Esercitazione: Eseguire un carico di lavoro parallelo con Azure Batch usando l'API Python
Usare Azure Batch per eseguire in modo efficiente processi batch paralleli e HPC (High Performance Computing) su larga scala in Azure. Questa esercitazione illustra un esempio Python di esecuzione di un carico di lavoro parallelo usando Batch. Vengono fornite informazioni su un flusso di lavoro dell'applicazione Batch comune e su come interagire a livello di codice con le risorse di Archiviazione e Batch.
- Eseguire l'autenticazione con gli account Batch e Archiviazione.
- Caricare i file di input in Archiviazione.
- Creare un pool di nodi di calcolo per eseguire un'applicazione.
- Creare un processo e attività per elaborare i file di input.
- Monitorare l'esecuzione delle attività.
- Recuperare i file di output.
In questa esercitazione si converteno file multimediali MP4 in formato MP3, in parallelo, usando lo strumento open source ffmpeg .
Se non si ha una sottoscrizione di Azure, creare un account Azure gratuito prima di iniziare.
Prerequisiti
Gestione pacchetti pip
Un account Azure Batch e un account di archiviazione di Azure collegato. Per creare questi account, vedere le guide introduttive di Batch per portale di Azure o l'interfaccia della riga di comando di Azure.
Accedere ad Azure
Accedi al portale di Azure.
Ottenere le credenziali dell'account
Per questo esempio, è necessario fornire le credenziali per gli account di archiviazione e Batch. Un modo semplice per ottenere le credenziali necessarie consiste nell'usare il portale di Azure. È anche possibile ottenere le credenziali usando le API di Azure o gli strumenti da riga di comando.
Selezionare Tutti i servizi>Account Batch e quindi selezionare il nome dell'account Batch.
Per visualizzare le credenziali di Batch, selezionare Chiavi. Copiare i valori di Account Batch, URL e Chiave di accesso primaria in un editor di testo.
Per visualizzare il nome e le chiavi dell'account di archiviazione, selezionare Account di archiviazione. Copiare i valori dei campi Nome account di archiviazione e Key1 in un editor di testo.
Scaricare ed eseguire l'app di esempio
Scaricare l'app di esempio
Scaricare o clonare l'app di esempio da GitHub. Per clonare il repository dell'app di esempio con un client Git, usare il comando seguente:
git clone https://github.com/Azure-Samples/batch-python-ffmpeg-tutorial.git
Passare alla directory che contiene il file batch_python_tutorial_ffmpeg.py.
Nell'ambiente Python installare i pacchetti necessari usando pip.
pip install -r requirements.txt
Usare un editor di codice per aprire il file config.py. Aggiornare le stringhe delle credenziali degli account di archiviazione e Batch con valori univoci per gli account in uso. Ad esempio:
_BATCH_ACCOUNT_NAME = 'yourbatchaccount'
_BATCH_ACCOUNT_KEY = 'xxxxxxxxxxxxxxxxE+yXrRvJAqT9BlXwwo1CwF+SwAYOxxxxxxxxxxxxxxxx43pXi/gdiATkvbpLRl3x14pcEQ=='
_BATCH_ACCOUNT_URL = 'https://yourbatchaccount.yourbatchregion.batch.azure.com'
_STORAGE_ACCOUNT_NAME = 'mystorageaccount'
_STORAGE_ACCOUNT_KEY = 'xxxxxxxxxxxxxxxxy4/xxxxxxxxxxxxxxxxfwpbIC5aAWA8wDu+AFXZB827Mt9lybZB1nUcQbQiUrkPtilK5BQ=='
Eseguire l'app
Per eseguire lo script:
python batch_python_tutorial_ffmpeg.py
Quando si esegue l'applicazione di esempio, l'output della console è simile al seguente. Durante l'esecuzione si verifica una pausa in corrispondenza di Monitoring all tasks for 'Completed' state, timeout in 00:30:00... mentre vengono avviati i nodi di calcolo del pool.
Sample start: 11/28/2018 3:20:21 PM
Container [input] created.
Container [output] created.
