Che cos'è un data lake?
Un archivio data lake è un repository che contiene una grande quantità di dati nel relativo formato nativo non elaborato. Gli archivi data lake sono ottimizzati per la scalabilità fino a terabyte e petabyte di dati. I dati provengono generalmente da più origini eterogenee e possono essere strutturati, semistrutturati o non strutturati. L'obiettivo di un archivio data lake è archiviare tutti gli elementi nello stato originale, senza trasformazioni. Questo approccio differisce dal tradizionale data warehouse, che invece trasforma ed elabora i dati al momento dell'inserimento.
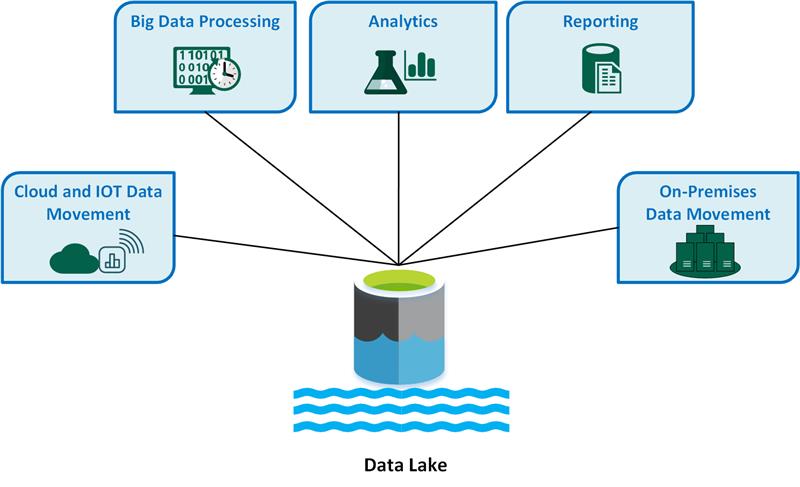
Di seguito sono riportati i casi d'uso chiave di Data Lake:
- Spostamento dei dati cloud e IoT
- Elaborazione di Big Data
- Analisi
- Creazione di report
- Spostamento dei dati locale
I vantaggi di un archivio data lake sono i seguenti:
- I dati non vengono mai eliminati perché vengono archiviati nel formato non elaborato. Ciò è particolarmente utile in un ambiente Big Data, quando non si sa in anticipo quali informazioni siano disponibili nei dati.
- Gli utenti possono esplorare i dati e creare le proprie query.
- Può essere più rapido degli strumenti di estrazione, trasformazione e caricamento tradizionali.
- È più flessibile di un data warehouse perché consente di archiviare dati non strutturati e semistrutturati.
Una soluzione data lake completa prevede l'archiviazione e l'elaborazione. L'archiviazione in un data lake è progettata per la tolleranza di errore, la scalabilità illimitata e l'elevata velocità nell'inserimento dei dati con diverse forme e dimensioni. L'elaborazione in un data lake prevede l'uso di uno o più motori creati tenendo presenti questi obiettivi e che sono in grado di elaborare i dati archiviati nel data lake su larga scala.
Quando usare un archivio data lake
L'archivio data lake viene tipicamente usato per l'esplorazione dei dati, l'analisi dei dati e le attività di Machine Learning.
Un archivio data lake può anche essere usato come origine dati di un data warehouse. Con questo approccio, i dati non elaborati vengono inseriti nell'archivio data lake e quindi trasformati in un formato strutturato disponibile per le query. Questa trasformazione usa in genere una pipeline ELT (Extract, Load, and Transform) in cui i dati vengono inseriti e trasformati sul posto. Un'origine dati già relazionale può essere inserita direttamente nel data warehouse usando un processo ETL, senza passare per l'archivio data lake.
Gli archivi di data lake vengono spesso usati in scenari di Internet delle cose o di flussi di eventi perché sono in grado di salvare in modo persistente grandi quantità di dati relazionali e non relazionali, senza alcuna trasformazione o definizione di schema. Vengono creati per gestire volumi elevati di piccole operazioni di scrittura a bassa latenza e sono ottimizzati per offrire un'enorme velocità effettiva.
