Guida a prestazioni e scalabilità dell'attività di copia
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
A volte si vuole eseguire una migrazione di dati su larga scala da Data Lake o Enterprise Data Warehouse (EDW) ad Azure. Altre volte si vogliono inserire grandi quantità di dati, da origini diverse in Azure, per l'analisi dei Big Data. In ogni caso, è fondamentale ottenere prestazioni e scalabilità ottimali.
Le pipeline di Azure Data Factory e Azure Synapse Analytics offrono un meccanismo per inserire i dati, con i vantaggi seguenti:
- Gestisce grandi quantità di dati
- Prestazioni elevate
- È conveniente
Questi vantaggi sono un'ottima soluzione per i data engineer che vogliono creare pipeline di inserimento dati scalabili con prestazioni elevate.
Dopo la lettura di questo articolo, si potrà rispondere alle domande seguenti:
- Quale livello di prestazioni e scalabilità è possibile ottenere usando l'attività di copia per scenari di migrazione dei dati e inserimento dati?
- Quali passaggi è necessario eseguire per ottimizzare le prestazioni dell'attività di copia?
- Quali ottimizzazioni delle prestazioni è possibile usare per una singola esecuzione dell'attività di copia?
- Quali altri fattori esterni considerare quando si ottimizzano le prestazioni di copia?
Nota
Se non si ha familiarità con l'attività di copia in generale, vedere la panoramica dell'attività di copia prima di leggere questo articolo.
Copiare prestazioni e scalabilità ottenibili usando azure Data Factory e le pipeline synapse
Le pipeline di Azure Data Factory e Synapse offrono un'architettura serverless che consente il parallelismo a livelli diversi.
Questa architettura consente di sviluppare pipeline che ottimizzano la velocità effettiva di spostamento dei dati per l'ambiente in uso. Queste pipeline usano completamente le risorse seguenti:
- Larghezza di banda di rete tra gli archivi dati di origine e di destinazione
- Operazioni di input/output dell'archivio dati di origine o di destinazione al secondo (IOPS) e larghezza di banda
Questo utilizzo completo consente di stimare la velocità effettiva complessiva misurando la velocità effettiva minima disponibile con le risorse seguenti:
- Archivio dati di origine
- Archivio dati di destinazione
- Larghezza di banda di rete tra gli archivi dati di origine e di destinazione
La tabella seguente illustra il calcolo della durata dello spostamento dei dati. La durata in ogni cella viene calcolata in base a una determinata larghezza di banda di rete e archivio dati e a una determinata dimensione del payload dei dati.
Nota
La durata riportata di seguito è destinata a rappresentare prestazioni ottenibili in una soluzione di integrazione dei dati end-to-end usando una o più tecniche di ottimizzazione delle prestazioni descritte in Funzionalità di ottimizzazione delle prestazioni di copia, incluso l'uso di ForEach per partizionare e generare più attività di copia simultanee. È consigliabile seguire i passaggi descritti in Procedura di ottimizzazione delle prestazioni per ottimizzare le prestazioni di copia per il set di dati e la configurazione di sistema specifici. È consigliabile usare i numeri ottenuti nei test di ottimizzazione delle prestazioni per la pianificazione della distribuzione di produzione, la pianificazione della capacità e la proiezione di fatturazione.
