Risolvere i problemi di prestazioni con Intelligent Insights - Database SQL di Azure e Istanza gestita di SQL di Azure
Si applica a:![]() Database SQL di Azure
Database SQL di Azure![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure
Questa pagina contiene informazioni sui problemi di prestazioni del database SQL di Azure e dell'Istanza gestita di SQL di Azure rilevati tramite il log delle risorse di Intelligent Insights. I log delle metriche e delle risorse possono essere trasmessi ai Log di monitoraggio di Azure, Hub eventi di Azure, Archiviazione di Azure oppure a una soluzione di terze parti per funzionalità di avvisi e report di DevOps personalizzate.
Nota
Per una rapida guida alla risoluzione dei problemi di prestazioni tramite Intelligent Insights, vedere il diagramma Flusso di risoluzione dei problemi consigliato in questo documento.
Intelligent Insights è una funzionalità di anteprima non disponibile nelle seguenti aree: Europa occidentale, Europa settentrionale, Stati Uniti occidentali 1 e Stati Uniti orientali 1.
Modelli di prestazioni del database rilevabili
Intelligent Insights rileva automaticamente i problemi di prestazioni in base ai tempi di attesa di esecuzione delle query, agli errori o ai timeout. Gli output di Intelligent Insights hanno rilevato modelli di prestazioni nel log delle risorse. La tabella seguente riepiloga i modelli di prestazioni rilevabili.
| Modelli di prestazioni rilevabili | database SQL di Azure | Istanza gestita di SQL di Azure |
|---|---|---|
| Raggiungimento dei limiti delle risorse | Il consumo di risorse disponibili (DTU), dei thread di lavoro del database o delle sessioni di accesso al database disponibili nella sottoscrizione monitorata ha raggiunto i suoi limiti di risorse. Ciò influisce sulle prestazioni. | Il consumo di risorse della CPU sta per raggiungere i suoi limiti di risorse. Questo influisce sulle prestazioni del database. |
| Aumento del carico di lavoro | È stato rilevato un aumento o un accumulo continuo di carico di lavoro nel database. Ciò influisce sulle prestazioni. | È stato rilevato un aumento del carico di lavoro. Questo influisce sulle prestazioni del database. |
| Utilizzo elevato della memoria | I thread di lavoro che hanno richiesto concessioni di memoria devono attendere le allocazioni di memoria per una quantità di tempo memoria statisticamente significativa, oppure esiste un maggiore accumulo di thread di lavoro che hanno richiesto concessioni di memoria. Ciò influisce sulle prestazioni. | I thread di lavoro che hanno richiesto concessioni di memoria devono attendere le allocazioni di memoria per una quantità di tempo statisticamente significativa. Questo influisce sulle prestazioni del database. |
| Blocco | È stato rilevato un blocco eccessivo del database con effetti sulle prestazioni. | È stato rilevato un blocco eccessivo del database con effetti sulle prestazioni del database. |
| Valore di MAXDOP aumentato | L'opzione relativa al massimo grado di parallelismo (MAXDOP) è stata modificata, con effetti sull'efficienza di esecuzione delle query. Ciò influisce sulle prestazioni. | L'opzione relativa al massimo grado di parallelismo (MAXDOP) è stata modificata, con effetti sull'efficienza di esecuzione delle query. Ciò influisce sulle prestazioni. |
| Contesa di latch di pagina | Più thread tentano di accedere contemporaneamente alle stesse pagine di buffer di dati in memoria provocando un aumento dei tempi di attesa e causando una contesa di latch di pagina. Ciò influisce sulle prestazioni. | Più thread tentano di accedere contemporaneamente alle stesse pagine di buffer di dati in memoria provocando un aumento dei tempi di attesa e causando una contesa di latch di pagina. Questo influisce sulle prestazioni del database. |
| Indice mancante | È stato rilevato un indice mancante con effetti sulle prestazioni. | È stato rilevato un indice mancante con effetti sulle prestazioni del database. |
| Nuova query | È stata rilevata una nuova query con impatto sulle prestazioni complessive. | È stata rilevata una nuova query con impatto sulle prestazioni complessive del database. |
| Statistiche di attesa in aumento | Sono stati rilevati tempi di attesa aumentati del database con impatto sulle prestazioni. | Sono stati rilevati tempi di attesa del database in aumento con impatto sulle prestazioni del database. |
| Contesa di TempDB | Più thread tentano di accedere alla stessa risorsa tempdb, provocando un collo di bottiglia. Ciò influisce sulle prestazioni. |
Più thread tentano di accedere alla stessa risorsa tempdb, provocando un collo di bottiglia. Questo influisce sulle prestazioni del database. |
| Carenza di DTU nel pool elastico | La carenza di eDTU disponibili nel pool elastico influisce sulle prestazioni. | Non disponibile per l'Istanza gestita di SQL di Azure perché questa usa il modello vCore. |
| Regressione di piani | È stato rilevato un nuovo piano o una modifica nel carico di lavoro di un piano esistente. Ciò influisce sulle prestazioni. | È stato rilevato un nuovo piano o una modifica nel carico di lavoro di un piano esistente. Questo influisce sulle prestazioni del database. |
| Modifica del valore di configurazione in ambito database | È stata rilevata una modifica della configurazione del database con impatto sulle prestazioni del database. | È stata rilevata una modifica della configurazione del database con impatto sulle prestazioni del database. |
| Client lento | Un client applicazione lento non riesce a usare in modo abbastanza veloce l'output del database. Ciò influisce sulle prestazioni. | Un client applicazione lento non riesce a usare in modo abbastanza veloce l'output del database. Questo influisce sulle prestazioni del database. |
| Downgrade del piano tariffario | Un'azione di downgrade del piano tariffario ha ridotto le risorse disponibili. Ciò influisce sulle prestazioni. | Un'azione di downgrade del piano tariffario ha ridotto le risorse disponibili. Questo influisce sulle prestazioni del database. |
Suggerimento
Per un'ottimizzazione continua delle prestazioni dei database, abilitare l'ottimizzazione automatica. Questa funzionalità di intelligenza incorporata monitora in continuo il database, ottimizza automaticamente gli indici e applica correzioni ai piani di esecuzione delle query.
