Operatore join
Consente di unire le righe di due tabelle in modo da formare una nuova tabella, facendo corrispondere i valori delle colonne specificate da ogni tabella.
Linguaggio di query Kusto (KQL) offre molti tipi di join che influiscono sullo schema e le righe nella tabella risultante in modi diversi. Ad esempio, se si usa un inner join, la tabella ha le stesse colonne della tabella sinistra, oltre alle colonne della tabella destra. Per assicurare prestazioni migliori, se una tabella è sempre più piccola dell'altra, usarla come lato sinistro dell'operatore join.
L'immagine seguente fornisce una rappresentazione visiva dell'operazione eseguita da ogni join.

Sintassi
LeftTable|join [ JoinFlavor ] [=kindHints ] (RightTable)onCondizioni
Altre informazioni sulle convenzioni di sintassi.
Parametri
| Nome | Tipo | Obbligatoria | Descrizione |
|---|---|---|---|
| LeftTable | string |
✔️ | La tabella sinistra o l'espressione tabulare, talvolta denominata tabella esterna, le cui righe devono essere unite. Indicata come $left. |
| JoinFlavor | string |
Tipo di join da eseguire: inneruniquefullouterinnerrightouterrightsemileftouterleftantirightantileftsemi, . Il valore predefinito è innerunique. Per altre informazioni sui sapori di join, vedere Restituisce. |
|
| Hint | string |
Zero o più hint di join separati dallo spazio sotto forma diValorenome= che controllano il comportamento dell'operazione di corrispondenza di riga e del piano di esecuzione. Per altre informazioni, vedere Hint. |
|
| RightTable | string |
✔️ | La tabella destra o l'espressione tabulare, talvolta denominata tabella interna, le cui righe devono essere unite. Indicata come $right. |
| Condizioni | string |
✔️ | Determina la corrispondenza delle righe da LeftTable con righe da RightTable. Se le colonne corrispondenti hanno lo stesso nome in entrambe le tabelle, usare la sintassi ONColumnName. In caso contrario, usare la sintassi ON $left.LeftColumn RightColumn==$right.. Per specificare più condizioni, è possibile usare la parola chiave "and" o separarle con virgole. Se si usano virgole, le condizioni vengono valutate usando l'operatore logico "e". |
Suggerimento
Per ottenere prestazioni ottimali, se una tabella è sempre più piccola dell'altra, usarla come lato sinistro del join.
Hint
| Chiave hint | Valori | Descrizione |
|---|---|---|
hint.remote |
auto, left, local, right |
Vedere Join tra cluster |
hint.strategy=broadcast |
Specifica il modo per condividere il carico di query nei nodi del cluster. | Vedere join di trasmissione |
hint.shufflekey=<key> |
La shufflekey query condivide il carico di query nei nodi del cluster usando una chiave per partizionare i dati. |
Vedere query shuffle |
hint.strategy=shuffle |
La shuffle query strategia condivide il carico di query nei nodi del cluster, in cui ogni nodo elabora una partizione dei dati. |
Vedere query shuffle |
| Nome | Valori | Descrizione |
|---|---|---|
hint.remote |
auto, left, local, right |
|
hint.strategy=broadcast |
Specifica il modo per condividere il carico di query nei nodi del cluster. | Vedere join di trasmissione |
hint.shufflekey=<key> |
La shufflekey query condivide il carico di query nei nodi del cluster usando una chiave per partizionare i dati. |
Vedere query shuffle |
hint.strategy=shuffle |
La shuffle query strategia condivide il carico di query nei nodi del cluster, in cui ogni nodo elabora una partizione dei dati. |
Vedere query shuffle |
Nota
Gli hint join non modificano la semantica di join ma possono influire sulle prestazioni.
Restituisce
Lo schema restituito e le righe dipendono dal sapore di join. Il sapore di join viene specificato con la parola chiave tipo . Nella tabella seguente vengono illustrati i tipi di join supportati. Per visualizzare esempi per un sapore di join specifico, selezionare il collegamento nella colonna Aggiungi sapore .
| Tipo di join | Restituisce | Illustrazione |
|---|---|---|
| innerunique (impostazione predefinita) | Inner join con deduplicazione del lato sinistro Schema: tutte le colonne di entrambe le tabelle, incluse le chiavi corrispondenti Righe: tutte le righe deduplicate della tabella sinistra che corrispondono alle righe della tabella destra |

|
| Interno | Inner join standard Schema: tutte le colonne di entrambe le tabelle, incluse le chiavi corrispondenti Righe: solo le righe corrispondenti di entrambe le tabelle |

|
| leftouter | Left outer join Schema: tutte le colonne di entrambe le tabelle, incluse le chiavi corrispondenti Righe: tutti i record della tabella sinistra e solo le righe corrispondenti della tabella destra |
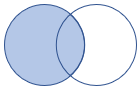
|
| rightouter | Right outer join Schema: tutte le colonne di entrambe le tabelle, incluse le chiavi corrispondenti Righe: tutti i record della tabella destra e solo le righe corrispondenti della tabella sinistra |

|
| fullouter | Full outer join Schema: tutte le colonne di entrambe le tabelle, incluse le chiavi corrispondenti Righe: tutti i record di entrambe le tabelle con celle non corrispondenti popolate con valori Null |

|
| leftsemi | Semi join di sinistra Schema: tutte le colonne della tabella sinistra Righe: tutti i record della tabella sinistra che corrispondono ai record della tabella destra |

|
leftanti, anti, leftantisemi |
Variante anti join e semi join di sinistra Schema: tutte le colonne della tabella sinistra Righe: tutti i record della tabella sinistra che non corrispondono ai record della tabella destra |
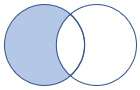
|
| rightsemi | Semi join di destra Schema: tutte le colonne della tabella destra Righe: tutti i record della tabella destra che corrispondono ai record della tabella sinistra |

|
rightanti, rightantisemi |
Variante anti join e semi join di destra Schema: tutte le colonne della tabella destra Righe: tutti i record della tabella destra che non corrispondono ai record della tabella sinistra |

|
Cross join
KQL non fornisce un tipo di cross join. È tuttavia possibile ottenere un effetto cross-join usando un approccio basato sulla chiave segnaposto.
Nell'esempio seguente viene aggiunta una chiave segnaposto a entrambe le tabelle e quindi usata per l'operazione di inner join, ottenendo in modo efficace un comportamento simile al cross join:
X | extend placeholder=1 | join kind=inner (Y | extend placeholder=1) on placeholder
Contenuti correlati
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per