Questo scenario di esempio illustra in che modo i dati possono essere inseriti in un ambiente cloud da un data warehouse locale, quindi gestiti usando un modello di Business Intelligence (BI). Questo approccio può essere un obiettivo finale o un primo passo verso la modernizzazione completa con componenti basati sul cloud.
I passaggi seguenti si basano sullo scenario end-to-end di Azure Synapse Analytics. Usa Azure Pipelines per inserire dati da un database SQL in pool SQL di Azure Synapse e quindi trasforma i dati per l'analisi.
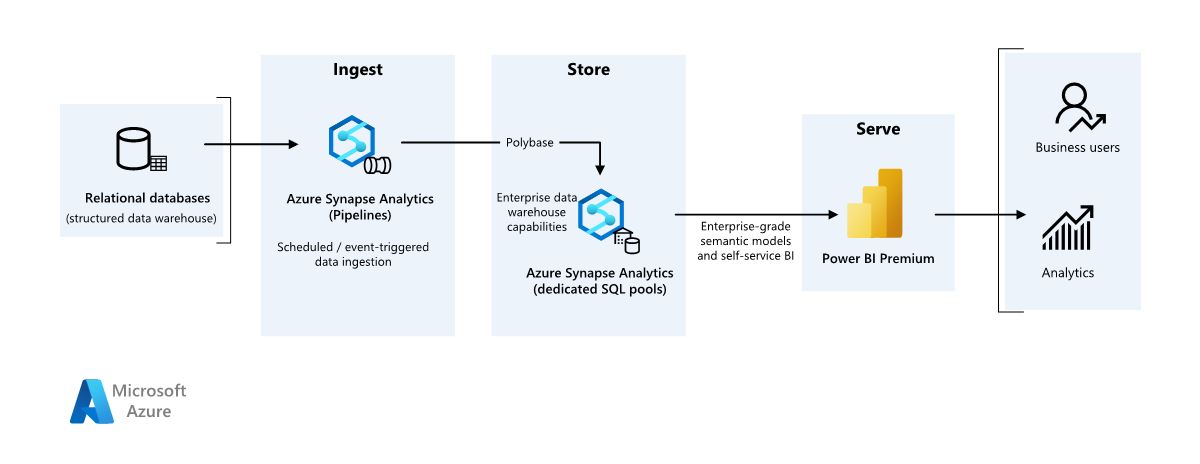
Architettura

Scaricare un file di Visio di questa architettura.
Workflow
Origine dati
- I dati di origine si trovano in un database di SQL Server in Azure. Per simulare l'ambiente locale, gli script di distribuzione per questo scenario effettuano il provisioning di un database SQL di Azure. Il database di esempio AdventureWorks viene usato come schema dei dati di origine e dati di esempio. Per informazioni su come copiare dati da un database locale, vedere Copiare e trasformare i dati da e verso SQL Server.
Inserimento e archiviazione dei dati
Azure Data Lake Gen2 viene usato come area di staging temporanea durante l'inserimento dati. È quindi possibile usare PolyBase per copiare i dati in un pool SQL dedicato di Azure Synapse.
Azure Synapse Analytics è un sistema distribuito progettato per eseguire analisi su dati di grandi dimensioni. Supporta l'elaborazione parallela su larga scala (MPP), che può essere usata per l'esecuzione di analisi ad alte prestazioni. Il pool SQL dedicato di Azure Synapse è una destinazione per l'inserimento continuo da locale. Può essere usato per un'ulteriore elaborazione e per gestire i dati per Power BI tramite DirectQuery.
Azure Pipelines viene usato per orchestrare l'inserimento e la trasformazione dei dati all'interno dell'area di lavoro di Azure Synapse.
Analisi e creazione di report
- L'approccio di modellazione dei dati in questo scenario viene presentato combinando il modello aziendale e il modello semantico bi. Il modello aziendale viene archiviato in un pool SQL dedicato di Azure Synapse e il modello semantico bi viene archiviato nelle capacità di Power BI Premium. Power BI accede ai dati tramite DirectQuery.
Componenti
Questo scenario usa i componenti seguenti:
Architettura semplificata
Dettagli dello scenario
Un'organizzazione ha un data warehouse locale di grandi dimensioni archiviato in un database SQL. L'organizzazione vuole usare Azure Synapse per eseguire l'analisi e quindi usare queste informazioni dettagliate con Power BI.
