Runtime di integrazione in Azure Data Factory
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
Integration Runtime (IR) è l'infrastruttura di calcolo usata dalle pipeline di Azure Data Factory e Azure Synapse per offrire le funzionalità di integrazione dei dati seguenti in diversi ambienti di rete:
- Flusso di dati: eseguire un Flusso di dati in un ambiente di calcolo di Azure gestito.
- Spostamento dati: copiare dati tra archivi dati in reti pubbliche o private (sia per le reti private locali che virtuali). Il servizio fornisce il supporto per i connettori predefiniti, la conversione del formato, il mapping delle colonne e il trasferimento di dati scalabile ed efficiente.
- Invio attività: inviare e monitorare le attività di trasformazione in esecuzione in un'ampia gamma di servizi di calcolo, ad esempio Azure Databricks, Azure HDInsight, ML Studio (versione classica), database SQL di Azure, SQL Server e altro ancora.
- Esecuzione di pacchetti SSIS: eseguire in modo nativo i pacchetti SQL Server Integration Services (SSIS) in un ambiente di calcolo Azure gestito.
Nelle pipeline di Data Factory e Synapse un'attività definisce l'azione da eseguire. Un servizio collegato definisce un archivio dati o un servizio di calcolo di destinazione. Un runtime di integrazione fornisce il bridge tra le attività e i servizi collegati. Fa riferimento al servizio o all'attività collegata e fornisce l'ambiente di calcolo in cui l'attività viene eseguita direttamente o inviata. Ciò consente di eseguire l'attività nell'area più vicina possibile all'archivio dati o al servizio di calcolo di destinazione per ottimizzare le prestazioni, consentendo al tempo stesso la flessibilità di soddisfare i requisiti di sicurezza e conformità.
I runtime di integrazione possono essere creati nell'interfaccia utente di Azure Data Factory e Azure Synapse direttamente tramite l'hub di gestione, nonché da qualsiasi attività, set di dati o flussi di dati che vi fanno riferimento.
Tipi di runtime di integrazione
Data Factory offre tre tipi di runtime di integrazione ed è consigliabile scegliere il tipo più adatto alle funzionalità di integrazione dei dati e ai requisiti dell'ambiente di rete. I tre tipi di runtime di integrazione sono:
- Azure
- Self-hosted
- Azure-SSIS
Nota
Le pipeline di Synapse attualmente supportano solo i runtime di integrazione self-hosted di Azure.
Nella tabella seguente vengono descritte le funzionalità e il supporto di rete per ogni tipo di runtime di integrazione:
| Tipo di runtime di integrazione | Supporto della rete pubblica | Supporto del collegamento privato |
|---|---|---|
| Azure | Flusso di dati Spostamento dati Invio di attività |
Flusso di dati Spostamento dati Invio di attività |
| Self-hosted | Spostamento dati Invio di attività |
Spostamento dati Invio di attività |
| Azure-SSIS | Esecuzione pacchetti SSIS | Esecuzione pacchetti SSIS |
Nota
I controlli in uscita variano in base al servizio per Il runtime di integrazione di Azure. In Synapse le aree di lavoro hanno opzioni per limitare il traffico in uscita dalla rete virtuale gestita quando si usa Il runtime di integrazione di Azure. In Data Factory tutte le porte vengono aperte per le comunicazioni in uscita quando si usa Il runtime di integrazione di Azure. Azure-SSIS IR può essere integrato con la rete virtuale per fornire controlli di comunicazione in uscita.
Runtime di integrazione di Azure
Un runtime di integrazione di Azure può:
- Eseguire Flusso di dati in Azure
- Eseguire attività di copia tra archivi dati cloud
- Inviare le attività di trasformazione seguenti in una rete pubblica:
- Attività personalizzata .NET
- Attività Funzioni di Azure
- Attività di Databricks Notebook/ Jar/ Python
- Attività U-SQL di Data Lake Analytics
- Attività di recupero dei metadati
- Attività Hive di HDInsight
- Attività Pig di HDInsight
- Attività MapReduce di HDInsight
- Attività HDInsight Spark
- Attività di streaming di HDInsight
- Attività di ricerca
- Attività Batch Execution di Machine Learning Studio (versione classica)
- Attività di aggiornamento delle risorse di Machine Learning Studio (versione classica)
- Attività stored procedure
- Attività di convalida
- Attività Web
Ambiente di rete del runtime di integrazione di Azure
Azure Integration Runtime supporta la connessione agli archivi dati e ai servizi di calcolo con endpoint pubblici accessibili. L'abilitazione di Rete virtuale gestita, Il runtime di integrazione di Azure supporta la connessione agli archivi dati usando il servizio collegamento privato nell'ambiente di rete privata. In Synapse le aree di lavoro hanno opzioni per limitare il traffico in uscita dalla rete virtuale gestita del runtime di integrazione. In Data Factory tutte le porte vengono aperte per le comunicazioni in uscita. Il runtime di integrazione Azure-SSIS può essere integrato con la rete virtuale per fornire controlli di comunicazione in uscita.
Risorsa di calcolo e ridimensionamento del runtime di integrazione di Azure
Il runtime di integrazione di Azure fornisce un calcolo senza server completamente gestito in Azure. Non è necessario preoccuparsi del provisioning dell'infrastruttura, dell'installazione del software, dell'applicazione di patch o del ridimensionamento della capacità. Inoltre si paga solo per la durata dell'utilizzo effettivo.
Il runtime di integrazione di Azure fornisce il calcolo nativo per spostare i dati tra gli archivi dati cloud in modo sicuro, affidabile e ad alte prestazioni. È possibile impostare il numero di unità di integrazione dei dati da usare nell'attività di copia e le dimensioni di calcolo del runtime di integrazione di Azure vengono ridimensionate in modo elastico di conseguenza senza che sia necessario modificare in modo esplicito le dimensioni del runtime di integrazione di Azure.
L'invio di attività è un'operazione leggera per instradare l'attività al servizio di calcolo di destinazione, quindi non è necessario aumentare le dimensioni di calcolo per questo scenario.
Per informazioni sulla creazione e la configurazione di un runtime di integrazione di Azure, vedere Come creare e configurare Il runtime di integrazione di Azure.
Nota
Il runtime di integrazione di Azure include proprietà correlate al runtime di Flusso di dati, che definisce l'infrastruttura di calcolo sottostante che verrebbe usata per eseguire i flussi di dati.
Runtime di integrazione self-hosted
Un runtime di integrazione self-hosted è in grado di eseguire queste operazioni:
- Eseguire attività di copia tra gli archivi dati cloud e un archivio dati in una rete privata.
- Invio delle attività di trasformazione seguenti sulle risorse di calcolo in locale o in Azure Rete virtuale:
- Attività Funzioni di Azure
- Attività personalizzata (eseguita in Azure Batch)
- Attività U-SQL di Data Lake Analytics
- Attività di recupero dei metadati
- Attività Hive di HDInsight (BYOC, Bring Your Own Cluster)
- Attività Pig di HDInsight (BYOC)
- Attività MapReduce di HDInsight (BYOC)
- Attività Spark di HDInsight (BYOC)
- Attività di streaming di HDInsight (BYOC)
- Attività di ricerca
- Attività Batch Execution di Machine Learning Studio (versione classica)
- Attività di aggiornamento delle risorse di Machine Learning Studio (versione classica)
- Attività Execute Pipeline di Machine Learning
- Attività stored procedure
- Attività di convalida
- Attività Web
Nota
Usare il runtime di integrazione self-hosted per supportare gli archivi dati che richiedono driver bring-your-own, ad esempio SAP Hana, MySQL e così via. Per altre informazioni, vedere Archivi dati supportati.
Nota
Java Runtime Environment (JRE) è una dipendenza del runtime di integrazione self-hosted. Assicurarsi di avere installato JRE nello stesso host.
Ambiente di rete del runtime di integrazione self-hosted
Se si vuole eseguire l'integrazione dei dati in modo sicuro in un ambiente di rete privata che non dispone di una linea diretta dall'ambiente cloud pubblico, è possibile installare un runtime di integrazione self-hosted nell'ambiente locale dietro un firewall o all'interno di una rete privata virtuale. Il runtime di integrazione self-hosted stabilisce solo connessioni basate su HTTP in uscita per accedere a Internet.
Risorsa di calcolo e ridimensionamento del runtime di integrazione self-hosted
Installare un runtime di integrazione self-hosted in una macchina locale o in una macchina virtuale all'interno di una rete privata. Attualmente, il runtime di integrazione self-hosted è supportato solo in un sistema operativo Windows.
In termini di disponibilità elevata e scalabilità è possibile aumentare il numero di istanze per il runtime di integrazione self-hosted associando l'istanza logica a più computer locali in modalità attivo-attivo. Per altre informazioni, vedere l'articolo su come creare e configurare un runtime di integrazione self-hosted per informazioni dettagliate.
Runtime di integrazione Azure-SSIS
Per eseguire in modalità lift-and-shift il carico di lavoro SSIS esistente, è possibile creare un runtime di integrazione Azure-SSIS per l'esecuzione di pacchetti SSIS in modo nativo.
Ambiente di rete del runtime di integrazione Azure-SSIS
È possibile effettuare il provisioning di Azure-SSIS IR in una rete pubblica o privata. L'accesso ai dati locali è supportato aggiungendo Azure-SSIS IR a una rete virtuale connessa alla rete locale.
Risorsa di calcolo e ridimensionamento del runtime di integrazione Azure-SSIS
Azure-SSIS IR è un cluster completamente gestito di macchine virtuali di Azure dedicate per eseguire i pacchetti SSIS. È possibile usare database SQL di Azure o Istanza gestita di SQL per il catalogo di progetti/pacchetti SSIS (SSISDB). È possibile aumentare la potenza di calcolo specificando la dimensione del nodo e scalare orizzontalmente specificando il numero di nodi nel cluster. È possibile gestire il costo dell'esecuzione del runtime di integrazione SSIS di Azure arrestandolo e avviandolo come richiesta dei requisiti.
Per altre informazioni, vedere Come creare e configurare Azure-SSIS IR. Dopo la creazione, è possibile distribuire e gestire i pacchetti SSIS esistenti senza alcuna modifica usando strumenti familiari, ad esempio SQL Server Data Tools (SSDT) e SQL Server Management Studio (SSMS), proprio come l'uso di SSIS in locale.
Per altre informazioni sul runtime Azure-SSIS, vedere gli articoli seguenti:
- Esercitazione: distribuire i pacchetti SSIS in Azure. Questo articolo fornisce istruzioni dettagliate per creare un runtime di integrazione SSIS di Azure e usa un database SQL di Azure per ospitare il catalogo SSIS.
- Procedura: come creare un runtime di integrazione SSIS di Azure. Questo articolo si espande sull'esercitazione e fornisce istruzioni sull'uso di Istanza gestita di SQL e sull'aggiunta del runtime di integrazione a una rete virtuale.
- Monitorare un runtime di integrazione SSIS di Azure. Questo articolo illustra come recuperare informazioni su un runtime di integrazione Azure-SSIS e fornisce descrizioni degli stati nelle informazioni restituite.
- Gestire un runtime di integrazione SSIS di Azure. In questo articolo viene illustrato come arrestare, avviare o rimuovere un runtime di integrazione SSIS di Azure. Viene inoltre mostrato come aumentare il numero di istanze per il runtime di integrazione SSIS di Azure aggiungendo più nodi al runtime di integrazione.
- Aggiungere il runtime di integrazione Azure-SSIS a una rete virtuale. Questo articolo offre informazioni concettuali sull'aggiunta di un runtime di integrazione Azure-SSIS a una rete virtuale di Azure. Fornisce anche la procedura per usare il portale di Azure per configurare una rete virtuale e aggiungere un runtime di integrazione Azure-SSIS.
Località del runtime di integrazione
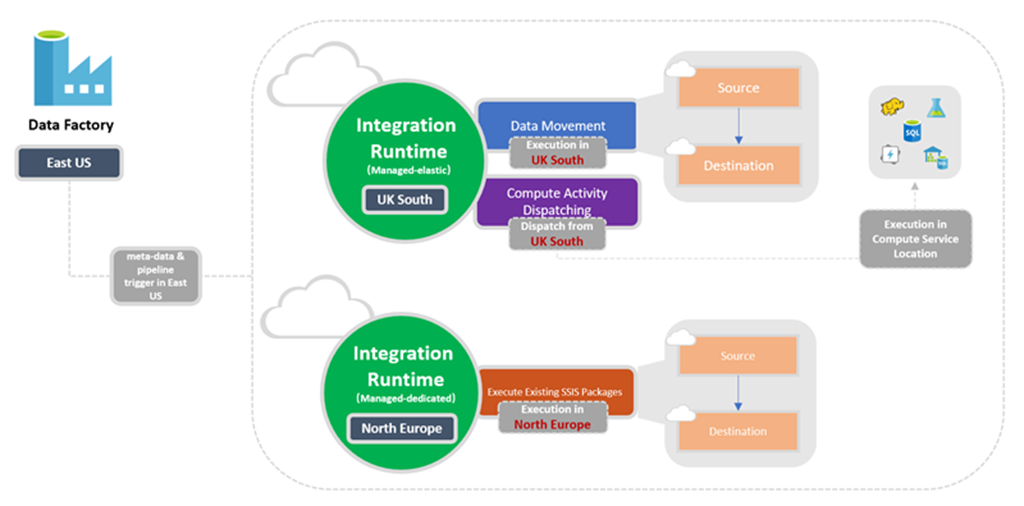
Relazione tra la posizione della factory e la posizione del runtime di integrazione
Quando si crea un'istanza di Data Factory o un'area di lavoro synapse, è necessario specificarne la posizione. I metadati per l'istanza vengono archiviati qui e l'attivazione della pipeline viene avviata da qui. I metadati vengono archiviati solo nell'area scelta e non verranno archiviati in altre aree.
Nel frattempo, una pipeline può accedere agli archivi dati e ai servizi di calcolo in altre aree di Azure per spostare i dati tra archivi dati o elaborare i dati usando i servizi di calcolo. Questo comportamento viene attuato tramite il runtime di integrazione disponibile a livello globale per garantire la conformità dei dati, l'efficienza e costi in uscita della rete inferiori.
La posizione del runtime di integrazione definisce la posizione del calcolo back-end e la posizione in cui vengono eseguiti lo spostamento dei dati, l'invio di attività e l'esecuzione del pacchetto SSIS. La posizione del runtime di integrazione può essere diversa dalla posizione della data factory a cui appartiene.
Località del runtime di integrazione di Azure
È possibile impostare l'area di posizione di un runtime di integrazione di Azure, nel qual caso l'esecuzione o l'invio dell'attività si verificherà nell'area selezionata.
L'impostazione predefinita consiste nel risolvere automaticamente il runtime di integrazione di Azure nella rete pubblica. Con questa opzione:
Per l'attività di copia, viene effettuato un tentativo ottimale per rilevare automaticamente la posizione dell'archivio dati sink, quindi usare il runtime di integrazione nella stessa area, se disponibile o quello più vicino nella stessa area geografica; in caso contrario, ; se l'area dell'archivio dati sink non è rilevabile, viene invece usato il runtime di integrazione nell'area dell'istanza.
Ad esempio, un'area di lavoro di Data Factory o Synapse è stata creata negli Stati Uniti orientali,
- Quando si copiano dati in un BLOB di Azure negli Stati Uniti occidentali, se viene rilevato che il BLOB si trova nell'area Stati Uniti occidentali, l'attività di copia viene eseguita nel runtime di integrazione negli Stati Uniti occidentali; se il rilevamento dell'area ha esito negativo, l'attività di copia viene eseguita nel runtime di integrazione negli Stati Uniti orientali.
- Quando si copiano dati in Salesforce, per cui l'area non è rilevabile, l'attività di copia viene eseguita nel runtime di integrazione negli Stati Uniti orientali.
Suggerimento
Se si hanno requisiti di conformità dei dati rigorosi e si deve assicurarsi che i dati non lascino una determinata area geografica, è possibile creare in modo esplicito un runtime di integrazione di Azure in una determinata area e puntare il servizio collegato a questo runtime di integrazione usando la proprietà Connessione Via. Ad esempio, se si vuole copiare dati da un BLOB nel Regno Unito meridionale a un'area di lavoro di Azure Synapse nel Regno Unito meridionale e si vuole assicurarsi che i dati non lascino il Regno Unito, creare un runtime di integrazione di Azure nel Regno Unito meridionale e collegare entrambi i servizi collegati a questo runtime di integrazione.
Per l'esecuzione dell'attività Lookup/GetMetadata/Delete (attività della pipeline), l'invio di attività di trasformazione (attività esterne) e le operazioni di creazione (connessione di test, esplorazione elenco cartelle ed elenco di tabelle e dati di anteprima), viene usato il runtime di integrazione nella stessa area dell'area di lavoro di Data Factory o Synapse.
Per Flusso di dati, viene usato il runtime di integrazione nell'area data factory o nell'area dell'area di lavoro di Synapse.
Suggerimento
Una procedura consigliata consiste nel garantire che i flussi di dati vengano eseguiti nella stessa area degli archivi dati corrispondenti, quando possibile. È possibile ottenere questo risultato con la risoluzione automatica per il runtime di integrazione di Azure (se la posizione dell'archivio dati è la stessa della posizione di Data Factory o dell'area di lavoro synapse) o creando una nuova istanza di Azure IR nella stessa area degli archivi dati e quindi eseguendo i flussi di dati su di esso.
Se si abilita l'Rete virtuale gestita con risoluzione automatica per il runtime di integrazione di Azure, viene usato il runtime di integrazione nell'area di lavoro di Data Factory o Synapse.
È possibile monitorare la posizione del runtime di integrazione durante l'esecuzione dell'attività nella visualizzazione di monitoraggio delle attività della pipeline in Data Factory Studio o Synapse Studio o nel payload di monitoraggio delle attività.
Località del runtime di integrazione self-hosted
Il runtime di integrazione self-hosted viene registrato logicamente nell'area di lavoro di Data Factory o Synapse e il calcolo usato per supportarne le funzionalità viene fornito dall'utente. Pertanto non esiste una proprietà location esplicita per il runtime di integrazione self-hosted.
Quando viene usato per eseguire lo spostamento di dati, il runtime di integrazione self-hosted estrae i dati dall'origine e li scrive nella destinazione.
Località del runtime di integrazione Azure-SSIS
Nota
I runtime di integrazione SSIS di Azure non sono attualmente supportati nelle pipeline di Synapse.
Selezionando la località corretta per il runtime di integrazione Azure-SSIS è fondamentale ottenere prestazioni elevate per ei flussi di lavoro di estrazione, trasformazione e caricamento (ETL).
- La posizione del runtime di integrazione Azure-SSIS non deve corrispondere alla posizione di Data Factory, ma deve corrispondere alla posizione del proprio database SQL di Azure o Istanza gestita di SQL in cui si trova SSISDB. In questo modo, il runtime di integrazione SSIS di Azure può accedere facilmente a SSISDB senza incorrere in un traffico eccessivo tra posizioni diverse.
- Se non si dispone di un database SQL o di un Istanza gestita di SQL esistente, ma si dispone di origini dati/destinazioni locali, è necessario creare una nuova database SQL di Azure o Istanza gestita di SQL nella stessa posizione di una rete virtuale connessa all'ambiente locale Rete. In questo modo, è possibile creare il runtime di integrazione Azure-SSIS usando il nuovo database SQL di Azure o Istanza gestita di SQL e aggiungere tale rete virtuale. Tutto si trova nella stessa posizione, riducendo al minimo lo spostamento dei dati e i costi associati, ottimizzando al contempo le prestazioni.
- Se il percorso del database SQL di Azure o dell'Istanza gestita di SQL esistente non corrisponde alla posizione di una rete virtuale connessa alla rete locale, creare prima di tutto il runtime di integrazione Azure-SSIS usando un database SQL di Azure esistente o Istanza gestita di SQL e aggiungere un'altra rete virtuale nella stessa posizione. Configurare quindi una rete virtuale per la connessione di rete virtuale tra le diverse posizioni.
