Integrazione dei dati con Azure Data Factory e Condivisione dati di Azure
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
I clienti che si imbarcano in progetti di data warehouse moderno e di analisi hanno bisogno non solo di più dati ma anche di una maggiore visibilità sugli stessi. Questo workshop illustra come semplificare l'integrazione e la gestione dei dati in Azure con i miglioramenti apportati ad Azure Data Factory e a Condivisione dati di Azure.
Dall'abilitazione di ETL/ELT senza codice alla creazione di una visualizzazione completa dei dati, miglioramenti in Azure Data Factory consentono ai data engineer di introdurre in modo sicuro più dati e quindi più valore per l'azienda. Azure Condivisione dati consente di svolgere attività aziendali per la condivisione aziendale in modo regolamentato.
In questo workshop si userà Azure Data Factory (ADF) per inserire i dati dal database SQL di Azure in Azure Data Lake Storage Gen2 (ADLS Gen2). Una volta inseriti nel data lake, i dati verranno trasformati tramite flussi di dati per mapping, il servizio di trasformazione nativo della data factory, e acquisiti tramite sink in Azure Synapse Analytics. Quindi, la tabella con i dati trasformati, insieme ad alcuni dati aggiuntivi, verrà condivisa tramite Condivisione dati di Azure.
I dati usati in questo lab sono relativi ai taxi di New York. Per importarli nel database del database SQL di Azure, scaricare il file bacpac taxi-data. Selezionare l'opzione Scarica file non elaborato in GitHub.
Prerequisiti
Sottoscrizione di Azure: se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
database SQL di Azure: se non si ha un database SQL di Azure, vedere come creare un database SQL.
Account di archiviazione di Azure Data Lake Archiviazione Gen2: se non si ha un account di archiviazione ADLS Gen2, informazioni su come creare un account di archiviazione ADLS Gen2.
Azure Synapse Analytics: se non si ha un'area di lavoro di Azure Synapse Analytics, vedere come iniziare a usare Azure Synapse Analytics.
Azure Data Factory: se non è stata creata una data factory, vedere come creare una data factory.
Azure Condivisione dati: se non è stata creata una condivisione dati, vedere come creare una condivisione dati.
Configurare l'ambiente di Azure Data Factory
In questa sezione viene illustrato come accedere all'esperienza utente di Azure Data Factory dall'portale di Azure. Una volta nell'esperienza utente di Azure Data Factory, si configureranno tre servizi collegati per ognuno degli archivi dati in uso: database SQL di Azure, ADLS Gen2 e Azure Synapse Analytics.
Nei servizi collegati di Azure Data Factory definire le informazioni di connessione alle risorse esterne. Azure Data Factory attualmente supporta 85 connettori.
Aprire l'esperienza utente di Azure Data Factory
Aprire il portale di Azure in Microsoft Edge o Google Chrome.
Usando la barra di ricerca nella parte superiore della pagina, cercare "Data Factory".
Selezionare la risorsa data factory per aprire le relative risorse nel riquadro a sinistra.
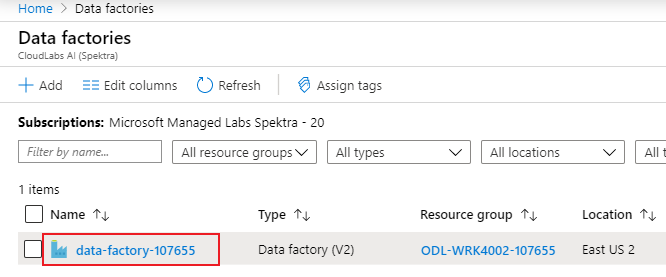
Selezionare Apri Azure Data Factory Studio. È anche possibile accedere a Data Factory Studio direttamente in adf.azure.com.
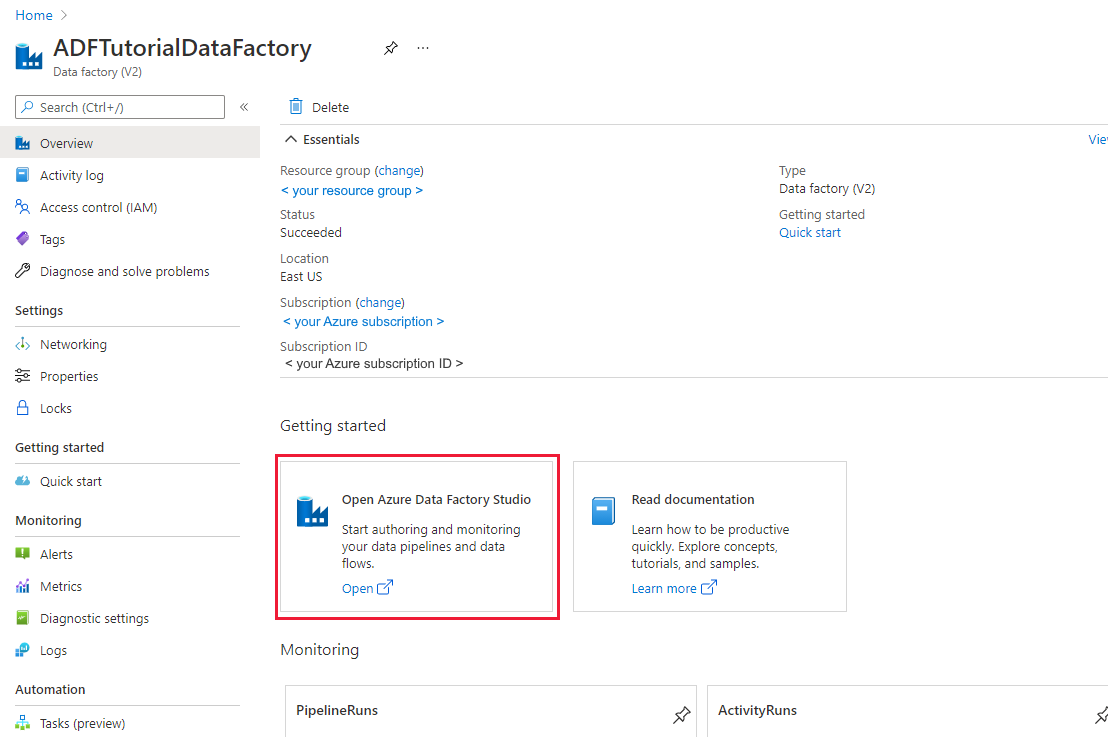
Si viene reindirizzati alla home page di Azure Data Factory nel portale di Azure. Questa pagina contiene argomenti di avvio rapido, video di istruzioni e collegamenti a esercitazioni sui concetti di data factory. Per iniziare la creazione, selezionare l'icona a forma di matita sulla barra laterale sinistra.



Creare un servizio collegato Database SQL di Azure
Per creare un servizio collegato, selezionare Gestisci hub nella barra laterale sinistra, nel riquadro Connessione ions selezionare Servizi collegati e quindi Selezionare Nuovo per aggiungere un nuovo servizio collegato.

Il primo servizio collegato configurato è un database SQL di Azure. È possibile usare la barra di ricerca per filtrare l'elenco di archivi dati. Selezionare il riquadro database SQL di Azure e selezionare Continua.

Nel riquadro di configurazione database SQL immettere "SQLDB" come nome del servizio collegato. Immettere le proprie credenziali per consentire alla data factory di connettersi al database. Se si usa l'autenticazione SQL, immettere il nome del server, il database, il nome utente e la password. È possibile verificare che le informazioni di connessione siano corrette selezionando Test connessione. Selezionare Create (Crea) al termine.


