Risolvere i problemi di connettività dell'endpoint XMLA
Gli endpoint XMLA in Power BI si basano sul protocollo di comunicazione nativo di Analysis Services per l'accesso ai modelli semantici di Power BI. Per questo motivo, la risoluzione dei problemi degli endpoint XMLA equivale alla risoluzione dei problemi di una connessione tipica di Analysis Services. Tuttavia, si applicano alcune differenze rispetto alle dipendenze specifiche di Power BI.
Operazioni preliminari
Prima di risolvere uno scenario di endpoint XMLA, assicurarsi di esaminare le nozioni di base illustrate in Connettività del modello semantico con l'endpoint XMLA. Sono illustrati i casi d'uso più comuni dell'endpoint XMLA. Altre guide alla risoluzione dei problemi di Power BI, ad esempio Risolvere i problemi dei gateway- Power BI e Risoluzione dei problemi di Analisi in Excel, possono essere utili.
Abilitazione dell'endpoint XMLA
L'endpoint XMLA può essere abilitato nelle capacità power BI Premium, Premium per utente e Power BI Embedded. Nelle capacità più piccole, ad esempio una capacità A1 con solo 2,5 GB di memoria, è possibile che si verifichi un errore nelle impostazioni capacità quando si tenta di impostare l'endpoint XMLA su Lettura/Scrittura e quindi selezionando Applica. L'errore indica che si è verificato un problema con le impostazioni del carico di lavoro. Riprovare un po'.
Ecco un paio di cose da provare:
- Limitare il consumo di memoria di altri servizi sulla capacità, ad esempio flussi di dati, al 40% o meno, o disabilitare completamente un servizio non necessario.
- Aggiornare la capacità a uno SKU più grande. Ad esempio, l'aggiornamento da A1 a una capacità A3 risolve questo problema di configurazione senza dover disabilitare i flussi di dati.
Tenere presente che è necessario abilitare anche l'impostazione Esporta dati a livello di tenant nel portale di Power BI Amministrazione. Questa impostazione è necessaria anche per la funzionalità Analizza in Excel.
Stabilire una connessione client
Dopo aver abilitato l'endpoint XMLA, è consigliabile testare la connettività a un'area di lavoro sulla capacità. Per altre informazioni, vedere Connessione a un'area di lavoro Premium. Assicurarsi inoltre di leggere la sezione Connessione requisiti di Connessione ion per suggerimenti utili e informazioni sulle limitazioni di connettività XMLA correnti.
Connessione con un'entità servizio
Se sono state abilitate le impostazioni del tenant per consentire alle entità servizio di usare API Power BI, come descritto in Abilitare le entità servizio, è possibile connettersi a un endpoint XMLA usando un'entità servizio. Tenere presente che l'entità servizio richiede lo stesso livello di autorizzazioni di accesso a livello di area di lavoro o di modello semantico degli utenti normali.
Per usare un'entità servizio, assicurarsi di specificare le informazioni sull'identità dell'applicazione nel stringa di connessione come:
User ID=<app:appid@tenantid>Password=<application secret>
Ad esempio:
Data Source=powerbi://api.powerbi.com/v1.0/myorg/Contoso;Initial Catalog=PowerBI_Dataset;User ID=app:91ab91bb-6b32-4f6d-8bbc-97a0f9f8906b@19373176-316e-4dc7-834c-328902628ad4;Password=6drX...;
Se viene visualizzato l'errore seguente:
"Non è possibile connettersi al modello semantico a causa di informazioni di account incomplete. Per le entità servizio, assicurarsi di specificare l'ID tenant insieme all'ID app usando il formato app:<appId@<tenantId>>, quindi riprovare."
Assicurarsi di specificare l'ID tenant insieme all'ID app usando il formato corretto.
È anche possibile specificare l'ID app senza l'ID tenant. In questo caso, tuttavia, è necessario sostituire l'alias myorg nell'URL dell'origine dati con l'ID tenant effettivo. Power BI può quindi individuare l'entità servizio nel tenant corretto. Tuttavia, come procedura consigliata, usare l'alias myorg e specificare l'ID tenant insieme all'ID app nel parametro ID utente.