Autenticazione
Microsoft Entra autentica gli utenti che si connettono a dashboard e app di Power BI. L'accesso Single Sign-On viene usato per connettersi all'origine dati nel pool di cui è stato effettuato il provisioning in Azure Synapse. L'autorizzazione viene eseguita nell'origine.
Caricamento incrementale
Quando si esegue un processo ETL (Extract-Transform-Load) automatizzato o ELT (Extract-Load-Transform), è più efficiente caricare solo i dati modificati dopo l'esecuzione precedente. Si tratta di un caricamento incrementale, anziché di un caricamento completo che carica tutti i dati. Per eseguire un caricamento incrementale, è necessario potere identificare i dati modificati. L'approccio più comune consiste nell'usare un valore di contrassegno di acqua elevato, che tiene traccia dell'ultimo valore di alcune colonne nella tabella di origine, una colonna datetime o una colonna integer univoca.
A partire da SQL Server 2016, è possibile usare tabelle temporali, ovvero tabelle con controllo delle versioni di sistema che mantengono una cronologia completa delle modifiche ai dati. Il motore di database registra automaticamente la cronologia di ogni modifica in una tabella di cronologia separata. È possibile eseguire query sui dati cronologici aggiungendo una FOR SYSTEM_TIME clausola a una query. Internamente, il motore di database esegue una query sulla tabella di cronologia, ma è trasparente per l'applicazione.
Nota
Per le versioni precedenti di SQL Server, è possibile usare Change Data Capture (CDC). Questo approccio risulta meno efficiente rispetto alle tabelle temporali, perché è necessario eseguire query su una tabella di modifiche separata e le modifiche vengono registrate tramite un numero di sequenza di log, invece che un timestamp.
Le tabelle temporali sono utili per i dati relativi alle dimensioni, che possono cambiare nel tempo. Le tabelle dei fatti rappresentano una transazione non modificabile, ad esempio una vendita, e in questo caso la conservazione della cronologia delle versioni di sistema risulta superflua. Le transazioni includono invece in genere una colonna che rappresenta la data della transazione, che può essere usata come valore limite. Ad esempio, nel data warehouse AdventureWorks le SalesLT.* tabelle hanno un LastModified campo.
Ecco il flusso generale per la pipeline ELT:
Per ogni tabella del database di origine, tenere traccia del valore temporale limite relativo all'esecuzione dell'ultimo processo ELT. Archiviare tali informazioni nel data warehouse. Durante l'installazione iniziale, tutte le volte vengono impostate su
1-1-1900.Durante il passaggio di esportazione dei dati, il valore temporale limite viene passato come parametro a un set di stored procedure nel database di origine. Queste stored procedure eseguono query su tutti i record modificati o creati dopo il periodo di interruzione. Per tutte le tabelle dell'esempio, è possibile usare la
ModifiedDatecolonna .Al termine della migrazione dei dati, aggiornare la tabella in cui sono archiviati i valori temporali limite.
Pipeline di dati
Questo scenario usa il database di esempio AdventureWorks come origine dati. Il modello di caricamento incrementale dei dati viene implementato per assicurarsi di caricare solo i dati modificati o aggiunti dopo l'esecuzione della pipeline più recente.
Strumento di copia basato sui metadati
Lo strumento di copia basata sui metadati predefinito in Azure Pipelines carica in modo incrementale tutte le tabelle contenute nel database relazionale. Passando all'esperienza basata su procedura guidata, è possibile connettere lo strumento Copia dati al database di origine e configurare il caricamento incrementale o completo per ogni tabella. Lo strumento Copia dati crea quindi sia le pipeline che gli script SQL per generare la tabella di controllo necessaria per archiviare i dati per il processo di caricamento incrementale, ad esempio il valore limite/colonna massimo per ogni tabella. Dopo l'esecuzione di questi script, la pipeline è pronta per caricare tutte le tabelle nel data warehouse di origine nel pool dedicato di Synapse.