Creare un servizio collegato Azure Synapse Analytics
Ripetere la stessa procedura per aggiungere un servizio collegato Azure Synapse Analytics. Nella scheda Connessioni selezionare Nuovo. Selezionare il riquadro Azure Synapse Analytics e selezionare Continua.
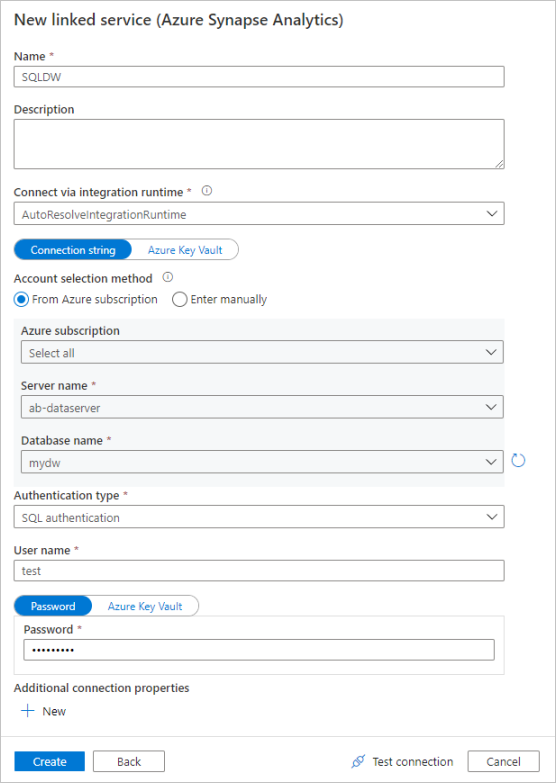
Nel riquadro di configurazione del servizio collegato immettere "SQLDW" come nome del servizio collegato. Immettere le proprie credenziali per consentire alla data factory di connettersi al database. Se si usa l'autenticazione SQL, immettere il nome del server, il database, il nome utente e la password. È possibile verificare che le informazioni di connessione siano corrette selezionando Test connessione. Selezionare Create (Crea) al termine.
Creare un servizio collegato Azure Data Lake Storage Gen2
L'ultimo servizio collegato necessario per questo lab è azure Data Lake Archiviazione Gen2. Nella scheda Connessioni selezionare Nuovo. Selezionare il riquadro Azure Data Lake Archiviazione Gen2 e selezionare Continua.
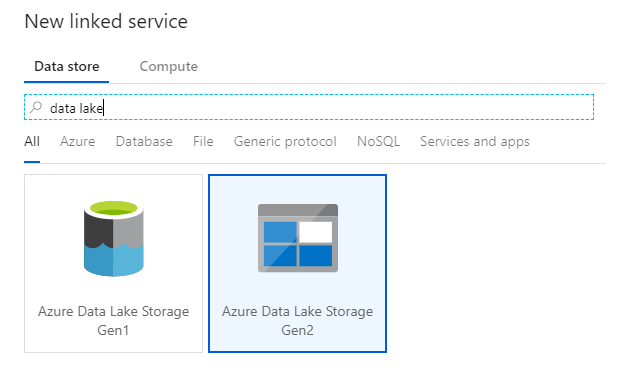
Nel riquadro di configurazione del servizio collegato immettere 'ADLSGen2' come nome. Se si usa l'autenticazione della chiave dell'account, selezionare l'account di archiviazione ADLS Gen2 dall'elenco a discesa nome account Archiviazione. È possibile verificare che le informazioni di connessione siano corrette selezionando Test connessione. Selezionare Create (Crea) al termine.
Attivare la modalità di debug dei flussi di dati
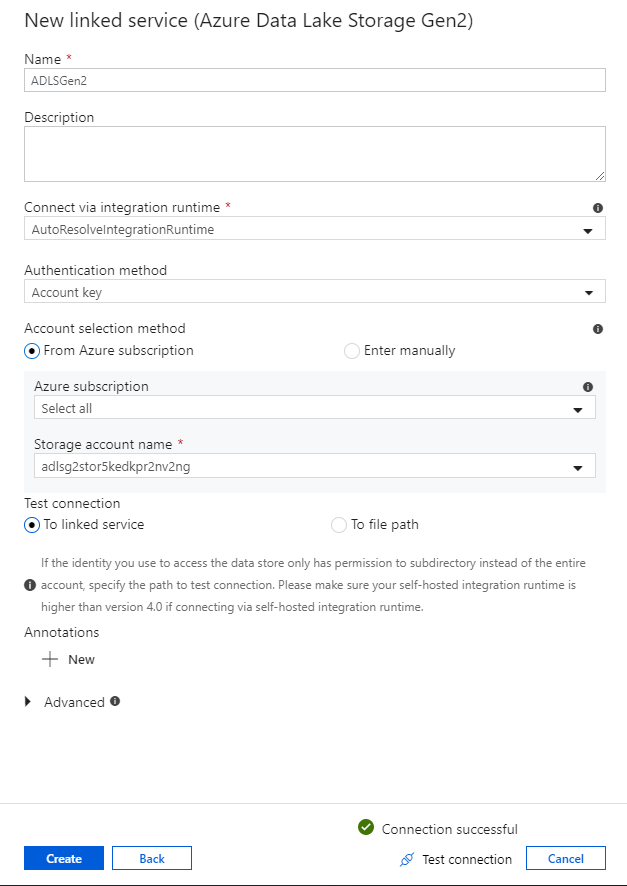
Nella sezione Trasformare i dati usando il flusso di dati di mapping si creano flussi di dati di mapping. Prima di creare flussi di dati per mapping, la procedura consigliata consiste nell'attivare la modalità di debug, che consente di testare la logica di trasformazione in pochi secondi su un cluster Spark attivo.
Per attivare il debug, selezionare il dispositivo di scorrimento Debug flusso di dati nella barra superiore dell'area di disegno del flusso di dati o nell'area di disegno della pipeline quando si dispone di attività flusso di dati. Selezionare OK quando viene visualizzata la finestra di dialogo di conferma. Il cluster viene avviato in circa 5-7 minuti. Continuare con l'inserimento dei dati da database SQL di Azure in ADLS Gen2 usando l'attività di copia durante l'inizializzazione.

Inserire i dati usando l'attività di copia
In questa sezione viene creata una pipeline con un'attività di copia che inserisce una tabella da un database SQL di Azure in un account di archiviazione ADLS Gen2. Si apprenderà come aggiungere una pipeline, configurare un set di dati ed eseguire il debug di una pipeline tramite l'esperienza utente di Azure Data Factory. Il modello di configurazione di questa esercitazione può essere applicato alla copia da un archivio dati relazionale a un archivio dati basato su file.
In Azure Data Factory una pipeline è un raggruppamento logico di attività che insieme eseguono un'azione. L'attività definisce un'operazione da eseguire sui dati. Il set di dati punta ai dati da usare in un servizio collegato.
Creare una pipeline con un'attività di copia
Nel riquadro delle risorse factory selezionare l'icona con il segno più per aprire il menu nuova risorsa. Selezionare Pipeline.

Nella scheda Generale del canvas assegnare alla pipeline un nome descrittivo, ad esempio 'IngestAndTransformTaxiData'.

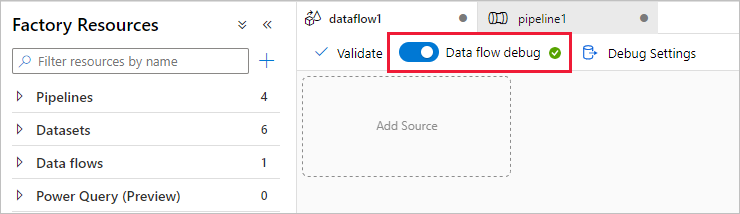
Nel riquadro attività del canvas della pipeline aprire il menu Move and Transform (Sposta e trasforma) e trascinare l'attività Copy data (Copia dati) nel canvas. Assegnare all'attività di copia un nome descrittivo, ad esempio 'IngestIntoADLS'.



