sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @redo_queue_size bigint
declare @redo_rate bigint
declare @replica_id uniqueidentifier
declare @group_database_id uniqueidentifier
declare @group_id uniqueidentifier
declare @RTO float
select
@is_primary_replica = dbr.is_primary_replica,
@is_failover_ready = dbcs.is_failover_ready,
@redo_queue_size = dbr.redo_queue_size,
@redo_rate = dbr.redo_rate,
@replica_id = dbr.replica_id,
@group_database_id = dbr.group_database_id,
@group_id = dbr.group_id
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbcs.database_name = @secondary_database_name
if @is_primary_replica is null or @is_failover_ready is null or @redo_queue_size is null or @replica_id is null or @group_database_id is null or @group_id is null
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else if @is_primary_replica = 1
begin
print 'You are visiting wrong replica';
return
end
if @redo_queue_size = 0
set @RTO = 0
else if @redo_rate is null or @redo_rate = 0
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else
set @RTO = CAST(@redo_queue_size AS float) / @redo_rate
print 'RTO of Database '+ @secondary_database_name +' is ' + convert(varchar, ceiling(@RTO))
print 'group_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_id)
print 'replica_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @replica_id)
print 'group_database_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_database_id)
end
- Jalankan proc_calculate_RTO dengan nama database sekunder target:
exec proc_calculate_RTO @secondary_database_name = N'DB_sec'
Output menampilkan nilai RTO dari database replika sekunder target. Simpan group_id, replica_id, dan group_database_id untuk digunakan dengan prosedur tersimpan estimasi RPO.
Contoh Output:
RTO database DB_sec' adalah 0
group_id Database DB4 adalah F176DD65-C3EE-4240-BA23-EA615F965C9B
replica_id Database DB4 adalah 405554F6-3FDC-4593-A650-2067F5FABFFD
group_database_id Database DB4 adalah 39F7942F-7B5E-42C5-977D-02E7FFA6C392
Membuat prosedur tersimpan untuk memperkirakan RPO
- Pada replika utama, buat prosedur tersimpan proc_calculate_RPO. Jika sudah ada, letakkan terlebih dahulu, lalu buat ulang.
if object_id(N'proc_calculate_RPO', 'p') is not null
drop procedure proc_calculate_RPO
go
raiserror('creating procedure proc_calculate_RPO', 0,1) with nowait
go
--
-- name: proc_calculate_RPO
--
-- description: Calculate RPO of a secondary database.
--
-- parameters: @group_id uniqueidentifier: group_id of the secondary database.
-- @replica_id uniqueidentifier: replica_id of the secondary database.
-- @group_database_id uniqueidentifier: group_database_id of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RPO
(
@group_id uniqueidentifier,
@replica_id uniqueidentifier,
@group_database_id uniqueidentifier
)
as
begin
declare @db_name sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @is_local bit
declare @last_commit_time_sec datetime
declare @last_commit_time_pri datetime
declare @RPO nvarchar(max)
-- secondary database's last_commit_time
select
@db_name = dbcs.database_name,
@is_failover_ready = dbcs.is_failover_ready,
@last_commit_time_sec = dbr.last_commit_time
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.replica_id = @replica_id and dbr.group_database_id = @group_database_id
-- correlated primary database's last_commit_time
select
@last_commit_time_pri = dbr.last_commit_time,
@is_local = dbr.is_local
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.is_primary_replica = 1 and dbr.group_database_id = @group_database_id
if @is_local is null or @is_failover_ready is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
if @is_local = 0
begin
print 'You are visiting wrong replica'
return
end
if @is_failover_ready = 1
set @RPO = '00:00:00'
else if @last_commit_time_sec is null or @last_commit_time_pri is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
begin
if DATEDIFF(ss, @last_commit_time_sec, @last_commit_time_pri) < 0
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
set @RPO = CONVERT(varchar, DATEADD(ms, datediff(ss ,@last_commit_time_sec, @last_commit_time_pri) * 1000, 0), 114)
end
print 'RPO of database '+ @db_name +' is ' + @RPO
end
- Jalankan proc_calculate_RPO dengan group_id, replica_id, dan group_database_id database sekunder target.
exec proc_calculate_RPO @group_id= 'F176DD65-C3EE-4240-BA23-EA615F965C9B',
@replica_id = '405554F6-3FDC-4593-A650-2067F5FABFFD',
@group_database_id = '39F7942F-7B5E-42C5-977D-02E7FFA6C392'
- Output menampilkan nilai RPO dari database replika sekunder target.
