Guida introduttiva: Creare un'istanza di Azure Data Factory con PowerShell
SI APPLICA A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
Questa guida di avvio rapido illustra come usare PowerShell per creare un'istanza di Azure Data Factory. La pipeline creata in questa data factory copia dati da una cartella a un'altra in un archivio BLOB di Azure. Per un'esercitazione su come trasformare i dati usando Azure Data Factory, vedere Esercitazione: Trasformare dati usando Spark.
Nota
Questo articolo non offre una presentazione dettagliata del servizio Data Factory. Per un'introduzione al servizio Azure Data Factory, vedere Introduzione ad Azure Data Factory.
Prerequisiti
La sottoscrizione di Azure
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Ruoli di Azure
Per creare istanze di Data Factory, l'account utente usato per accedere ad Azure deve essere un membro del ruolo collaboratore o proprietario oppure un amministratore della sottoscrizione di Azure. Per visualizzare le autorizzazioni disponibili nella sottoscrizione, passare al portale di Azure, selezionare il nome utente nell'angolo in alto a destra, selezionare l'icona ... per visualizzare altre opzioni e quindi selezionare Autorizzazioni personali. Se si accede a più sottoscrizioni, selezionare quella appropriata.
Per creare e gestire le risorse figlio per Data Factory, inclusi i set di dati, i servizi collegati, le pipeline, i trigger e i runtime di integrazione, sono applicabili i requisiti seguenti:
- Per creare e gestire le risorse figlio nel portale di Azure, è necessario appartenere al ruolo Collaboratore Data Factory a livello di gruppo di risorse o superiore.
- Per creare e gestire le risorse figlio con PowerShell o l'SDK, è sufficiente il ruolo di collaboratore a livello di risorsa o superiore.
Per istruzioni di esempio su come aggiungere un utente a un ruolo, vedere l'articolo Aggiungere i ruoli.
Per altre informazioni, vedere gli articoli seguenti:
Account di archiviazione di Azure
In questa guida di avvio rapido si usa un account di archiviazione di Azure per utilizzo generico (nello specifico, un account di archiviazione BLOB) come archivio dati sia di origine che di destinazione. Se non si ha un account di archiviazione di Azure per utilizzo generico, vedere Creare un account di archiviazione per informazioni su come crearne uno.
Ottenere il nome dell'account di archiviazione
Il nome dell'account di archiviazione di Azure è necessario per questa guida di avvio rapido. La procedura seguente illustra i passaggi per recuperare il nome dell'account di archiviazione:
- In un Web browser passare al portale di Azure e accedere usando il nome utente e la password di Azure.
- Dal menu del portale di Azure scegliere Tutti i servizi, quindi selezionare Archiviazione>Account di archiviazione. È anche possibile cercare e selezionare Account di archiviazione in qualsiasi pagina.
- Nella pagina Account di archiviazione filtrare gli account di archiviazione, se necessario, quindi selezionare il proprio account di archiviazione.
È anche possibile cercare e selezionare Account di archiviazione in qualsiasi pagina.
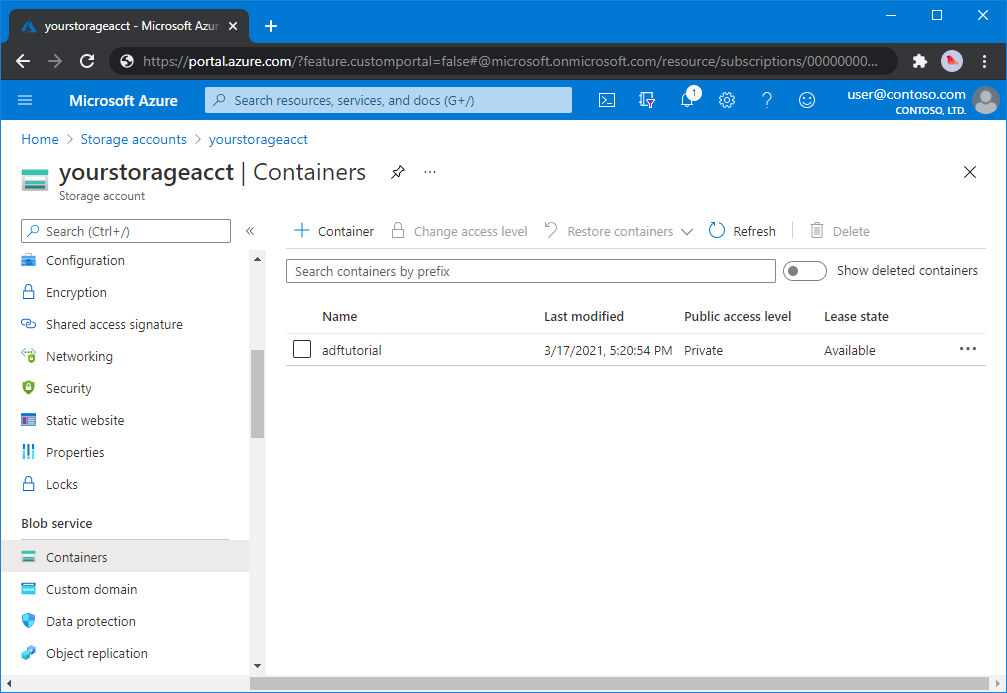
Creare un contenitore BLOB
In questa sezione viene creato un contenitore BLOB denominato adftutorial nell'archivio BLOB di Azure.
Dalla pagina dell'account di archiviazione, selezionare Panoramica>Contenitori.
<Nella barra degli strumenti della pagina Nome - >account Contenitori selezionare Contenitore.
Nella finestra di dialogo Nuovo contenitore immettere adftutorial come nome e quindi fare clic su OK. La pagina Contenitori nome - >account viene aggiornata per includere adftutorial nell'elenco dei contenitori.<
Aggiungere una cartella di input e un file per il contenitore BLOB
In questa sezione viene creata una cartella denominata input nel contenitore creato, in cui verrà caricato un file di esempio. Prima di iniziare, aprire un editor di testo come il Blocco note e creare un file denominato emp.txt con il contenuto seguente:
John, Doe
Jane, Doe
Salvare il file nella cartella C:\ADFv2QuickStartPSH. Se la cartella non esiste già, crearla. Tornare quindi alla portale di Azure e seguire questa procedura:
<Nella pagina Contenitori nome - >account in cui è stata interrotta selezionare adftutorial dall'elenco aggiornato dei contenitori.
- Se la finestra è stata chiusa o è passata a un'altra pagina, accedere nuovamente al portale di Azure.
- Dal menu del portale di Azure scegliere Tutti i servizi, quindi selezionare Archiviazione>Account di archiviazione. È anche possibile cercare e selezionare Account di archiviazione in qualsiasi pagina.
- Selezionare l'account di archiviazione, quindi Contenitori>adftutorial.
Nella barra degli strumenti della pagina del contenitore adftutorial selezionare Carica.
Nella pagina Carica BLOB selezionare la casella File, quindi individuare e selezionare il file emp.txt.
Espandere l'intestazione Avanzate. La pagina viene ora visualizzata come illustrato di seguito:
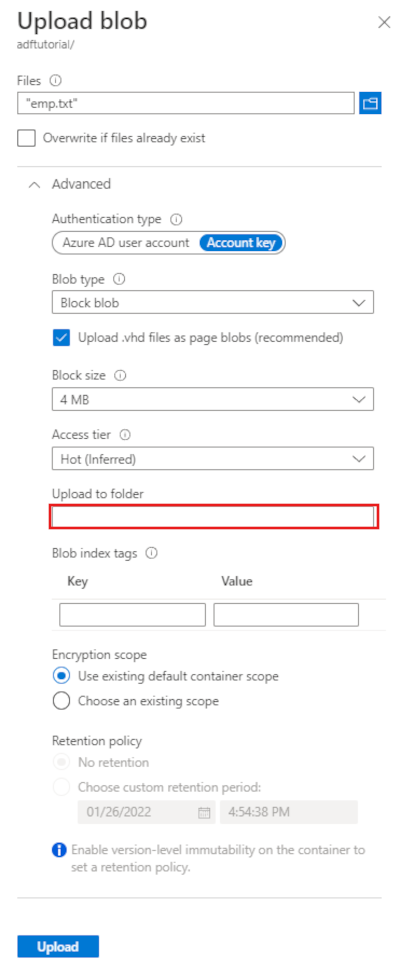
Nella casella Carica nella cartella immettere input.
Seleziona il pulsante Carica. Verranno visualizzati il file emp.txt e lo stato del caricamento nell'elenco.
Selezionare l'icona Chiudi (una X) per chiudere la pagina Carica BLOB.
Lasciare aperta la pagina del contenitore adftutorial. perché verrà usata per verificare l'output alla fine di questa guida introduttiva.
Azure PowerShell
Nota
È consigliabile usare il modulo Azure Az PowerShell per interagire con Azure. Per iniziare, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo AZ PowerShell, vedere Eseguire la migrazione di Azure PowerShell da AzureRM ad Az.
Installare i moduli di Azure PowerShell più recenti seguendo le istruzioni descritte in Come installare e configurare Azure PowerShell.
Avviso
Se non si usano le versioni più recenti del modulo PowerShell e Data Factory, è possibile che si verifichino errori di deserializzazione durante l'esecuzione dei comandi.
Accedere a PowerShell
Avviare PowerShell nel computer. Tenere aperto PowerShell fino alla fine di questa guida introduttiva. Se si chiude e si riapre, sarà necessario eseguire di nuovo questi comandi.
Eseguire questo comando e immettere lo stesso nome utente e la stessa password di Azure usati per accedere al portale di Azure:
Connect-AzAccountEseguire questo comando per visualizzare tutte le sottoscrizioni per l'account:
Get-AzSubscriptionSe vengono visualizzate più sottoscrizioni associate all'account, eseguire il comando seguente per selezionare la sottoscrizione da usare. Sostituire SubscriptionId con l'ID della sottoscrizione di Azure:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"
Creare una data factory
Definire una variabile per il nome del gruppo di risorse usato in seguito nei comandi di PowerShell. Copiare il testo del comando seguente in PowerShell, specificare un nome per il gruppo di risorse di Azure tra virgolette doppie e quindi eseguire il comando. Ad esempio:
"ADFQuickStartRG".$resourceGroupName = "ADFQuickStartRG";Se il gruppo di risorse esiste già, potrebbe essere preferibile non sovrascriverlo. Assegnare un valore diverso alla variabile
$ResourceGroupNameed eseguire di nuovo il comando.Per creare il gruppo di risorse di Azure, eseguire questo comando:
$ResGrp = New-AzResourceGroup $resourceGroupName -location 'East US'Se il gruppo di risorse esiste già, potrebbe essere preferibile non sovrascriverlo. Assegnare un valore diverso alla variabile
$ResourceGroupNameed eseguire di nuovo il comando.Definire una variabile per il nome della data factory.
Importante
Aggiornare il nome della data factory in modo che sia univoco a livello globale. Ad esempio, ADFTutorialFactorySP1127.
$dataFactoryName = "ADFQuickStartFactory";Per creare la data factory, eseguire il cmdlet Set-AzDataFactoryV2 usando le proprietà Location e ResourceGroupName della variabile $ResGrp:
$DataFactory = Set-AzDataFactoryV2 -ResourceGroupName $ResGrp.ResourceGroupName ` -Location $ResGrp.Location -Name $dataFactoryName
Notare i punti seguenti:
Il nome dell'istanza di Azure Data Factory deve essere univoco globale. Se viene visualizzato l'errore seguente, modificare il nome e riprovare.
The specified Data Factory name 'ADFv2QuickStartDataFactory' is already in use. Data Factory names must be globally unique.Per creare istanze di Data Factory, l'account utente usato per accedere ad Azure deve essere un membro dei ruoli collaboratore o proprietario oppure un amministratore della sottoscrizione di Azure.
Per un elenco di aree di Azure in cui Data Factory è attualmente disponibile, selezionare le aree di interesse nella pagina seguente, quindi espandere Analytics per individuare Data Factory: Prodotti disponibili in base all'area. Gli archivi dati (Archiviazione di Azure, database SQL di Azure e così via) e le risorse di calcolo (HDInsight e così via) usati dalla data factory possono trovarsi in altre aree.
Creare un servizio collegato
Creare servizi collegati in una data factory per collegare gli archivi dati e i servizi di calcolo alla data factory. In questa guida introduttiva si crea un servizio collegato Archiviazione di Azure che viene usato come archivio sia di origine che sink. Il servizio collegato ha le informazioni di connessione usate dal servizio Data Factory in fase di esecuzione per la connessione.
Suggerimento
In questo argomento di avvio rapido si usa La chiave account come tipo di autenticazione per l'archivio dati, ma è possibile scegliere altri metodi di autenticazione supportati: URI di firma di accesso condiviso, entità servizio e identità gestita, se necessario. Per informazioni dettagliate, vedere le sezioni corrispondenti in questo articolo. Per archiviare in modo sicuro i segreti per gli archivi dati, è anche consigliabile usare il servizio Azure Key Vault. Per le spiegazioni dettagliate, vedere questo articolo.
Creare un file JSON denominato AzureStorageLinkedService.json nella cartella C:\ADFv2QuickStartPSH con il contenuto seguente. Creare la cartella ADFv2QuickStartPSH se non esiste già.
Importante
Sostituire <accountname> e <accountkey> con il nome e la chiave dell'account di archiviazione di Azure prima di salvare il file.
{ "name": "AzureStorageLinkedService", "properties": { "annotations": [], "type": "AzureBlobStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>;EndpointSuffix=core.windows.net" } } }Se si usa Blocco note, selezionare Tutti i file per il campo Tipo file nella finestra di dialogo Salva con nome. In caso contrario, è possibile che venga aggiunta l'estensione
.txtal file. Ad esempio,AzureStorageLinkedService.json.txt. Se si crea il file in Esplora file prima di aprirlo in Blocco note, è possibile che l'estensione.txtnon venga visualizzata perché l'opzione Nascondi estensioni per i tipi di file conosciuti è selezionata per impostazione predefinita. Rimuovere l'estensione.txtprima di procedere al passaggio successivo.In PowerShell passare alla cartella ADFv2QuickStartPSH.
Set-Location 'C:\ADFv2QuickStartPSH'Eseguire il cmdlet Set-AzDataFactoryV2LinkedService per creare il servizio collegato: Azure Archiviazione LinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "AzureStorageLinkedService" ` -DefinitionFile ".\AzureStorageLinkedService.json"Di seguito è riportato l'output di esempio:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobStorageLinkedService
Creare i set di dati
In questa procedura vengono creati due set di dati, InputDataset e OutputDataset. I set di dati sono di tipo Binary. Fanno riferimento al servizio collegato Archiviazione di Azure creato nella sezione precedente. Il set di dati di input rappresenta i dati di origini nella cartella di input. Nella definizione del set di dati di input specificare il contenitore BLOB (adftutorial), la cartella (input) e il file (emp.txt) che includono i dati di origine. Il set di dati di output rappresenta i dati copiati nella destinazione. Nella definizione del set di dati di output specificare il contenitore BLOB (adftutorial), la cartella (output) e il file in cui vengono copiati i dati.
Creare un file JSON denominato InputDataset.json nella cartella C:\ADFv2QuickStartPSH, con il contenuto seguente:
{ "name": "InputDataset", "properties": { "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" }, "annotations": [], "type": "Binary", "typeProperties": { "location": { "type": "AzureBlobStorageLocation", "fileName": "emp.txt", "folderPath": "input", "container": "adftutorial" } } } }Per creare il set di dati InputDataset, eseguire il cmdlet Set-AzDataFactoryV2Dataset .
Set-AzDataFactoryV2Dataset -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "InputDataset" ` -DefinitionFile ".\InputDataset.json"Di seguito è riportato l'output di esempio:
DatasetName : InputDataset ResourceGroupName : <resourceGroupname> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.BinaryDatasetRipetere la procedura per creare il set di dati di output. Creare un file JSON denominato OutputDataset.json nella cartella C:\ADFv2QuickStartPSH, con il contenuto seguente:
{ "name": "OutputDataset", "properties": { "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" }, "annotations": [], "type": "Binary", "typeProperties": { "location": { "type": "AzureBlobStorageLocation", "folderPath": "output", "container": "adftutorial" } } } }Eseguire il cmdlet Set-AzDataFactoryV2Dataset per creare il set di dati OutDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "OutputDataset" ` -DefinitionFile ".\OutputDataset.json"Di seguito è riportato l'output di esempio:
DatasetName : OutputDataset ResourceGroupName : <resourceGroupname> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.BinaryDataset
Creare una pipeline
In questa procedura viene creata una pipeline con un'attività di copia che usa i set di dati di input e di output. Con l'attività di copia i dati vengono copiati dal file specificato nelle impostazioni del set di dati di input al file specificato nelle impostazioni del set di dati di output.
Creare un file JSON denominato Adfv2QuickStartPipeline.json nella cartella C:\ADFv2QuickStartPSH, con il contenuto seguente:
{ "name": "Adfv2QuickStartPipeline", "properties": { "activities": [ { "name": "CopyFromBlobToBlob", "type": "Copy", "dependsOn": [], "policy": { "timeout": "7.00:00:00", "retry": 0, "retryIntervalInSeconds": 30, "secureOutput": false, "secureInput": false }, "userProperties": [], "typeProperties": { "source": { "type": "BinarySource", "storeSettings": { "type": "AzureBlobStorageReadSettings", "recursive": true } }, "sink": { "type": "BinarySink", "storeSettings": { "type": "AzureBlobStorageWriteSettings" } }, "enableStaging": false }, "inputs": [ { "referenceName": "InputDataset", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "OutputDataset", "type": "DatasetReference" } ] } ], "annotations": [] } }Per creare la pipeline: Adfv2QuickStartPipeline, eseguire il cmdlet Set-AzDataFactoryV2Pipeline .
$DFPipeLine = Set-AzDataFactoryV2Pipeline ` -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName ` -Name "Adfv2QuickStartPipeline" ` -DefinitionFile ".\Adfv2QuickStartPipeline.json"
Creare un'esecuzione della pipeline
In questo passaggio viene creata un'esecuzione della pipeline.
Eseguire il cmdlet Invoke-AzDataFactoryV2Pipeline per creare un'esecuzione della pipeline. Il cmdlet restituisce l'ID di esecuzione della pipeline per il monitoraggio futuro.
$RunId = Invoke-AzDataFactoryV2Pipeline `
-DataFactoryName $DataFactory.DataFactoryName `
-ResourceGroupName $ResGrp.ResourceGroupName `
-PipelineName $DFPipeLine.Name
Monitorare l'esecuzione della pipeline
Eseguire lo script di PowerShell seguente per verificare continuamente lo stato di esecuzione della pipeline fino al termine della copia dei dati. Copiare/Incollare lo script seguente nella finestra di PowerShell e premere INVIO.
while ($True) { $Run = Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $ResGrp.ResourceGroupName ` -DataFactoryName $DataFactory.DataFactoryName ` -PipelineRunId $RunId if ($Run) { if ( ($Run.Status -ne "InProgress") -and ($Run.Status -ne "Queued") ) { Write-Output ("Pipeline run finished. The status is: " + $Run.Status) $Run break } Write-Output ("Pipeline is running...status: " + $Run.Status) } Start-Sleep -Seconds 10 }Ecco l'output di esempio dell'esecuzione della pipeline:
Pipeline is running...status: InProgress Pipeline run finished. The status is: Succeeded ResourceGroupName : ADFQuickStartRG DataFactoryName : ADFQuickStartFactory RunId : 00000000-0000-0000-0000-0000000000000 PipelineName : Adfv2QuickStartPipeline LastUpdated : 8/27/2019 7:23:07 AM Parameters : {} RunStart : 8/27/2019 7:22:56 AM RunEnd : 8/27/2019 7:23:07 AM DurationInMs : 11324 Status : Succeeded Message :Eseguire lo script seguente per recuperare i dettagli sull'esecuzione dell'attività di copia, ad esempio le dimensioni dei dati letti/scritti.