Configurare il set di dati di origine del database SQL di Azure
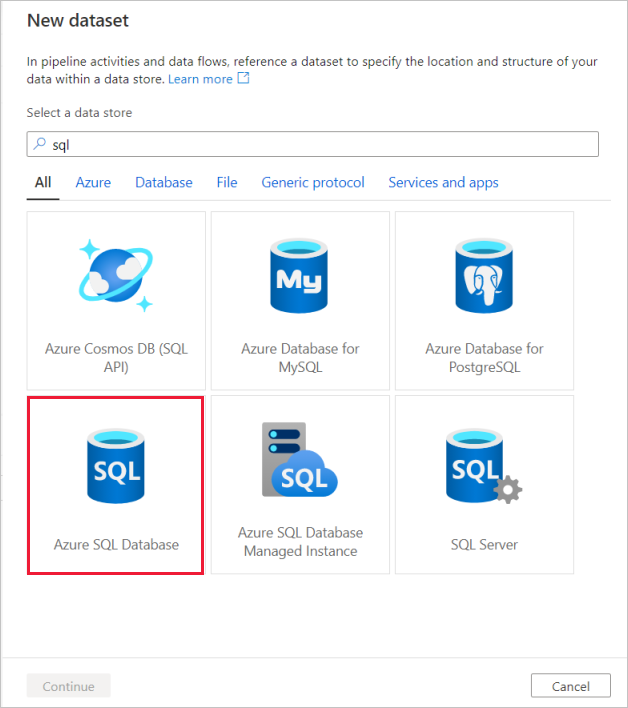
Selezionare la scheda Origine dell'attività di copia. Per creare un nuovo set di dati, selezionare Nuovo. L'origine sarà la tabella
dbo.TripDatache si trova nel servizio collegato 'SQLDB' configurato in precedenza.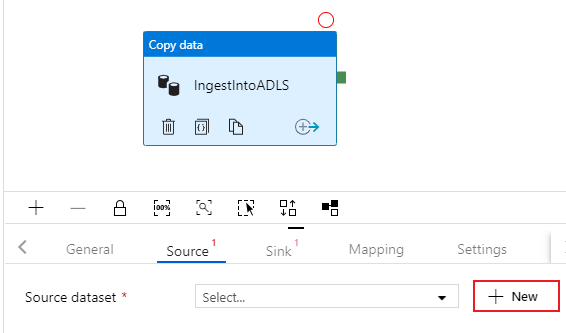
Cercare database SQL di Azure e selezionare Continua.
Assegnare al set di dati il nome 'TripData'. Selezionare 'SQLDB' come servizio collegato. Selezionare il nome
dbo.TripDatadella tabella dall'elenco a discesa nome tabella. Importare lo schema From connection/store (Da connessione/archivio). Al termine, selezionare OK.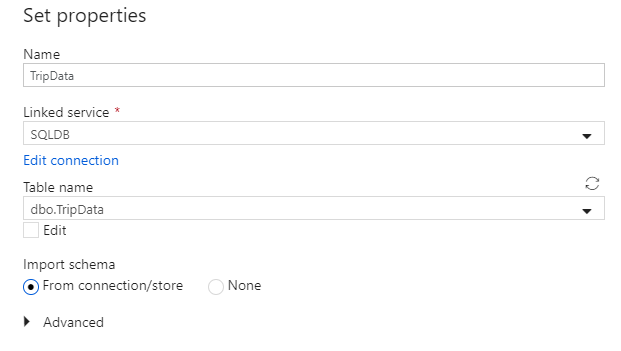
Il set di dati di origine è stato creato. Assicurarsi che nel campo Usa query delle impostazioni dell'origine sia selezionato il valore predefinito Tabella.
Configurare il set di dati sink di ADLS Gen 2
Selezionare la scheda Sink dell'attività di copia. Per creare un nuovo set di dati, selezionare Nuovo.
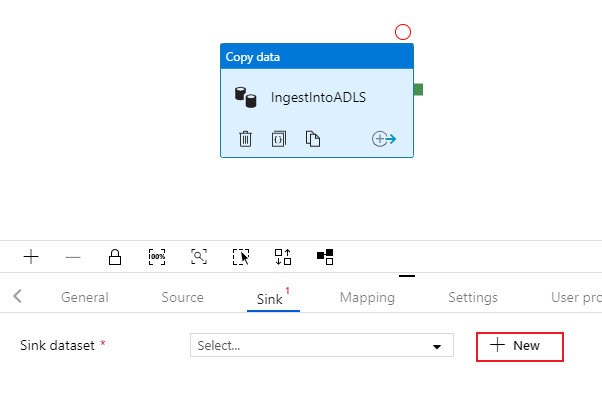
Cercare Azure Data Lake Archiviazione Gen2 e selezionare Continua.

Nel riquadro Formato selezionare DelimitedText perché si scriverà un file CSV. Selezionare Continua.

Assegnare al set di dati sink il nome 'TripDataCSV'. Selezionare 'ADLSGen2' come servizio collegato. Specificare dove si vuole scrivere il file CSV. Ad esempio, è possibile scrivere i dati nel file
trip-data.csvnel contenitorestaging-container. Impostare First row as header (Prima riga come intestazione) su True se si vuole che i dati di output abbiano intestazioni. Poiché nella destinazione non esistono ancora file, impostare Importa schema su Nessuno. Al termine, selezionare OK.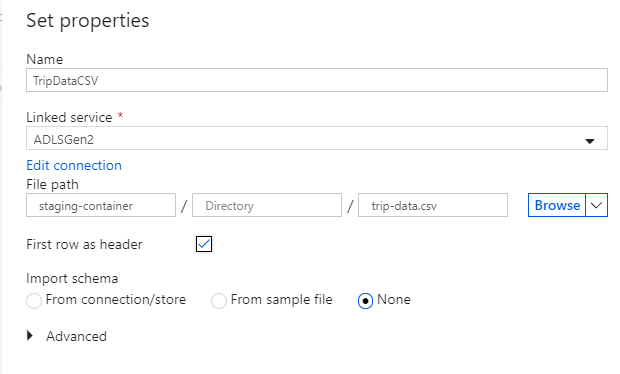
Testare l'attività di copia con l'esecuzione del debug della pipeline
Per verificare che l'attività di copia funzioni correttamente, selezionare Debug nella parte superiore dell'area di disegno della pipeline per eseguire un'esecuzione di debug. L'esecuzione del debug consente di testare la pipeline end-to-end o fino a un punto di interruzione prima di pubblicarla nel servizio data factory.
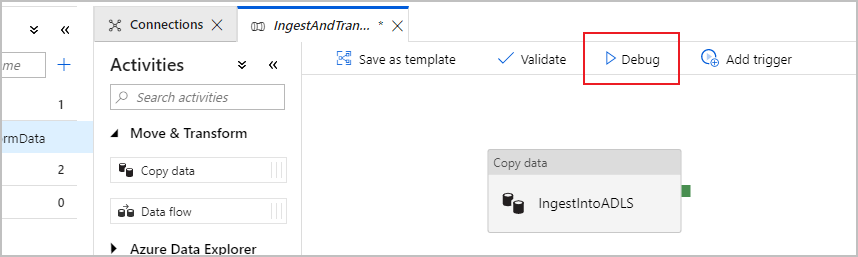
Per monitorare l'esecuzione del debug, aprire la scheda Output del canvas della pipeline. La schermata di monitoraggio si aggiorna automaticamente ogni 20 secondi o quando si seleziona manualmente il pulsante di aggiornamento. L'attività di copia ha una visualizzazione di monitoraggio speciale, accessibile selezionando l'icona degli occhiali nella colonna Azioni .
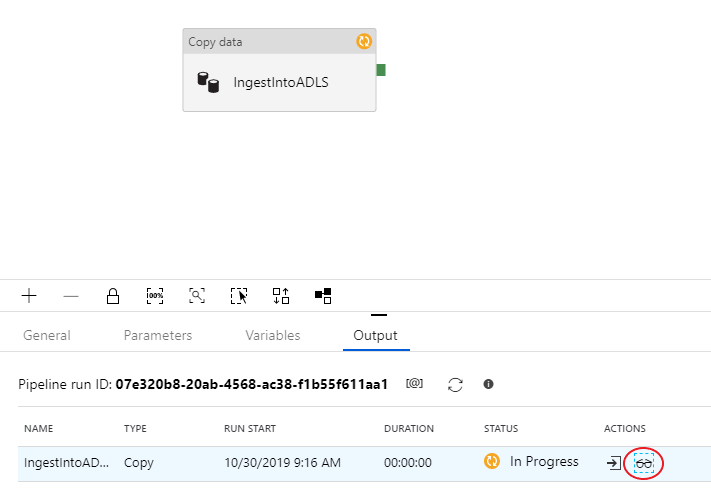
La visualizzazione del monitoraggio della copia fornisce i dettagli sull'esecuzione e le caratteristiche delle prestazioni dell'attività. Le informazioni riguardano la quantità di dati, righe e file letti/scritti, oltre alla velocità effettiva. Se tutto è stato configurato correttamente, verranno visualizzate 49.999 righe scritte in un unico file nel sink ADLS.
Prima di passare alla sezione successiva, è consigliabile pubblicare le modifiche nel servizio data factory selezionando Pubblica tutto nella barra superiore della factory di fabbrica. Anche se non è descritto in questo lab, Azure Data Factory supporta la piena integrazione con git. L'integrazione con git consente il controllo della versione, il salvataggio iterativo in un repository e la collaborazione su una data factory. Per altre informazioni, vedere Controllo del codice sorgente in Azure Data Factory.