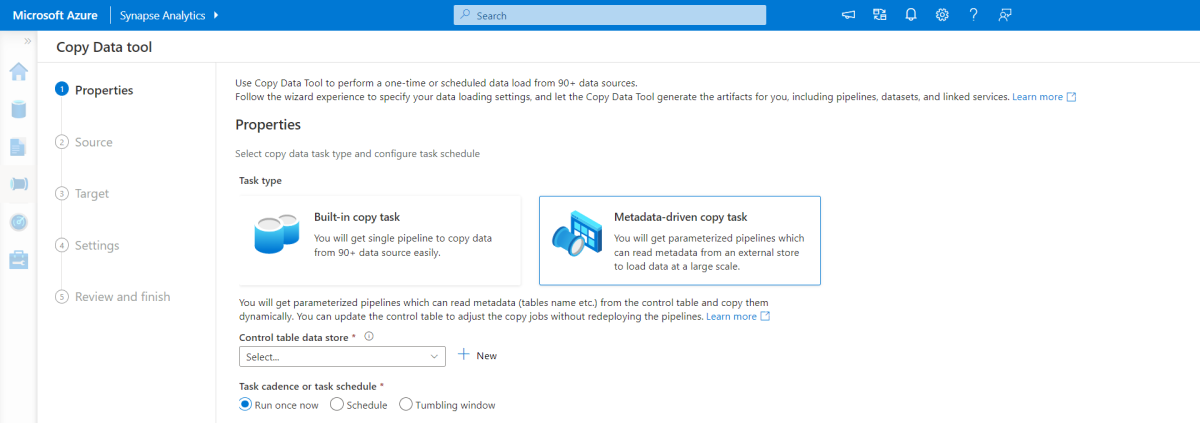
Lo strumento crea tre pipeline per scorrere tutte le tabelle del database, prima di caricare i dati.
Le pipeline generate da questo strumento:
- Contare il numero di oggetti, ad esempio tabelle, da copiare nell'esecuzione della pipeline.
- Scorrere ogni oggetto da caricare/copiare e quindi:
- Controllare se è necessario un carico differenziale; in caso contrario, completare un normale caricamento completo.
- Recuperare il valore limite massimo dalla tabella dei controlli.
- Copiare dati dalle tabelle di origine nell'account di staging in ADLS Gen2.
- Caricare i dati nel pool SQL dedicato tramite il metodo di copia selezionato, ad esempio Polybase, Comando Copia.
- Aggiornare il valore limite massimo nella tabella dei controlli.
Caricare dati nel pool SQL di Azure Synapse
L'attività di copia copia i dati dal database SQL nel pool SQL di Azure Synapse. In questo esempio, poiché il database SQL si trova in Azure, viene usato il runtime di integrazione di Azure per leggere i dati dal database SQL e scrivere i dati nell'ambiente di gestione temporanea specificato.
L'istruzione copy viene quindi usata per caricare i dati dall'ambiente di gestione temporanea nel pool dedicato di Synapse.
Usare Azure Pipelines
Le pipeline in Azure Synapse vengono usate per definire il set ordinato di attività per completare il modello di carico incrementale. I trigger vengono usati per avviare la pipeline, che può essere attivata manualmente o alla volta specificata.
Trasformazione dei dati
Poiché il database di esempio nell'architettura di riferimento non è di grandi dimensioni, sono state create tabelle replicate senza partizioni. Per i carichi di lavoro di produzione, è probabile che l'uso di tabelle distribuite migliori le prestazioni delle query. Vedere Linee guida per la progettazione di tabelle distribuite in Azure Synapse. Gli script di esempio eseguono le query usando una classe di risorse statiche.
In un ambiente di produzione è consigliabile creare tabelle di staging con distribuzione round robin. Quindi trasformare e spostare i dati in tabelle di produzione con indici columnstore cluster, che offrono le migliori prestazioni complessive delle query. Gli indici columnstore sono ottimizzati per query di analisi di record numerosi. Gli indici columnstore non vengono eseguiti anche per le ricerche singleton, ovvero la ricerca di una singola riga. Se è necessario eseguire ricerche singleton frequenti, è possibile aggiungere un indice non cluster a una tabella. Le ricerche singleton possono essere eseguite molto più velocemente usando un indice non cluster. Tuttavia, le ricerche singleton sono in genere meno comuni negli scenari di data warehouse rispetto ai carichi di lavoro OLTP. Per altre informazioni, vedere Indicizzazione di tabelle in Azure Synapse.