Connessione ing con Microsoft Entra B2B
Con il supporto per Microsoft Entra business to business (B2B) in Power BI, è possibile fornire agli utenti guest esterni l'accesso ai modelli semantici sull'endpoint XMLA. Assicurarsi che l'impostazione Condividi contenuto con utenti esterni sia abilitata nel portale di Power BI Amministrazione. Per altre informazioni, vedere Distribuire il contenuto di Power BI agli utenti guest esterni con Microsoft Entra B2B.
Distribuzione di un modello semantico
È possibile distribuire un progetto di modello tabulare in Visual Studio (SSDT) in un'area di lavoro assegnata a una capacità Premium, molto uguale a quella di una risorsa server in Azure Analysis Services. Tuttavia, quando si distribuisce sono presenti alcune considerazioni aggiuntive. Assicurarsi di esaminare la sezione Distribuire progetti di modello da Visual Studio (SSDT) nell'articolo Connettività del modello semantico con l'endpoint XMLA.
Distribuzione di un nuovo modello
Nella configurazione predefinita, Visual Studio tenta di elaborare il modello come parte dell'operazione di distribuzione per caricare i dati nel modello semantico dalle origini dati. Come descritto in Distribuire progetti modello da Visual Studio (SSDT), questa operazione può avere esito negativo perché le credenziali dell'origine dati non possono essere specificate come parte dell'operazione di distribuzione. Se invece le credenziali per l'origine dati non sono già definite per uno dei modelli semantici esistenti, è necessario specificare le credenziali dell'origine dati nelle impostazioni del modello semantico usando l'interfaccia utente di Power BI (Modelli> semantici Impostazioni> Credenziali di origine Dati Modifica credenziali).> Dopo aver definito le credenziali dell'origine dati, Power BI può quindi applicare automaticamente le credenziali a questa origine dati per qualsiasi nuovo modello semantico, dopo che la distribuzione dei metadati è stata completata e il modello semantico è stato creato.
Se Power BI non è in grado di associare il nuovo modello semantico alle credenziali dell'origine dati, verrà visualizzato un errore che indica che non è possibile elaborare il database. Motivo: Impossibile salvare le modifiche apportate al server." con il codice di errore "DMTS_DatasourceHasNoCredentialError", come illustrato di seguito:
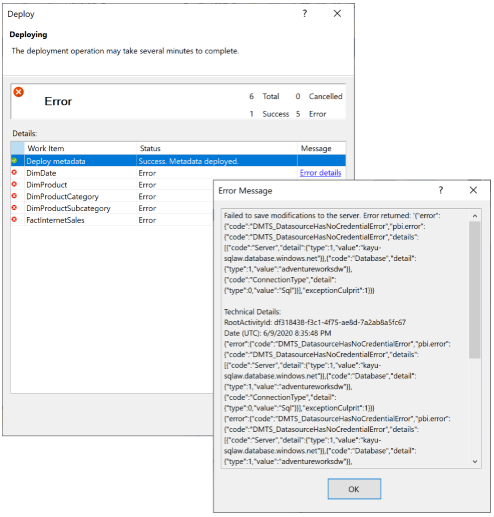
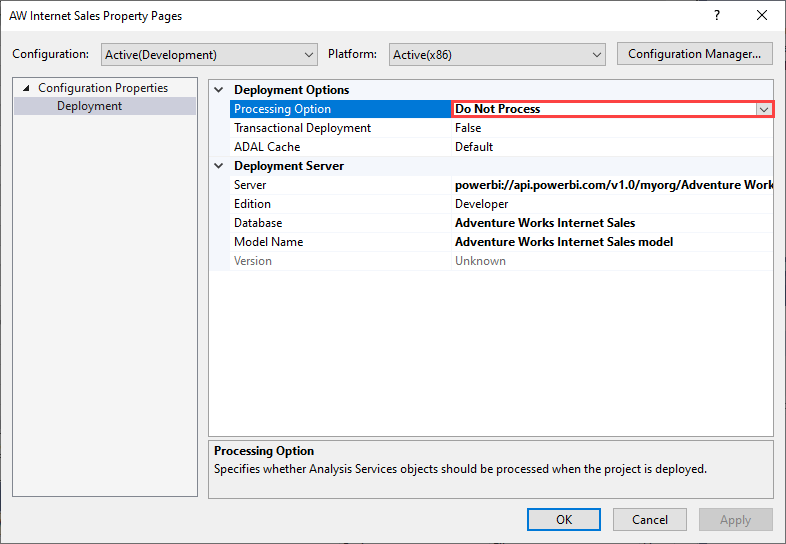
Per evitare l'errore di elaborazione, impostare Opzioni di elaborazione opzioni> di distribuzione su Non elaborare, come illustrato nell'immagine seguente. Visual Studio distribuisce quindi solo i metadati. È quindi possibile configurare le credenziali dell'origine dati e fare clic su Aggiorna ora per il modello semantico nell'interfaccia utente di Power BI.
