attività Flusso di dati in Azure Data Factory e Azure Synapse Analytics
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
Usare l'attività Flusso di dati per trasformare e spostare i dati tramite flussi di dati di mapping. Se non si ha familiarità con i flussi di dati, vedere Panoramica del mapping Flusso di dati
Creare un'attività Flusso di dati con l'interfaccia utente
Per usare un'attività Flusso di dati in una pipeline, completare la procedura seguente:
Cercare Flusso di dati nel riquadro Attività pipeline e trascinare un'attività Flusso di dati nell'area di disegno della pipeline.
Selezionare la nuova attività Flusso di dati nell'area di disegno se non è già selezionata e la relativa scheda Impostazioni per modificarne i dettagli.

La chiave del checkpoint viene usata per impostare il checkpoint quando viene usato il flusso di dati per l'acquisizione dei dati modificata. È possibile sovrascriverlo. Le attività del flusso di dati usano un valore GUID come chiave del checkpoint anziché "nome pipeline e nome attività" in modo che possa sempre tenere traccia dello stato change data capture del cliente anche se sono presenti azioni di ridenominazione. Tutte le attività del flusso di dati esistenti usano la chiave del modello precedente per garantire la compatibilità con le versioni precedenti. L'opzione Chiave del checkpoint dopo la pubblicazione di una nuova attività del flusso di dati con la risorsa flusso di dati abilitata per Change Data Capture è illustrata di seguito.
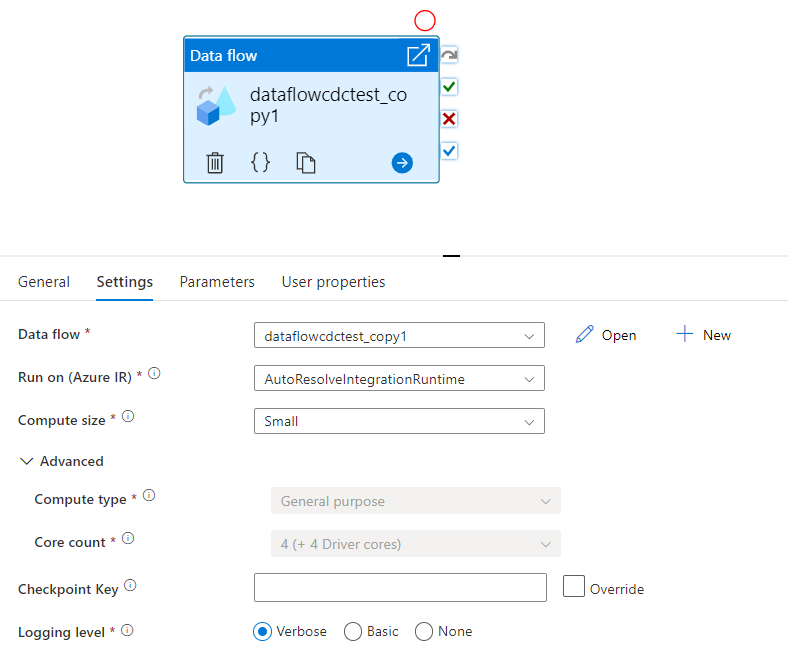
Selezionare un flusso di dati esistente o crearne uno nuovo usando il pulsante Nuovo. Selezionare altre opzioni necessarie per completare la configurazione.