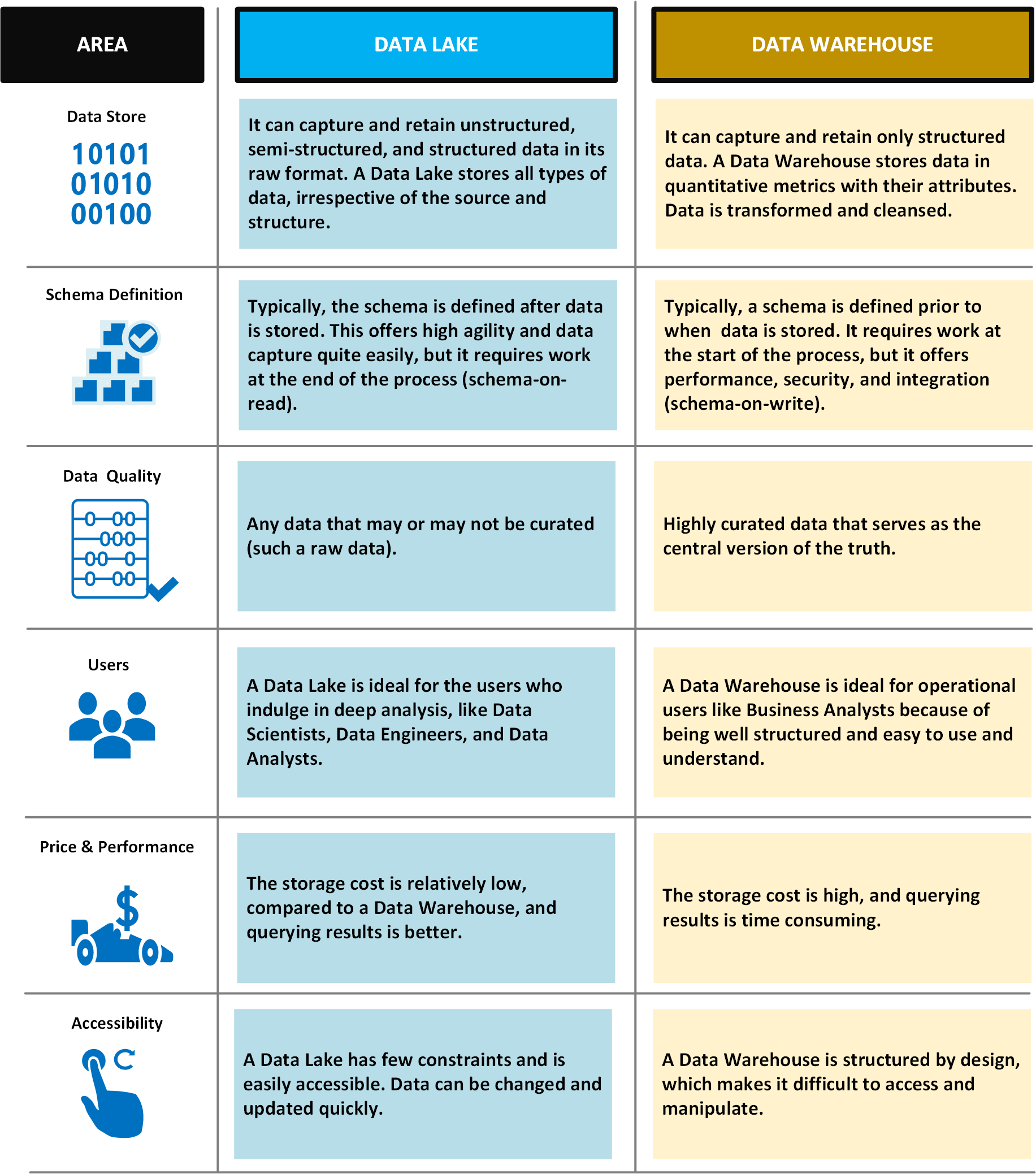
La tabella seguente confronta data lake e data warehouse:
Sfide
- L'assenza di uno schema o di metadati descrittivi può rendere complesso l'utilizzo dei dati o l'esecuzione di query.
- L'assenza di coerenza semantica tra i dati può rendere complicato eseguire l'analisi dei dati, a meno che gli utenti non abbiano competenze particolarmente elevate in materia di analisi.
- Può essere difficile garantire la qualità dei dati che vengono inseriti nell'archivio data lake.
- Senza una governance appropriata, gli aspetti correlati al controllo degli accessi e alla privacy possono rappresentare problemi. È necessario stabilire quali informazioni verranno inserite nell'archivio data lake, chi potrà accedere ai dati e per quali fini.
- Un archivio data lake potrebbe non essere il modo migliore per integrare dati già relazionali.
- Un archivio data lake non fornisce di per sé visualizzazioni integrate o olistiche dell'intera organizzazione.
- Un archivio data lake può diventare una "discarica" di dati che non vengono mai effettivamente analizzati o sottoposti a data mining per ottenere informazioni dettagliate.
Scelte di tecnologia
Creare soluzioni Data Lake usando i servizi seguenti offerti da Azure:
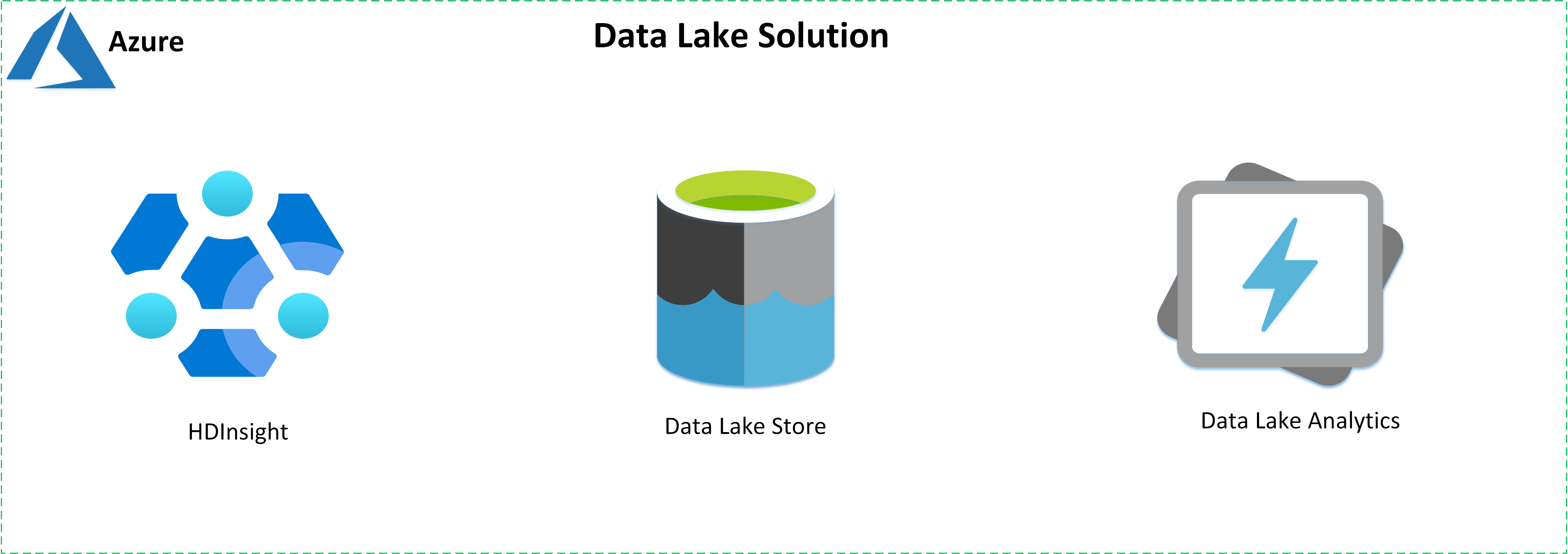
- Azure HD Insight è un servizio di analisi open source gestito e a spettro completo nel cloud per le aziende.
- Azure Data Lake Store è un repository compatibile con Hadoop e hyperscale.
- Azure Data Lake Analytics è un servizio di processo di analisi su richiesta per semplificare l'analisi dei Big Data.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Avijit Prasad | Consulente cloud
Passaggi successivi
- Che cos'è Azure HDInsight?
- Introduzione ad Archiviazione di Azure Data Lake
- Documentazione di Azure Data Lake Analytics
- Introduzione ad Azure Data Lake Archiviazione (modulo di training)
- Che cos'è un Data Lake?
Risorse correlate
Commenti e suggerimenti
Presto disponibile: nel corso del 2024 verranno dismessi i problemi di GitHub come meccanismo di feedback per il contenuto e verranno sostituiti con un nuovo sistema di feedback. Per altre informazioni, vedere: https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per