Trasformare i dati con il flusso di dati di mapping
Dopo aver correttamente copiato i dati in Azure Data Lake Storage, è possibile aggregarli in un data warehouse. Viene usato il flusso di dati di mapping, il servizio di trasformazione progettato visivamente di Azure Data Factory. I flussi di dati per mapping consentono agli utenti di sviluppare logica di trasformazione senza codice e di eseguirli in cluster Spark gestiti dal servizio ADF.
Il flusso di dati creato in questo passaggio unisce il set di dati 'TripDataCSV' creato nella sezione precedente con una tabella dbo.TripFares archiviata in 'SQLDB' in base a quattro colonne chiave. Quindi i dati vengono aggregati in base alla colonna payment_type per calcolare la media di determinati campi e vengono scritti in una tabella di Azure Synapse Analytics.
Aggiungere un'attività di flusso di dati alla pipeline
Nel riquadro attività del canvas della pipeline aprire il menu Move and Transform (Sposta e trasforma) e trascinare l'attività Flusso di dati nel canvas.
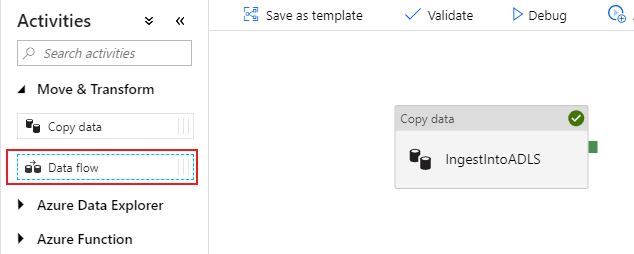
Nel riquadro laterale che si apre selezionare Create new data flow (Crea nuovo flusso di dati) e scegliere Flusso di dati per mapping. Seleziona OK.
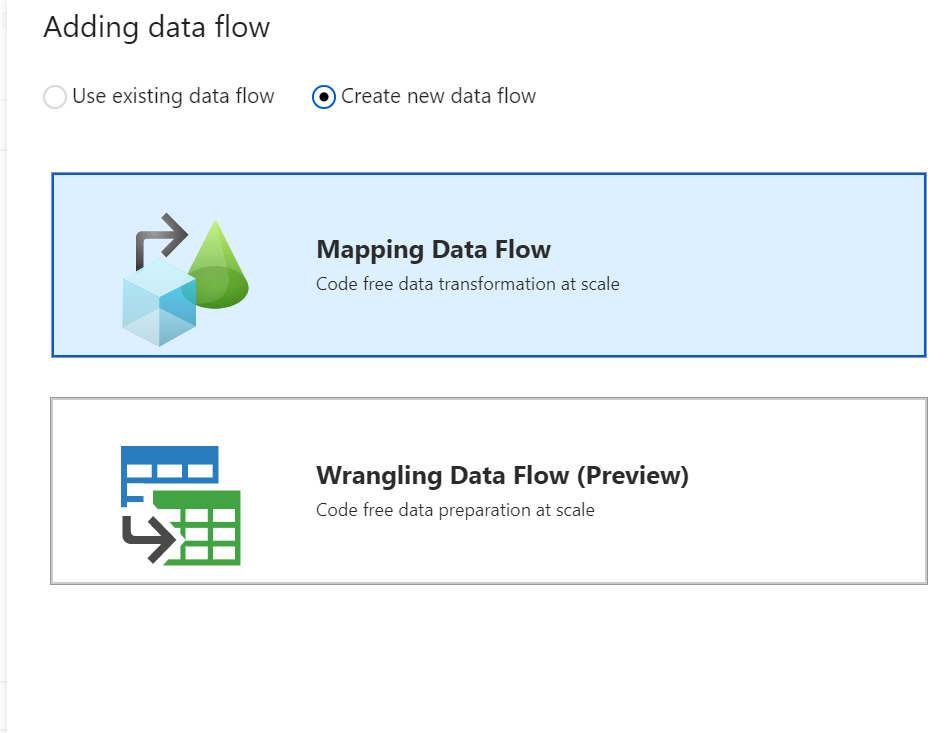
Si viene indirizzati all'area di disegno del flusso di dati in cui si creerà la logica di trasformazione. Nella scheda Generale assegnare al flusso di dati il nome 'JoinAndAggregateData'.


Configurare l'origine CSV dei dati di viaggio
La prima cosa da fare è configurare le due trasformazioni di origine. La prima origine punta al set di dati DelimitedText "TripDataCSV". Per aggiungere una trasformazione di origine, selezionare la casella Aggiungi origine nell'area di disegno.
Assegnare all'origine il nome "TripDataCSV" e selezionare il set di dati "TripDataCSV" dall'elenco a discesa di origine. Inizialmente, quando è stato creato questo set di dati, non è stato importato uno schema perché non erano disponibili dati. Poiché
trip-data.csvesiste ora, selezionare Modifica per passare alla scheda impostazioni del set di dati.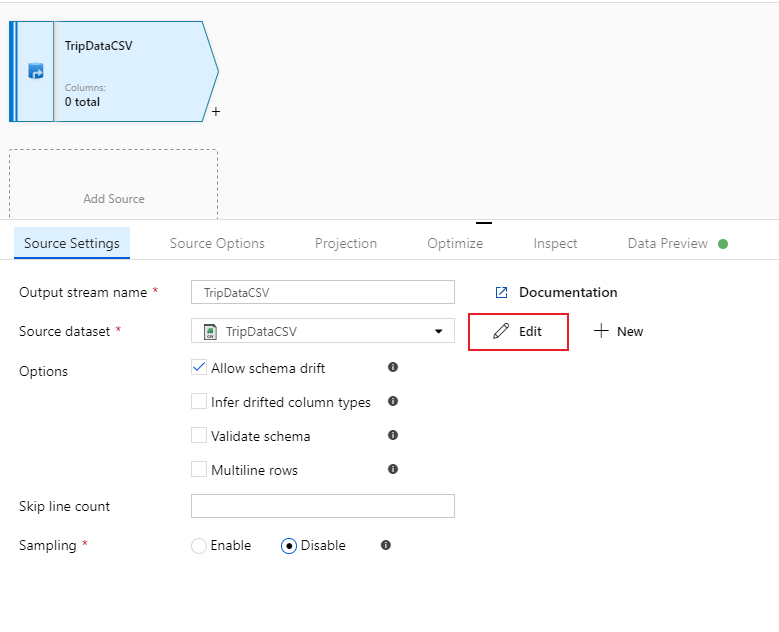
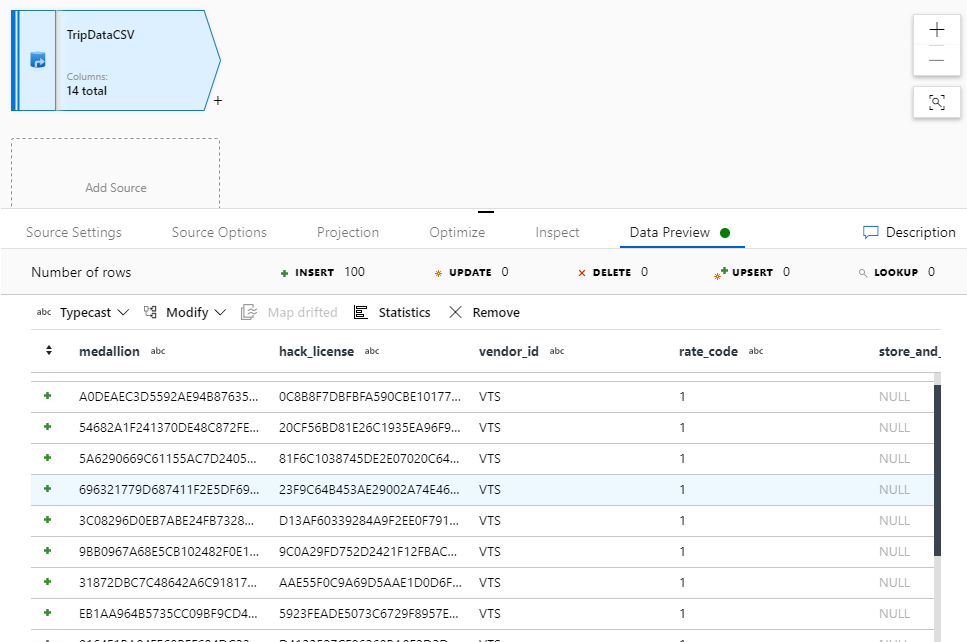
Passare alla scheda Schema e selezionare Importa schema. Selezionare From connection/store (Da connessione/archivio) per eseguire l'importazione direttamente dall'archivio file. Verranno visualizzate 14 colonne di tipo stringa.

Tornare nel flusso di dati 'JoinAndAggregateData'. Se il cluster di debug è stato avviato (indicato da un cerchio verde accanto al dispositivo di scorrimento di debug), è possibile ottenere uno snapshot dei dati nella scheda Anteprima dati. Selezionare Aggiorna per recuperare un'anteprima dei dati.


Nota
L'anteprima dei dati non scrive dati.
Configurare le tariffe di viaggio database SQL'origine
La seconda origine da aggiungere punti alla tabella
dbo.TripFaresdatabase SQL . Nell'origine "TripDataCSV" è presente un'altra casella Aggiungi origine . Selezionarlo per aggiungere una nuova trasformazione di origine.
Assegnare a questa origine il nome 'TripFaresSQL'. Selezionare Nuovo accanto al campo del set di dati di origine per creare un nuovo set di dati database SQL.
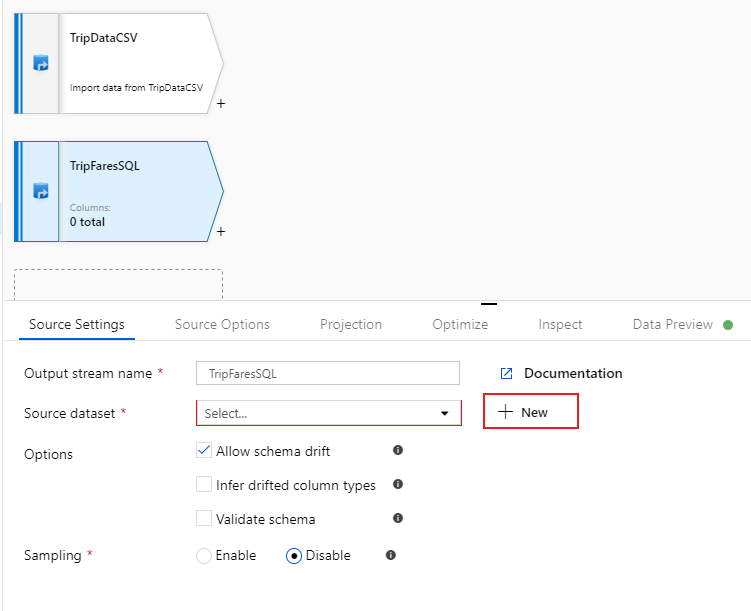
Selezionare il riquadro database SQL di Azure e selezionare Continua. È possibile notare che molti connettori nella data factory non sono supportati nel flusso di dati di mapping. Per trasformare i dati di una di queste origini, inserirli in un'origine supportata usando l'attività di copia.

Assegnare al set di dati il nome 'TripFares'. Selezionare 'SQLDB' come servizio collegato. Selezionare il nome
dbo.TripFaresdella tabella dall'elenco a discesa nome tabella. Importare lo schema From connection/store (Da connessione/archivio). Al termine, selezionare OK.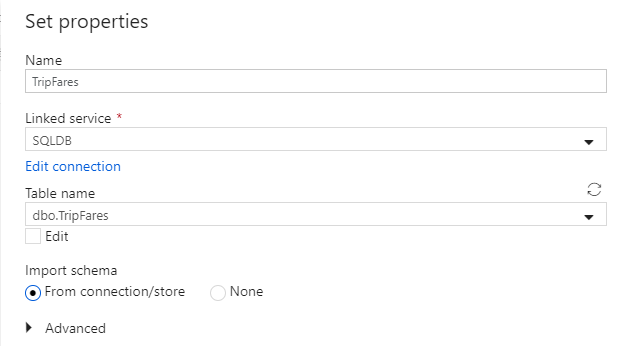
Per verificare i dati, recuperare un'anteprima nella scheda Anteprima dei dati.


Unire TripDataCSV e TripFaresSQL tramite inner join
Per aggiungere una nuova trasformazione, selezionare l'icona con il segno più nell'angolo in basso a destra di 'TripDataCSV'. In Multiple inputs/outputs (Più input/output) selezionare Join.
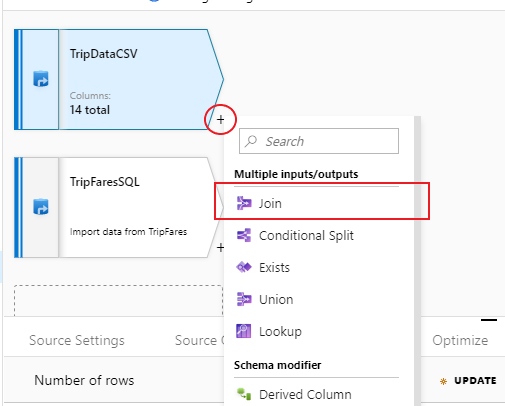
Assegnare alla trasformazione di join il nome 'InnerJoinWithTripFares'. Selezionare "TripFaresSQL" nell'elenco a discesa del flusso a destra. Selezionare Inner come tipo di join. Per altre informazioni sui diversi tipi di join nel flusso di dati per mapping, vedere Tipi di join.
Selezionare le colonne da associare da ogni flusso tramite l'elenco a discesa Condizioni di join . Per aggiungere una condizione di join aggiuntiva, selezionare l'icona del segno più accanto a una condizione esistente. Per impostazione predefinita, tutte le condizioni di join vengono combinate con un operatore AND, il che significa che devono essere soddisfatte tutte per restituire una corrispondenza. In questo lab verrà trovata una corrispondenza per le colonne
medallion,hack_license,vendor_idepickup_datetime
Verificare di aver unito correttamente 25 colonne tra loro con un'anteprima dei dati.



Aggregazione per payment_type
Dopo aver completato la trasformazione join, aggiungere una trasformazione di aggregazione selezionando l'icona del segno più accanto a InnerJoinWithTripFares. Scegliere Aggregate (Aggregazione) in Schema modifier (Modificatore di schema).
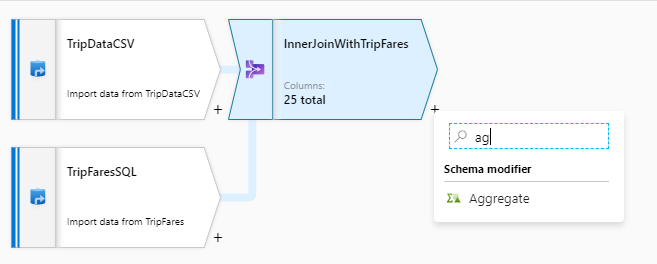
Assegnare alla trasformazione di aggregazione il nome 'AggregateByPaymentType'. Selezionare
payment_typecome colonna in base a cui raggruppare.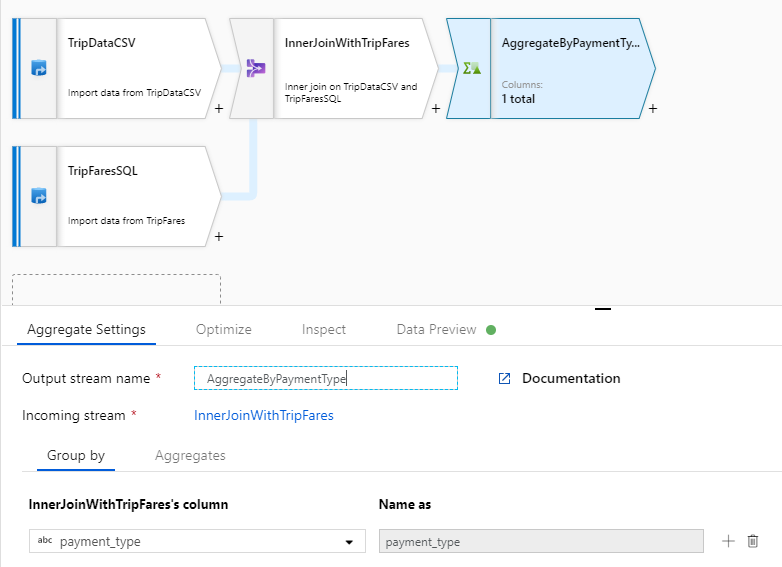
Passare alla scheda Aggregazioni. Specificare due aggregazioni :
- La tariffa media raggruppata per tipo di pagamento
- La distanza totale delle corse raggruppata per tipo di pagamento
Creare prima di tutto l'espressione per la tariffa media. Nella casella di testo Add or select a column (Aggiungere o selezionare una colonna) immettere 'average_fare'.
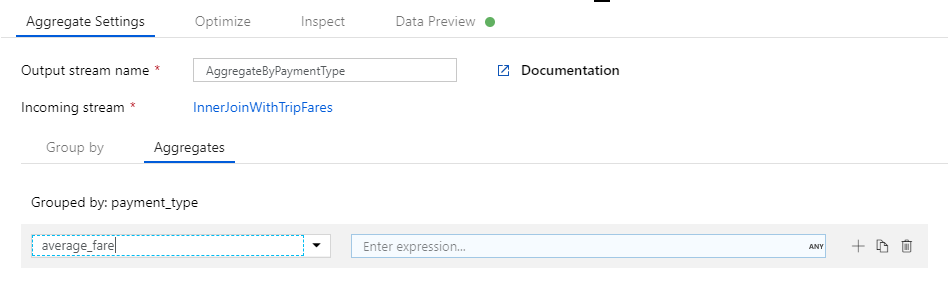
Per immettere un'espressione di aggregazione, selezionare la casella blu con etichetta Invio espressione, che apre il generatore di espressioni del flusso di dati, uno strumento usato per creare visivamente espressioni del flusso di dati usando lo schema di input, le funzioni e le operazioni predefinite e i parametri definiti dall'utente. Per altre informazioni sulle funzionalità di generatore di espressioni, vedere la relativa documentazione.
Per ottenere la tariffa media, usare la funzione di aggregazione
avg()per aggregare il cast della colonnatotal_amounta un intero contoInteger(). Nel linguaggio delle espressioni del flusso di dati, questa operazione viene definita comeavg(toInteger(total_amount)). Al termine, selezionare Salva e terminare .
Per aggiungere un'espressione di aggregazione aggiuntiva, selezionare l'icona con il segno più accanto a
average_fare. Selezionare Aggiungi colonna.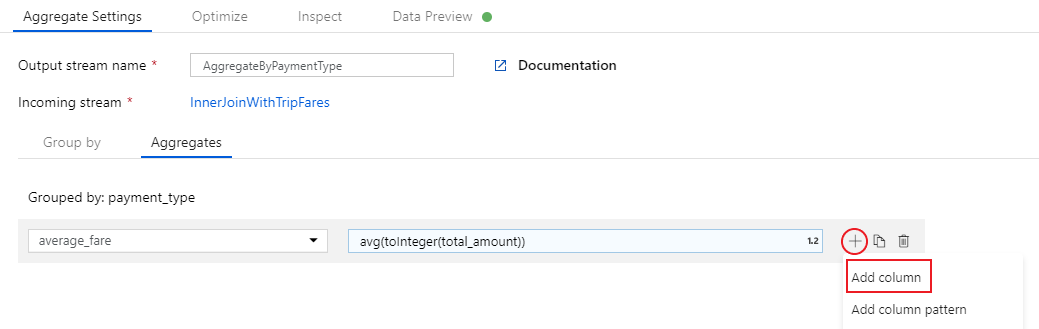
Nella casella di testo Add or select a column (Aggiungere o selezionare una colonna) immettere 'total_trip_distance'. Come nel passaggio precedente, aprire il generatore di espressioni per immettere l'espressione.
Per ottenere la distanza totale delle corse, usare la funzione di aggregazione
sum()per aggregare il cast della colonnatrip_distancea un intero contoInteger(). Nel linguaggio delle espressioni del flusso di dati, questa operazione viene definita comesum(toInteger(trip_distance)). Al termine, selezionare Salva e terminare .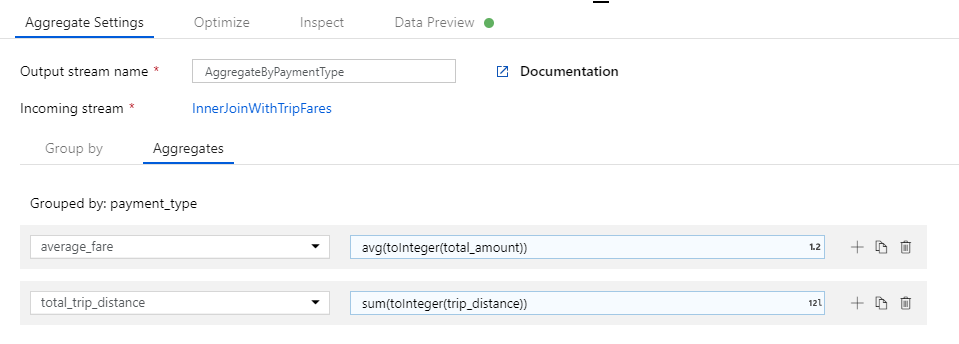
Testare la logica di trasformazione nella scheda Anteprima dati. Come si può notare, sono presenti meno righe e colonne rispetto a quelle precedenti. Solo le tre colonne di raggruppamento e aggregazione definite in questa trasformazione continuano downstream. Poiché nell'esempio sono presenti solo cinque gruppi di tipi di pagamento, vengono restituite solo cinque righe.






Configurare il sink di Azure Synapse Analytics
Una volta completata la logica di trasformazione, è possibile eseguire il sink dei dati in una tabella di Azure Synapse Analytics. Aggiungere una trasformazione di sink nella sezione Destination (Destinazione).

Assegnare un nome al sink 'SQLDWSink'. Selezionare Nuovo accanto al campo del set di dati sink per creare un nuovo set di dati di Azure Synapse Analytics.
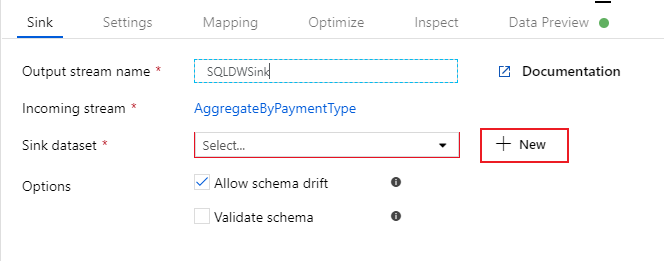
Selezionare il riquadro Azure Synapse Analytics e selezionare Continua.
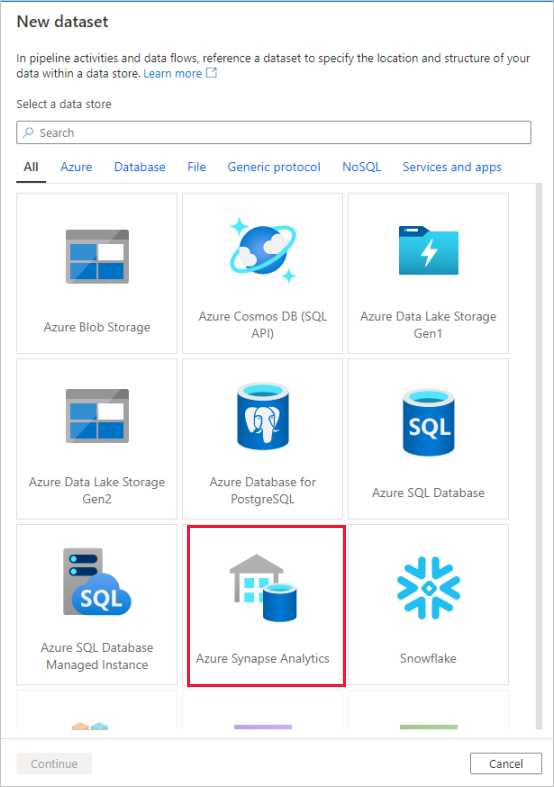
Assegnare al set di dati il nome 'AggregatedTaxiData'. Selezionare 'SQLDW' come servizio collegato. Selezionare Crea nuova tabella e assegnare alla nuova tabella
dbo.AggregateTaxiDatail nome . Al termine, selezionare OK.
Passare alla scheda Impostazioni del sink. Poiché si sta creando una nuova tabella, è necessario selezionare Recreate table (Ricrea tabella) come azione. Deselezionare Enable staging (Abilita staging), che consente di scegliere se inserire i dati riga per riga o in batch.
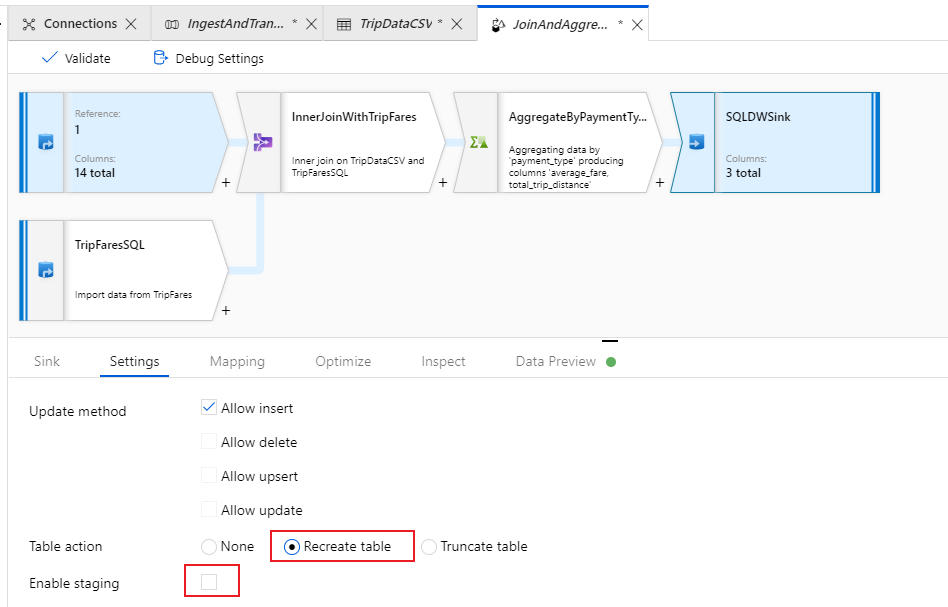


Il flusso di dati è stato creato. A questo punto è possibile eseguirlo in un'attività della pipeline.
Eseguire il debug della pipeline end-to-end
Tornare nella scheda relativa alla pipeline IngestAndTransformData. Notare la casella verde nell'attività di copia 'IngestIntoADLS'. Trascinarla nell'attività del flusso di dati 'JoinAndAggregateData'. Viene creato un oggetto 'on success', che determina l'esecuzione dell'attività del flusso di dati solo se la copia riesce.
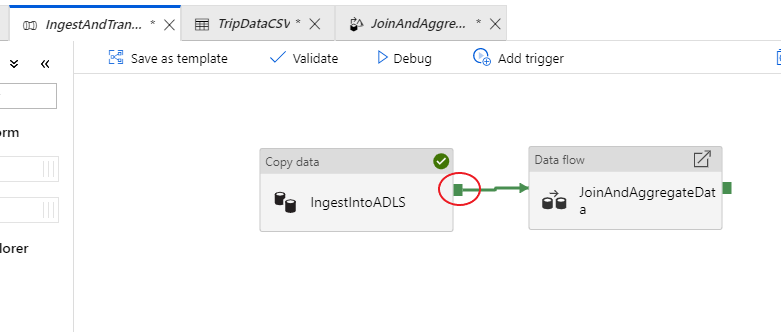
Come è stato fatto per l'attività di copia, selezionare Debug per eseguire un'esecuzione di debug. Per le esecuzioni di debug, l'attività flusso di dati usa il cluster di debug attivo anziché avviare un nuovo cluster. L'esecuzione di questa pipeline richiede poco più di un minuto.

