Concetti fondamentali
Quando Verrà deprecato Advisor metriche?
A partire dal 20 settembre 2023 non sarà possibile creare nuove risorse di Advisor metriche. Il servizio Advisor metriche viene ritirato il 1° ottobre 2026.
Che cosa sono i dati di una serie temporale multidimensionale?
Vedere la definizione di Metrica multidimensionale nel glossario.
Quanti dati sono necessari perché Advisor metriche avvii il rilevamento anomalie?
Il rilevamento anomalie può essere attivato almeno da un punto dati. Ciò non consente tuttavia di ottenere la massima accuratezza. Il servizio presuppone una finestra di punti dati precedenti usando il valore specificato come regola di riempimento durante la creazione del feed di dati.
È consigliabile avere alcuni dati prima del timestamp su cui si vuole eseguire il rilevamento. In base alla granularità dei dati, la quantità di dati consigliata varia come indicato di seguito.
| Granularità | Quantità di dati consigliata per il rilevamento |
|---|---|
| Meno di 5 minuti | 4 giorni di dati |
| Da 5 minuti a 1 giorno | 28 giorni di dati |
| Più di 1 giorno fino a 31 giorni | 4 anni di dati |
| Più di 31 giorni | 48 anni di dati |
Quali dati vengono elaborati da Advisor metriche e come vengono conservati i dati?
- Advisor metriche elabora i dati delle serie temporali raccolti dall'origine dati di un cliente, i dati cronologici vengono usati per la selezione del modello e determinano il limite dei dati previsto.
- I dati delle serie temporali del cliente e i risultati dell'inferenza verranno archiviati all'interno del servizio. Advisor metriche non archivia o elabora i dati dei clienti all'esterno dell'area in cui il cliente distribuisce l'istanza del servizio.
Perché Advisor metriche non rileva anomalie dai dati cronologici?
Advisor metriche è progettato per il rilevamento dei dati in streaming live. Esiste una limitazione per la lunghezza massima dei dati cronologici a cui il servizio risalirà per eseguire il rilevamento anomalie. Di conseguenza, solo i punti dati successivi a un determinato timestamp avranno risultati di rilevamento anomalie. Il timestamp più indietro nel tempo dipende dalla granularità dei dati.
A seconda della granularità dei dati, le lunghezze dei dati cronologici che avranno risultati del rilevamento anomalie sono le seguenti.
| Granularità | Lunghezza massima dei dati cronologici per il rilevamento anomalie |
|---|---|
| Meno di 5 minuti | Tempo di onboarding: 13 ore |
| Da 5 minuti a meno di 1 ora | Tempo di onboarding: 4 giorni |
| Da 1 ora a meno di 1 giorno | Tempo di onboarding: 14 giorni |
| 1 giorno | Tempo di onboarding: 28 giorni |
| Più di 1 giorno, meno di 31 giorni | Tempo di onboarding: 2 anni |
| Più di 31 giorni | Tempo di onboarding: 24 anni |
Quali sono le limitazioni e la conservazione dei dati di Advisor metriche?
- Conservazione dei dati. Advisor metriche manterrà al massimo 10.000 intervalli di tempo che cos'è un intervallo? conteggio in avanti rispetto al timestamp corrente, indipendentemente dalla disponibilità o meno dei dati. I dati che non rientrano nella finestra verranno eliminati. Associazione tra la conservazione dei dati e il numero di giorni per varie granularità delle metriche.
| Granularità (min) | Conservazione (giorno) |
|---|---|
| 1 | 6,94 |
| 5 | 34,72 |
| 15 | 104,1 |
| 60 (ogni ora) | 416,67 |
| 1440 (ogni giorno) | 10.000,00 |
- Limitazione per il numero massimo di serie temporali all'interno di una metrica.
Possono esistere più dimensioni all'interno di una metrica e ogni dimensione può avere più valori. La combinazione massima di dimensioni per una metrica non deve superare 100.000.
- Gli amministratori delle risorse di Advisor metriche e i proprietari dei feed di dati riceveranno una notifica quando viene raggiunto il limite dell'80% nella pagina dei dettagli del feed di dati.
- Se la metrica ha superato la limitazione, il feed di dati verrà sospeso e attendere che i clienti eseguano azioni di completamento. È consigliabile suddividere il feed di dati in più feed di dati usando un filtro.
- Limitazione per il numero massimo di punti dati archiviati in un'istanza di Advisor metriche
Advisor metriche conta sui punti dati totali di tutti i feed di dati di cui è stato eseguito l'onboarding nell'istanza a partire dal primo timestamp di inserimento. Il numero massimo di punti dati da archiviare in un'istanza di Advisor metriche è 2 miliardi.
- Gli amministratori delle risorse di Advisor metriche e tutti gli utenti riceveranno una notifica quando viene raggiunta la limitazione dell'80 % nella pagina dell'elenco dei feed di dati e tramite la pagina aggiungi nuovo feed di dati.