La sezione seguente descrive in modo più dettagliato i modelli di prestazioni rilevabili.
Raggiungimento dei limiti delle risorse
Situazione
Questo modello di prestazioni rilevabili combina i problemi di prestazioni correlati al raggiungimento dei limiti delle risorse disponibili, dei thread di lavoro e delle sessioni. Dopo che il problema è stato rilevato, un campo di descrizione del log di diagnostica indica se il problema di prestazioni è correlato ai limiti delle risorse, dei thread di lavoro o delle sessioni.
Le risorse nel database SQL di Azure sono in genere denominate risorse DTU o vCore, e le risorse nell'Istanza gestita di SQL di Azure sono denominate risorse vCore. Il modello del raggiungimento dei limiti delle risorse viene riconosciuto quando la riduzione delle prestazioni delle query rilevata è provocata dal raggiungimento di uno qualsiasi dei limiti delle risorse misurate.
La risorsa con limiti di sessione indica il numero di accessi simultanei disponibili al database. Questo modello di prestazioni viene riconosciuto nel caso in cui le applicazioni che si connettono ai database abbiano raggiunto il numero di accessi simultanei disponibili al database. Se le applicazioni tentano di usare più sessioni rispetto a quelle disponibili in un database, le prestazioni delle query ne sono influenzate.
Il raggiungimento dei limiti dei thread di lavoro rappresenta un caso di raggiungimento dei limiti delle risorse specifico poiché i thread di lavoro disponibili non vengono conteggiati nell'uso di DTU o vCore. Il raggiungimento dei limiti dei thread di lavoro in un database può causare l'aumento dei tempi di attesa specifici di una risorsa, con conseguente riduzione delle prestazioni delle query.
Risoluzione dei problemi
Il log di diagnostica genera hash di query per le query con effetti sulle prestazioni e sulle percentuali di consumo delle risorse. È possibile usare queste informazioni come punto iniziale per ottimizzare il carico di lavoro del database. In particolare, è possibile ottimizzare le query con effetti sulla riduzione delle prestazioni tramite l'aggiunta di indici. Oppure è possibile ottimizzare le applicazioni con una distribuzione più uniforme dei carichi di lavoro. Se non è possibile ridurre i carichi di lavoro o eseguire ottimizzazioni, valutare il passaggio a un piano tariffario di livello superiore di sottoscrizione al database per incrementare la quantità di risorse disponibili.
Se sono stati raggiunti i limiti delle sessioni disponibili, è possibile ottimizzare le applicazioni riducendo il numero di accessi al database. Se non si riesce a ridurre il numero di accessi dalle applicazioni al database, valutare il passaggio a un piano tariffario di livello superiore di sottoscrizione al database. In alternativa, è possibile suddividere e spostare il database in più database per una distribuzione più equilibrata del carico di lavoro.
Per ulteriori suggerimenti sulla risoluzione dei limiti di sessione, vedere Come gestire i limiti di accessi massimi.. Per informazioni sui limiti a livello di server e sottoscrizione, vedere Panoramica dei limiti delle risorse in un server.
Aumento del carico di lavoro
Situazione
Questo modello di prestazioni identifica i problemi causati da un aumento o, in forma peggiore, da un accumulo del carico di lavoro.
Il rilevamento viene eseguito tramite una combinazione di diverse metriche. La metrica di base misurata è la rilevazione di un aumento del carico di lavoro rispetto alla baseline del carico di lavoro precedente. L'altra forma di rilevamento si basa sulla misurazione di un notevole aumento di thread di lavoro attivi, sufficiente per influire sulle prestazioni delle query.
Nella sua forma più grave, il carico di lavoro potrebbe accumularsi continuamente per via dell'incapacità del database di gestire il carico di lavoro. La conseguenza è un continuo aumento delle dimensioni del carico di lavoro, ovvero la condizione che determina l'accumulo. A causa di questa condizione, aumenta il tempo di attesa dell'esecuzione per il carico di lavoro. Questa condizione rappresenta uno dei più gravi problemi di prestazioni di database. Questo problema viene rilevato monitorando l'aumento del numero di thread di lavoro interrotti.