Pemantauan untuk RTO dan RPO
Bagian ini menunjukkan cara memantau grup ketersediaan Anda untuk metrik RTO dan RPO. Demonstrasi ini mirip dengan tutorial GUI yang diberikan dalam model kesehatan Always On, bagian 2: Memperluas model kesehatan.
Elemen waktu failover dan potensi perhitungan kehilangan data dalam Memperkirakan waktu failover (RTO) dan Memperkirakan potensi kehilangan data (RPO) disediakan dengan nyaman sebagai metrik performa dalam status Replika Database faset manajemen kebijakan (lihat Melihat faset manajemen berbasis kebijakan pada objek SQL Server). Anda dapat memantau kedua metrik ini sesuai jadwal dan diberi tahu ketika metrik melebihi RTO dan RPO Anda.
Skrip yang ditunjukkan membuat dua kebijakan sistem yang dijalankan pada jadwal masing-masing, dengan karakteristik berikut:
Kebijakan RTO yang gagal ketika perkiraan waktu failover melebihi 10 menit, dievaluasi setiap 5 menit
Kebijakan RPO yang gagal ketika perkiraan kehilangan data melebihi 1 jam, dievaluasi setiap 30 menit
Kedua kebijakan memiliki konfigurasi yang identik pada semua replika ketersediaan
Kebijakan dievaluasi di semua server, tetapi hanya pada grup ketersediaan yang replika ketersediaan lokalnya adalah replika utama. Jika replika ketersediaan lokal bukan replika utama, kebijakan tidak dievaluasi.
Kegagalan kebijakan ditampilkan dengan nyaman di Dasbor AlwaysOn saat Anda melihatnya di replika utama.
Untuk membuat kebijakan, ikuti instruksi di bawah ini pada semua instans server yang berpartisipasi dalam grup ketersediaan:
Mulai layanan SQL Server Agent jika belum dimulai.
Di SQL Server Management Studio, dari menu Alat , klik Opsi.
Di tab SQL Server Always On , pilih Aktifkan kebijakan AlwaysOn yang ditentukan pengguna dan klik OK.
Pengaturan ini memungkinkan Anda menampilkan kebijakan kustom yang dikonfigurasi dengan benar di Dasbor AlwaysOn.
Buat kondisi manajemen berbasis kebijakan menggunakan spesifikasi berikut:
Nama:
RTOFaset: Status Replika Database
Bidang:
Add(@EstimatedRecoveryTime, 60)Operator: <=
Nilai:
600
Kondisi ini gagal ketika potensi waktu failover melebihi 10 menit, termasuk overhead 60 detik untuk deteksi kegagalan dan failover.
Buat kondisi manajemen berbasis kebijakan kedua menggunakan spesifikasi berikut:
Nama:
RPOFaset: Status Replika Database
Bidang:
@EstimatedDataLossOperator: <=
Nilai:
3600
Kondisi ini gagal ketika potensi kehilangan data melebihi 1 jam.
Buat kondisi manajemen berbasis kebijakan ketiga menggunakan spesifikasi berikut:
Nama:
IsPrimaryReplicaFaset: Grup Ketersediaan
Bidang:
@LocalReplicaRoleOperator: =
Nilai:
Primary
Kondisi ini memeriksa apakah replika ketersediaan lokal untuk grup ketersediaan tertentu adalah replika utama.
Buat kebijakan manajemen berbasis kebijakan menggunakan spesifikasi berikut:
Halaman umum :
Nama:
CustomSecondaryDatabaseRTOPeriksa kondisi:
RTOTerhadap target: Setiap DatabaseReplicaState di IsPrimaryReplica AvailabilityGroup
Pengaturan ini memastikan bahwa kebijakan hanya dievaluasi pada grup ketersediaan yang replika ketersediaan lokalnya adalah replika utama.