Analogamente all'attività di copia, il flusso di dati include una speciale visualizzazione di monitoraggio accessibile tramite l'icona degli occhiali al completamento dell'attività.
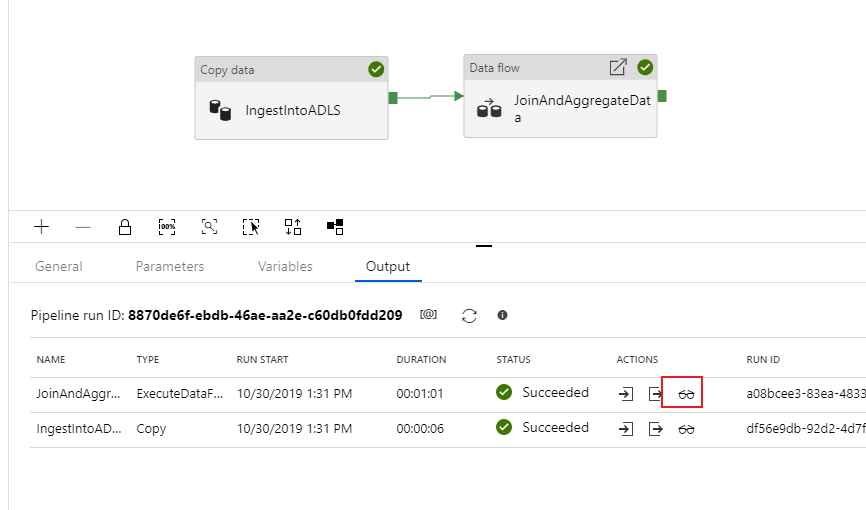
Nella visualizzazione di monitoraggio è possibile visualizzare un grafico del flusso di dati semplificato insieme ai tempi di esecuzione e alle righe in ogni fase dell'esecuzione. Se l'attività viene eseguita correttamente, si dovrebbe aver aggregato 49.999 righe in cinque righe.
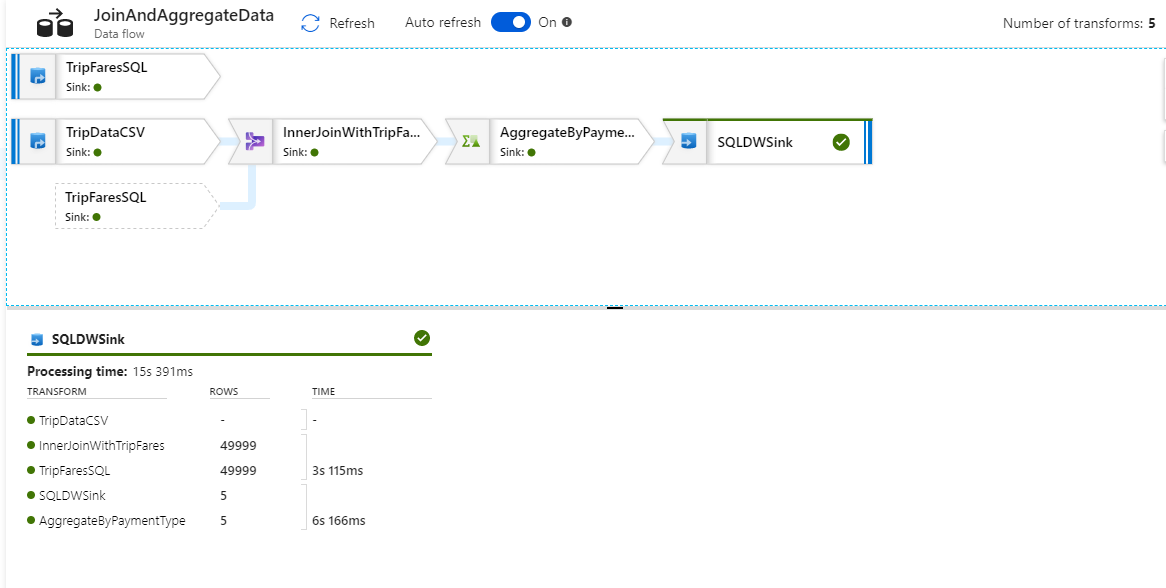
È possibile selezionare una trasformazione per ottenere dettagli aggiuntivi sull'esecuzione, ad esempio informazioni sul partizionamento e colonne nuove/aggiornate/eliminate.





A questo punto è stata completata la parte di questo lab relativa alla data factory. Pubblicare le risorse da operazionalizzare con i trigger. È stata eseguita correttamente una pipeline che ha inserito i dati del database SQL di Azure in Azure Data Lake Storage usando l'attività di copia e quindi ha aggregato questi dati in Azure Synapse Analytics. È possibile verificare che i dati siano stati scritti correttamente esaminando l'istanza stessa di SQL Server.
Condividere dati con Condivisione dati di Azure
In questa sezione viene illustrato come configurare una nuova condivisione dati usando il portale di Azure. Ciò comporta la creazione di una nuova condivisione dati che contiene set di dati da Azure Data Lake Archiviazione Gen2 e Azure Synapse Analytics. Verrà quindi configurata una pianificazione degli snapshot che fornirà ai consumer di dati l'opzione per aggiornare automaticamente i dati condivisi. Infine, verranno invitati i destinatari nella condivisione dati.
Dopo aver creato una condivisione di dati, si assumerà il ruolo di consumer di dati. In veste di consumer di dati, si completerà il flusso che consiste nell'accettare un invito alla condivisione dati, configurare la posizione in cui ricevere i dati ed eseguire il mapping dei set di dati in posizioni di archiviazione diverse. Verrà quindi attivato uno snapshot, che copia i dati condivisi con l'utente nella destinazione specificata.
Condividere dati (flusso di provider di dati)
Aprire il portale di Azure in Microsoft Edge o Google Chrome.
Usando la barra di ricerca nella parte superiore della pagina, cercare Condivisioni dati
Selezionare l'account di condivisione dati con 'Provider' nel nome. Ad esempio, DataProvider0102.
Selezionare Inizia la condivisione dei dati

Selezionare + Crea per avviare la configurazione della nuova condivisione dati.
In Condivisione dati specificare un nome a scelta. Si tratta del nome della condivisione che verrà visualizzato dal consumer di dati, quindi assicurarsi di specificare un nome descrittivo, ad esempio TaxiData.
In Descrizione inserire una frase che descriva il contenuto della condivisione dati. La condivisione dati contiene dati relativi alle corse in taxi a livello mondiale archiviati in un'ampia gamma di archivi, tra cui Azure Synapse Analytics e Azure Data Lake Archiviazione.
In Condizioni per l'utilizzo specificare una serie di condizioni a cui il consumer di dati dovrà conformarsi, ad esempio "Non distribuire questi dati all'esterno dell'organizzazione" oppure "Vedere il contratto legale".