Uploading file LowPriVMs-1.mp4 to container [input]...
Uploading file LowPriVMs-2.mp4 to container [input]...
Uploading file LowPriVMs-3.mp4 to container [input]...
Uploading file LowPriVMs-4.mp4 to container [input]...
Uploading file LowPriVMs-5.mp4 to container [input]...
Creating pool [LinuxFFmpegPool]...
Creating job [LinuxFFmpegJob]...
Adding 5 tasks to job [LinuxFFmpegJob]...
Monitoring all tasks for 'Completed' state, timeout in 00:30:00...
Success! All tasks completed successfully within the specified timeout period.
Deleting container [input]....
Sample end: 11/28/2018 3:29:36 PM
Elapsed time: 00:09:14.3418742
Passare all'account Batch nel portale di Azure per monitorare il pool, i nodi di calcolo, il processo e le attività. Ad esempio, per visualizzare una mappa termica dei nodi di calcolo nel pool, selezionare Pool>LinuxFFmpegPool.
Quando le attività sono in esecuzione, la mappa termica è simile all'esempio seguente:
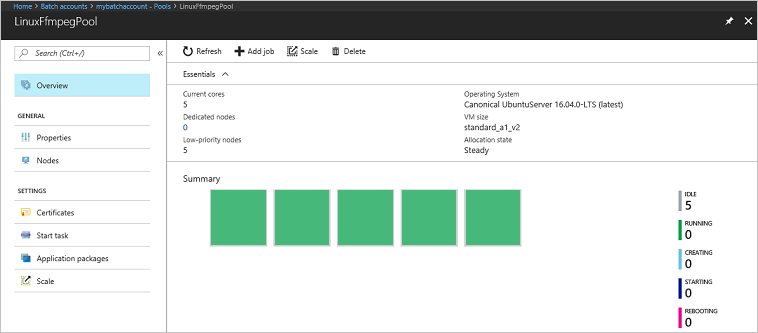
Quando si esegue l'applicazione con la configurazione predefinita, il tempo di esecuzione tipico è di circa 5 minuti. La maggior parte del tempo è necessaria per la creazione del pool.
Recuperare i file di output
È possibile usare il portale di Azure per scaricare i file MP3 di output generati dalle attività ffmpeg.
- Fare clic su Tutti i servizi>Account di archiviazione e quindi fare clic sul nome dell'account di archiviazione.
- Fare clic su BLOB>output.
- Fare clic con il pulsante destro del mouse su uno dei file MP3 di output e quindi scegliere Scarica. Seguire i prompt nel browser per aprire o salvare il file.
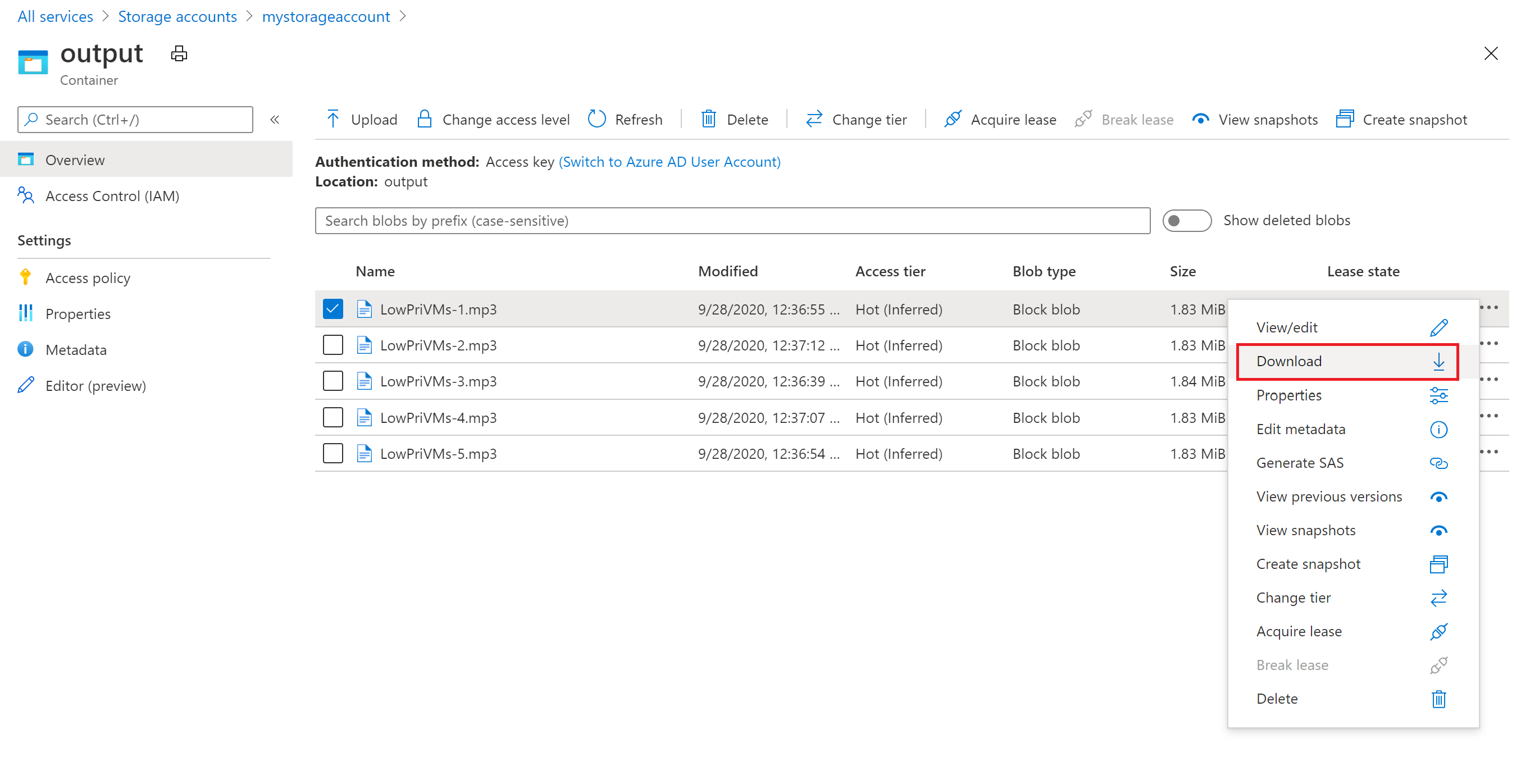
Anche se non viene mostrato in questo esempio, è anche possibile scaricare i file a livello di codice dai nodi di calcolo o dal contenitore di archiviazione.
Esaminare il codice
Nelle sezioni seguenti si esamineranno in dettaglio i singoli passaggi eseguiti dall'applicazione di esempio per l'elaborazione di un carico di lavoro nel servizio Batch. Fare riferimento al codice Python mentre si legge la parte restante di questo articolo, perché non vengono illustrate tutte le righe di codice dell'esempio.
Autenticare i client BLOB e Batch
Per interagire con un account di archiviazione, l'app usa il pacchetto azure-storage-blob per creare un oggetto BlockBlobService.
blob_client = azureblob.BlockBlobService(
account_name=_STORAGE_ACCOUNT_NAME,
account_key=_STORAGE_ACCOUNT_KEY)
L'app crea un oggetto BatchServiceClient per creare e gestire pool, processi e attività nel servizio Batch. Il client Batch nell'esempio usa l'autenticazione con chiave condivisa. Batch supporta anche l'autenticazione tramite Microsoft Entra ID, per autenticare singoli utenti o un'applicazione automatica.
credentials = batchauth.SharedKeyCredentials(_BATCH_ACCOUNT_NAME,
_BATCH_ACCOUNT_KEY)
batch_client = batch.BatchServiceClient(
credentials,
base_url=_BATCH_ACCOUNT_URL)
Caricare i file di input
L'applicazione usa il riferimento blob_client per creare un contenitore di archiviazione per i file MP4 di input e un contenitore per l'output dell'attività. Chiama quindi la upload_file_to_container funzione per caricare i file MP4 nella directory InputFiles locale nel contenitore. I file nel contenitore di archiviazione sono definiti come oggetti ResourceFile di Batch che successivamente Batch può scaricare nei nodi di calcolo.
blob_client.create_container(input_container_name, fail_on_exist=False)
blob_client.create_container(output_container_name, fail_on_exist=False)
input_file_paths = []
for folder, subs, files in os.walk(os.path.join(sys.path[0], './InputFiles/')):
for filename in files:
if filename.endswith(".mp4"):
input_file_paths.append(os.path.abspath(
os.path.join(folder, filename)))
# Upload the input files. This is the collection of files that are to be processed by the tasks.
input_files = [
upload_file_to_container(blob_client, input_container_name, file_path)
for file_path in input_file_paths]
Creare un pool di nodi di calcolo
L'esempio crea quindi un pool di nodi di calcolo nell'account Batch con una chiamata a create_pool. Questa funzione definita usa la classe PoolAddParameter di Batch per impostare il numero di nodi, le dimensioni delle VM e una configurazione del pool. In questo caso, un oggetto VirtualMachineConfiguration specifica un oggetto ImageReference a un'immagine Ubuntu Server 20.04 LTS pubblicata in Azure Marketplace. Batch supporta una vasta gamma di immagini di VM in Azure Marketplace, oltre che immagini di VM personalizzate.
Il numero di nodi e le dimensioni delle VM vengono impostati usando costanti definite. Batch supporta nodi dedicati e nodi spot ed è possibile usare uno o entrambi i pool. I nodi dedicati sono riservati per il pool. I nodi spot vengono offerti a un prezzo ridotto rispetto alla capacità di macchine virtuali in eccedenza in Azure. I nodi spot diventano non disponibili se Azure non dispone di capacità sufficiente. Per impostazione predefinita, l'esempio crea un pool contenente solo cinque nodi Spot di dimensioni Standard_A1_v2.
Oltre alle proprietà dei nodi fisici, la configurazione del pool include un oggetto StartTask. L'attività StartTask viene eseguita in ogni nodo quando questo viene aggiunto al pool e ogni volta che viene riavviato. In questo esempio l'oggetto StartTask esegue i comandi della shell Bash per installare il pacchetto ffmpeg e le dipendenze nei nodi.
Il metodo pool.add invia il pool al servizio Batch.
new_pool = batch.models.PoolAddParameter(
id=pool_id,
virtual_machine_configuration=batchmodels.VirtualMachineConfiguration(
image_reference=batchmodels.ImageReference(
publisher="Canonical",
offer="UbuntuServer",
sku="20.04-LTS",
version="latest"
),
node_agent_sku_id="batch.node.ubuntu 20.04"),
vm_size=_POOL_VM_SIZE,
target_dedicated_nodes=_DEDICATED_POOL_NODE_COUNT,
target_low_priority_nodes=_LOW_PRIORITY_POOL_NODE_COUNT,
start_task=batchmodels.StartTask(
command_line="/bin/bash -c \"apt-get update && apt-get install -y ffmpeg\"",
wait_for_success=True,
user_identity=batchmodels.UserIdentity(
auto_user=batchmodels.AutoUserSpecification(
scope=batchmodels.AutoUserScope.pool,
elevation_level=batchmodels.ElevationLevel.admin)),
)
)
batch_service_client.pool.add(new_pool)
Creare un processo
Un processo Batch specifica un pool in cui eseguire le attività e impostazioni facoltative, ad esempio una priorità e una pianificazione per il lavoro. L'esempio crea un processo con una chiamata a create_job. La funzione definita usa la classe JobAddParameter per creare un processo nel pool. Il metodo job.add invia il pool al servizio Batch. Inizialmente il processo è privo di attività.
job = batch.models.JobAddParameter(
id=job_id,
pool_info=batch.models.PoolInformation(pool_id=pool_id))
batch_service_client.job.add(job)
Creare attività
L'app crea le attività nel processo con una chiamata a add_tasks. Questa funzione definita crea un elenco di oggetti attività usando la classe TaskAddParameter. Ogni attività esegue ffmpeg per elaborare un oggetto resource_files di input usando un parametro command_line. Lo strumento ffmpeg è stato installato in precedenza in ogni nodo al momento della creazione del pool. In questo caso, la riga di comando esegue ffmpeg per convertire ogni file (video) MP4 di input in un file (audio) MP3.
L'esempio crea un oggetto OutputFile per il file MP3 dopo l'esecuzione della riga di comando. I file di output di ogni attività, in questo caso uno, vengono caricati in un contenitore nell'account di archiviazione collegato, usando la proprietà output_files dell'attività.
L'app aggiunge quindi le attività al processo con il metodo task.add_collection, che le accoda per l'esecuzione nei nodi di calcolo.
tasks = list()
for idx, input_file in enumerate(input_files):
input_file_path = input_file.file_path
output_file_path = "".join((input_file_path).split('.')[:-1]) + '.mp3'
command = "/bin/bash -c \"ffmpeg -i {} {} \"".format(
input_file_path, output_file_path)
tasks.append(batch.models.TaskAddParameter(
id='Task{}'.format(idx),
command_line=command,
resource_files=[input_file],
output_files=[batchmodels.OutputFile(
file_pattern=output_file_path,
destination=batchmodels.OutputFileDestination(
container=batchmodels.OutputFileBlobContainerDestination(
container_url=output_container_sas_url)),
upload_options=batchmodels.OutputFileUploadOptions(
upload_condition=batchmodels.OutputFileUploadCondition.task_success))]
)
)
batch_service_client.task.add_collection(job_id, tasks)
Monitorare le attività
Quando le attività vengono aggiunte a un processo, Batch le accoda automaticamente e ne pianifica l'esecuzione nei nodi di calcolo nel pool associato. In base alle impostazioni specificate, Batch gestisce tutte le operazioni di accodamento, pianificazione, ripetizione di tentativi e tutte le altre operazioni di amministrazione relative alle attività.
Sono disponibili molti approcci al monitoraggio dell'esecuzione delle attività. La funzione wait_for_tasks_to_complete in questo esempio usa l'oggetto TaskState per monitorare le attività al fine di individuare un determinato stato, in questo caso lo stato completato, entro un limite di tempo.
while datetime.datetime.now() < timeout_expiration:
print('.', end='')
sys.stdout.flush()
tasks = batch_service_client.task.list(job_id)
incomplete_tasks = [task for task in tasks if
task.state != batchmodels.TaskState.completed]
if not incomplete_tasks:
print()
return True
else:
time.sleep(1)
...
Pulire le risorse
Al termine dell'esecuzione delle attività, l'app elimina automaticamente il contenitore di archiviazione di input creato e consente di scegliere se eliminare il processo e il pool di Batch. Le classi JobOperations e PoolOperations di BatchClient hanno entrambe metodi di eliminazione, che vengono chiamati se l'utente conferma l'eliminazione. Anche se non vengono addebitati costi per i processi e per le attività, vengono invece addebiti costi per i nodi di calcolo. È quindi consigliabile allocare solo i pool necessari. Quando si elimina il pool, tutto l'output delle attività nei nodi viene eliminato. I file di input e output rimangono tuttavia nell'account di archiviazione.
Quando non sono più necessari, eliminare il gruppo di risorse, l'account Batch e l'account di archiviazione. A tale scopo, nella portale di Azure selezionare il gruppo di risorse per l'account Batch e scegliere Elimina gruppo di risorse.
Passaggi successivi
Questa esercitazione ha descritto come:
- Eseguire l'autenticazione con gli account Batch e Archiviazione.
- Caricare i file di input in Archiviazione.
- Creare un pool di nodi di calcolo per eseguire un'applicazione.
- Creare un processo e attività per elaborare i file di input.
- Monitorare l'esecuzione delle attività.
- Recuperare i file di output.
Per altri esempi sull'uso dell'API Python per pianificare ed elaborare carichi di lavoro batch, vedere gli esempi di Batch Python in GitHub.