Nota
Le tabelle columnstore cluster non supportano varchar(max)i tipi di dati , nvarchar(max)o varbinary(max) . In tal caso, prendere in considerazione un indice cluster o heap. È possibile inserire tali colonne in una tabella distinta.
Usare Power BI Premium per accedere, modellare e visualizzare i dati
Power BI Premium supporta diverse opzioni per la connessione alle origini dati in Azure, in particolare il pool di cui è stato effettuato il provisioning in Azure Synapse:
- Importazione: i dati vengono importati nel modello di Power BI.
- DirectQuery: i dati vengono estratti direttamente dall'archiviazione relazionale.
- Modello composito: combinare l'importazione per alcune tabelle e DirectQuery per altre.
Questo scenario viene fornito con il dashboard DirectQuery perché la quantità di dati usati e la complessità del modello non sono elevate, quindi è possibile offrire un'esperienza utente ottimale. DirectQuery delega la query al potente motore di calcolo sottostante e usa funzionalità di sicurezza estese nell'origine. DirectQuery assicura anche che i risultati siano sempre coerenti con gli ultimi dati di origine.
La modalità di importazione offre il tempo di risposta alle query più veloce e deve essere considerata quando il modello rientra interamente nella memoria di Power BI, la latenza dei dati tra gli aggiornamenti può essere tollerata e potrebbero esserci alcune trasformazioni complesse tra il sistema di origine e il modello finale. In questo caso, gli utenti finali vogliono accedere completamente ai dati più recenti senza ritardi nell'aggiornamento di Power BI e a tutti i dati cronologici, maggiori di quelli che un set di dati di Power BI può gestire, tra 25 e 400 GB, a seconda delle dimensioni della capacità. Poiché il modello di dati nel pool SQL dedicato è già in uno schema star e non richiede alcuna trasformazione, DirectQuery è una scelta appropriata.
Power BI Premium Gen2 consente di gestire modelli di grandi dimensioni, report impaginati, pipeline di distribuzione ed endpoint di Analysis Services predefiniti. È anche possibile avere capacità dedicata con proposta di valore univoco.
Quando il modello di business intelligence aumenta o aumenta la complessità del dashboard, è possibile passare a modelli compositi e iniziare a importare parti di tabelle di ricerca, tramite tabelle ibride e alcuni dati preaggregati. L'abilitazione della memorizzazione nella cache delle query all'interno di Power BI per i set di dati importati è un'opzione, nonché l'uso di due tabelle per la proprietà della modalità di archiviazione.
All'interno del modello composito, i set di dati fungono da livello pass-through virtuale. Quando l'utente interagisce con le visualizzazioni, Power BI genera query SQL nei pool Synapse SQL con doppio spazio di archiviazione: in memoria o query diretta, a seconda di quale sia più efficiente. Il motore decide quando passare dalla memoria alla query diretta ed esegue il push della logica nel pool Synapse SQL. A seconda del contesto delle tabelle di query, possono fungere da modelli compositi memorizzati nella cache (importati) o non memorizzati nella cache. Selezionare e scegliere quale tabella memorizzare nella cache in memoria, combinare i dati da una o più origini DirectQuery e/o combinare dati da una combinazione di origini DirectQuery e dati importati.
Consigli: Quando si usa DirectQuery sul pool di provisioning di Azure Synapse Analytics:
- Usare la memorizzazione nella cache dei set di risultati di Azure Synapse per memorizzare nella cache i risultati delle query nel database utente per uso ripetitivo, migliorare le prestazioni delle query fino a millisecondi e ridurre l'utilizzo delle risorse di calcolo. Le query che usano set di risultati memorizzati nella cache non usano slot di concorrenza in Azure Synapse Analytics e pertanto non vengono conteggiate rispetto ai limiti di concorrenza esistenti.
- Usare le viste materializzate di Azure Synapse per pre-calcolare, archiviare e gestire i dati esattamente come una tabella. Le query che usano tutti o un sottoinsieme dei dati nelle viste materializzate possono ottenere prestazioni più veloci e non devono fare un riferimento diretto alla vista materializzata definita per usarla.
Considerazioni
Queste considerazioni implementano i pilastri di Azure Well-Architected Framework, che è un set di set di principi guida che possono essere usati per migliorare la qualità di un carico di lavoro. Per altre informazioni, vedere Framework ben progettato di Microsoft Azure.
Sicurezza
La sicurezza offre garanzie contro attacchi intenzionali e l'abuso di dati e sistemi preziosi. Per altre informazioni, vedere Panoramica del pilastro della sicurezza.
I titoli frequenti su violazioni dei dati, infezioni malware e injection di codice dannoso sono solo alcune tra le numerose preoccupazioni relative alla sicurezza per le aziende che desiderano eseguire la migrazione al cloud per la modernizzazione. I clienti aziendali hanno bisogno di una soluzione di servizi o provider di servizi che possa risolvere le proprie preoccupazioni perché non possono permettersi di sbagliare.
Questo scenario risolve i problemi di sicurezza più impegnativi usando una combinazione di controlli di sicurezza a più livelli: rete, identità, privacy e autorizzazione. La maggior parte dei dati viene archiviata nel pool di provisioning di Azure Synapse, con Power BI tramite DirectQuery tramite Single Sign-On. È possibile usare Microsoft Entra ID per l'autenticazione. Sono inoltre disponibili controlli di sicurezza estesi per l'autorizzazione dei dati dei pool di cui è stato effettuato il provisioning.
Alcune domande comuni sulla sicurezza includono:
- Come è possibile controllare chi può visualizzare quali dati?
- Le organizzazioni devono proteggere i dati per rispettare le linee guida federali, locali e aziendali per attenuare i rischi di violazione dei dati. Azure Synapse offre più funzionalità di protezione dei dati per ottenere la conformità.
- Quali sono le opzioni per verificare l'identità di un utente?
- Azure Synapse supporta un'ampia gamma di funzionalità per controllare chi può accedere ai dati tramite il controllo di accesso e l'autenticazione.
- Quale tecnologia di sicurezza di rete è possibile usare per proteggere l'integrità, la riservatezza e l'accesso alle reti e ai dati?
- Per proteggere Azure Synapse, sono disponibili diverse opzioni di sicurezza di rete.
- Quali sono gli strumenti che rilevano e notificano le minacce?
- Azure Synapse offre molte funzionalità di rilevamento delle minacce, ad esempio il controllo SQL, il rilevamento delle minacce SQL e la valutazione delle vulnerabilità per controllare, proteggere e monitorare i database.
- Cosa è possibile fare per proteggere i dati nell'account di archiviazione?
- Archiviazione di Azure account sono ideali per i carichi di lavoro che richiedono tempi di risposta rapidi e coerenti o con un numero elevato di operazioni di output di input al secondo. Archiviazione account contengono tutti gli oggetti dati Archiviazione di Azure e sono disponibili molte opzioni per la sicurezza degli account di archiviazione.
Ottimizzazione dei costi
L'ottimizzazione dei costi riguarda l'analisi dei modi per ridurre le spese non necessarie e migliorare l'efficienza operativa. Per altre informazioni, vedere Panoramica del pilastro di ottimizzazione dei costi.
In questa sezione vengono fornite informazioni sui prezzi per i diversi servizi coinvolti in questa soluzione e vengono menzionate le decisioni prese per questo scenario con un set di dati di esempio.
Azure Synapse
L'architettura serverless di Azure Synapse Analytics consente di dimensionare i livelli di calcolo e archiviazione in modo indipendente. Le risorse di calcolo vengono addebitate in base all'utilizzo ed è possibile dimensionare o sospendere queste risorse su richiesta. Le risorse di archiviazione vengono addebitate per terabyte, pertanto i costi aumenteranno man mano che si inseriscono altri dati.
Azure Pipelines
I dettagli sui prezzi per le pipeline in Azure Synapse sono disponibili nella scheda Integrazione dei dati della pagina dei prezzi di Azure Synapse. Esistono tre componenti principali che influenzano il prezzo di una pipeline:
- Attività della pipeline di dati e ore di runtime di integrazione
- Dimensioni ed esecuzione del cluster dei flussi di dati
- Addebiti per le operazioni
Il prezzo varia a seconda dei componenti o delle attività, della frequenza e del numero di unità di runtime di integrazione.
Per il set di dati di esempio, il runtime di integrazione ospitato in Azure standard, l'attività di copia dei dati per il nucleo della pipeline, viene attivata in base a una pianificazione giornaliera per tutte le entità (tabelle) nel database di origine. Lo scenario non contiene flussi di dati. Non sono previsti costi operativi perché sono presenti meno di 1 milione di operazioni con pipeline al mese.
Pool e archiviazione dedicati di Azure Synapse
I dettagli sui prezzi per il pool dedicato di Azure Synapse sono disponibili nella scheda Archiviazione dati della pagina dei prezzi di Azure Synapse. Nel modello a consumo dedicato, i clienti vengono fatturati per unità DWU di cui è stato effettuato il provisioning, per ora di tempo di attività. Un altro fattore che contribuisce è costituito dai costi di archiviazione dei dati: dimensioni dei dati inattivi + snapshot e ridondanza geografica, se presenti.
Per il set di dati di esempio, è possibile effettuare il provisioning di 500DWU, che garantisce un'esperienza ottimale per il carico analitico. È possibile mantenere il calcolo operativo durante l'orario lavorativo di creazione di report. Se impiegato in produzione, la capacità riservata del data warehouse è un'opzione interessante per la gestione dei costi. È consigliabile usare tecniche diverse per ottimizzare le metriche relative ai costi/prestazioni, descritte nelle sezioni precedenti.
Archiviazione BLOB
Prendere in considerazione l'uso della funzionalità di capacità riservata Archiviazione di Azure per ridurre i costi di archiviazione. Con questo modello si ottiene uno sconto se si riserva la capacità di archiviazione fissa per uno o tre anni. Per altre informazioni, vedere Ottimizzare i costi per l'archiviazione BLOB con capacità riservata.
In questo scenario non è disponibile alcuna risorsa di archiviazione permanente.
Power BI Premium
I dettagli sui prezzi di Power BI Premium sono disponibili nella pagina dei prezzi di Power BI.
Questo scenario usa le aree di lavoro di Power BI Premium con una serie di miglioramenti delle prestazioni integrati per soddisfare esigenze analitiche impegnative.
Eccellenza operativa
L'eccellenza operativa copre i processi operativi che distribuiscono un'applicazione e la mantengono in esecuzione nell'ambiente di produzione. Per altre informazioni, vedere Panoramica del pilastro dell'eccellenza operativa.
Raccomandazioni di DevOps
Creare gruppi di risorse separati per gli ambienti di produzione, sviluppo e test. L'uso di gruppi di risorse separati semplifica la gestione delle distribuzioni, l'eliminazione delle distribuzioni di test e l'assegnazione dei diritti di accesso.
Inserire ogni carico di lavoro in un modello di distribuzione separato e archiviare le risorse nei sistemi di controllo del codice sorgente. È possibile distribuire i modelli insieme o singolarmente come parte di un processo di integrazione continua (CI) e recapito continuo (CD), semplificando il processo di automazione. In questa architettura sono disponibili quattro carichi di lavoro principali:
- Il server del data warehouse e le risorse correlate
- Pipeline di Azure Synapse
- Asset di Power BI: dashboard, app, set di dati
- Scenario simulato da locale a cloud
Mirare a avere un modello di distribuzione separato per ognuno dei carichi di lavoro.
Prendere in considerazione la gestione temporanea dei carichi di lavoro dove è pratico. Eseguire la distribuzione in varie fasi ed eseguire controlli di convalida in ogni fase prima di passare alla fase successiva. In questo modo è possibile eseguire il push degli aggiornamenti negli ambienti di produzione in modo controllato e ridurre al minimo i problemi di distribuzione imprevisti. Usare le strategie di distribuzione blu-verde e canary per aggiornare gli ambienti di produzione live.
Avere una buona strategia di rollback per la gestione delle distribuzioni non riuscite. Ad esempio, è possibile ridistribuire automaticamente una distribuzione precedente e corretta dalla cronologia di distribuzione. Vedere il flag nell'interfaccia della
--rollback-on-errorriga di comando di Azure.Monitoraggio di Azure è l'opzione consigliata per analizzare le prestazioni del data warehouse e l'intera piattaforma di analisi di Azure per un'esperienza di monitoraggio integrata. Azure Synapse Analytics offre un'esperienza di monitoraggio all'interno del portale di Azure per visualizzare informazioni dettagliate sul carico di lavoro del data warehouse. Il portale di Azure è lo strumento consigliato per il monitoraggio del data warehouse perché fornisce periodi di conservazione configurabili, avvisi, raccomandazioni e grafici e dashboard personalizzabili per metriche e log.