Sintassi
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
Proprietà del tipo
| Proprietà | Descrizione | Valori consentiti | Richiesto |
|---|---|---|---|
| dataflow | Riferimento al Flusso di dati in esecuzione | DataFlowReference | Sì |
| integrationRuntime | L'ambiente di calcolo in cui viene eseguito il flusso di dati. Se non specificato, viene usato il runtime di integrazione di Azure autoresolve. | IntegrationRuntimeReference | No |
| compute.coreCount | Numero di core usati nel cluster Spark. Può essere specificato solo se viene usato il runtime di integrazione di Azure autoresolve | 8, 16, 32, 48, 80, 144, 272 | No |
| compute.computeType | Tipo di calcolo usato nel cluster Spark. Può essere specificato solo se viene usato il runtime di integrazione di Azure autoresolve | "Generale" | No |
| staging.linkedService | Se si usa un'origine o un sink di Azure Synapse Analytics, specificare l'account di archiviazione usato per la gestione temporanea di PolyBase. Se il Archiviazione di Azure è configurato con l'endpoint del servizio di rete virtuale, è necessario usare l'autenticazione dell'identità gestita con "consenti il servizio Microsoft attendibile" abilitato nell'account di archiviazione, vedere Impatto sull'uso degli endpoint servizio di rete virtuale con Archiviazione di Azure. Informazioni sulle configurazioni necessarie rispettivamente per BLOB di Azure e Azure Data Lake Archiviazione Gen2. |
LinkedServiceReference | Solo se il flusso di dati legge o scrive in Azure Synapse Analytics |
| staging.folderPath | Se si usa un'origine o un sink di Azure Synapse Analytics, il percorso della cartella nell'account di archiviazione BLOB usato per la gestione temporanea di PolyBase | String | Solo se il flusso di dati legge o scrive in Azure Synapse Analytics |
| Tracelevel | Impostare il livello di registrazione dell'esecuzione dell'attività del flusso di dati | Fine, Grossolano, Nessuno | No |
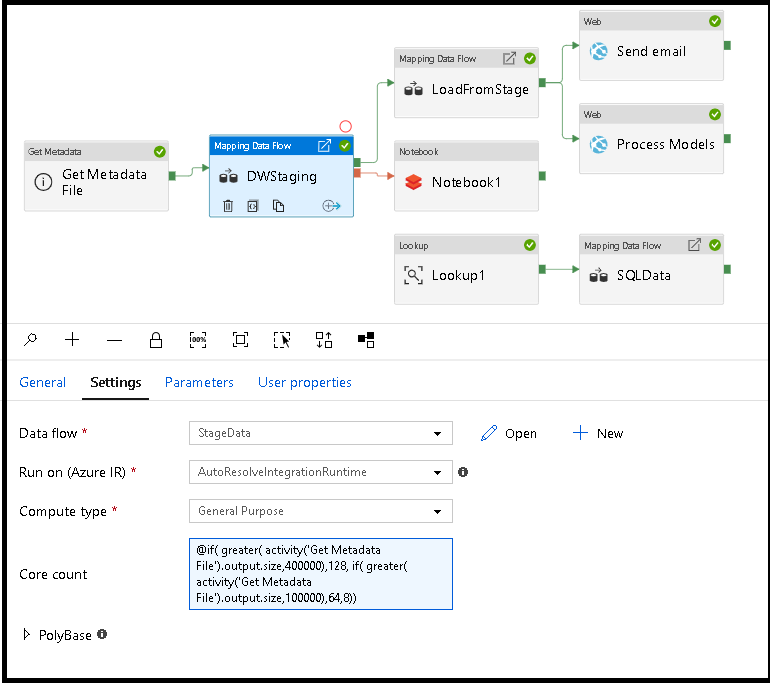
Ridimensionare dinamicamente il calcolo del flusso di dati in fase di esecuzione
Le proprietà Core Count e Compute Type possono essere impostate in modo dinamico per adattarsi alle dimensioni dei dati di origine in ingresso in fase di esecuzione. Usare attività della pipeline come Ricerca o Recupera metadati per trovare le dimensioni dei dati del set di dati di origine. Usare quindi Aggiungi contenuto dinamico nelle proprietà dell'attività Flusso di dati. È possibile scegliere dimensioni di calcolo piccole, medie o grandi. Facoltativamente, selezionare "Personalizzato" e configurare manualmente i tipi di calcolo e il numero di core.