Nuovo progetto da un modello semantico esistente
La creazione di un nuovo progetto tabulare in Visual Studio importando i metadati da un modello semantico esistente non è supportata. Tuttavia, è possibile connettersi al modello semantico usando SQL Server Management Studio, creare lo script dei metadati e riutilizzarlo in altri progetti tabulari.
Migrazione di un modello semantico a Power BI
È consigliabile specificare il livello di compatibilità 1500 (o superiore) per i modelli tabulari. Questo livello di compatibilità supporta la maggior parte delle funzionalità e dei tipi di origine dati. I livelli di compatibilità successivi sono compatibili con le versioni precedenti.
Provider di dati supportati
A livello di compatibilità 1500, Power BI supporta i tipi di origine dati seguenti:
- Origini dati del provider (legacy con un stringa di connessione nei metadati del modello).
- Origini dati strutturate (introdotte con il livello di compatibilità 1400).
- Dichiarazioni M inline delle origini dati (come le dichiara Power BI Desktop).
È consigliabile usare origini dati strutturate, create da Visual Studio per impostazione predefinita durante l'esecuzione del flusso di dati di importazione. Tuttavia, se si prevede di eseguire la migrazione di un modello esistente a Power BI che usa un'origine dati del provider, assicurarsi che l'origine dati del provider si basi su un provider di dati supportato. In particolare, il Microsoft OLE DB Driver per SQL Server e qualsiasi driver ODBC di terze parti. Per OLE DB Driver per SQL Server, è necessario passare la definizione dell'origine dati al provider di dati .NET Framework per SQL Server. Per i driver ODBC di terze parti che potrebbero non essere disponibili nella servizio Power BI, è invece necessario passare a una definizione di origine dati strutturata.
È anche consigliabile sostituire i Microsoft OLE DB Driver per SQL Server obsoleti (SQLNCLI11) nelle definizioni dell'origine dati di SQL Server con .NET Framework provider di dati per SQL Server.
La tabella seguente fornisce un esempio di provider di dati .NET Framework per SQL Server stringa di connessione sostituendo un stringa di connessione corrispondente per il OLE DB Driver per SQL Server.
| Driver OLE DB per SQL Server | Provider di dati .NET Framework per SQL Server |
|---|---|
Provider=SQLNCLI11;Data Source=sqldb.database.windows.net;Initial Catalog=AdventureWorksDW;Trusted_Connection=yes; |
Data Source=sqldb.database.windows.net;Initial Catalog=AdventureWorksDW2016;Integrated Security=SSPI;Encrypt=true;TrustServerCertificate=false |
Riferimenti incrociati alle origini di partizione
Come esistono più tipi di origine dati, esistono anche più tipi di origine partizione che un modello tabulare può includere per importare dati in una tabella. In particolare, una partizione può usare un'origine di partizione di query o un'origine di partizione M. Questi tipi di origine di partizione, a loro volta, possono fare riferimento a origini dati provider o origini dati strutturate. Mentre i modelli tabulari in Azure Analysis Services supportano il riferimento incrociato a questi diversi tipi di origine dati e partizione, Power BI applica una relazione più rigorosa. Le origini delle partizioni di query devono fare riferimento alle origini dati del provider e le origini di partizione M devono fare riferimento a origini dati strutturate. Altre combinazioni non sono supportate in Power BI. Se si vuole eseguire la migrazione di un modello semantico di riferimento incrociato, la tabella seguente descrive le configurazioni supportate:
| Origine dati | Origine partizione | Commenti | Supportato con l'endpoint XMLA |
|---|---|---|---|
| Origine dati provider | Origine della partizione di query | Il motore AS usa lo stack di connettività basato su munizioni per accedere all'origine dati. | Sì |
| Origine dati provider | Origine partizione M | Il motore AS converte l'origine dati del provider in un'origine dati strutturata generica e quindi usa il motore Mashup per importare i dati. | No |
| Origine dati strutturata | Origine della partizione di query | Il motore AS esegue il wrapping della query nativa nell'origine della partizione in un'espressione M e quindi usa il motore Mashup per importare i dati. | No |
| Origine dati strutturata | Origine partizione M | Il motore AS usa il motore Mashup per importare i dati. | Sì |
Origini dati e rappresentazione
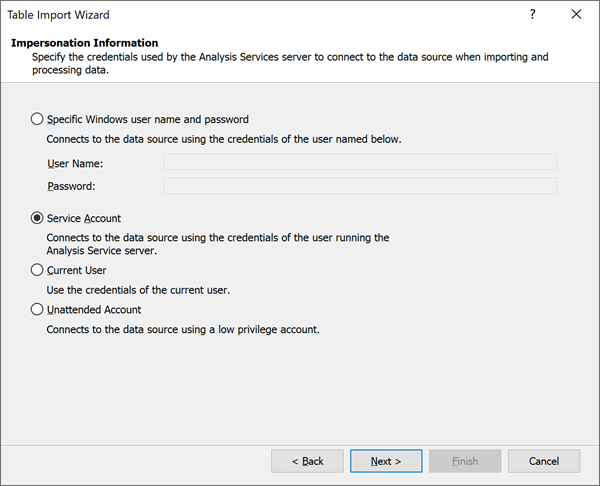
Le impostazioni di rappresentazione che è possibile definire per le origini dati del provider non sono rilevanti per Power BI. Power BI usa un meccanismo diverso basato sulle impostazioni del modello semantico per gestire le credenziali dell'origine dati. Per questo motivo, assicurarsi di selezionare Account del servizio se si sta creando un'origine dati provider.
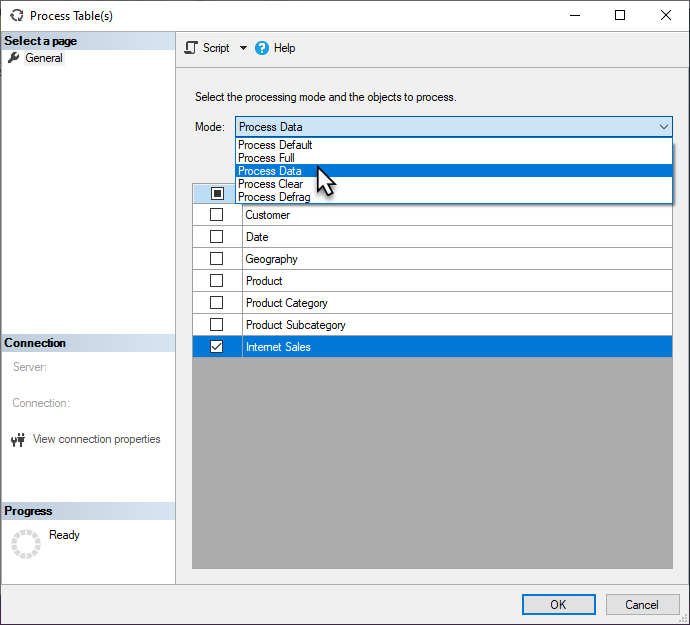
Elaborazione con granularità fine
Quando si attiva un aggiornamento pianificato o su richiesta in Power BI, Power BI aggiorna in genere l'intero modello semantico. In molti casi, è più efficiente eseguire gli aggiornamenti in modo più selettivo. È possibile eseguire attività di elaborazione con granularità fine in SQL Server Management Studio (SSMS) come illustrato di seguito o usando strumenti o script di terze parti.
Override nel comando Aggiorna TMSL
Le sostituzioni nel comando Refresh (TMSL) consentono agli utenti di scegliere una definizione di query di partizione diversa o una definizione di origine dati per l'operazione di aggiornamento.
Sottoscrizioni tramite posta elettronica
I modelli semantici aggiornati usando un endpoint XMLA non attivano una sottoscrizione di posta elettronica.
Errori nella capacità Premium
errore da Connessione al server in SSMS
Quando ci si connette a un'area di lavoro di Power BI con SQL Server Management Studio (SSMS), potrebbe essere visualizzato l'errore seguente:
TITLE: Connect to Server
------------------------------
Cannot connect to powerbi://api.powerbi.com/v1.0/[tenant name]/[workspace name].
------------------------------
ADDITIONAL INFORMATION:
The remote server returned an error: (400) Bad Request.
Technical Details:
RootActivityId:
Date (UTC): 10/6/2021 1:03:25 AM (Microsoft.AnalysisServices.AdomdClient)
------------------------------
The remote server returned an error: (400) Bad Request. (System)
Quando ci si connette a un'area di lavoro di Power BI con SSMS, verificare quanto segue:
- L'impostazione dell'endpoint XMLA è abilitata per la capacità del tenant. Per altre informazioni, vedere Abilitare la lettura/scrittura XMLA.
- L'impostazione Consenti endpoint XMLA e Analizza in Excel con modelli semantici locali è abilitata nelle impostazioni tenant.
- Si sta usando la versione più recente di SSMS. Scaricare la versione più recente.
Esecuzione di query in SSMS
Quando si è connessi a un'area di lavoro in power BI Premium o a una capacità di Power BI Embedded , SQL Server Management Studio potrebbe visualizzare l'errore seguente:
Executing the query ...
Error -1052311437: We had to move the session with ID '<Session ID>' to another Power BI Premium node. Moving the session temporarily interrupted this trace - tracing will resume automatically as soon as the session has been fully moved to the new node.
Si tratta di un messaggio informativo che può essere ignorato in SSMS 18.8 e versioni successive perché le librerie client si riconnetteranno automaticamente. Si noti che le librerie client installate con SSMS v18.7.1 o versioni precedenti non supportano la traccia delle sessioni. Scaricare la versione più recente di SSMS.
Esecuzione di un comando di grandi dimensioni tramite l'endpoint XMLA
Quando si esegue un comando di grandi dimensioni usando l'endpoint XMLA, è possibile che venga visualizzato l'errore seguente:
Executing the query ...
Error -1052311437:
The remote server returned an error: (400) Bad Request.
Technical Details:
RootActivityId: 3716c0f7-3d01-4595-8061-e6b2bd9f3428
Date (UTC): 11/13/2020 7:57:16 PM
Run complete
Quando si usa SSMS v18.7.1 o versione precedente per eseguire un'operazione di aggiornamento a esecuzione prolungata (>1 min) in un modello semantico in power BI Premium o in una capacità di Power BI Embedded , SSMS potrebbe visualizzare questo errore anche se l'operazione di aggiornamento ha esito positivo. Ciò è dovuto a un problema noto nelle librerie client in cui lo stato della richiesta di aggiornamento viene rilevato in modo non corretto. Questo problema viene risolto in SSMS 18.8 e versioni successive. Scaricare la versione più recente di SSMS.
Questo errore può verificarsi anche quando è necessario reindirizzare una richiesta molto grande a un nodo diverso nel cluster Premium. Viene spesso visualizzato quando si tenta di creare o modificare un modello semantico usando uno script TMSL di grandi dimensioni. In questi casi, l'errore può in genere essere evitato specificando il catalogo iniziale al nome del database prima di eseguire il comando .
Quando si crea un nuovo database, è possibile creare un modello semantico vuoto, ad esempio:
{
"create": {
"database": {
"name": "DatabaseName"
}
}
}
Dopo aver creato il nuovo modello semantico, specificare il catalogo iniziale e quindi apportare modifiche al modello semantico.
Altre applicazioni client e strumenti
Le applicazioni client e gli strumenti, ad esempio Excel, Power BI Desktop, SSMS o strumenti esterni che si connettono e utilizzano modelli semantici nelle capacità di Power BI Premium, possono causare l'errore seguente: Il server remoto ha restituito un errore: (400) Richiesta non valida. L'errore può essere causato soprattutto se una query DAX sottostante o un comando XMLA è a esecuzione prolungata. Per ridurre i potenziali errori, assicurarsi di usare le applicazioni e gli strumenti più recenti che installano le versioni recenti delle librerie client di Analysis Services con aggiornamenti regolari. Indipendentemente dall'applicazione o dallo strumento, le versioni minime della libreria client necessarie per connettersi e lavorare con i modelli semantici in una capacità Premium tramite l'endpoint XMLA sono:
| Libreria client | Versione |
|---|---|
| MSOLAP | 15.1.65.22 |
| AMO | 19.12.7.0 |
| ADOMD | 19.12.7.0 |
Modifica delle appartenenze ai ruoli in SSMS
Quando si usa SQL Server Management Studio (SSMS) v18.8 per modificare un'appartenenza a un ruolo in un modello semantico, SSMS potrebbe visualizzare l'errore seguente:
Failed to save modifications to the server.
Error returned: ‘Metadata change of current operation cannot be resolved, please check the command or try again later.’
Ciò è dovuto a un problema noto nell'API REST dei servizi app. Questo problema verrà risolto in una versione futura. Nel frattempo, per risolvere questo errore, in Proprietà ruolo fare clic su Script, quindi immettere ed eseguire il comando TMSL seguente:
{
"createOrReplace": {
"object": {
"database": "AdventureWorks",
"role": "Role"
},
"role": {
"name": "Role",
"modelPermission": "read",
"members": [
{
"memberName": "xxxx",
"identityProvider": "AzureAD"
},
{
"memberName": “xxxx”
"identityProvider": "AzureAD"
}
]
}
}
}
Errore di pubblicazione - Modello semantico connesso in tempo reale
Quando si ripubblica un modello semantico connesso in tempo reale utilizzando il connettore Analysis Services, l'errore seguente indica che esiste un modello semantico/report esistente con lo stesso nome. Eliminare o rinominare il modello semantico esistente e riprovare. può essere visualizzato.
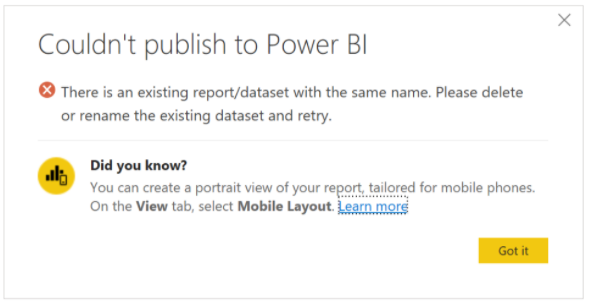
Ciò è dovuto alla pubblicazione del modello semantico con un stringa di connessione diverso ma con lo stesso nome del modello semantico esistente. Per risolvere questo problema, eliminare o rinominare il modello semantico esistente. Assicurarsi anche di ripubblicare tutte le app dipendenti dal report. Se necessario, gli utenti downstream devono essere informati per aggiornare eventuali segnalibri con il nuovo indirizzo del report per assicurarsi che accevano al report più recente.
Alias dell'area di lavoro/server
A differenza di Azure Analysis Services, glialias dei nomi del server non sono supportati per le aree di lavoro Premium.
DISCOVER_M_EXPRESSIONS
La DMV DISCOVER_M_EXPRESSIONS vista di gestione dei dati (DMV) non è attualmente supportata in Power BI tramite l'endpoint XMLA. Le applicazioni possono usare il modello a oggetti tabulare (TOM) per ottenere le espressioni M usate dal modello di dati.
Limite di memoria dei comandi per la gestione delle risorse in Premium
Le capacità Premium usano la governance delle risorse per garantire che nessuna singola operazione del modello semantico possa superare la quantità di risorse di memoria disponibili per la capacità, determinata dallo SKU. Ad esempio, una sottoscrizione P1 ha un limite di memoria effettivo per elemento di 25 GB, per una sottoscrizione P2 il limite è 50 GB e per una sottoscrizione P3 il limite è 100 GB. Oltre alle dimensioni del modello semantico (database), il limite di memoria effettivo si applica anche alle operazioni di comando del modello semantico sottostanti, ad esempio Create, Alter e Refresh.
Il limite di memoria effettivo per un comando si basa sul minore del limite di memoria della capacità (determinato dallo SKU) o sul valore della proprietà DbpropMsmdRequestMemoryLimit XMLA.
Ad esempio, per una capacità P1, se:
DbpropMsmdRequestMemoryLimit = 0 (o non specificato), il limite di memoria effettivo per il comando è 25 GB.
DbpropMsmdRequestMemoryLimit = 5 GB, il limite di memoria effettivo per il comando è 5 GB.
DbpropMsmdRequestMemoryLimit = 50 GB, il limite di memoria effettivo per il comando è 25 GB.
In genere, il limite di memoria effettivo per un comando viene calcolato sulla memoria consentita per il modello semantico in base alla capacità (25 GB, 50 GB, 100 GB) e alla quantità di memoria già utilizzata dal modello semantico all'avvio dell'esecuzione del comando. Ad esempio, un modello semantico che usa 12 GB in una capacità P1 consente un limite di memoria effettivo per un nuovo comando di 13 GB. Tuttavia, il limite di memoria effettivo può essere ulteriormente vincolato dalla proprietà DbPropMsmdRequestMemoryLimit XMLA quando facoltativamente specificato da un'applicazione. Usando l'esempio precedente, se si specificano 10 GB nella proprietà DbPropMsmdRequestMemoryLimit, il limite effettivo del comando viene ulteriormente ridotto a 10 GB.
Se l'operazione di comando tenta di utilizzare una quantità di memoria superiore a quella consentita dal limite, l'operazione può non riuscire e viene restituito un errore. Ad esempio, l'errore seguente descrive un limite di memoria effettivo di 25 GB (capacità P1) superato perché il modello semantico ha già utilizzato 12 GB (12288 MB) all'avvio dell'esecuzione del comando e un limite effettivo di 13 GB (13312 MB) è stato applicato per l'operazione di comando:
"Gestione delle risorse: questa operazione è stata annullata perché non c'era memoria sufficiente per completare l'esecuzione. Aumentare la memoria della capacità Premium in cui è ospitato questo modello semantico o ridurre il footprint di memoria del modello semantico, limitando la quantità di dati importati. Altri dettagli: memoria utilizzata 13312 MB, limite di memoria di 13312 MB, dimensioni del database prima dell'esecuzione del comando 12288 MB. Altre informazioni: https://go.microsoft.com/fwlink/?linkid=2159753".
In alcuni casi, come illustrato nell'errore seguente, "memoria utilizzata" è 0, ma la quantità mostrata per "dimensioni del database prima dell'esecuzione del comando" è già maggiore del limite di memoria effettivo. Ciò significa che l'operazione non è riuscita ad avviare l'esecuzione perché la quantità di memoria già usata dal modello semantico è maggiore del limite di memoria per lo SKU.
"Gestione delle risorse: questa operazione è stata annullata perché non c'era memoria sufficiente per completare l'esecuzione. Aumentare la memoria della capacità Premium in cui è ospitato questo modello semantico o ridurre il footprint di memoria del modello semantico, limitando la quantità di dati importati. Altri dettagli: memoria utilizzata 0 MB, limite di memoria di 25600 MB, dimensioni del database prima dell'esecuzione del comando 26000 MB. Altre informazioni: https://go.microsoft.com/fwlink/?linkid=2159753".
Per evitare potenzialmente di superare il limite di memoria effettivo:
- Eseguire l'aggiornamento a una dimensione di capacità Premium (SKU) maggiore per il modello semantico.
- Ridurre il footprint di memoria del modello semantico limitando la quantità di dati caricati con ogni aggiornamento.
- Per le operazioni di aggiornamento tramite l'endpoint XMLA, ridurre il numero di partizioni elaborate in parallelo. Troppe partizioni elaborate in parallelo con un singolo comando possono superare il limite di memoria effettivo.
Contenuto correlato
Commenti e suggerimenti
In arrivo: Nel corso del 2024 verranno ritirati i problemi di GitHub come meccanismo di feedback per il contenuto e verranno sostituiti con un nuovo sistema di feedback. Per altre informazioni, vedi: https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per