Selezionare Continua.
Selezionare Aggiungi set di dati

Selezionare Azure Synapse Analytics per selezionare una tabella di Azure Synapse Analytics in cui sono state inserite le trasformazioni di Azure Data Factory.
Viene assegnato uno script da eseguire prima di procedere. Lo script fornito crea un utente nel database SQL per consentire all'identità del servizio gestita di Condivisione dati di Azure di eseguire l'autenticazione per suo conto.
Importante
Prima di eseguire lo script, è necessario impostare se stessi come Amministrazione di Active Directory per il server SQL logico del database SQL di Azure.
Aprire una nuova scheda e passare al portale di Azure. Copiare lo script fornito per creare un utente nel database da cui si vogliono condividere i dati. A tale scopo, accedere al database EDW usando l'editor di query portale di Azure usando l'autenticazione Di Microsoft Entra. È necessario modificare l'utente nello script di esempio seguente:
CREATE USER [dataprovider-xxxx@contoso.com] FROM EXTERNAL PROVIDER; ALTER ROLE db_owner ADD MEMBER [wiassaf@microsoft.com];Tornare in Condivisione dati di Azure in cui sono stati aggiunti i set di dati alla condivisione dati.
Selezionare EDW, quindi selezionare AggregatedTaxiData per la tabella.
Selezionare Aggiungi set di dati
È ora disponibile una tabella SQL che fa parte del set di dati. Verranno quindi aggiunti altri set di dati da Azure Data Lake Archiviazione.
Selezionare Aggiungi set di dati e selezionare Azure Data Lake Archiviazione Gen2

Selezionare Avanti.
Espandere wwtaxidata. Espandere Boston Taxi Data. È possibile condividere fino al livello di file.
Selezionare la cartella Boston Taxi Data per aggiungere l'intera cartella alla condivisione dati.
Selezionare Aggiungi set di dati
Esaminare i set di dati aggiunti. Alla condivisione dati dovrebbero essere state aggiunte una tabella SQL e una cartella di ADLS Gen2.
Selezionare Continua
In questa schermata è possibile aggiungere i destinatari alla condivisione dati. I destinatari aggiunti riceveranno gli inviti alla condivisione dati. Ai fini di questo lab, è necessario aggiungere due indirizzi di posta elettronica:
L'indirizzo di posta elettronica della sottoscrizione di Azure in uso.

Aggiungere il consumer di dati fittizio denominato janedoe@fabrikam.com.
In questa schermata è possibile configurare un'impostazione degli snapshot per il consumer di dati. In questo modo è possibile ricevere aggiornamenti regolari dei dati a intervalli definiti dall'utente.
Selezionare Pianificazione snapshot e configurare un aggiornamento orario dei dati usando l'elenco a discesa Ricorrenza .
Seleziona Crea.
A questo punto è disponibile una condivisione dati attiva. Esaminare i contenuti visibili a un provider di dati quando si crea una condivisione dati.
Selezionare la condivisione dati creata, denominata DataProvider. È possibile accedervi selezionando Condivisioni inviate in Condivisione dati.
Selezionare Pianificazione snapshot. Se si preferisce, è possibile disabilitare la pianificazione degli snapshot.
Selezionare quindi la scheda Set di dati . È possibile aggiungere altri set di dati a questa condivisione dati dopo la creazione.
Selezionare la scheda Condividi sottoscrizioni . Nessuna sottoscrizione di condivisione esistente perché il consumer di dati non ha ancora accettato l'invito.
Passare alla scheda Inviti . Qui verrà visualizzato un elenco di inviti in sospeso.

Selezionare l'invito inviato a janedoe@fabrikam.com. Selezionare Elimina. Se il destinatario non ha ancora accettato l'invito, non sarà più in grado di farlo.
Selezionare la scheda Cronologia . Non viene ancora visualizzato nulla perché il consumer di dati non ha ancora accettato l'invito e ha attivato uno snapshot.






Ricevere dati (flusso del consumer di dati)
Dopo aver esaminato la condivisione dati, è possibile cambiare contesto e assumere il ruolo di consumer di dati.
A questo punto, nella posta in arrivo si dovrebbe avere un invito di Condivisione dati di Azure inviato da Microsoft Azure. Avviare Outlook Web Access (outlook.com) e accedere usando le credenziali fornite per la sottoscrizione di Azure.
Nel messaggio di posta elettronica che si dovrebbe ricevere selezionare "Visualizza invito >". A questo punto, si simulerà l'esperienza del consumer di dati quando accetta l'invito di un provider di dati nella sua condivisione dati.

Potrebbe essere richiesto di selezionare una sottoscrizione. Assicurarsi di selezionare la sottoscrizione che si usa per questo lab.
Selezionare l'invito denominato DataProvider.
In questa schermata invito si notino vari dettagli sulla condivisione dati configurata in precedenza come provider di dati. Esaminare i dettagli e accettare le condizioni per l'utilizzo, se disponibili.
Selezionare la sottoscrizione e il gruppo di risorse già esistenti per il lab.
Per Data share account (Account di condivisione dati), selezionare DataConsumer. È anche possibile creare un nuovo account di condivisione dati.
Accanto a Nome condivisione ricevuta, si noti che il nome di condivisione predefinito è il nome specificato dal provider di dati. Assegnare alla condivisione un nome descrittivo per i dati che si stanno per ricevere, ad esempio TaxiDataShare.

È possibile scegliere l'opzione Accept and configure now (Accetta e configura ora) o Accept and configure later (Accetta e configura più tardi). Se si sceglie di accettare e configurare ora, specificare un account di archiviazione in cui copiare tutti i dati. Se si sceglie la seconda opzione, i set di dati della condivisione non saranno mappati e sarà necessario eseguirne il mapping manualmente. Questa opzione verrà scelta in seguito.
Selezionare Accept and configure later (Accetta e configura più tardi).
Quando si configura questa opzione, viene creata una sottoscrizione di condivisione, ma non è possibile che i dati vengano inseriti perché non è stato eseguito il mapping della destinazione.
Configurare quindi i mapping dei set di dati per la condivisione dati.
Selezionare la condivisione ricevuta (il nome specificato nel passaggio 5).
L'opzione Attiva snapshot è disattivata, ma la condivisione è attiva.
Selezionare la scheda Set di dati. Ogni set di dati è Unmapped, il che significa che non ha alcuna destinazione in cui copiare i dati.

Selezionare la tabella di Azure Synapse Analytics e quindi selezionare + Esegui mapping alla destinazione.
Sul lato destro della schermata selezionare l'elenco a discesa Tipo di dati di destinazione.
È possibile eseguire il mapping dei dati SQL a un'ampia gamma di archivi dati. In questo caso, verrà eseguito a un database SQL di Azure.

(Facoltativo) Selezionare Azure Data Lake Archiviazione Gen2 come tipo di dati di destinazione.
(Facoltativo) Selezionare la sottoscrizione, il gruppo di risorse e l'account di archiviazione in uso.
(Facoltativo) È possibile scegliere di ricevere i dati nel data lake in formato CSV o parquet.
Quindi, accanto a Tipo di dati di destinazioneselezionare Database SQL di Azure.
Selezionare la sottoscrizione, il gruppo di risorse e l'account di archiviazione in uso.

Prima di continuare, è necessario creare un nuovo utente in SQL Server eseguendo lo script fornito. Copiare prima di tutto lo script fornito negli Appunti.
Aprire una nuova scheda portale di Azure. Non chiudere la scheda esistente perché sarà necessario tornare ad esso in un momento.
Nella nuova scheda aperta passare a Database SQL.
Selezionare il database SQL (dovrebbe esserne presente uno solo nella sottoscrizione). Fare attenzione a non selezionare il data warehouse.
Selezionare Editor di query (anteprima)
Usare l'autenticazione di Microsoft Entra per accedere all'editor di query.
Eseguire la query specificata nella condivisione dati (copiata negli Appunti nel passaggio 14).
Con questo comando il servizio Condivisione dati di Azure può usare identità gestite per consentire ai servizi di Azure di eseguire l'autenticazione in SQL Server in modo da potervi copiare i dati.
Tornare nella scheda originale e selezionare Esegui mapping alla destinazione.
Selezionare quindi la cartella Azure Data Lake Archiviazione Gen2 che fa parte del set di dati ed eseguirne il mapping a un account Archiviazione BLOB di Azure.

Con tutti i set di dati mappati, è ora possibile iniziare a ricevere dati dal provider di dati.

Selezionare Dettagli.
Lo snapshot del trigger non è più disattivato, perché la condivisione dati include ora destinazioni in cui eseguire la copia.
Selezionare Trigger snapshot -Full copy (Attiva snapshot ->Copia completa).

Verrà avviata la copia dei dati nel nuovo account di condivisione dati. In uno scenario reale, questi dati provengono da terze parti.
La visualizzazione dei dati richiede circa 3-5 minuti. È possibile monitorare lo stato di avanzamento selezionando nella scheda Cronologia .
Durante l'attesa, passare alla condivisione dati originale (DataProvider) e visualizzare lo stato della scheda Condividi sottoscrizioni e cronologia . È ora disponibile una sottoscrizione attiva e, come provider di dati, è anche possibile monitorare quando il consumer di dati ha iniziato a ricevere i dati condivisi con essi.
Tornare alla condivisione dati del consumer di dati. Quando lo stato del trigger indica che l'operazione è riuscita, passare al database SQL e al data lake di destinazione per verificare che i dati siano stati inseriti nei rispettivi archivi.







Il lab è stato completato.