Risoluzione dei problemi
Il log di diagnostica riporta il numero di query la cui esecuzione è aumentata e l'hash della query che contribuisce maggiormente all'aumento del carico di lavoro. È possibile usare queste informazioni come punto di partenza per l'ottimizzazione del carico di lavoro. La query identificata come quella che contribuisce maggiormente all'aumento del carico di lavoro è particolarmente utile come punto di partenza.
Si potrebbe valutare una distribuzione più uniforme dei carichi di lavoro nel database. Prendere in considerazione l'ottimizzazione della query che influisce sulle prestazioni tramite l'aggiunta di indici. Si può anche distribuire il carico di lavoro tra più database. Se queste soluzioni non sono praticabili, valutare il passaggio a un piano tariffario di livello superiore di sottoscrizione al database per incrementare la quantità di risorse disponibili.
Utilizzo elevato della memoria
Situazione
Questo modello di prestazioni indica una riduzione delle prestazioni correnti del database causata da un utilizzo elevato della memoria o, nella forma più grave, da una condizione di accumulo d richieste alla memoria rispetto alla baseline delle prestazioni dei sette giorni precedenti.
L'utilizzo elevato della memoria indica una condizione delle prestazioni in cui è presente un numero elevato di thread di lavoro che richiedono concessioni di memoria. Questo volume elevato causa una condizione di utilizzo elevato della memoria in cui il database non è in grado di allocare in modo efficiente la memoria a tutti i thread di lavoro che la richiedono. Uno dei motivi più comuni per questo problema è da un lato correlato alla quantità di memoria disponibile per il database. Dall'altro, un aumento del carico di lavoro causa l'aumento dei thread di lavoro e l'utilizzo elevato della memoria.
La forma più grave di utilizzo elevato della memoria è la condizione di accumulo di richieste di memoria. Questa condizione indica la presenza di un numero di thread di lavoro che richiede concessioni di memoria maggiore rispetto alle query che rilasciano la memoria. Il numero di thread di lavoro che richiedono concessioni di memoria potrebbe anche crescere di continuo (accumulo) perché il motore del database non è in grado di allocare memoria in modo sufficientemente efficiente per soddisfare la domanda. La condizione di accumulo di richieste alla memoria rappresenta uno dei più gravi problemi di prestazioni di database.
Risoluzione dei problemi
Il log di diagnostica restituisce i dettagli dell'archivio di oggetti di memoria con il clerk di memoria, ovvero thread di lavoro, contrassegnato come il motivo principale per l'uso elevato della memoria e i timestamp pertinenti. È possibile usare queste informazioni come base per la risoluzione dei problemi.
È possibile ottimizzare o rimuovere query correlate ai clerk con l'utilizzo della memoria più elevato. È anche possibile assicurarsi di evitare l'esecuzione di query su dati che non si prevede di usare. Una buona norma consiste nell'usare sempre una clausola WHERE nelle query. Inoltre, è consigliabile creare indici non cluster per la ricerca dei dati, anziché eseguirne l'analisi.
È anche possibile ridurre il carico di lavoro ottimizzandolo o distribuendolo su più database. Oppure è possibile distribuire il carico di lavoro tra più database. Se queste soluzioni non sono praticabili, valutare il passaggio a un piano tariffario di livello superiore di sottoscrizione al database per incrementare la quantità di risorse di memoria disponibili per il database.
Per altre informazioni sulla risoluzione dei problemi, vedere Memory grants meditation: The mysterious SQL Server memory consumer with many names (Riflessione sulle concessioni di memoria: il misterioso consumer di memoria di SQL Server con molti nomi). Per maggiori informazioni sugli errori di memoria insufficiente nel database SQL di Azure, vedere Risolvere gli errori di memoria insufficiente nel database SQL di Azure.
Blocco
Situazione
Questo modello di prestazioni indica una riduzione delle prestazioni correnti del database in cui viene rilevato un blocco eccessivo del database rispetto alla baseline delle prestazioni dei sette giorni precedenti.
Nei sistemi RDBMS moderni il blocco è essenziale per l'implementazione multithreading in cui le prestazioni sono massimizzate tramite l'esecuzione di più thread di lavoro simultanei e di transazioni di database parallele ove possibile. Il termine blocco in questo contesto si riferisce al meccanismo di accesso predefinito in cui solo un'unica transazione può accedere in modo esclusivo a righe, pagine, tabelle e file necessari e non entra in conflitto con un'altra transazione per accedere alle risorse. Quando la transazione che ha bloccato le risorse per l'uso è completata, il blocco su tali risorse viene rilasciato consentendo ad altre transazioni di accedere alle risorse necessarie. Per altre informazioni sul blocco, vedere Utilizzo dei blocchi in Motore di database.
Se le transazioni eseguite dal motore SQL rimangono in attesa per periodi di tempo prolungati prima di accedere alle risorse bloccate per l'uso, il tempo di attesa causa il rallentamento delle prestazioni di esecuzione del carico di lavoro.
Risoluzione dei problemi
Il log di diagnostica restituisce dettagli di blocchi che è possibile usare come base per la risoluzione dei problemi. È possibile analizzare le query che causano il blocco segnalate, ovvero quelle che introducono la riduzione delle prestazioni correlate al blocco, e quindi rimuoverle. In alcuni casi potrebbe essere utile ottimizzare le query che causano il blocco.
Il modo più semplice e sicuro per attenuare il problema consiste nel mantenere brevi le transazioni e nel ridurre l'impatto del blocco causato dalle query più dispendiose. È possibile suddividere un batch di grandi dimensioni di operazioni in operazioni più piccole. È buona norma ridurre l'impatto del blocco aumentando il più possibile l'efficienza della query. Ridurre le analisi di grandi dimensioni perché aumentano le possibilità di deadlock e influiscono negativamente sulle prestazioni generali del database. Per le query identificate che causano il blocco, è possibile creare nuovi indici o aggiungere colonne all'indice esistente per evitare scansioni di tabella.
Per ulteriori suggerimenti, vedere:
- Comprendere e risolvere i problemi che causano un blocco di Azure SQL
- Come risolvere i problemi di blocco causati dall'escalation dei blocchi in SQL Server
Valore di MAXDOP aumentato
Situazione
Questo modello di prestazioni rilevabili indica una condizione in cui un piano di esecuzione di query scelto è stato eseguito in parallelo in misura maggiore del previsto. Query Optimizer può migliorare le prestazioni del carico di lavoro eseguendo query in parallelo per velocizzare le operazioni ove possibile. In alcuni casi, i thread di lavoro che elaborano in parallelo una query trascorrono più tempo in attesa della sincronizzazione e dell'unione dei risultati reciproche, rispetto all'esecuzione della stessa query con meno thread di lavoro paralleli o, in alcuni casi, con un unico thread.
Un sistema esperto analizza le prestazioni del database correnti confrontandole con il periodo della baseline e determina se una query eseguita in precedenza è più lenta rispetto a prima perché il piano di esecuzione di query viene eseguito in parallelo più di quanto necessario.
L'opzione di configurazione del server MAXDOP viene usata per controllare il numero di core CPU che possono essere usati per eseguire la stessa query in parallelo.
Risoluzione dei problemi
Il log di diagnostica restituisce gli hash di query correlati alle query per cui la durata di esecuzione è aumentata a causa di una parallelizzazione maggiore rispetto al necessario. Il log restituisce anche i tempi di attesa CXP. Tale tempo rappresenta il tempo che un singolo thread organizzatore/coordinatore (thread 0) rimane in attesa della terminazione di tutti gli altri thread prima di unire i risultati e procedere. Il log di diagnostica restituisce anche i tempi di attesa complessivi per l'esecuzione delle query con prestazioni ridotte. È possibile usare queste informazioni come base per la risoluzione dei problemi.
Ottimizzare o semplificare prima di tutto le query più complesse. ad esempio suddividendo processi batch di grandi dimensioni in processi di dimensioni minori. Assicurarsi inoltre che siano stati creati indici a supporto delle query. È anche possibile applicare manualmente l'opzione di massimo grado di parallelismo (MAXDOP) per una query contrassegnata con prestazioni insufficienti. Per configurare questa operazione tramite T-SQL, vedere Configurare l'opzione di configurazione del server max degree of parallelism.
L'impostazione dell'opzione di configurazione del server MAXDOP su zero (0) come valore predefinito indica che il database può usare tutti i core CPU logici disponibili per parallelizzare i thread per l'esecuzione di una singola query. L'impostazione di MAXDOP su uno (1) indica che è possibile usare un solo core per l'esecuzione di una singola query. In pratica, ciò significa che il parallelismo è disattivato. A seconda del caso, dei core disponibili per il database e delle informazioni del log di diagnostica, è possibile impostare l'opzione MAXDOP sul numero di core per l'esecuzione di query parallele che consente di risolvere il problema nel caso specifico.
Contesa di latch di pagina
Situazione
Questo modello di prestazioni indica la riduzione delle prestazioni correnti correlate al carico di lavoro del database a causa della contesa di latch di pagina rispetto alla baseline del carico di lavoro dei sette giorni precedenti.
I latch sono meccanismi di sincronizzazione leggeri usati per abilitare il multithreading. per garantire la coerenza delle strutture in memoria che includono indici, pagine di dati e altre strutture interne.
Sono disponibili molti tipi di latch. Per semplificare, i latch di buffer vengono usati per proteggere le pagine in memoria nel pool di buffer. I latch di I/O vengono usati per proteggere le pagine non ancora caricate nel pool di buffer. Ogni volta che i dati vengono scritti o letti in una pagina nel pool di buffer, un thread di lavoro deve prima acquisire un latch di buffer per la pagina. Ogni volta che un thread di lavoro tenta di accedere a una pagina che non è già disponibile nel pool di buffer in memoria, viene eseguita una richiesta di I/O per caricare le informazioni necessarie dall'archiviazione. Questa sequenza di eventi indica una forma più grave di riduzione delle prestazioni.
La contesa di latch di pagina si verifica quando più thread tentano di acquisire contemporaneamente latch sulla stessa struttura in memoria con il conseguente aumento del tempo di attesa per l'esecuzione delle query. In caso di contesa I/O di latch di pagina quando occorre accedere ai dati dall'archiviazione, il tempo di attesa è anche maggiore. Ciò può influire notevolmente sulle prestazioni del carico di lavoro. La contesa di latch di pagina è lo scenario più comune di thread in attesa tra loro e in conflitto per l'accesso alle risorse su più CPU.
Risoluzione dei problemi
Il log di diagnostica include informazioni dettagliate sulle contese di latch di pagina. È possibile usare queste informazioni come base per la risoluzione dei problemi.
Dato che il latch di pagina è un meccanismo di controllo interno, esso determina automaticamente quando usare tali dettagli. Le decisioni correlate alle applicazioni, ad esempio la progettazione dello schema, possono influire sul funzionamento del latch di pagina a causa del comportamento deterministico dei latch.
Un metodo per gestire una contesa di latch consiste nel sostituire una chiave di indice sequenziale con una chiave non sequenziale per distribuire uniformemente gli inserimenti su un intervallo di indici. Una colonna iniziale nell'indice distribuisce in genere il carico di lavoro in modo proporzionale. Un altro metodo da considerare consiste nel partizionamento delle tabelle. La creazione di uno schema di partizionamento hash con una colonna calcolata in una tabella partizionata è un approccio comune per attenuare la contesa di latch eccessiva. Nel caso di contesa I/O di latch di pagina l'introduzione degli indici è utile per ridurre questo problema di prestazioni.
Per altre informazioni, vedere il documento in formato PDF Diagnose and resolve latch contention on SQL Server (Diagnosi e risoluzione delle contese di latch in SQL Server).
Indice mancante
Situazione
Questo modello di prestazioni indica la riduzione delle prestazioni correnti correlate al carico di lavoro del database a causa di un indice mancante rispetto alla baseline dei sette giorni precedenti.
Per velocizzare le prestazioni delle query, viene usato un indice che consente di accedere rapidamente ai dati della tabella grazie alla riduzione del numero di pagine dei set di dati che devono essere visitate o analizzate.
Le query specifiche che hanno causato una riduzione delle prestazioni vengono identificate tramite il rilevamento, per cui la creazione degli indici influirebbe favorevolmente sulle prestazioni.
Risoluzione dei problemi
Il log di diagnostica include gli hash delle query identificate con effetti sulle prestazioni del carico di lavoro. È possibile creare indici per queste query. È anche possibile ottimizzare o rimuovere queste query se non sono necessarie. È buona norma evitare di eseguire query sui dati che non vengono usati.
Suggerimento
Le funzionalità di intelligenza incorporate possono gestire automaticamente gli indici con le prestazioni migliori per i database in uso.
Per un'ottimizzazione continua delle prestazioni, si consiglia di abilitare l'ottimizzazione automatica. Questa funzionalità di intelligenza incorporata unica monitora in continuo il database, e ottimizza automaticamente e crea gli indici per i database.
Nuova query
Situazione
Questo modello di prestazioni indica che è stata rilevata una nuova query con prestazioni insufficienti e con impatto sulle prestazioni del carico di lavoro rispetto alla baseline delle prestazioni dei sette giorni precedenti.
La scrittura di una query con buone prestazioni può essere un'attività complessa. Per altre informazioni sulla scrittura di query, vedere Writing SQL queries (Scrittura di query SQL). Per ottimizzare le prestazioni delle query esistenti, vedere Ottimizzazione delle query.
Risoluzione dei problemi
Il log di diagnostica include informazioni sulle due nuove query che usano maggiormente la CPU, includendo gli hash corrispondenti. Dato che la query rilevata influisce sulle prestazioni del carico di lavoro, è possibile ottimizzarla. È buona norma recuperare solo i dati necessari. È anche consigliabile usare query con una clausola WHERE. Si consiglia inoltre di semplificare le query più complesse e suddividerle in query di dimensioni inferiori. Un'altra buona norma consiste nel suddividere query in batch di grandi dimensioni in query in batch più piccole. L'introduzione di indici per le nuove query è in genere consigliabile per ridurre questo problema di prestazioni.
Nel database SQL di Azure, valutare di usare le Informazioni dettagliate prestazioni delle query.
Statistiche di attesa in aumento
Situazione
Questo modello di prestazioni rilevabili indica una riduzione delle prestazioni del carico di lavoro in cui vengono identificate le query con prestazioni ridotte rispetto alla baseline del carico di lavoro dei sette giorni precedenti.