Avvio rapido
- Portale: Modello di verifica di Azure Synapse
- Interfaccia della riga di comando di Azure: Creare un'area di lavoro di Azure Synapse con l'interfaccia della riga di comando di Azure
- Terraform: data warehousing moderno con Terraform e Microsoft Azure
Efficienza prestazionale
L'efficienza delle prestazioni è la capacità di dimensionare il carico di lavoro per soddisfare in modo efficiente le richieste poste dagli utenti. Per altre informazioni, vedere Panoramica dell'efficienza delle prestazioni.
Questa sezione fornisce informazioni dettagliate sulle decisioni di dimensionamento per supportare questo set di dati.
Pool di cui è stato effettuato il provisioning in Azure Synapse
È disponibile una serie di configurazioni del data warehouse tra cui scegliere.
| Unità di data warehouse | Numero di nodi di calcolo | Numero di distribuzioni per nodo |
|---|---|---|
| DW100c | 1 | 60 |
-- TO -- |
||
| DW30000c | 60 | 1 |
Per visualizzare i vantaggi delle prestazioni della scalabilità orizzontale, in particolare per le unità data warehouse di dimensioni maggiori, usare almeno un set di dati da 1 TB. Per trovare il numero migliore di unità data warehouse per il pool SQL dedicato, provare a aumentare e ridurre le prestazioni. Dopo il caricamento dei dati, eseguire alcune query con numeri di unità di data warehouse diversi. Poiché il ridimensionamento è rapido, è possibile provare diversi livelli di prestazioni in un'ora o meno.
Trovare il numero migliore di unità data warehouse
Per un pool SQL dedicato in fase di sviluppo, iniziare selezionando un numero minore di unità data warehouse. Un buon punto di partenza è DW400c o DW200c. Monitorare le prestazioni dell'applicazione, osservando il numero di unità di data warehouse selezionato rispetto alle prestazioni ottenute. Presupporre una scalabilità lineare e determinare quanto è necessario aumentare o ridurre le unità di data warehouse. Continuare ad apportare modifiche finché non si raggiunge un livello di prestazioni ottimale per i propri requisiti aziendali.
Ridimensionamento del pool SYNapse SQL
- Ridimensionare le risorse di calcolo per il pool Synapse SQL con il portale di Azure
- Ridimensionare le risorse di calcolo per il pool SQL dedicato con Azure PowerShell
- Ridimensionare le risorse di calcolo per il pool SQL dedicato in Azure Synapse Analytics usando T-SQL
- Sospensione, monitoraggio e automazione
Azure Pipelines
Per le funzionalità di scalabilità e ottimizzazione delle prestazioni delle pipeline in Azure Synapse e l'attività di copia usata, vedere la guida alle prestazioni e alla scalabilità attività Copy.
Power BI Premium
Questo articolo usa Power BI Premium Gen 2 per illustrare le funzionalità di BUSINESS Intelligence. Gli SKU di capacità per Power BI Premium sono attualmente compresi tra P1 (otto v-core) e P5 (128 v-core). Il modo migliore per selezionare la capacità necessaria consiste nell'eseguire la valutazione del caricamento della capacità, installare l'app metriche di seconda generazione per il monitoraggio continuo e valutare l'uso della scalabilità automatica con Power BI Premium.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autori principali:
- Galina Polyakova | Senior Cloud Solution Architect
- Noah Costar | Cloud Solution Architect
- George Stevens | Cloud Solution Architect
Altri contributori:
- Jim McLeod | Cloud Solution Architect
- Miguel Myers | Senior Program Manager
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.
Passaggi successivi
- Che cos'è Power BI Premium?
- Cos'è Microsoft Entra ID?
- Accesso ad Azure Data Lake Archiviazione Gen2 e Archiviazione BLOB con Azure Databricks
- Che cos'è Azure Synapse Analytics?
- Pipeline e attività in Azure Data Factory e Azure Synapse Analytics
- Che cos'è Azure SQL?