Eseguire il training di un modello di riconoscimento vocale personalizzato
Questo articolo illustra come eseguire il training di un modello personalizzato per migliorare l'accuratezza del riconoscimento dal modello di base Microsoft. L'accuratezza e la qualità del riconoscimento vocale di un modello di riconoscimento vocale personalizzato rimangono coerenti, anche quando viene rilasciato un nuovo modello di base.
Nota
Si paga per l'utilizzo del modello di riconoscimento vocale personalizzato e l'hosting degli endpoint. Verranno addebitati anche i costi per il training del modello di riconoscimento vocale personalizzato se il modello di base è stato creato il 1° ottobre 2023 e versioni successive. Non viene addebitato alcun costo per il training se il modello di base è stato creato prima di ottobre 2023. Per altre informazioni, vedere Prezzi di Riconoscimento vocale di Azure e la sezione Addebito per l'adattamento nella guida alla migrazione del riconoscimento vocale al testo 3.2.
Il training di un modello è in genere un processo iterativo. Selezionare prima di tutto un modello di base che rappresenta il punto di partenza per un nuovo modello. Si esegue il training di un modello con set di dati che possono includere testo e audio e quindi si esegue il test. Se la qualità o l'accuratezza del riconoscimento non soddisfa i requisiti, è possibile creare un nuovo modello con più dati di training o modificati e quindi ripetere il test.
È possibile usare un modello personalizzato per un periodo di tempo limitato dopo il training. È necessario ricreare e adattare periodicamente il modello personalizzato dal modello di base più recente per sfruttare l'accuratezza e la qualità migliorate. Per altre informazioni, vedere Ciclo di vita del modello e dell'endpoint.
Importante
Se si esegue il training di un modello personalizzato con dati audio, scegliere un'area di risorse Voce con hardware dedicato per il training dei dati audio. Dopo aver eseguito il training di un modello, è possibile copiarlo in una risorsa Voce in un'altra area in base alle esigenze.
Nelle aree con hardware dedicato per il training vocale personalizzato, il servizio Voce userà fino a 20 ore di dati di training audio e può elaborare circa 10 ore di dati al giorno. In altre aree, il servizio Voce usa fino a 8 ore di dati audio e può elaborare circa 1 ora di dati al giorno. Per altre informazioni, vedere note a piè di pagina nella tabella delle aree .
Creazione di un modello
Dopo aver caricato i set di dati di training, seguire queste istruzioni per avviare il training del modello:
Accedere a Speech Studio.
Selezionare Riconoscimento vocale> personalizzato Nome progetto Eseguire il training >di modelli personalizzati.
Selezionare Esegui training di un nuovo modello.
Nella pagina Selezionare un modello di base selezionare un modello di base e quindi selezionare Avanti. Se non si è certi, selezionare il modello più recente nella parte superiore dell'elenco. Il nome del modello di base corrisponde alla data in cui è stata rilasciata in formato AAAAMMGG. Le funzionalità di personalizzazione del modello di base sono elencate tra parentesi dopo il nome del modello in Speech Studio.
Importante
Prendere nota della data di scadenza per l'adattamento. Questa è l'ultima data in cui è possibile usare il modello di base per il training. Per altre informazioni, vedere Ciclo di vita del modello e dell'endpoint.
Nella pagina Scegli dati selezionare uno o più set di dati da usare per il training. Se non sono disponibili set di dati, annullare la configurazione e quindi passare al menu Set di dati voce per caricare i set di dati.
Immettere un nome e una descrizione per il modello personalizzato e quindi selezionare Avanti.
Facoltativamente, selezionare la casella Aggiungi test nel passaggio successivo. Se si ignora questo passaggio, è possibile eseguire gli stessi test in un secondo momento. Per altre informazioni, vedere Qualità del riconoscimento dei test e Modello di test in modo quantitativo.
Selezionare Salva e chiudi per avviare la compilazione per il modello personalizzato.