Write-Output "Activity run details:" $Result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $DataFactory.DataFactoryName -ResourceGroupName $ResGrp.ResourceGroupName -PipelineRunId $RunId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) $Result Write-Output "Activity 'Output' section:" $Result.Output -join "`r`n" Write-Output "Activity 'Error' section:" $Result.Error -join "`r`n"Assicurarsi di visualizzare un output simile all'output di esempio seguente come risultato dell'esecuzione dell'attività:
ResourceGroupName : ADFQuickStartRG DataFactoryName : ADFQuickStartFactory ActivityRunId : 00000000-0000-0000-0000-000000000000 ActivityName : CopyFromBlobToBlob PipelineRunId : 00000000-0000-0000-0000-000000000000 PipelineName : Adfv2QuickStartPipeline Input : {source, sink, enableStaging} Output : {dataRead, dataWritten, filesRead, filesWritten...} LinkedServiceName : ActivityRunStart : 8/27/2019 7:22:58 AM ActivityRunEnd : 8/27/2019 7:23:05 AM DurationInMs : 6828 Status : Succeeded Error : {errorCode, message, failureType, target} Activity 'Output' section: "dataRead": 20 "dataWritten": 20 "filesRead": 1 "filesWritten": 1 "sourcePeakConnections": 1 "sinkPeakConnections": 1 "copyDuration": 4 "throughput": 0.01 "errors": [] "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (Central US)" "usedDataIntegrationUnits": 4 "usedParallelCopies": 1 "executionDetails": [ { "source": { "type": "AzureBlobStorage" }, "sink": { "type": "AzureBlobStorage" }, "status": "Succeeded", "start": "2019-08-27T07:22:59.1045645Z", "duration": 4, "usedDataIntegrationUnits": 4, "usedParallelCopies": 1, "detailedDurations": { "queuingDuration": 3, "transferDuration": 1 } } ] Activity 'Error' section: "errorCode": "" "message": "" "failureType": "" "target": "CopyFromBlobToBlob"
Esaminare le risorse distribuite
La pipeline crea automaticamente la cartella di output nel contenitore BLOB adftutorial, quindi copia il file emp.txt dalla cartella di input a quella di output.
Nella pagina del contenitore adftutorial del portale di Azure selezionare Aggiorna per visualizzare la cartella di output.
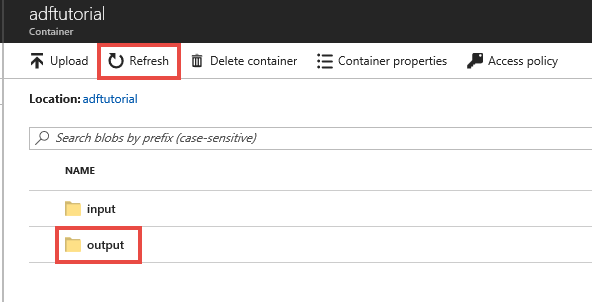
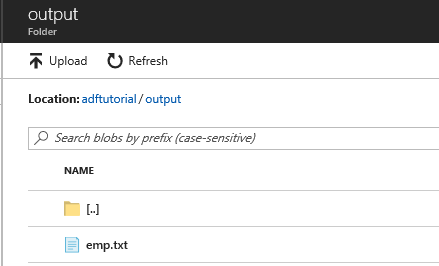
Nell'elenco delle cartelle selezionare output.
Verificare che emp.txt venga copiato nella cartella di output.
Pulire le risorse
È possibile eseguire la pulizia delle risorse create nel corso della guida introduttiva in due modi. È possibile eliminare il gruppo di risorse di Azure, che include tutte le risorse del gruppo. Se invece si vogliono mantenere intatte le altre risorse, eliminare solo la data factory creata in questa esercitazione.
Se si elimina un gruppo di risorse, vengono eliminate tutte le risorse in esso contenute, incluse le data factory. Eseguire il comando seguente per eliminare l'intero gruppo di risorse:
Remove-AzResourceGroup -ResourceGroupName $resourcegroupname
Nota
L'eliminazione di un gruppo di risorse può richiedere tempo. Attendere il completamento del processo.
Per eliminare solo la data factory e non l'intero gruppo di risorse, eseguire il comando seguente:
Remove-AzDataFactoryV2 -Name $dataFactoryName -ResourceGroupName $resourceGroupName
Contenuto correlato
La pipeline in questo esempio copia i dati da una posizione a un'altra in un archivio BLOB di Azure. Per informazioni sull'uso di Data Factory in più scenari, fare riferimento alle esercitazioni.