Il diagramma seguente illustra le impostazioni di posizione per Data Factory e i relativi runtime di integrazione:
Determinazione del runtime di integrazione da usare
Se un'attività è associata a più tipi di runtime di integrazione, verrà risolta in uno di essi. Il runtime di integrazione self-hosted ha la precedenza sul runtime di integrazione di Azure nelle istanze di Azure Data Factory o di Synapse Workspace usando una rete virtuale gestita. Quest'ultimo ha la precedenza sul runtime di integrazione globale di Azure.
Ad esempio, un'attività di copia viene usata per copiare i dati dall'origine al sink. Il runtime di integrazione globale di Azure è associato al servizio collegato all'origine e a un runtime di integrazione di Azure in una rete virtuale gestita di Azure Data Factory associa al servizio collegato per il sink, quindi il risultato è che i servizi collegati di origine e sink usano il runtime di integrazione di Azure nella rete virtuale gestita di Azure Data Factory. Tuttavia, se un runtime di integrazione self-hosted associa il servizio collegato per l'origine, il servizio collegato di origine e sink usa il runtime di integrazione self-hosted.
Attività di copia
Il attività Copy richiede servizi collegati sia di origine che di sink per definire la direzione del flusso di dati. Per determinare l'istanza del runtime di integrazione usata per eseguire la copia, viene usata la logica seguente:
- Copia tra due origini dati cloud: se entrambi i servizi collegati di origine e sink usano Il runtime di integrazione di Azure, il runtime di integrazione di Azure a livello di area viene usato se è stato specificato o la posizione del runtime di integrazione di Azure viene determinata automaticamente se è stata scelta l'opzione runtime di risoluzione automatica (impostazione predefinita) come descritto nella sezione Percorso del runtime di integrazione.
- Copia tra un'origine dati cloud e un'origine dati in una rete privata: se il servizio collegato di origine o sink punta a un runtime di integrazione self-hosted, l'attività di copia viene eseguita nel runtime di integrazione self-hosted.
- La copia tra due origini dati in una rete privata: il servizio collegato di origine e sink deve puntare alla stessa istanza del runtime di integrazione e tale runtime di integrazione viene usato per eseguire l'attività di copia.
Attività Lookup e GetMetadata
L'attività Lookup e GetMetadata viene eseguita sul runtime di integrazione associato al servizio collegato dell'archivio dati.
Attività di trasformazione esterna
Ogni attività di trasformazione esterna che usa un motore di calcolo esterno dispone di un servizio collegato di calcolo di destinazione, che punta a un runtime di integrazione. Questa istanza del runtime di integrazione determina la posizione da cui viene inviata l'attività di trasformazione manuale esterna.
Attività flusso di dati
Flusso di dati le attività vengono eseguite nel runtime di integrazione di Azure associato. Le risorse di calcolo Spark usate dai Flusso di dati sono determinate dalle proprietà del flusso di dati nel runtime di integrazione di Azure e sono completamente gestite dal servizio.
Integration Runtime in CI/CD
I runtime di integrazione non cambiano spesso e sono simili in tutte le fasi di CI/CD. Data Factory richiede lo stesso nome e il tipo di runtime di integrazione in tutte le fasi di CI/CD. Se si vogliono condividere i runtime di integrazione in tutte le fasi, è consigliabile usare una factory dedicata solo per contenere i runtime di integrazione condivisa. È quindi possibile usare questa factory condivisa in tutti gli ambienti come tipo di runtime di integrazione collegato.
Contenuto correlato
Fai riferimento ai seguenti articoli:
- Creare il runtime di integrazione di Azure
- Creare il runtime di integrazione self-hosted
- Creare un runtime di integrazione SSIS di Azure. Questo articolo si espande sull'esercitazione e fornisce istruzioni sull'uso di Istanza gestita di SQL e sull'aggiunta del runtime di integrazione a una rete virtuale.