Eseguire la migrazione di centinaia di terabyte di dati ad Azure Cosmos DB
SI APPLICA A:![]() Nosql
Nosql![]() Mongodb
Mongodb![]() Cassandra
Cassandra![]() Gremlin
Gremlin![]() Tabella
Tabella
Con Azure Cosmos DB è possibile archiviare terabyte di dati. È possibile eseguire una migrazione dei dati su larga scala per spostare il carico di lavoro di produzione in Azure Cosmos DB. Questo articolo descrive i problemi relativi allo spostamento dei dati su larga scala in Azure Cosmos DB e presenta lo strumento che consente di risolvere le problematiche ed eseguire la migrazione dei dati in Azure Cosmos DB. In questo case study, il cliente ha usato l'API Azure Cosmos DB per NoSQL.
Prima di eseguire la migrazione dell'intero carico di lavoro ad Azure Cosmos DB, è possibile eseguire la migrazione di un subset di dati per convalidare alcuni aspetti, ad esempio scelta della chiave di partizione, prestazioni delle query e modellazione dei dati. Dopo aver convalidato il modello di verifica, è possibile spostare l'intero carico di lavoro in Azure Cosmos DB.
Strumenti per la migrazione dei dati
Le strategie di migrazione di Azure Cosmos DB sono attualmente diverse in base alla scelta dell'API e alle dimensioni dei dati. Per eseguire la migrazione di set di dati più piccoli, per convalidare la modellazione dei dati, le prestazioni delle query, la scelta della chiave di partizione e così via, è possibile usare il connettore Azure Cosmos DB di Azure Data Factory. Se si ha familiarità con Spark, è anche possibile scegliere di usare il connettore Spark di Azure Cosmos DB per eseguire la migrazione dei dati.
Sfide per le migrazioni su larga scala
Gli strumenti esistenti per la migrazione dei dati ad Azure Cosmos DB presentano alcune limitazioni che diventano particolarmente evidenti su larga scala:
Funzionalità di scalabilità orizzontale limitate: per eseguire la migrazione di terabyte di dati in Azure Cosmos DB il più rapidamente possibile e usare in modo efficace l'intera velocità effettiva con provisioning, i client di migrazione devono avere la possibilità di aumentare il numero illimitato di istanze.
Mancanza di rilevamento dello stato e check-point: è importante tenere traccia dello stato di avanzamento della migrazione e fare check-point durante la migrazione di set di dati di grandi dimensioni. In caso contrario, qualsiasi errore che si verifica durante la migrazione arresterà la migrazione e sarà necessario avviare il processo da zero. Non sarebbe produttivo riavviare l'intero processo di migrazione quando il 99% di esso è già stato completato.
Mancanza di coda di messaggi non recapitabili: all'interno di set di dati di grandi dimensioni, in alcuni casi potrebbero verificarsi problemi con parti dei dati di origine. Inoltre, potrebbero verificarsi problemi temporanei con il client o la rete. Uno di questi casi non deve causare l'esito negativo dell'intera migrazione. Anche se la maggior parte degli strumenti di migrazione offre solide funzionalità di ripetizione dei tentativi che proteggono da problemi intermittenti, non è sempre sufficiente. Ad esempio, se la dimensione dei documenti dati di origine è inferiore allo 0,01% dei documenti di dati di origine è maggiore di 2 MB, la scrittura del documento avrà esito negativo in Azure Cosmos DB. Idealmente, è utile per lo strumento di migrazione rendere persistenti questi documenti "non riusciti" in un'altra coda di messaggi non recapitabili, che può essere elaborata dopo la migrazione.
Molte di queste limitazioni vengono risolte per strumenti come Azure Data Factory, Servizi di migrazione dei dati di Azure.
Strumento personalizzato con libreria dell'executor bulk
Le problematiche descritte nella sezione precedente possono essere risolte usando uno strumento personalizzato che può essere facilmente ridimensionato in più istanze ed è resiliente agli errori temporanei. Inoltre, lo strumento personalizzato può sospendere e riprendere la migrazione in vari checkpoint. Azure Cosmos DB fornisce già la libreria dell'executor bulk che incorpora alcune di queste funzionalità. Ad esempio, la libreria dell'executor bulk ha già la funzionalità per gestire gli errori temporanei e può aumentare il numero di thread in un singolo nodo per utilizzare circa 500 K UR per nodo. La libreria dell'executor bulk partiziona anche il set di dati di origine in micro batch gestiti in modo indipendente come forma di checkpoint.
Lo strumento personalizzato usa la libreria dell'executor bulk e supporta la scalabilità orizzontale tra più client e per tenere traccia degli errori durante il processo di inserimento. Per usare questo strumento, i dati di origine devono essere partizionati in file distinti in Azure Data Lake Storage (ADLS) in modo che i diversi ruoli di lavoro per la migrazione possano prelevare ogni file e inserirli in Azure Cosmos DB. Lo strumento personalizzato usa una raccolta separata, che archivia i metadati relativi allo stato di avanzamento della migrazione per ogni singolo file di origine in ADLS e tiene traccia di eventuali errori associati.