In questo caso, il sistema non può classificare le query con prestazioni scarse in nessun'altra categoria di prestazioni rilevabili standard, ma è in grado di rilevare la statistica di attesa responsabile della regressione. Queste query vengono quindi considerate con statistiche di attesa in aumento e viene anche esposta la statistica di attesa responsabile della regressione.
Risoluzione dei problemi
Il log di diagnostica include informazioni sui dettagli del tempo di attesa in aumento e sugli hash di query delle query interessate.
Dato che in questo caso il sistema non è stato in grado di identificare la causa radice delle query con prestazioni ridotte, le informazioni di diagnostica rappresentano un buon punto di partenza per una risoluzione dei problemi manuale. È possibile ottimizzare le prestazioni di queste query. È buona norma recuperare solo i dati che devono essere usati e semplificare e suddividere le query complesse in query di dimensioni minori.
Per altre informazioni sull'ottimizzazione delle prestazioni delle query, vedere Ottimizzazione delle query.
Contesa di TempDB
Situazione
Questo modello di prestazioni rilevabili indica una condizione delle prestazioni del database in cui è presente un collo di bottiglia di thread che tentano di accedere a risorse tempdb. (Tale condizione non è correlata all'IO.). Lo scenario tipico per questo problema di prestazioni è la presenza di centinaia di query simultanee, tutte che creano, usano e rilasciano tabelle tempdb di piccole dimensioni. Il sistema ha rilevato che il numero di query simultanee che usano le stesse tabelle tempdb è aumentato in modo statisticamente significativo, sufficiente da influire sulle prestazioni del database rispetto alla baseline delle prestazioni degli ultimi sette giorni.
Risoluzione dei problemi
Il log di diagnostica include dettagli sulle contese di tempdb. È possibile usare queste informazioni come punto di partenza per la risoluzione dei problemi. Esistono due operazioni che è possibile eseguire per risolvere questo tipo di contesa e aumentare la velocità effettiva del carico di lavoro globale, ovvero è possibile interrompere l'uso di tabelle temporanee e usare tabelle ottimizzate per la memoria.
Per altre informazioni, vedere Introduzione alle tabelle ottimizzate per la memoria.
Carenza di DTU nel pool elastico
Situazione
Questo modello di prestazioni rilevabili indica la riduzione delle prestazioni correnti correlate al carico di lavoro del database rispetto alla baseline dei sette giorni precedenti. La causa è la carenza di DTU disponibili nel pool elastico della sottoscrizione.
Le risorse del pool elastico di Azure vengono usate come un pool di risorse disponibili condivise tra più database a scopo di ridimensionamento. Quando le risorse eDTU disponibili nel pool elastico non sono in numero sufficiente per supportare tutti i database nel pool, il sistema rileva un problema di prestazioni per carenza di eDTU nel pool elastico.
Risoluzione dei problemi
Il log di diagnostica include informazioni sul pool elastico, elenca i database che usano più DTU e restituisce la percentuale delle DTU del pool usate dal database più dispendioso.
Dato che questa condizione delle prestazioni è correlata a più database che usano lo stesso pool di eDTU del pool elastico, la procedura di risoluzione dei problemi è focalizzata sui database che usano più DTU. È possibile ridurre il carico di lavoro nei database più dispendiosi, ad esempio ottimizzando le query più dispendiose su tali database. È anche possibile assicurarsi di evitare l'esecuzione di query su dati che non si prevede di usare. Un altro approccio consiste nell'ottimizzare le applicazioni coinvolte nei database che usano più DTU e nel ridistribuire il carico di lavoro tra più database.
Se la riduzione e l'ottimizzazione del carico di lavoro corrente nei database che usano più DTU non sono possibili, valutare la possibilità di aumentare il piano tariffario del pool elastico. Tale aumento determina l'incremento delle DTU disponibili nel pool elastico.
Regressione di piani
Situazione
Questo modello di prestazioni rilevabili indica una condizione in base alla quale il database utilizza un piano di esecuzione delle query non ottimale. Tale piano causa in genere un aumento del tempo di esecuzione di query che comporta a sua volta tempi di attesa superiori per la query corrente e le altre.
Il motore di database determina il piano di esecuzione delle query con il minor costo di esecuzione. Dato che il tipo delle query e dei carichi di lavoro può variare, talvolta i piani esistenti non sono più efficienti, o è possibile che il motore di database non esegua una valutazione corretta. In termini di correzione i piani di esecuzione delle query possono essere forzati manualmente.
Questo modello di prestazioni rilevabili combina tre casi diversi di regressione di piani, ovvero regressione di nuovi piani, regressione di piani precedenti e carico di lavoro modificato di piani esistenti. Il tipo specifico di regressione del piano che si è verificato è indicato nella proprietà details nel log di diagnostica.
La condizione di regressione di nuovi piani fa riferimento a uno stato in cui il motore database inizia l'esecuzione di un nuovo piano delle query non efficiente come quello precedente. La condizione di regressione di piani precedenti fa riferimento allo stato in cui il motore di database passa dall'uso di un nuovo piano più efficiente all'uso del piano precedente, che non efficiente come quello nuovo. La regressione correlata al carico di lavoro modificato di piani esistenti fa riferimento allo stato in cui il piano precedente e quello nuovo vengono continuamente alternati, con una preferenza verso il piano con prestazioni inferiori.
Per altre informazioni sulle regressioni di piani, vedere What is plan regression in SQL server? (Informazioni sulla regressione di piani in SQL Server).
Risoluzione dei problemi
Il logo di diagnostica include gli hash delle query, l'ID del piano appropriato, l'ID del piano non valido e gli ID delle query. È possibile usare queste informazioni come base per la risoluzione dei problemi.
È possibile analizzare i dati per individuare il piano con prestazioni migliori per le query specifiche che è possibile identificare in base agli hash forniti. Dopo aver determinato il piano più adatto alle query, è possibile applicarlo manualmente.
Per altre informazioni, vedere How SQL Server prevents plan regressions (Come SQL Server impedisce le regressioni di piani).
Suggerimento
Le funzionalità di intelligenza incorporate possono gestire automaticamente i piani di esecuzione delle query con le prestazioni migliori per i database in uso.
Per un'ottimizzazione continua delle prestazioni, si consiglia di abilitare l'ottimizzazione automatica. Questa funzionalità di intelligenza incorporata monitora in continuo il database, ottimizza automaticamente e crea i piani di esecuzione delle query con prestazioni migliori per i database.
Modifica del valore di configurazione in ambito database
Situazione
Questo modello di prestazioni rilevabili indica una condizione in cui viene rilevata una modifica nella configurazione in ambito database che causa una regressione delle prestazioni rispetto al comportamento del carico di lavoro del database dei sette giorni precedenti. Ciò indica che le modifiche recenti apportate alla configurazione in ambito database non sembrano essere utili per le prestazioni del database in uso.
La modifica della configurazione in ambito database può essere impostata per ogni singolo database. Questa configurazione viene usata caso per caso per ottimizzare le singole prestazioni del database. Le opzioni seguenti possono essere configurate per ogni singolo database: MAXDOP, LEGACY_CARDINALITY_ESTIMATION, PARAMETER_SNIFFING, QUERY_OPTIMIZER_HOTFIXES e CLEAR PROCEDURE_CACHE.
Risoluzione dei problemi
Il log di diagnostica include le modifiche della configurazione in ambito database apportate di recente che hanno causato la riduzione delle prestazioni rispetto al comportamento del carico di lavoro dei sette giorni precedenti. È possibile ripristinare le modifiche di configurazione reimpostando i valori precedenti. Si possono anche ottimizzare i singoli valori fino a ottenere il livello di prestazioni desiderato. È possibile copiare i valori di configurazione in ambito database da un database simile con prestazioni soddisfacenti. Se non si riesce a risolvere i problemi di prestazioni, ripristinare i valori predefiniti e tentare di avviare un'ottimizzazione partendo da questa baseline.
Per altre informazioni sull'ottimizzazione della configurazione in ambito database e sulla sintassi T-SQL per la modifica della configurazione, vedere ALTER DATABASE SCOPED CONFIGURATION (Transact-SQL).
Client lento
Situazione
Questo modello di prestazioni rilevabili indica una condizione in cui il client che usa il database non è in grado di usare l'output del database alla velocità con cui quest'ultimo invia i risultati. Dato che il database non archivia i risultati delle query eseguite in un buffer, subisce un rallentamento e rimane in attesa che il client usi i risultati della query trasmessi prima di procedere. Questa condizione potrebbe anche essere correlata a una rete lenta che non è in grado di trasmettere in modo abbastanza rapido gli output dal database al client che li usa.
Questa condizione viene generata solo se viene rilevata una regressione delle prestazioni rispetto al comportamento del carico di lavoro del database dei sette giorni precedenti. Questo problema di prestazioni viene rilevato solo se si verifica una riduzione delle prestazioni statisticamente significativa rispetto al comportamento delle prestazioni precedenti.
Risoluzione dei problemi
Questo modello di prestazioni rilevabili indica una condizione sul lato client. Sono richiesti interventi di risoluzione dei problemi nell'applicazione sul lato client o nella rete sul lato client. Il log di diagnostica include gli hash e i tempi di attesa delle query che sembrano attendere da più tempo che il client ne usi i risultati nelle due ore precedenti. È possibile usare queste informazioni come base per la risoluzione dei problemi.
È possibile ottimizzare le prestazioni dell'applicazione per l'uso di queste query oppure valutare possibili problemi di latenza della rete. Dato che il problema di riduzione delle prestazioni è basato su una modifica nella baseline delle prestazioni negli ultimi sette giorni, è possibile verificare se questo evento di regressione delle prestazioni è causato da modifiche recenti delle condizioni per l'applicazione o la rete.
Downgrade del piano tariffario
Situazione
Questo modello di prestazioni rilevabili indica una condizione in cui è stato eseguito il downgrade del piano tariffario della sottoscrizione al database. A causa della riduzione delle risorse (DTU) disponibili per il database, il sistema ha rilevato un calo delle prestazioni correnti del database rispetto alla baseline dei sette giorni precedenti.
Potrebbe essersi verificata anche una condizione in cui è stato eseguito il downgrade del piano tariffario della sottoscrizione al database, aggiornato in seguito a un livello superiore entro un breve periodo di tempo. Il rilevamento di questa riduzione temporanea del livello delle prestazioni è indicato nella sezione dei dettagli del log di diagnostica come downgrade e aggiornamento del piano tariffario.
Risoluzione dei problemi
Se il piano tariffario è stato ridotto e di conseguenza sono state ridotte le DTU disponibili e le prestazioni sono soddisfacenti, non è necessario eseguire alcuna azione. Se il piano tariffario è stato ridotto e non si è soddisfatti delle prestazioni dei database, ridurre i carichi di lavoro del database o provare a passare a un livello superiore del piano tariffario.
Flusso di risoluzione dei problemi consigliato
Per un approccio consigliato alla risoluzione dei problemi di prestazioni con Intelligent Insights, seguire il diagramma di flusso.
Accedere a Intelligent Insights nel portale di Azure passando ad Analisi SQL di Azure. Tentare di individuare l'avviso relativo alle prestazioni in arrivo e selezionarlo. Identificare cosa accade nella pagina dei rilevamenti. Osservare l'analisi della causa radice del problema indicata, il testo e le tendenze nel tempo della query e l'evoluzione degli eventi imprevisti. Tentare di risolvere il problema usando i consigli di Intelligent Insights per ridurre il problema di prestazioni.
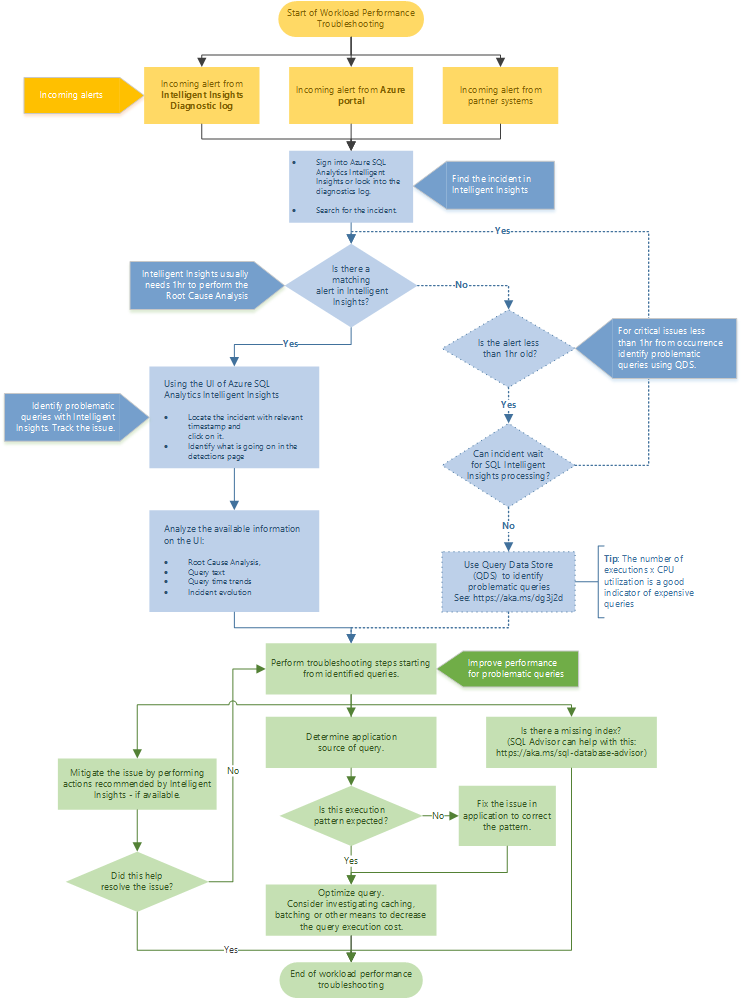
Suggerimento
Selezionare il diagramma di flusso per scaricarne una versione in formato PDF.
Intelligent Insights in genere ha bisogno di un'ora di tempo per eseguire l'analisi della causa radice del problema di prestazioni. Se non è possibile individuare il problema in Intelligent Insights ed è cruciale trovare una soluzione, usare Query Store per identificare manualmente la causa radice del problema di prestazioni. (In genere, questi problemi risalgono a meno di un'ora prima). Per maggiori informazioni, vedere Monitorare le prestazioni usando Query Store.
Passaggi successivi
- Informazioni sui concetti di Intelligent Insights.
- Usare il log di diagnostica delle prestazioni di Intelligent Insights.
- Monitorare usando Analisi SQL di Azure.
- Informazioni su come raccogliere e usare i dati dei log dalle risorse di Azure.
Commenti e suggerimenti
Presto disponibile: nel corso del 2024 verranno dismessi i problemi di GitHub come meccanismo di feedback per il contenuto e verranno sostituiti con un nuovo sistema di feedback. Per altre informazioni, vedere: https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per