Ecco una breve esercitazione video che illustra questa tecnica
Flusso di dati runtime di integrazione
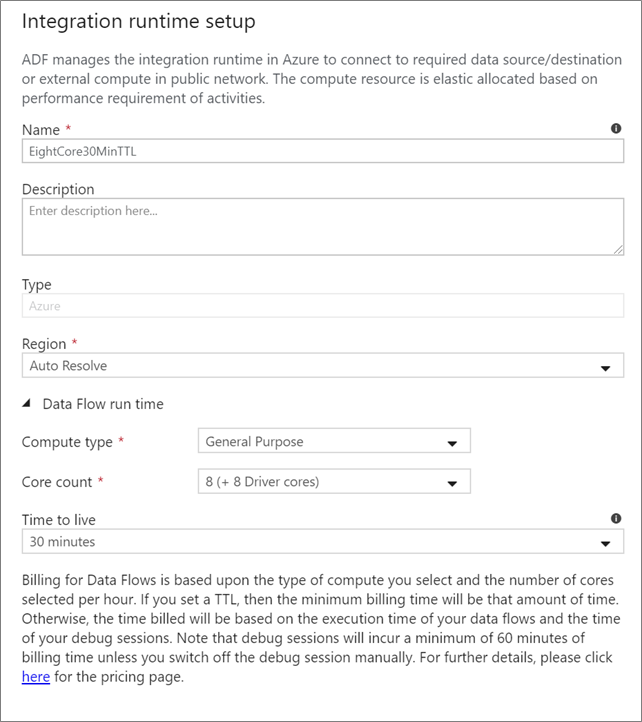
Scegliere il runtime di integrazione da usare per l'esecuzione dell'attività Flusso di dati. Per impostazione predefinita, il servizio usa il runtime di integrazione automatica di Azure con quattro core di lavoro. Questo runtime di integrazione ha un tipo di calcolo per utilizzo generico e viene eseguito nella stessa area dell'istanza del servizio. Per le pipeline operative, è consigliabile creare runtime di integrazione di Azure personalizzati che definiscono aree specifiche, tipo di calcolo, numero di core e TTL per l'esecuzione dell'attività del flusso di dati.
Un tipo di calcolo minimo per utilizzo generico con una configurazione di 8+8 (16 v-core totali) e una durata (TTL) di 10 minuti è la raccomandazione minima per la maggior parte dei carichi di lavoro di produzione. Impostando una durata (TTL) di piccole dimensioni, il runtime di integrazione di Azure può gestire un cluster ad accesso frequente che non comporta diversi minuti di ora di inizio per un cluster a freddo. Per altre informazioni, vedere Runtime di integrazione di Azure.
Importante
La selezione del runtime di integrazione nell'attività Flusso di dati si applica solo alle esecuzioni attivate della pipeline. Il debug della pipeline con i flussi di dati viene eseguito nel cluster specificato nella sessione di debug.
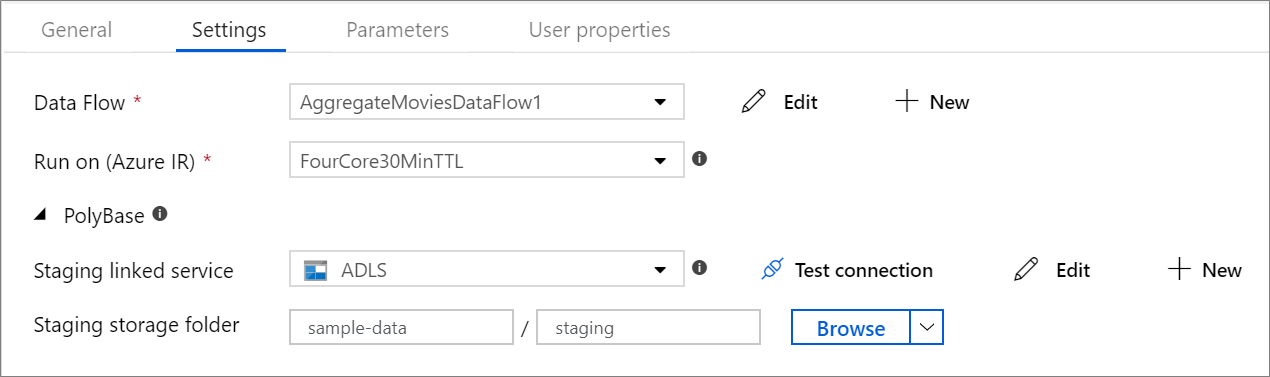
PolyBase
Se si usa Azure Synapse Analytics come sink o origine, è necessario scegliere un percorso di gestione temporanea per il caricamento batch polyBase. PolyBase consente il caricamento in blocco in blocco invece di caricare la riga di dati per riga. PolyBase riduce drasticamente il tempo di caricamento in Azure Synapse Analytics.