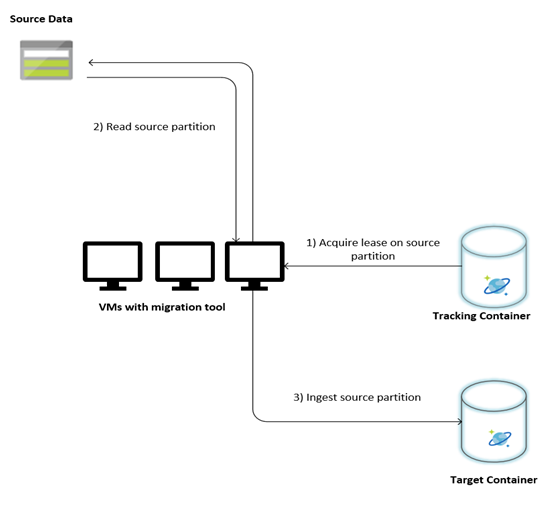
L'immagine seguente descrive il processo di migrazione usando questo strumento personalizzato. Lo strumento viene eseguito in un set di macchine virtuali e ogni macchina virtuale esegue una query sulla raccolta di rilevamento in Azure Cosmos DB per acquisire un lease in una delle partizioni di dati di origine. Al termine, la partizione dei dati di origine viene letta dallo strumento e inserita in Azure Cosmos DB usando la libreria dell'executor bulk. Successivamente, la raccolta di rilevamento viene aggiornata per registrare lo stato di avanzamento dell'inserimento dei dati ed eventuali errori rilevati. Dopo l'elaborazione di una partizione di dati, lo strumento tenta di eseguire una query per la successiva partizione di origine disponibile. Continua a elaborare la partizione di origine successiva fino a quando non viene eseguita la migrazione di tutti i dati. Il codice sorgente per lo strumento è disponibile nel repository di inserimento bulk di Azure Cosmos DB .
La raccolta di rilevamento contiene documenti, come illustrato nell'esempio seguente. Tali documenti verranno visualizzati uno per ogni partizione nei dati di origine. Ogni documento contiene i metadati per la partizione dati di origine, ad esempio la posizione, lo stato della migrazione e gli errori (se presenti):
{
"owner": "25812@bulkimporttest07",
"jsonStoreEntityImportResponse": {
"numberOfDocumentsReceived": 446688,
"isError": false,
"totalRequestUnitsConsumed": 3950252.2800000003,
"errorInfo": [],
"totalTimeTakenInSeconds": 188,
"numberOfDocumentsImported": 446688
},
"storeType": "AZURE_BLOB",
"name": "sourceDataPartition",
"location": "sourceDataPartitionLocation",
"id": "sourceDataPartitionId",
"isInProgress": false,
"operation": "unpartitioned-writes",
"createDate": {
"seconds": 1561667225,
"nanos": 146000000
},
"completeDate": {
"seconds": 1561667515,
"nanos": 180000000
},
"isComplete": true
}
Prerequisiti per la migrazione dei dati
Prima dell'avvio della migrazione dei dati, è necessario considerare alcuni prerequisiti:
Stimare le dimensioni dei dati:
Le dimensioni dei dati di origine potrebbero non corrispondere esattamente alle dimensioni dei dati in Azure Cosmos DB. È possibile inserire alcuni documenti di esempio dall'origine per controllare le dimensioni dei dati in Azure Cosmos DB. A seconda delle dimensioni del documento di esempio, è possibile stimare le dimensioni totali dei dati in Azure Cosmos DB dopo la migrazione.
Ad esempio, se ogni documento dopo la migrazione in Azure Cosmos DB è di circa 1 KB e se sono presenti circa 60 miliardi di documenti nel set di dati di origine, significa che le dimensioni stimate in Azure Cosmos DB saranno vicine a 60 TB.
Pre-creare contenitori con ur sufficienti:
Anche se Azure Cosmos DB aumenta automaticamente l'archiviazione, non è consigliabile iniziare dalle dimensioni del contenitore più piccole. I contenitori più piccoli hanno una disponibilità di velocità effettiva inferiore, il che significa che il completamento della migrazione richiederebbe molto più tempo. È invece utile creare i contenitori con le dimensioni finali dei dati (come stimato nel passaggio precedente) e assicurarsi che il carico di lavoro di migrazione stia consumando completamente la velocità effettiva con provisioning.
Nel passaggio precedente. poiché le dimensioni dei dati sono state stimate per circa 60 TB, per supportare l'intero set di dati è necessario un contenitore di almeno 2,4 M UR.