| Dimensioni dei dati/ bandwidth |
50 Mbps | 100 Mbps | 500 Mbps | 1 Gbps | 5 Gbps | 10 Gbps | 50 Gbps |
|---|---|---|---|---|---|---|---|
| 1 GB | 2,7 minuti | 1,4 minuti | 0,3 minuti | 0,1 min | 0,03 minuti | 0,01 min | 0,0 min |
| 10 GB | 27,3 minuti | 13,7 minuti | 2,7 minuti | 1,3 minuti | 0,3 minuti | 0,1 min | 0,03 minuti |
| 100 GB | 4,6 ore | 2,3 ore | 0,5 ore | 0,2 ore | 0,05 ore | 0,02 ore | 0,0 ore |
| 1 TB | 46,6 ore | 23,3 ore | 4,7 ore | 2,3 ore | 0,5 ore | 0,2 ore | 0,05 ore |
| 10 TB | 19,4 giorni | 9,7 giorni | 1,9 giorni | 0,9 giorni | 0,2 giorni | 0,1 giorni | 0,02 giorni |
| 100 TB | 194,2 giorni | 97,1 giorni | 19,4 giorni | 9,7 giorni | 1,9 giorni | 1 giorno | 0,2 giorni |
| 1 PB | 64,7 mo | 32.4 mo | 6,5 mo | 3.2 mo | 0,6 mo | 0,3 mo | 0,06 mo |
| 10 PB | 647,3 mo | 323.6 mo | 64,7 mo | 31,6 mo | 6,5 mo | 3.2 mo | 0,6 mo |
La copia è scalabile a livelli diversi:
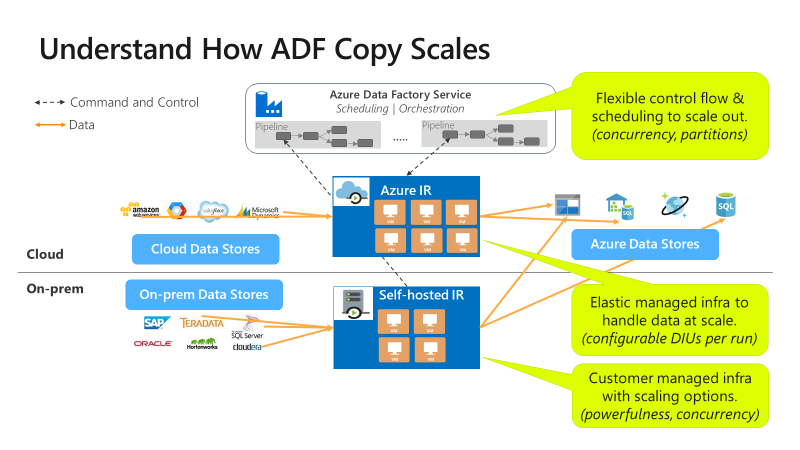
Il flusso di controllo può avviare più attività di copia in parallelo, ad esempio usando il ciclo For Each.
Una singola attività di copia può sfruttare le risorse di calcolo scalabili.
- Quando si usa il runtime di integrazione di Azure, è possibile specificare fino a 256 unità di integrazione dati (DIU) per ogni attività di copia, in modo serverless.
- Quando si usa il runtime di integrazione self-hosted, è possibile adottare uno degli approcci seguenti:
- Aumentare manualmente le prestazioni del computer.
- Aumentare il numero di istanze in più computer (fino a 4 nodi) e una singola attività di copia partizionerà il relativo set di file in tutti i nodi.
Una singola attività di copia legge e scrive nell'archivio dati usando più thread in parallelo.
Procedura di ottimizzazione delle prestazioni
Per ottimizzare le prestazioni del servizio con l'attività di copia, seguire questa procedura:
Selezionare un set di dati di test e stabilire una linea di base.
Durante lo sviluppo, testare la pipeline usando l'attività di copia su un esempio di dati rappresentativo. Il set di dati scelto deve rappresentare i modelli di dati tipici lungo gli attributi seguenti:
- Struttura delle cartelle
- Modello di file
- Schema dati
Il set di dati deve essere sufficientemente grande da valutare le prestazioni di copia. Il completamento dell'attività di copia richiede almeno 10 minuti. Raccogliere i dettagli di esecuzione e le caratteristiche delle prestazioni seguendo il monitoraggio dell'attività di copia.
Come ottimizzare le prestazioni di una singola attività di copia:
È consigliabile ottimizzare prima di tutto le prestazioni usando una singola attività di copia.
Se l'attività di copia viene eseguita in un runtime di integrazione di Azure :
Iniziare con i valori predefiniti per le unità di Integrazione dei dati (DIU) e le impostazioni di copia parallela.
Se l'attività di copia viene eseguita in un runtime di integrazione self-hosted :
È consigliabile usare un computer dedicato per ospitare il runtime di integrazione. Il computer deve essere separato dal server in cui è ospitato l'archivio dati. Iniziare con i valori predefiniti per l'impostazione di copia parallela e usando un singolo nodo per il runtime di integrazione self-hosted.
Eseguire un'esecuzione di test delle prestazioni. Prendere nota delle prestazioni ottenute. Includere i valori effettivi usati, ad esempio le DIU e le copie parallele. Fare riferimento al monitoraggio delle attività di copia su come raccogliere i risultati di esecuzione e le impostazioni delle prestazioni usate. Informazioni su come risolvere i problemi relativi alle prestazioni dell'attività di copia per identificare e risolvere il collo di bottiglia.
Eseguire l'iterazione per eseguire test aggiuntivi sulle prestazioni seguendo le indicazioni per la risoluzione dei problemi e l'ottimizzazione. Una volta che l'esecuzione di un'attività di copia singola non riesce a ottenere una velocità effettiva migliore, valutare se ottimizzare la velocità effettiva aggregata eseguendo più copie contemporaneamente. Questa opzione viene illustrata nel punto elenco numerato successivo.
Come ottimizzare la velocità effettiva aggregata eseguendo più copie contemporaneamente:
A questo livello sono state ottimizzate le prestazioni di una singola attività di copia. Se non è ancora stato raggiunto il limite massimo di velocità effettiva dell'ambiente, è possibile eseguire più attività di copia in parallelo. È possibile eseguire in parallelo usando costrutti del flusso di controllo. Un costrutto di questo tipo è il ciclo For Each. Per altre informazioni, vedere gli articoli seguenti sui modelli di soluzione:
Espandere la configurazione per l'intero set di dati.
Quando si è soddisfatti dei risultati e delle prestazioni dell'esecuzione, è possibile espandere la definizione e la pipeline per coprire l'intero set di dati.
Risolvere i problemi relativi alle prestazioni dell'attività di copia
Seguire i passaggi di ottimizzazione delle prestazioni per pianificare ed eseguire test delle prestazioni per lo scenario. Informazioni su come risolvere i problemi di prestazioni di ogni esecuzione dell'attività di copia da Risolvere i problemi relativi alle prestazioni dell'attività di copia.
Funzionalità di ottimizzazione delle prestazioni di copia
Il servizio offre le funzionalità di ottimizzazione delle prestazioni seguenti:
- Unità di integrazione dati
- Scalabilità del runtime di integrazione self-hosted
- Copia parallela
- Copia di staging
Unità di integrazione dati
Un'unità di Integrazione dei dati (DIU) è una misura che rappresenta la potenza di una singola unità nelle pipeline di Azure Data Factory e Synapse. La potenza è una combinazione di CPU, memoria e allocazione delle risorse di rete. DiU si applica solo al runtime di integrazione di Azure. DIU non si applica al runtime di integrazione self-hosted. Fare clic qui per altre informazioni.
Scalabilità del runtime di integrazione self-hosted
Può essere necessario ospitare un carico di lavoro simultaneo crescente oppure ottenere prestazioni più elevate per il livello attuale del carico di lavoro. È possibile migliorare la scalabilità dell'elaborazione in base agli approcci seguenti:
- È possibile aumentare le prestazioni del runtime di integrazione self-hosted aumentando il numero di processi simultanei che possono essere eseguiti in un nodo.
La scalabilità orizzontale funziona solo se il processore e la memoria del nodo sono meno che completamente utilizzati. - È possibile aumentare il numero di istanze del runtime di integrazione self-hosted aggiungendo altri nodi (computer).
Per altre informazioni, vedere:
- attività Copy funzionalità di ottimizzazione delle prestazioni: scalabilità del runtime di integrazione self-hosted
- Creare e configurare un runtime di integrazione self-hosted: Considerazioni sulla scalabilità
Copia parallela
È possibile impostare la parallelCopies proprietà per indicare il parallelismo che si desidera utilizzare l'attività di copia. Si consideri questa proprietà come il numero massimo di thread all'interno dell'attività di copia. I thread operano in parallelo. I thread leggono dall'origine o scrivono negli archivi dati sink. Ulteriori informazioni.
copia di staging
Un'operazione di copia dei dati può inviare i dati direttamente all'archivio dati sink. In alternativa, è possibile scegliere di usare l'archiviazione BLOB come archivio di staging provvisorio. Ulteriori informazioni.
Contenuto correlato
Vedere gli altri articoli relativi all'attività di copia:
- Panoramica dell'attività di copia
- Risolvere i problemi relativi alle prestazioni dell'attività di copia
- attività Copy funzionalità di ottimizzazione delle prestazioni
- Usare Azure Data Factory per eseguire la migrazione dei dati dal data lake o dal data warehouse ad Azure
- Eseguire la migrazione dei dati da Amazon S3 a Archiviazione di Azure