Chiave del checkpoint
Quando si usa l'opzione Change Capture per le origini del flusso di dati, Azure Data Factory gestisce e gestisce automaticamente il checkpoint. La chiave del checkpoint predefinita è un hash del nome del flusso di dati e del nome della pipeline. Se si usa un modello dinamico per le tabelle o le cartelle di origine, è possibile eseguire l'override di questo hash e impostare qui il proprio valore della chiave di checkpoint.
Livello di registrazione
Se non è necessaria ogni esecuzione della pipeline delle attività del flusso di dati per registrare completamente tutti i log di telemetria dettagliati, facoltativamente è possibile impostare il livello di registrazione su "Basic" o "Nessuno". Quando si eseguono i flussi di dati in modalità "Dettagliato" (impostazione predefinita), si richiede al servizio di registrare completamente l'attività a ogni singolo livello di partizione durante la trasformazione dei dati. Può trattarsi di un'operazione costosa, quindi l'abilitazione dettagliata solo quando la risoluzione dei problemi può migliorare il flusso di dati complessivo e le prestazioni della pipeline. La modalità "Basic" registra solo le durate della trasformazione mentre "Nessuno" fornisce solo un riepilogo delle durate.

Proprietà sink
La funzionalità di raggruppamento nei flussi di dati consente di impostare l'ordine di esecuzione dei sink e di raggruppare i sink usando lo stesso numero di gruppo. Per gestire i gruppi, è possibile chiedere al servizio di eseguire sink, nello stesso gruppo, in parallelo. È anche possibile impostare il gruppo di sink per continuare anche dopo che uno dei sink rileva un errore.
Il comportamento predefinito dei sink del flusso di dati consiste nell'eseguire ogni sink in modo sequenziale, in modo seriale e per interrompere il flusso di dati quando si verifica un errore nel sink. Inoltre, per impostazione predefinita, tutti i sink vengono impostati sullo stesso gruppo, a meno che non si entrino nelle proprietà del flusso di dati e si impostino priorità diverse per i sink.

Solo prima riga
Questa opzione è disponibile solo per i flussi di dati con sink della cache abilitati per "Output to activity". L'output del flusso di dati inserito direttamente nella pipeline è limitato a 2 MB. L'impostazione di "first row only" consente di limitare l'output dei dati dal flusso di dati quando si inserisce l'output dell'attività del flusso di dati direttamente nella pipeline.
Parametrizzazione di Flusso di dati
Set di dati con parametri
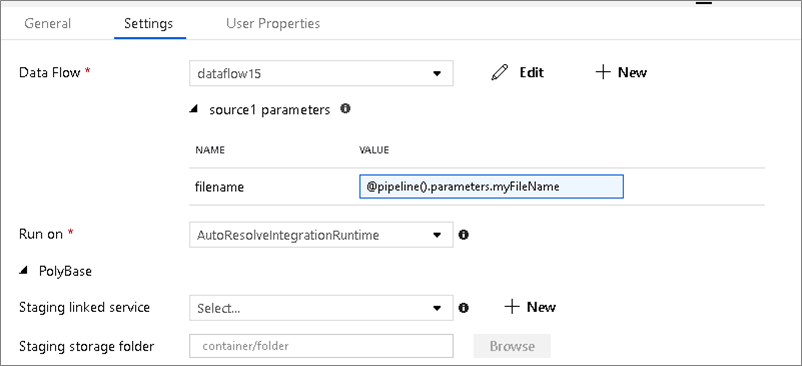
Se il flusso di dati usa set di dati con parametri, impostare i valori dei parametri nella scheda Impostazioni.