Stimare la velocità di migrazione:
Supponendo che il carico di lavoro di migrazione possa utilizzare l'intera velocità effettiva con provisioning, il provisioning in tutto fornirà una stima della velocità di migrazione. Continuando l'esempio precedente, sono necessarie 5 UR per scrivere un documento da 1 KB nell'API di Azure Cosmos DB per l'account NoSQL. 2,4 milioni di UR consentirebbe un trasferimento di 480.000 documenti al secondo (o 480 MB/s). Ciò significa che la migrazione completa di 60 TB richiederà 125.000 secondi o circa 34 ore.
Se si vuole che la migrazione venga completata entro un giorno, è necessario aumentare la velocità effettiva con provisioning a 5 milioni di UR.
Disattivare l'indicizzazione:
Poiché la migrazione deve essere completata il prima possibile, è consigliabile ridurre al minimo il tempo e le UR per la creazione di indici per ognuno dei documenti inseriti. Azure Cosmos DB indicizza automaticamente tutte le proprietà, vale la pena ridurre al minimo l'indicizzazione a pochi termini selezionati o disattivarla completamente per il corso della migrazione. È possibile disattivare i criteri di indicizzazione del contenitore modificando indexingMode su nessuno, come illustrato di seguito:
{
"indexingMode": "none"
}
Al termine della migrazione, è possibile aggiornare l'indicizzazione.
Processo di migrazione
Al termine dei prerequisiti, è possibile eseguire la migrazione dei dati seguendo questa procedura:
Importare prima di tutto i dati dall'origine a Archiviazione BLOB di Azure. Per aumentare la velocità di migrazione, è utile eseguire la parallelizzazione tra partizioni di origine distinte. Prima di avviare la migrazione, il set di dati di origine deve essere partizionato in file con dimensioni di circa 200 MB.
La libreria dell'executor bulk può aumentare le prestazioni per usare 500.000 UR in una singola macchina virtuale client. Poiché la velocità effettiva disponibile è di 5 milioni di UR, è necessario effettuare il provisioning di 10 macchine virtuali Ubuntu 16.04 (Standard_D32_v3) nella stessa area in cui si trova il database di Azure Cosmos DB. È necessario preparare queste macchine virtuali con lo strumento di migrazione e il relativo file di impostazioni.
Eseguire il passaggio della coda in una delle macchine virtuali client. Questo passaggio crea la raccolta di rilevamento, che analizza il contenitore ADLS e crea un documento di rilevamento dello stato per ognuno dei file di partizione del set di dati di origine.
Eseguire quindi il passaggio di importazione in tutte le macchine virtuali client. Ognuno dei client può assumere la proprietà di una partizione di origine e inserire i dati in Azure Cosmos DB. Una volta completato e il relativo stato viene aggiornato nella raccolta di rilevamento, i client possono quindi eseguire una query per la successiva partizione di origine disponibile nella raccolta di rilevamento.
Questo processo continua fino a quando non è stato inserito l'intero set di partizioni di origine. Una volta elaborate tutte le partizioni di origine, lo strumento deve essere rieseguito sulla modalità di correzione degli errori nella stessa raccolta di rilevamento. Questo passaggio è necessario per identificare le partizioni di origine che devono essere rielaborate a causa di errori.
Alcuni di questi errori potrebbero essere dovuti a documenti non corretti nei dati di origine. Questi elementi devono essere identificati e corretti. Successivamente, è necessario eseguire di nuovo il passaggio di importazione nelle partizioni non riuscite per eseguirne di nuovo il failover.
Al termine della migrazione, è possibile verificare che il conteggio dei documenti in Azure Cosmos DB corrisponda al numero di documenti nel database di origine. In questo esempio le dimensioni totali in Azure Cosmos DB sono risultate pari a 65 terabyte. Dopo la migrazione, l'indicizzazione può essere attivata in modo selettivo e le UR possono essere abbassate al livello richiesto dalle operazioni del carico di lavoro.
Passaggi successivi
- Per altre informazioni, provare le applicazioni di esempio che usano la libreria dell'executor bulk in .NET e Java.
- La libreria di executor bulk è integrata nel connettore Spark di Azure Cosmos DB per altre informazioni, vedere l'articolo sul connettore Spark di Azure Cosmos DB .
- Contattare il team di prodotti Azure Cosmos DB aprendo un ticket di supporto nel tipo di problema "Consulenza generale" e nel sottotipo di problemi "Large (TB+) per ulteriori informazioni sulle migrazioni su larga scala.
- Si sta tentando di pianificare la capacità per una migrazione ad Azure Cosmos DB? È possibile usare le informazioni del cluster di database esistente per la pianificazione della capacità.
- Se si conosce tutto il numero di vcore e server nel cluster di database esistente, leggere informazioni sulla stima delle unità richiesta tramite vCore o vCPUs
- Se si conosce la frequenza delle richieste tipiche per il carico di lavoro corrente del database, leggere le informazioni sulla stima delle unità richieste con lo strumento di pianificazione della capacità di Azure Cosmos DB