- Se i punti dati totali hanno superato la limitazione, tutti i feed di dati verranno sospesi e anche il nuovo onboarding dei feed verrà bloccato . È consigliabile eliminare i feed di dati inutilizzati o creare una nuova risorsa di Advisor metriche all'interno della sottoscrizione.
Perché non è possibile accedere a Advisor metriche? Il messaggio di errore indica che la risorsa è stata rimossa a causa dell'inattività in 90 giorni.
Esistono due casi in cui una risorsa viene rimossa:
- Viene creata una risorsa di Advisor metriche, ma non è stato eseguito l'onboarding del feed di dati entro 90 giorni. La risorsa verrà rimossa dopo 90 giorni a causa dell'inattività.
- Se sono stati creati uno o più feed di dati, ma non sono presenti nuovi dati inseriti in Advisor metriche, il servizio passerà in modalità inattiva senza dati da elaborare. Il sistema tenterà comunque di acquisire regolarmente i dati dall'origine in base alla granularità delle metriche. Tuttavia, se continua a non avere dati disponibili o nessuna singola serie temporale da elaborare per un periodo di 90 giorni consecutivi, la risorsa verrà rimossa. Tutti i dati cronologici associati alla risorsa andranno persi quando vengono rimossi.
È consigliabile creare una nuova risorsa ed eliminare quella precedente, se si vuole riavviare l'utilizzo.
Come si fa a rilevare picchi e valli come anomalie?
Se sono presenti soglie rigide predefinite, è possibile impostare manualmente la "soglia rigida" nelle configurazioni di rilevamento anomalie. Se non sono presenti soglie, è possibile usare il "rilevamento intelligente", basato sull'intelligenza artificiale. Per informazioni dettagliate, leggere come ottimizzare la configurazione del rilevamento.
Come si fa a rilevare le difformità rispetto a modelli regolari (stagionali) come anomalie?
Il "rilevamento intelligente" è in grado di apprendere il modello dei dati, inclusi i modelli stagionali. Rileva quindi i punti dati che non sono conformi ai modelli regolari come anomalie. Per informazioni dettagliate, leggere come ottimizzare la configurazione del rilevamento.
Advisor metriche supporta le origini dati dietro una rete virtuale?
No, Advisor metriche non supporta attualmente le origini dati che si trovano dietro una rete virtuale.
Come si fa a rilevare le linee piatte come anomalie?
Se i dati sono normalmente abbastanza instabili e soggetti a grandi fluttuazioni e si vuole ricevere una notifica quando diventano troppo stabili o addirittura diventano una linea piatta, è possibile configurare "Change threshold" (Soglia di modifica) in modo da rilevare tali punti dati quando la variazione è troppo piccola. Per informazioni dettagliate, vedere le configurazioni del rilevamento anomalie.
Come si fa a configurare le impostazioni di posta elettronica e abilitare gli avvisi tramite posta elettronica?
Un utente con privilegi di amministratore della sottoscrizione o amministratore del gruppo di risorse deve passare alla risorsa di Advisor metriche creata nel portale di Azure e selezionare la scheda Controllo di accesso (IAM).
Selezionare Aggiungi assegnazioni di ruolo
Scegliere un ruolo Cognitive Services Metrics Advisor Administrator (Amministratore di Advisor metriche di Servizi cognitivi) e selezionare l'account, come mostrato nell'immagine seguente.
Selezionare il pulsante Salva e si viene aggiunti come amministratore della risorsa di Advisor metriche. Tutte le azioni precedenti devono essere eseguite dall'amministratore della sottoscrizione o dall'amministratore del gruppo di risorse.
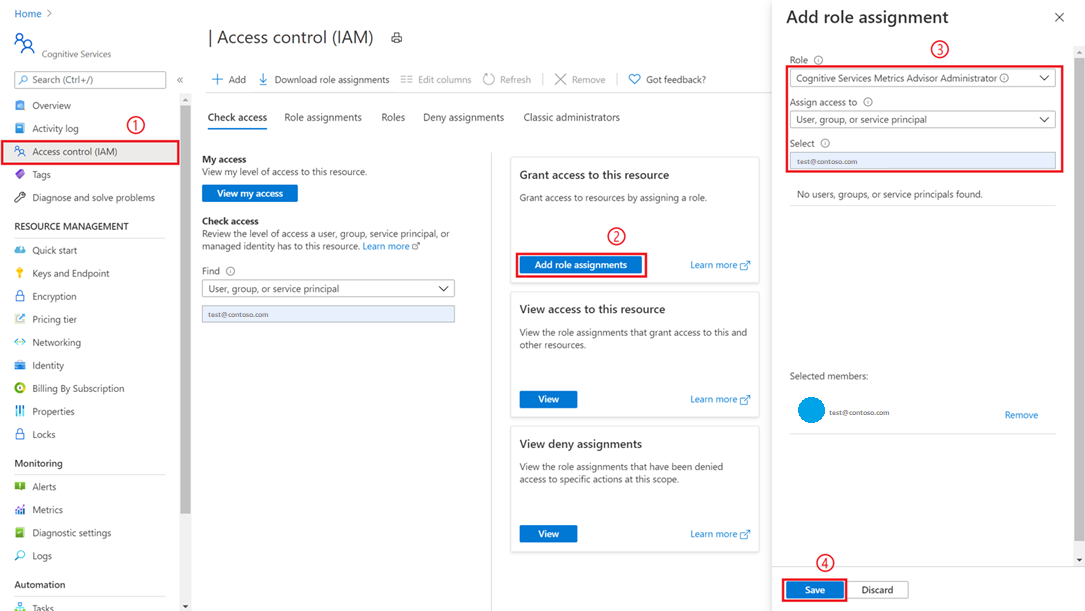
La propagazione delle autorizzazioni potrebbe richiedere fino a un minuto. Selezionare quindi l'area di lavoro Advisor metriche e selezionare l'opzione Email setting (Impostazione posta elettronica) nel riquadro di spostamento a sinistra. Compilare le voci necessarie, in particolare le informazioni relative a SMTP.
Selezionare Salva per completare la configurazione della posta elettronica. È possibile creare nuovi hook e sottoscrivere le anomalie delle metriche per avvisi quasi in tempo reale.

Concetti avanzati
In che modo Advisor metriche crea un albero di diagnostica per le metriche multidimensionali?
Una metrica può essere suddivisa in più serie temporali in base alle dimensioni. Ad esempio, la metrica Response latency viene monitorata per tutti i servizi di proprietà del team. La categoria Service può essere usata come dimensione per arricchire la metrica, ottenendo così Response latency suddivisa per Service1Service2 e così via. Ogni servizio può essere distribuito in computer diversi in più data center, quindi la metrica può essere ulteriormente suddivisa per Machine e Data center.
| Servizioo | Data center | Computer |
|---|---|---|
| S1 | DC1 | M1 |
| S1 | DC1 | M2 |
| S1 | DC2 | M3 |
| S1 | DC2 | M4 |
| S2 | DC1 | M1 |
| S2 | DC1 | M2 |
| S2 | DC2 | M5 |
| S2 | DC2 | M6 |
| ... |
Iniziando dal totale di Response latency, possiamo eseguire il drill-down nella metrica in base a Service, Data center e Machine. Tuttavia, forse è più opportuno che i proprietari dei servizi usino il percorso Service ->Data center>Machine o forse ha più senso per i tecnici dell'infrastruttura usare il percorso Data Center -Machine> - .>Service Tutto dipende dai singoli requisiti aziendali degli utenti.
In Advisor metriche gli utenti possono specificare qualsiasi percorso da eseguire il drill-down o il rollup da un nodo della topologia gerarchica. Più precisamente, la topologia gerarchica è un grafo aciclico diretto anziché una struttura ad albero. Esiste una topologia gerarchica completa costituita da tutte le possibili combinazioni di dimensioni, come la seguente:

In teoria, se la dimensione Service ha Ls valori distinti, la dimensione Data center ha Ldc valori distinti e la dimensione Machine ha Lm valori distinti, potrebbero esserci (Ls + 1) * (Ldc + 1) * (Lm + 1) combinazioni di dimensioni nella topologia gerarchica.
In genere, però, non tutte le combinazioni di dimensioni sono valide, il che può ridurre significativamente la complessità. Attualmente, se gli utenti aggregano la metrica autonomamente, non viene limitato il numero di dimensioni. Se è necessario usare la funzionalità di rollup fornita da Advisor metriche, il numero di dimensioni non deve essere superiore a 6. Tuttavia, il numero di serie temporali espanse per dimensioni per una metrica deve essere inferiore a 10.000.
Lo strumento Diagnostic tree (Albero di diagnostica) nella pagina di diagnostica mostra i nodi in cui è stata rilevata un'anomalia, anziché l'intera topologia. Questo permette di concentrarsi sul problema corrente. Potrebbe anche non mostrare tutte le anomalie all'interno della metrica, mostrando invece le anomalie principali in base all'impatto. In questo modo è possibile individuare rapidamente l'impatto, l'ambito e il percorso di diffusione dei dati anomali. Questo riduce in modo significativo il numero di anomalie su cui è necessario concentrarsi e aiuta gli utenti a comprendere e individuare i problemi chiave.
Ad esempio, quando si verifica un'anomalia in Service = S2 | Data Center = DC2 | Machine = M5, la deviazione dell'anomalia influisce sul nodo Service= S2padre , che ha rilevato anche l'anomalia, ma l'anomalia non influisce sull'intero data center in DC2 e su tutti i servizi in M5. L'albero degli eventi imprevisti verrebbe creato come nello screenshot seguente, l'anomalia principale viene acquisita in Service = S2 e la causa radice può essere analizzata in due percorsi che conducono entrambi a Service = S2 | Data Center = DC2 | Machine = M5.