Tornare alla pagina Esegui training di modelli personalizzati.
Importante
Prendere nota della data di scadenza . Questa è l'ultima data in cui è possibile usare il modello personalizzato per il riconoscimento vocale. Per altre informazioni, vedere Ciclo di vita del modello e dell'endpoint.
Per creare un modello con set di dati per il training, usare il spx csr model create comando . Creare i parametri della richiesta in base alle istruzioni seguenti:
- Impostare il
projectparametro sull'ID di un progetto esistente. Questo parametro è consigliato in modo da poter anche visualizzare e gestire il modello in Speech Studio. È possibile eseguire ilspx csr project listcomando per ottenere i progetti disponibili. - Impostare il parametro obbligatorio
datasetsull'ID di un set di dati da usare per il training. Per specificare più set di dati, impostare ildatasetsparametro (plurale) e separare gli ID con un punto e virgola. - Impostare il parametro obbligatorio
language. Le impostazioni locali del set di dati devono corrispondere alle impostazioni locali del progetto. Le impostazioni locali non possono essere modificate in un secondo momento. Il parametro dell'interfaccia dellalocaleriga di comandolanguagedi Voce corrisponde alla proprietà nella richiesta e nella risposta JSON. - Impostare il parametro obbligatorio
name. Questo parametro è il nome visualizzato in Speech Studio. Il parametro dell'interfaccia delladisplayNameriga di comandonamedi Voce corrisponde alla proprietà nella richiesta e nella risposta JSON. - Facoltativamente, è possibile impostare la
baseproprietà . Ad esempio:--base 1aae1070-7972-47e9-a977-87e3b05c457d. Se non si specificabase, viene usato il modello di base predefinito per le impostazioni locali. Il parametro dell'interfaccia dellabaseModelriga di comandobasedi Voce corrisponde alla proprietà nella richiesta e nella risposta JSON.
Ecco un esempio di comando dell'interfaccia della riga di comando di Voce che crea un modello con set di dati per il training:
spx csr model create --api-version v3.1 --project YourProjectId --name "My Model" --description "My Model Description" --dataset YourDatasetId --language "en-US"
Nota
In questo esempio base l'oggetto non è impostato, quindi viene usato il modello di base predefinito per le impostazioni locali. L'URI del modello di base viene restituito nella risposta.
Dovrebbe essere visualizzato un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/1aae1070-7972-47e9-a977-87e3b05c457d"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/datasets/69e46263-ab10-4ab4-abbe-62e370104d95"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7/manifest",
"copyTo": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7:copyto"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/5d25e60a-7f4a-4816-afd9-783bb8daccfc"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-07-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-21T13:21:01Z",
"status": "NotStarted",
"createdDateTime": "2022-05-21T13:21:01Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Importante
Prendere nota della data nella adaptationDateTime proprietà . Questa è l'ultima data in cui è possibile usare il modello di base per il training. Per altre informazioni, vedere Ciclo di vita del modello e dell'endpoint.
Prendere nota della data nella transcriptionDateTime proprietà . Questa è l'ultima data in cui è possibile usare il modello personalizzato per il riconoscimento vocale. Per altre informazioni, vedere Ciclo di vita del modello e dell'endpoint.
La proprietà di primo livello self nel corpo della risposta è l'URI del modello. Usare questo URI per ottenere informazioni dettagliate sulle date di progetto, manifesto e deprecazione del modello. È anche possibile usare questo URI per aggiornare o eliminare un modello.
Per informazioni sull'interfaccia della riga di comando di Voce con i modelli, eseguire il comando seguente:
spx help csr model
Per creare un modello con set di dati per il training, usare l'operazione Models_Create dell'API REST Riconoscimento vocale in testo. Costruire il corpo della richiesta in base alle istruzioni seguenti:
- Impostare la
projectproprietà sull'URI di un progetto esistente. Questa proprietà è consigliata per consentire anche di visualizzare e gestire il modello in Speech Studio. È possibile effettuare una richiesta di Projects_List per ottenere i progetti disponibili. - Impostare la proprietà obbligatoria
datasetssull'URI dei set di dati da usare per il training. - Impostare la proprietà obbligatoria
locale. Le impostazioni locali del modello devono corrispondere alle impostazioni locali del progetto e del modello di base. Le impostazioni locali non possono essere modificate in un secondo momento. - Impostare la proprietà obbligatoria
displayName. Questa proprietà è il nome visualizzato in Speech Studio. - Facoltativamente, è possibile impostare la
baseModelproprietà . Ad esempio:"baseModel": {"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/1aae1070-7972-47e9-a977-87e3b05c457d"}. Se non si specificabaseModel, viene usato il modello di base predefinito per le impostazioni locali.
Effettuare una richiesta HTTP POST usando l'URI, come illustrato nell'esempio seguente. Sostituire YourSubscriptionKey con la chiave della risorsa Voce, sostituire YourServiceRegion con l'area della risorsa Voce e impostare le proprietà del corpo della richiesta come descritto in precedenza.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/5d25e60a-7f4a-4816-afd9-783bb8daccfc"
},
"displayName": "My Model",
"description": "My Model Description",
"baseModel": null,
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/datasets/69e46263-ab10-4ab4-abbe-62e370104d95"
}
],
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.1/models"
Nota
In questo esempio baseModel l'oggetto non è impostato, quindi viene usato il modello di base predefinito per le impostazioni locali. L'URI del modello di base viene restituito nella risposta.
Dovrebbe essere visualizzato un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/1aae1070-7972-47e9-a977-87e3b05c457d"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/datasets/69e46263-ab10-4ab4-abbe-62e370104d95"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7/manifest",
"copyTo": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7:copyto"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/5d25e60a-7f4a-4816-afd9-783bb8daccfc"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-07-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-21T13:21:01Z",
"status": "NotStarted",
"createdDateTime": "2022-05-21T13:21:01Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Importante
Prendere nota della data nella adaptationDateTime proprietà . Questa è l'ultima data in cui è possibile usare il modello di base per il training. Per altre informazioni, vedere Ciclo di vita del modello e dell'endpoint.
Prendere nota della data nella transcriptionDateTime proprietà . Questa è l'ultima data in cui è possibile usare il modello personalizzato per il riconoscimento vocale. Per altre informazioni, vedere Ciclo di vita del modello e dell'endpoint.
La proprietà di primo livello self nel corpo della risposta è l'URI del modello. Usare questo URI per ottenere informazioni dettagliate sulle date di progetto, manifesto e deprecazione del modello. È anche possibile usare questo URI per aggiornare o eliminare il modello.
Copiare un modello
È possibile copiare un modello in un altro progetto che usa le stesse impostazioni locali. Ad esempio, dopo che un modello è stato sottoposto a training con dati audio in un'area con hardware dedicato per il training, è possibile copiarlo in una risorsa Voce in un'altra area in base alle esigenze.
Seguire queste istruzioni per copiare un modello in un progetto in un'altra area:
- Accedere a Speech Studio.
- Selezionare Riconoscimento vocale> personalizzato Nome progetto Eseguire il training >di modelli personalizzati.
- Selezionare Copia in.
- Nella pagina Copia modello di riconoscimento vocale selezionare un'area di destinazione in cui si vuole copiare il modello.

- Selezionare una risorsa Voce nell'area di destinazione o creare una nuova risorsa Voce.
- Selezionare un progetto in cui si vuole copiare il modello o creare un nuovo progetto.
- Seleziona Copia.

Dopo che il modello è stato copiato correttamente, si riceverà una notifica e sarà possibile visualizzarlo nel progetto di destinazione.
La copia di un modello direttamente in un progetto in un'altra area non è supportata con l'interfaccia della riga di comando di Voce. È possibile copiare un modello in un progetto in un'altra area usando Speech Studio o l'API REST Voce in testo.
Per copiare un modello in un'altra risorsa Voce, usare l'operazione Models_CopyTo dell'API REST Riconoscimento vocale in testo. Costruire il corpo della richiesta in base alle istruzioni seguenti:
- Impostare la proprietà obbligatoria
targetSubscriptionKeysulla chiave della risorsa Voce di destinazione.
Effettuare una richiesta HTTP POST usando l'URI, come illustrato nell'esempio seguente. Usare l'area e l'URI del modello da cui si vuole eseguire la copia. Sostituire YourModelId con l'ID modello, sostituire YourSubscriptionKey con la chiave della risorsa Voce, sostituire YourServiceRegion con l'area della risorsa Voce e impostare le proprietà del corpo della richiesta come descritto in precedenza.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"targetSubscriptionKey": "ModelDestinationSpeechResourceKey"
} ' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.1/models/YourModelId:copyto"
Nota
Solo la targetSubscriptionKey proprietà nel corpo della richiesta contiene informazioni sulla risorsa Voce di destinazione.
Dovrebbe essere visualizzato un corpo della risposta nel formato seguente:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/eb5450a7-3ca2-461a-b2d7-ddbb3ad96540"
},
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae/manifest",
"copyTo": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae:copyto"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-07-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-22T23:15:27Z",
"status": "NotStarted",
"createdDateTime": "2022-05-22T23:15:27Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description",
"customProperties": {
"PortalAPIVersion": "3",
"Purpose": "",
"VadKind": "None",
"ModelClass": "None",
"UsesHalide": "False",
"IsDynamicGrammarSupported": "False"
}
}
Connessione un modello
È possibile che i modelli siano stati copiati da un progetto usando l'interfaccia della riga di comando di Voce o l'API REST, senza essere connessi a un altro progetto. Connessione un modello è una questione di aggiornamento del modello con un riferimento al progetto.
Se viene richiesto in Speech Studio, è possibile connetterli selezionando il pulsante Connessione.
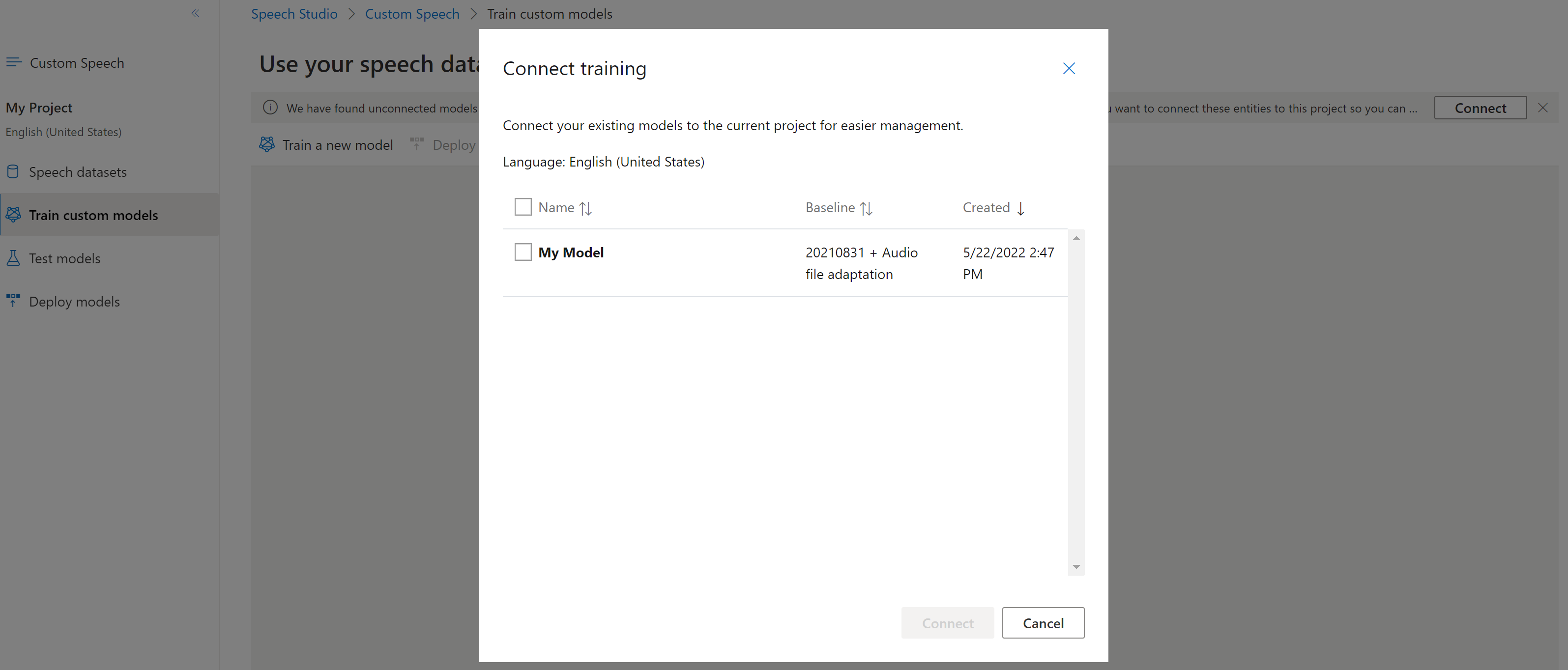
Per connettere un modello a un progetto, usare il spx csr model update comando . Creare i parametri della richiesta in base alle istruzioni seguenti:
- Impostare il
projectparametro sull'URI di un progetto esistente. Questo parametro è consigliato in modo da poter anche visualizzare e gestire il modello in Speech Studio. È possibile eseguire ilspx csr project listcomando per ottenere i progetti disponibili. - Impostare il parametro obbligatorio
modelIdsull'ID del modello che si desidera connettere al progetto.
Ecco un esempio di comando dell'interfaccia della riga di comando di Voce che connette un modello a un progetto:
spx csr model update --api-version v3.1 --model YourModelId --project YourProjectId
Dovrebbe essere visualizzato un corpo della risposta nel formato seguente:
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/e6ffdefd-9517-45a9-a89c-7b5028ed0e56"
},
}
Per informazioni sull'interfaccia della riga di comando di Voce con i modelli, eseguire il comando seguente:
spx help csr model
Per connettere un nuovo modello a un progetto della risorsa Voce in cui è stato copiato il modello, usare l'operazione Models_Update dell'API REST Riconoscimento vocale in testo. Costruire il corpo della richiesta in base alle istruzioni seguenti:
- Impostare la proprietà obbligatoria
projectsull'URI di un progetto esistente. Questa proprietà è consigliata per consentire anche di visualizzare e gestire il modello in Speech Studio. È possibile effettuare una richiesta di Projects_List per ottenere i progetti disponibili.
Effettuare una richiesta HTTP PATCH usando l'URI, come illustrato nell'esempio seguente. Usare l'URI del nuovo modello. È possibile ottenere il nuovo ID modello dalla self proprietà del corpo della risposta Models_CopyTo . Sostituire YourSubscriptionKey con la chiave della risorsa Voce, sostituire YourServiceRegion con l'area della risorsa Voce e impostare le proprietà del corpo della richiesta come descritto in precedenza.
curl -v -X PATCH -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/e6ffdefd-9517-45a9-a89c-7b5028ed0e56"
},
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.1/models"
Dovrebbe essere visualizzato un corpo della risposta nel formato seguente:
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/e6ffdefd-9517-45a9-a89c-7b5028ed0e56"
},
}