Mode evaluasi: Sesuai jadwal
Jadwal: CollectorSchedule_Every_5min
Diaktifkan: dipilih
Halaman deskripsi :
Kategori: Peringatan database ketersediaan
Pengaturan ini memungkinkan hasil evaluasi kebijakan ditampilkan di Dasbor AlwaysOn.
Deskripsi: Replika saat ini memiliki RTO yang melebihi 10 menit, dengan asumsi overhead 1 menit untuk penemuan dan failover. Anda harus segera menyelidiki masalah performa pada instans server masing-masing.
Teks yang akan ditampilkan: RTO Terlampaui!
Buat kebijakan manajemen berbasis kebijakan kedua menggunakan spesifikasi berikut:
Halaman umum :
Nama:
CustomAvailabilityDatabaseRPOPeriksa kondisi:
RPOTerhadap target: Setiap DatabaseReplicaState di IsPrimaryReplica AvailabilityGroup
Mode evaluasi: Sesuai jadwal
Jadwal: CollectorSchedule_Every_30min
Diaktifkan: dipilih
Halaman deskripsi :
Kategori: Peringatan database ketersediaan
Deskripsi: Database ketersediaan telah melebihi RPO Anda 1 jam. Anda harus segera menyelidiki masalah performa pada replika ketersediaan.
Teks yang akan ditampilkan: RPO Terlampaui!
Setelah selesai, dua pekerjaan SQL Server Agent baru dibuat, satu untuk setiap jadwal evaluasi kebijakan. Pekerjaan ini harus memiliki nama yang dimulai dengan syspolicy_check_schedule.
Anda dapat melihat riwayat pekerjaan untuk memeriksa hasil evaluasi. Kegagalan evaluasi juga dicatat di log aplikasi Windows (di Pemantau Peristiwa) dengan ID Peristiwa 34052. Anda juga dapat mengonfigurasi SQL Server Agent untuk mengirim pemberitahuan tentang kegagalan kebijakan. Untuk informasi selengkapnya, lihat Mengonfigurasi pemberitahuan untuk memberi tahu administrator kebijakan tentang kegagalan kebijakan.
Skenario pemecahan masalah performa
Tabel berikut mencantumkan skenario pemecahan masalah terkait performa umum.
| Skenario | Deskripsi |
|---|---|
| Pemecahan masalah: Grup ketersediaan melebihi RTO | Setelah failover otomatis atau failover manual yang direncanakan tanpa kehilangan data, waktu failover melebihi RTO Anda. Atau, ketika Anda memperkirakan waktu failover replika sekunder penerapan sinkron (seperti mitra failover otomatis), Anda menemukan bahwa itu melebihi RTO Anda. |
| Pemecahan masalah: Grup ketersediaan melebihi RPO | Setelah Anda melakukan failover manual paksa, kehilangan data Anda lebih dari RPO Anda. Atau, ketika Anda menghitung potensi kehilangan data dari replika sekunder penerapan asinkron, Anda menemukan bahwa itu melebihi RPO Anda. |
| Pemecahan masalah: Perubahan pada replika utama tidak tercermin pada replika sekunder | Aplikasi klien berhasil menyelesaikan pembaruan pada replika utama, tetapi mengkueri replika sekunder menunjukkan bahwa perubahan tidak tercermin. |
Peristiwa yang diperluas yang berguna
Peristiwa yang diperluas berikut ini berguna saat memecahkan masalah replika dalam status Sinkronisasi .
| Nama Acara | Category | Saluran | Replika ketersediaan |
|---|---|---|---|
| redo_caught_up | transaksi | Debug | Sekunder |
| redo_worker_entry | transaksi | Debug | Sekunder |
| hadr_transport_dump_message | alwayson |
Debug | Primer |
| hadr_worker_pool_task | alwayson |
Debug | Primer |
| hadr_dump_primary_progress | alwayson |
Debug | Primer |
| hadr_dump_log_progress | alwayson |
Debug | Primer |
| hadr_undo_of_redo_log_scan | alwayson |
Analitik | Sekunder |
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk