Che cos'è il pool SQL dedicato (in precedenza SQL Data Warehouse) in Azure Synapse Analytics?
Azure Synapse Analytics è un servizio di analisi che riunisce data warehousing aziendale e analisi di Big Data. Per pool SQL dedicato (in precedenza SQL Data Warehouse) si intendono le funzionalità di data warehousing aziendali disponibili in Azure Synapse.
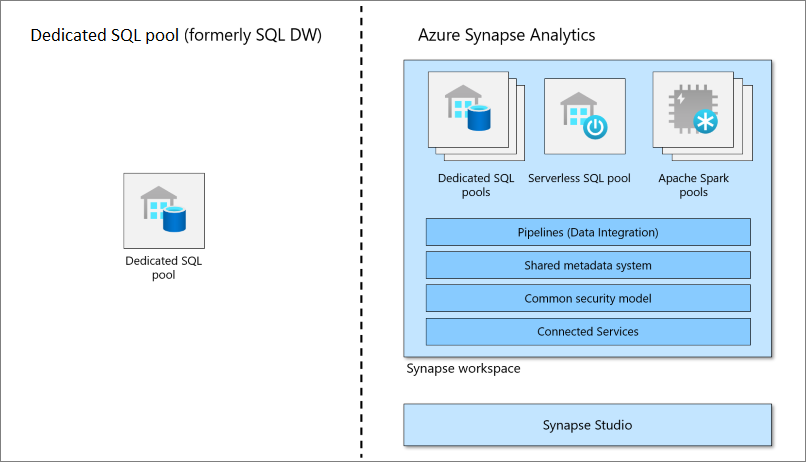
Il pool SQL dedicato (in precedenza SQL Data Warehouse) rappresenta una raccolta di risorse di analisi di cui viene effettuato il provisioning quando si usa Synapse SQL. Le dimensioni di un pool SQL dedicato (in precedenza SQL Data Warehouse) sono determinate da unità Data Warehouse (DWU).
Una volta creato un pool SQL dedicato, è possibile importare i Big Data con semplici query T-SQL PolyBase e quindi sfruttare la potenza del motore di query distribuito per eseguire analisi a elevate prestazioni. Man mano che si procede con l'integrazione e l'analisi dei dati, il pool SQL dedicato (in precedenza SQL Data Warehouse) diventerà il punto di riferimento dell'azienda da cui ricavare più rapidamente informazioni dettagliate più affidabili.
Nota
Non tutte le funzionalità del pool SQL dedicato nelle aree di lavoro di Azure Synapse si applicano al pool SQL dedicato (in precedenza SQL Data Warehouse) e viceversa. Per abilitare le funzionalità dell'area di lavoro per un pool SQL dedicato esistente (in precedenza SQL Data Warehouse) vedere Come abilitare un'area di lavoro per il pool SQL dedicato (in precedenza SQL Data Warehouse). Per altre informazioni, vedere Qual è la differenza tra pool SQL dedicati di Azure Synapse (in precedenza SQL Data Warehouse) e pool SQL dedicati in un'area di lavoro di Azure Synapse Analytics?. Esplorare la documentazione di Azure Synapse Analytics e Introduzione ad Azure Synapse.
Componente chiave di una soluzione per Big Data
Il data warehouse è un componente chiave di una soluzione per Big Data end-to-end basata sul cloud.

In una soluzione per i dati cloud, i dati vengono inseriti in archivi di Big Data da diverse origini. Una volta posizionati in un archivio di Big Data, Hadoop, Spark e gli algoritmi di Machine Learning preparano ed eseguono il training dei dati. Quando i dati sono pronti per essere sottoposti ad analisi complesse, il pool SQL dedicato usa PolyBase per eseguire query sugli archivi di Big Data. PolyBase usa query T-SQL standard per inserire i dati in tabelle del pool SQL dedicato (in precedenza SQL Data Warehouse).
Il pool SQL dedicato (in precedenza SQL Data Warehouse) archivia i dati in tabelle relazionali con archiviazione a colonne. Questo formato consente di ridurre notevolmente i costi di archiviazione dei dati e di migliorare le prestazioni delle query. Una volta archiviati i dati, è possibile eseguire l'analisi su larga scala. Rispetto ai sistemi di database tradizionali, le query di analisi vengono completate in pochi secondi anziché in minuti o in ore anziché in giorni.
I risultati delle analisi possono essere passati ad applicazioni o database di report in tutto il mondo. Gli analisti aziendali possono quindi ottenere informazioni dettagliate per prendere decisioni ben informate.
Passaggi successivi
- Esplorare l'architettura di Azure Synapse
- Creare un pool SQL dedicato in tempi rapidi
- Caricare dati di esempio.
- Esplorare i video
- Introduzione ad Azure Synapse
- Qual è la differenza tra pool SQL dedicati di Azure Synapse (in precedenza SQL Data Warehouse) e pool SQL dedicati in un'area di lavoro di Azure Synapse Analytics?
In alternativa, esaminare alcune di queste altre risorse di Azure Synapse:
- Eseguire ricerche nei blog
- Inviare richieste di funzionalità
- Creare un ticket di supporto
- Eseguire ricerche nella Pagina delle domande di Domande e risposte Microsoft
- Eseguire ricerche nel forum di Stack Overflow