Flussi di dati con parametri
Se il flusso di dati è con parametri, impostare i valori dinamici dei parametri del flusso di dati nella scheda Parametri . È possibile usare il linguaggio delle espressioni della pipeline o il linguaggio delle espressioni del flusso di dati per assegnare valori di parametro dinamici o letterali. Per altre informazioni, vedere parametri Flusso di dati.
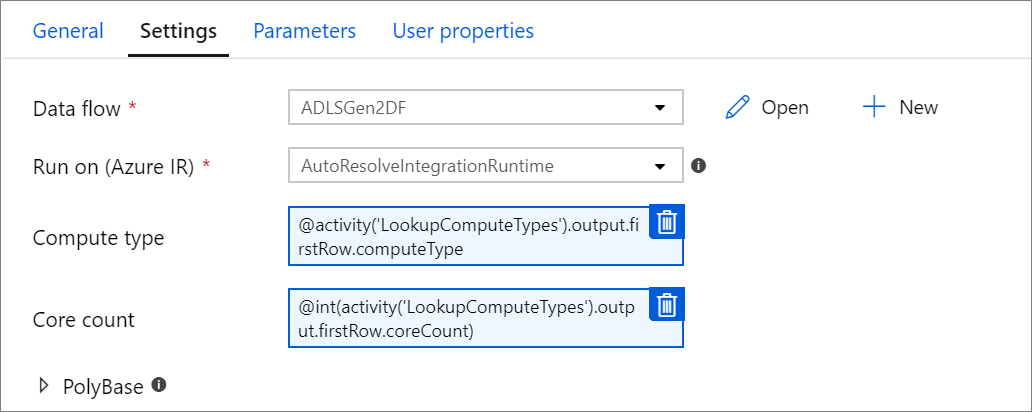
Proprietà di calcolo con parametri.
È possibile parametrizzare il numero di core o il tipo di calcolo se si usa il runtime di integrazione di Azure autoresolve e si specificano i valori per compute.coreCount e compute.computeType.
Debug della pipeline dell'attività Flusso di dati
Per eseguire un'esecuzione della pipeline di debug con un'attività Flusso di dati, è necessario attivare la modalità di debug del flusso di dati tramite il dispositivo di scorrimento Flusso di dati Debug sulla barra superiore. La modalità di debug consente di eseguire il flusso di dati su un cluster Spark attivo. Per altre informazioni, vedere Modalità di debug.

La pipeline di debug viene eseguita nel cluster di debug attivo, non nell'ambiente di runtime di integrazione specificato nelle impostazioni dell'attività Flusso di dati. È possibile scegliere l'ambiente di calcolo di debug quando si avvia la modalità di debug.
Monitoraggio dell'attività di Flusso di dati
L'attività Flusso di dati offre un'esperienza di monitoraggio speciale in cui è possibile visualizzare le informazioni di partizionamento, fase e derivazione dei dati. Aprire il riquadro di monitoraggio tramite l'icona degli occhiali in Azioni. Per altre informazioni, vedere Monitoraggio delle Flusso di dati.
Usare Flusso di dati risultati dell'attività in un'attività successiva
L'attività flusso di dati restituisce metriche relative al numero di righe scritte in ogni sink e righe lette da ogni origine. Questi risultati vengono restituiti nella output sezione del risultato dell'esecuzione dell'attività. Le metriche restituite sono nel formato del codice JSON seguente.
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
Ad esempio, per ottenere il numero di righe scritte in un sink denominato "sink1" in un'attività denominata "dataflowActivity", usare @activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten.
Per ottenere il numero di righe lette da un'origine denominata 'source1' usata in tale sink, usare @activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead.
Nota
Se un sink ha zero righe scritte, non verrà visualizzato nelle metriche. L'esistenza può essere verificata usando la contains funzione . Ad esempio, contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1') controlla se le righe sono state scritte in sink1.
Contenuto correlato
Vedere le attività supportate del flusso di controllo: